大家好,我是微学AI,今天给大家介绍一下计算机视觉的应用12-卷积神经网络中图像特征提取的可视化研究,让大家理解特征提取的全过程。
要理解卷积神经网络中图像特征提取的全过程,我们可以将其比喻为人脑对视觉信息的处理过程。就像我们看到一个物体时,大脑会通过不同的神经元来处理不同特征的信息,如轮廓、色彩和纹理等。
一、图像特征提取介绍
在CNN中,输入图像会被逐层处理,每一层都会提取不同的特征信息。这些层可以被看作是不同的“过滤器”,它们会识别图像中特定的模式和形状,比如边缘、角落和线条等。随着层数的逐渐增加,CNN能够提取越来越复杂的特征,比如图像中的纹理、形状和结构等。
假设我们的输入图像是一张猫的图片。CNN的第一层可能会检测到猫身体的边缘和角落,第二层可能会提取出猫耳朵的形状和脸部的轮廓,第三层可能会进一步分析猫毛发的纹理,眼睛,形状。这种特征提取的过程可以被可视化,让我们更好地理解CNN是如何学习和处理图像信息的。通过可视化,我们可以看到CNN不同层次提取的图像特征,可以发现低层次的特征包括边缘和纹理等,而高层次的特征包括眼睛、鼻子和嘴巴等更加抽象和语义化的信息。
二、CNN提取特征的原理
卷积神经网络通过卷积和池化操作来提取图像中的特征。其原理如下:
输入图像 I I I 经过多个卷积层和池化层的处理,得到最后的特征图 F F F。在卷积层中,使用一组可学习的滤波器 W W W 对输入图像进行卷积运算,并加上偏置 b b b,即:
C = W ∗ I + b C = W * I + b C=W∗I+b
其中, ∗ * ∗ 表示卷积运算。这样,每个滤波器在输入图像上滑动,并通过计算卷积运算,得到一个对应的特征图。
在特征图中,通过激活函数(如ReLU)进行非线性激活,得到激活特征图:
A = ReLU ( C ) A = \text{{ReLU}}(C) A=ReLU(C)
然后,通过池化层对激活特征图进行下采样操作,以减少特征图的空间维度。常用的池化操作是最大池化,它在每个池化窗口中选择最大值作为输出特征。这样可以保留最显著的特征,同时减少计算量。
经过多次卷积和池化操作,得到了一系列不同尺寸的特征图。这些特征图包含了输入图像的不同级别的特征,从低级的边缘和纹理到高级的语义信息。
这些特征图可以被传递到全连接层进行分类、检测或其他任务。全连接层将特征图展平成向量,并与权重矩阵相乘,再加上偏置,最后通过softmax函数等激活函数得到最终的输出结果。
CNN网络通过卷积和池化操作,自动学习图像中的特征,使得我们能够更好地理解和分析图像数据,并应用于各种计算机视觉任务。
三、CNN提取特征可视化过程
现在我将通过代码实现这个图像特征提取的过程:
import matplotlib.pyplot as plt
import torch
from PIL import Image
import numpy as np
import sys
sys.path.append("..")
from torchvision import transforms# 对于给定的一个网络层的输出x,x为numpy格式的array,维度为[0, channels, width, height]def draw_features(width, height, channels,x,savename):fig = plt.figure(figsize=(32,32))fig.subplots_adjust(left=0.05, right=0.95, bottom=0.05, top=0.95, wspace=0.05, hspace=0.05)for i in range(channels):plt.subplot(height,width, i + 1)plt.axis('off')img = x[0, i, :, :]pmin = np.min(img)pmax = np.max(img)img = (img - pmin) / (pmax - pmin + 0.000001)plt.imshow(img, cmap='gray')
# print("{}/{}".format(i, channels))fig.savefig(savename, dpi=300)fig.clf()plt.close()# 读取模型
def load_checkpoint(filepath):checkpoint = torch.load(filepath)model = checkpoint['model'] # 提取网络结构model.load_state_dict(checkpoint['net_state_dict']) # 加载网络权重参数for parameter in model.parameters():parameter.requires_grad = Falsemodel.eval()return modelsavepath = './'
