DSA-Face: Diverse and Sparse Attentions for Face Recognition Robust to Pose Variation and Occlusion
一、创新点
1.提出了成对自我对比注意力来强制模型提取不同的局部特征;
2.设计注意力稀疏性损失是为了鼓励注意力图中的稀疏反应,阻止对分散注意力的区域的强调,同时鼓励对有区别的面部部位的关注。
二、模型
提出了多样化和稀疏注意力,称为 DSA-Face。首先,散度损失旨在通过最大化每对注意力图之间的欧几里得距离来明确鼓励多个注意力图之间的多样性。因此,开发了成对自我对比注意(PSCA)来定位提供全面描述的不同面部部位。其次,提出了注意力稀疏损失(ASL)来鼓励注意力图中的稀疏响应,其中仅强调有区别的部分,而不鼓励分散注意力的区域(例如背景或面罩)。 DSA-Face 模型建立在 PSCA 和 ASL 的基础上,旨在学习多样化和稀疏的注意力,它可以提取多样化的判别性局部表示并抑制对噪声区域的关注。
主要包括成对自我对比注意力(PSCA)和注意力稀疏损失(ASL)。首先,PSCA以自我对比的方式扩大了成对注意力距离。以这种方式,鼓励不同的注意力图相互排斥,从而定位不同的面部部位。PSCA 能够通过扩大成对注意力距离来提取不同的局部表示。由于每个图像细节都是在 PSCA 的指导下进行彻底挖掘的,因此如果没有明确的信号,则可能会提取一些噪声信息,例如背景或面罩。其次,ASL 将注意力图中分散区域的反应缩小到零。因此,仅强调有区别的部分,而不鼓励分散注意力的区域。
总体框架如图3所示。主干CNN提取高级特征图以提取不同的局部特征。然后使用多个局部分支来提取不同的局部特征,这些特征由 PSCA 和 ASL 指导。提取局部特征并用于预测身份。
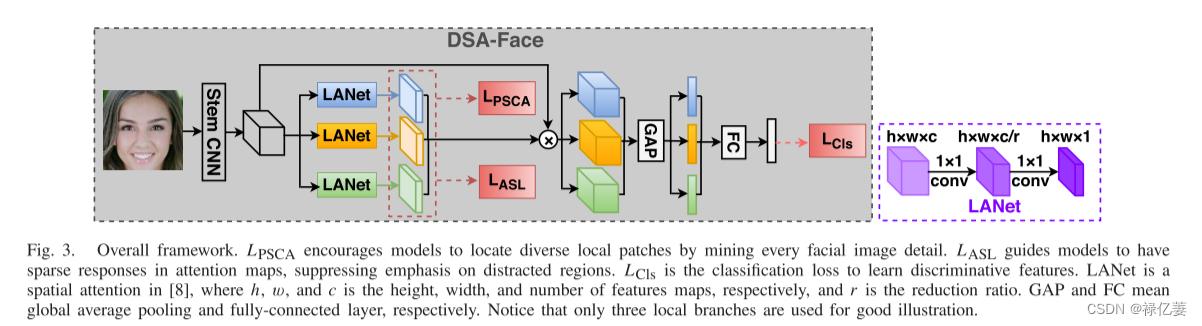
总体框架:LPSCA 鼓励模型通过挖掘每个面部图像细节来定位不同的局部块。 LASL 引导模型在注意力图中做出稀疏响应,从而抑制对分散区域的强调。GAP和FC分别表示全局平均池化和全连接层。LCls 是学习判别特征的分类损失。 LANet是[8]中的空间注意力,其中h、w和c分别是特征图的高度、宽度和数量,r是缩减比率。
A. 成对自我对比注意力
由于不同的本地分支使用相同的架构(即LANet),如果没有适当的指导,将会学习到高度相似的参数。这会导致注意力冗余问题。因此,应该设计一个多元化先验,旨在多元化多个本地分支机构。成对自我对比注意力(PSCA),它由散度损失 LPSCA 引导。损失定义如下:
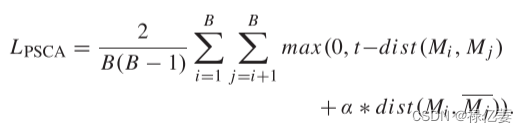
其中, Mi 和 Mj 分别表示由第 i 个和第 j 个局部分支生成的注意力图。 B是局部分支的总数,t是指超参数边距,dist(Mi,Mj)是Mi和Mj之间的欧氏距离。它最大化 Mi 和 Mj 之间的距离,并最小化 Mi 和 Mj 之间的距离。请注意,Mj + Mj` = E,其中 E 是一个全 1 元素的矩阵,这意味着 Mj 中响应高的区域在 Mj` 中响应低,反之亦然。
对于 FR 中的局部表示,只有少数重要的局部斑块(例如鼻子、嘴巴、双眼或嘴巴)可以发挥至关重要的作用。因此,预计 Mi 和 Mj 在少数部分上有稀疏响应。另一方面,Mj` 在大的不重要区域周围有很高的响应。因此,dist(Mi , Mj`)往往比 dist (Mi , Mj ) 大得多。因此,我们使用一个系数(即α)来平衡这两个值。PSCA中不太可能出现注意力子集问题。通过这种方式,鼓励不同的地方分支相互排斥并提取更多样化的参数。
B. 注意力稀疏损失
应该强调少数有区别的部分,并且应该抑制不重要或分散注意力的区域。因此,注意力响应应该是稀疏的。提出了一种注意力稀疏损失 LASL 来增强目标函数,其定义如下:
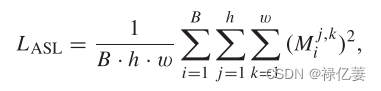
其中B是当地分支机构的总数。 h 和 w 是注意力图 Mi 的高度和宽度。这个想法背后的主要动机是通过鼓励注意力图中的响应稀疏性来施加稀疏性惩罚损失。通过惩罚高响应区域,LASL 将注意力图中的值限制为零。通过这种方式,只有有用的面部部位才会做出反应,而分散注意力的区域则被抑制。
C. 总体损失
为了监督网络学习判别性特征,应该使用分类损失LCls,包括CosFace损失(LCls-cosface)和ArcFace损失(LCls-arcface),它们可以生成判别性特征。 CosFace 损失的公式如下:

