文章目录
- 优化算法服务:从单进程到并行化
- 单个服务架构
- 多并行服务架构
- Docker化并指定并行服务数量
优化算法服务:从单进程到并行化
在实际应用中,单个算法服务的并发能力可能无法满足需求。为了提高性能和并发处理能力,我们可以使用Gunicorn和Docker来实现算法服务的并行化部署。
单个服务架构
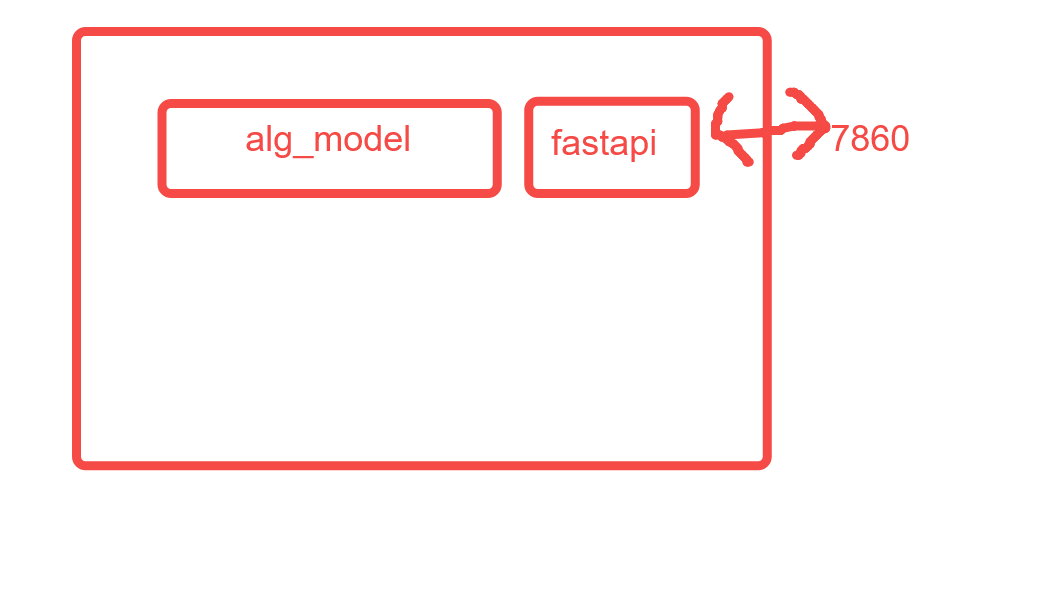
首先,让我们来看看单个服务的架构:
from fastapi import FastAPIapp = FastAPI()alg_model = xxxx() # Initialize your algorithm model@app.post("/alginfer")
def alginfer(xxxx):# Perform inference using alg_modelresult = alg_model.predict(xxxx)return result
在这个架构下,服务拓扑图如下:
多并行服务架构
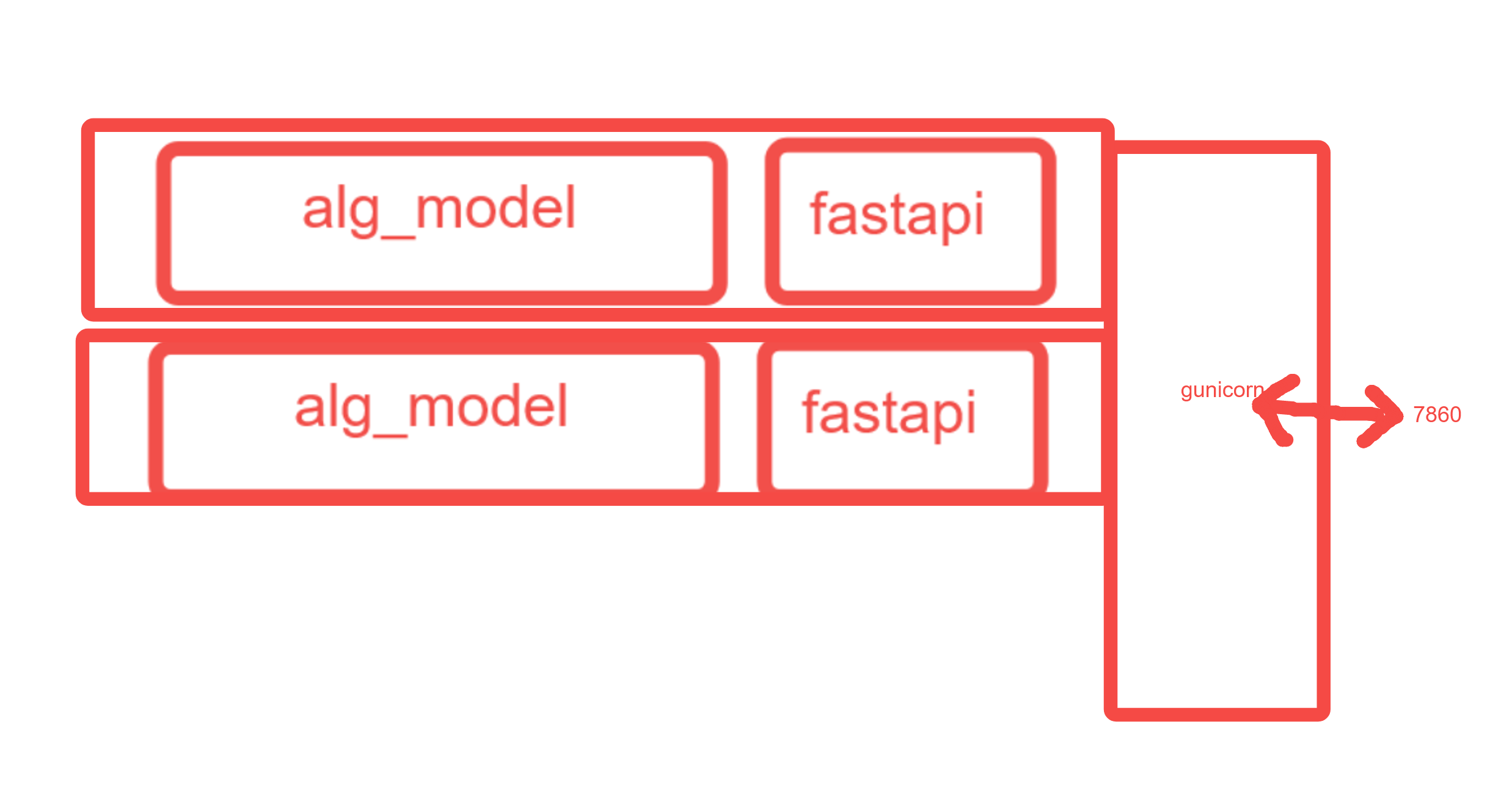
为了提高服务并发能力,我们可以使用Gunicorn来启动多个并行的算法服务。以下是如何使用Gunicorn进行多并行服务的部署:
pip install gunicorn
gunicorn -w 2 -b 0.0.0.0:7860 -k uvicorn.workers.UvicornWorker sdxl_app:app
在这个架构下,服务拓扑图变为:
Docker化并指定并行服务数量
通过Docker容器化算法服务,并通过环境变量来指定并行服务的数量,可以进一步简化部署和管理。以下是实现这一目标的步骤:
首先,创建一个gunicorn_config.py文件:
import osbind = '0.0.0.0:7860' # Listen address and port
workers = int(os.environ.get('GUNICORN_WORKERS', '1')) # Number of workers
worker_class = 'uvicorn.workers.UvicornWorker' # Worker type
然后,编写Dockerfile:
FROM kevinchina/xxxx:xxxx
EXPOSE 7860
ENTRYPOINT gunicorn -c /workspace/gunicorn_config.py sdxl_app:app
最后,通过docker run命令启动容器,并指定环境变量来设置并行服务的数量:
docker run -e GUNICORN_WORKERS=2 -p 7860:7860 -d --gpus all kevinchina/xxxx:tttt
通过这些优化,我们可以轻松地实现算法服务的并行化部署,提高系统的性能和可伸缩性。

![Orion-14B-Chat-Plugin [model server error]解决方案](http://pic.xiahunao.cn/Orion-14B-Chat-Plugin [model server error]解决方案)






![【PWN · ret2syscall】[CISCN 2023 初赛]烧烤摊儿](http://pic.xiahunao.cn/【PWN · ret2syscall】[CISCN 2023 初赛]烧烤摊儿)
)






函数、插入子串.insert()函数)