def predict(model):# 读入模型model = load_checkpoint(model)print(model)##将模型放置在gpu上运行if torch.cuda.is_available():model.cuda()img = Image.open(img_path).convert('RGB')INPUT_SIZE =(224,224) # 根据需要调整图像的大小# 创建图像转换函数transform = transforms.Compose([transforms.Resize(INPUT_SIZE),transforms.ToTensor(),])# 对图像进行转换img = transform(img).unsqueeze(0)if torch.cuda.is_available():img = img.cuda()# 查看每一层处理的图片信息with torch.no_grad():x = model.conv1(img)x = model.bn1(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv1.png".format(savepath))x = model.relu(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv2.png".format(savepath))x = model.layer1(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv3.png".format(savepath))x = model.layer2(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv4.png".format(savepath))x = model.layer3(x)draw_features(5,5,15, x.cpu().numpy(), "{}/f1_conv5.png".format(savepath))if __name__ == "__main__":trained_model = 'resnet_model.pkl'img_path = 'cat.png'predict(trained_model)
构建模型ResNet模型:在可视化主函数的同级下创建目录:models->ClassNetwork->ResNet.py
import math
import torch
import torch.nn as nndef conv3x3(in_planes, out_planes, stride=1):"3x3 convolution with padding"return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,padding=1, bias=False)class BasicBlock(nn.Module):expansion = 1def __init__(self, inplanes, planes, stride=1, downsample=None):super(BasicBlock, self).__init__()self.conv1 = conv3x3(inplanes, planes, stride)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = conv3x3(planes, planes)self.bn2 = nn.BatchNorm2d(planes)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None):super(Bottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, planes * Bottleneck.expansion, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(planes * Bottleneck.expansion)self.relu = nn.ReLU(inplace=True)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)if self.downsample is not None:residual = self.downsample(x)#attention blockout += residualout = self.relu(out)return outclass ResNet(nn.Module):def __init__(self, dataset='cifar10', depth=18, num_classes=10, bottleneck=False):super(ResNet, self).