其中 N 代表样本数。 m 是使角度空间中的决策裕度最大化的余弦裕度。样本 xi 被归一化并重新缩放为 s,属于 yi 类。
ArcFace 损失中使用附加角边距惩罚 m 来鼓励类内紧凑性和类间差异:
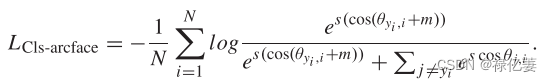
在我们的方法中,总体损失计算如下:
![]()
其中 LCls 是分类损失,监督网络学习受试者之间的区分。 LPSCA 鼓励不同面部部位的本地化。由于每个细节都是在图像中探索的,LCl 可能无法过滤掉一些分散注意力的区域,例如面罩或其他被遮挡的部分。为了解决这个问题,LASL 能够增强抑制噪声响应的能力。 λ和β控制这三种损失的平衡。
三、实验
DSA-Face[a]采用ResNet-100[38]作为主干CNN,ArcFace 损失进行监督;
DSA-Face[c]采用LS-CNN[8]作为主干CNN,由ArcFace 损失进行监督;
DSA-Face[b]使用LS-CNN[8]作为主干 CNN,由CosFace 损失进行监督;
DSA-Face[d]使用LS-CNN-177作为主干,CosFace 损失进行监督;
我们在表 III 中展示了我们的 DSA-Face 模型在 M2N、M2M 和 MLFW 协议上的结果。M2N是指蒙面人脸与正常人脸之间的匹配。M2M是指蒙面与蒙面人脸之间的匹配。MLFW 表示masked LFW 数据集中的协议。错误接受率 (FAR) = 0.1、0.01 和 0.001 时的真实接受率 (TAR) 值, d 表示 Rank-1 准确度。







)


)





 类、对象)
)
!)
![[网络安全] IIS----WEB服务器](http://pic.xiahunao.cn/[网络安全] IIS----WEB服务器)
、:nth-child(n)、first-child和last-child))