__init__()self.dataset = datasetif self.dataset.startswith('cifar'):self.inplanes = 16# print(bottleneck)if bottleneck == True:n = int((depth - 2) / 9)block = Bottleneckelse:n = int((depth - 2) / 6)block = BasicBlockself.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=3, stride=1, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(self.inplanes)self.relu = nn.ReLU(inplace=True)self.layer1 = self._make_layer(block, 16, n)self.layer2 = self._make_layer(block, 32, n, stride=2)self.layer3 = self._make_layer(block, 64, n, stride=2)self.avgpool = nn.AvgPool2d(8)self.fc = nn.Linear(64 * block.expansion, num_classes)elif dataset == 'imagenet':blocks = {18: BasicBlock, 34: BasicBlock, 50: Bottleneck, 101: Bottleneck, 152: Bottleneck, 200: Bottleneck}layers = {18: [2, 2, 2, 2], 34: [3, 4, 6, 3], 50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3],200: [3, 24, 36, 3]}assert layers[depth], 'invalid detph for ResNet (depth should be one of 18, 34, 50, 101, 152, and 200)'self.inplanes = 64self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False)self.bn1 = nn.BatchNorm2d(64)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)self.layer1 = self._make_layer(blocks[depth], 64, layers[depth][0])self.layer2 = self._make_layer(blocks[depth], 128, layers[depth][1], stride=2)self.layer3 = self._make_layer(blocks[depth], 256, layers[depth][2], stride=2)self.layer4 = self._make_layer(blocks[depth], 512, layers[depth][3], stride=2)self.avgpool = nn.AvgPool2d(7)self.fc = nn.Linear(512 * blocks[depth].expansion, num_classes)for m in self.modules():if isinstance(m, nn.Conv2d):n = m.kernel_size[0] * m.kernel_size[1] * m.out_channelsm.weight.data.normal_(0, math.sqrt(2. / n))elif isinstance(m, nn.BatchNorm2d):m.weight.data.fill_(1)m.bias.data.zero_()def _make_layer(self, block, planes, blocks, stride=1):downsample = Noneif stride != 1 or self.inplanes != planes * block.expansion:downsample = nn.Sequential(nn.Conv2d(self.inplanes, planes * block.expansion,kernel_size=1, stride=stride, bias=False),nn.BatchNorm2d(planes * block.expansion),)layers = []layers.append(block(self.inplanes, planes, stride, downsample))self.inplanes = planes * block.expansionfor i in range(1, blocks):layers.append(block(self.inplanes, planes))return nn.Sequential(*layers)def forward(self, x):if self.dataset == 'cifar10' or self.dataset == 'cifar100':x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc(x)elif self.dataset == 'imagenet':x = self.conv1(x)x = self.bn1(x)x = self.relu(x)x = self.maxpool(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.avgpool(x)x = x.view(x.size(0), -1)x = self.fc(x)return x
四、征可视化过程运行
这里我们输入一张猫咪的图像:

程序运行我们看到ResNet的网络结构如下:
ResNet((conv1): Conv2d(3, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(layer1): Sequential((0): BasicBlock((conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True))(1): BasicBlock((conv1): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(16, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer2): Sequential((0): BasicBlock((conv1): Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(16, 32, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(layer3): Sequential((0): BasicBlock((conv1): Conv2d(32, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)(downsample): Sequential((0): Conv2d(32, 64, kernel_size=(1, 1), stride=(2, 2), bias=False)(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)))(1): BasicBlock((conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(relu): ReLU(inplace=True)))(avgpool): AvgPool2d(kernel_size=8, stride=8, padding=0)(fc): Linear(in_features=64, out_features=100, bias=True)
)
然后会生成每一层图像处理的过程:
conv1第一层处理:

relu层处理:

layer1层处理:
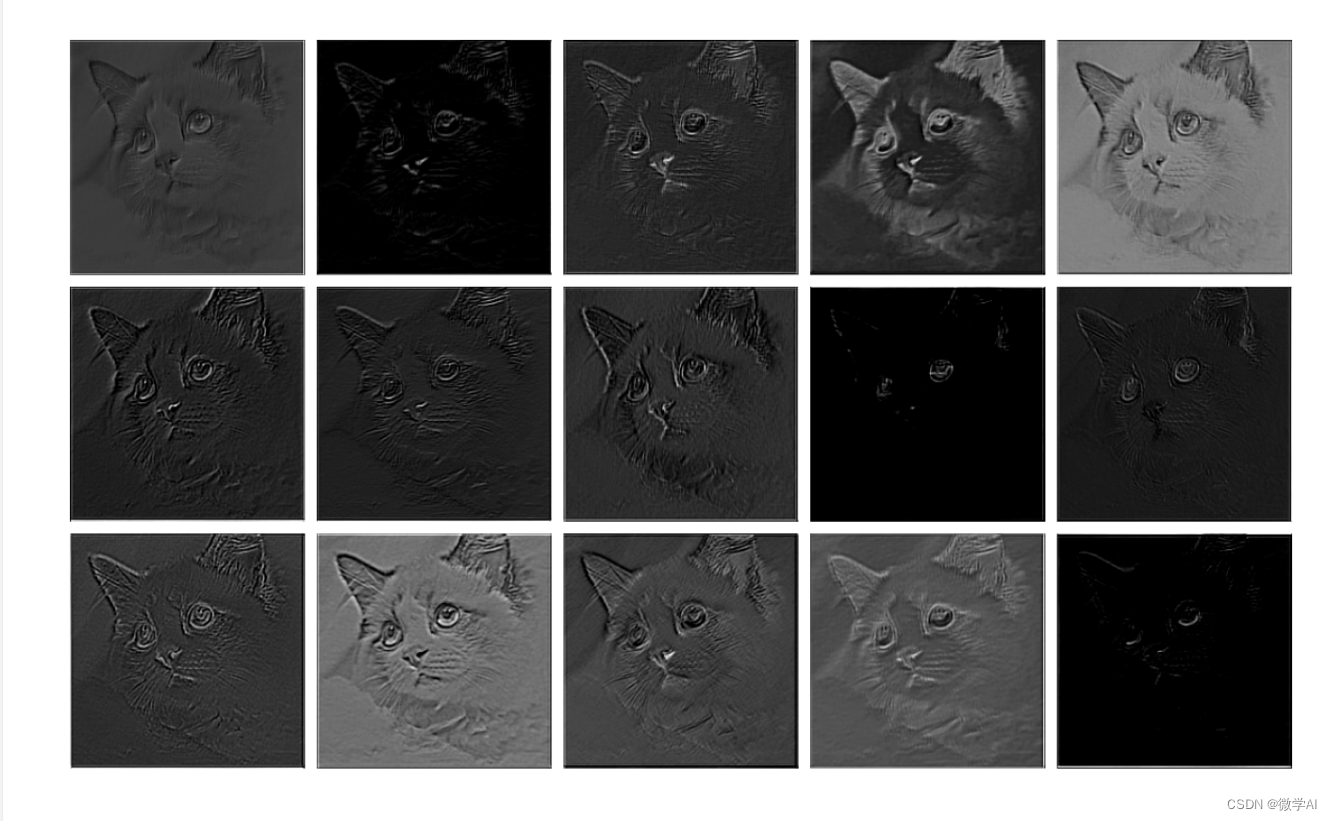
layer2层处理:

layer3层处理:
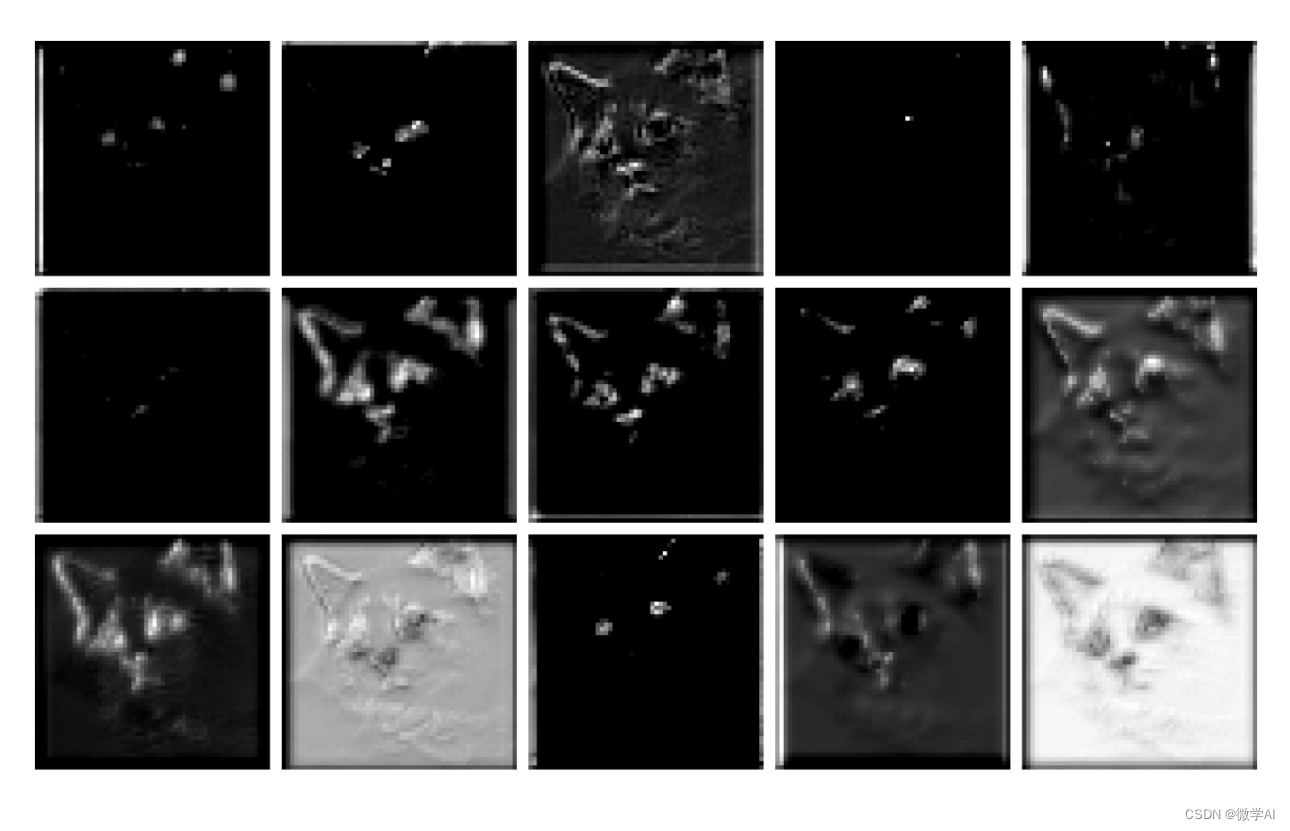
五、总结
CNN中的图像特征提取是通过模拟人类视觉系统的工作原理,逐层提取输入数据(比如图像)的不同层次的特征表示,从而实现对输入数据的深度学习和分析。通过卷积层、池化层和全连接层等组成的多层结构,CNN能够自动学习出输入数据中的抽象特征,从低级特征(如边缘、纹理)到更高级的语义概念(如物体形状、颜色、纹理等)。这种层次化的特征表达方式,使得CNN在图像分类、目标检测、人脸识别、图像生成等多种计算机视觉任务中都具有优异的性能表现。与传统的手工特征提取方法相比,CNN不需要人工设计特征,能够自动学习出最优的特征表示,因此大大减少了人工干预的成本,并且具有更好的泛化能力和鲁棒性。







相比有什么优势和劣势?)









)
- 实战项目案例)
