GPT-SoVITS 本地搭建踩坑
- 前言
- 搭建
- 下载
- 解压
- VSCode打开
- 安装依赖包
- 修改内容
- 1.重新安装版本
- 2.修改文件内容
- 运行
- 总结
前言
传言GPT-SoVITS作为当前与BertVits2.3并列的TTS大模型,于是本地搭了一个,简单说一下坑。
搭建
下载
到GitHub点击此处下载
https://github.com/RVC-Boss/GPT-SoVITS
解压
解压到全英文目录
VSCode打开
使用VSCode打开,切到conda并clone一个之前BertVits的环境(没环境的自己先做一个Python3.10的配好PyTorch的)
安装依赖包
使用下面语句安装依赖
pip install -r requirements.txt
修改内容
根据issues内大家讨论的结果,这样操作是实测可行的,但是之后作者应该会优化,截止发文这么改是没问题的,以后可能不用改了
https://github.com/RVC-Boss/GPT-SoVITS/issues/26
1.重新安装版本
输入下面的指令重新安装一下对应版本的
pip install funasr==0.8.7
pip install modelscope==1.10.0
2.修改文件内容
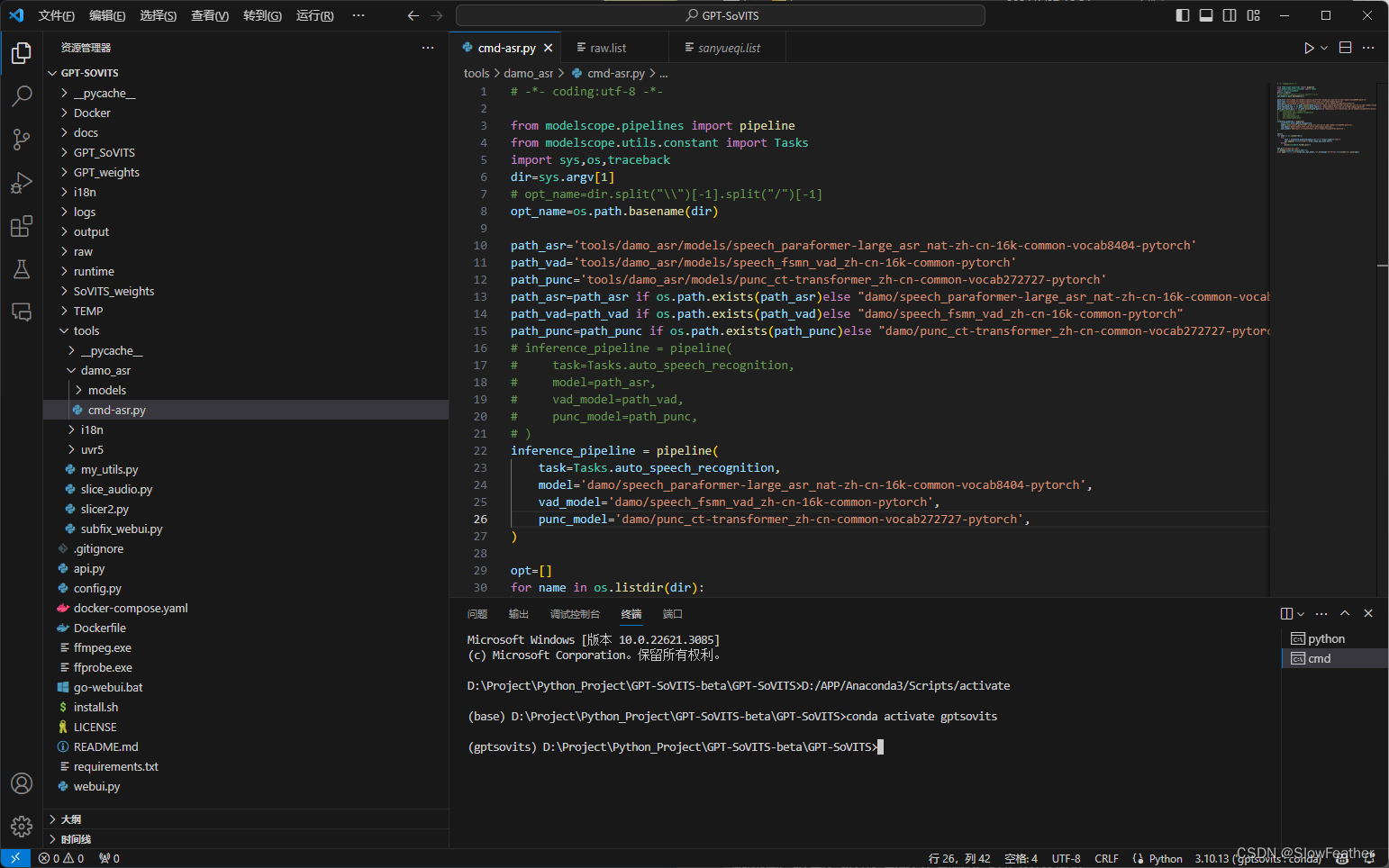
将 tools\damo_asr\cmd-asr.py 文件中的
inference_pipeline = pipeline(task=Tasks.auto_speech_recognition,model='tools/damo_asr/models/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch',vad_model='tools/damo_asr/models/speech_fsmn_vad_zh-cn-16k-common-pytorch',punc_model='tools/damo_asr/models/punc_ct-transformer_zh-cn-common-vocab272727-pytorch',
)
改成
inference_pipeline = pipeline(task=Tasks.auto_speech_recognition,model='damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch',vad_model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch',punc_model='damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch',
)
根据我的研究,原因是 git clone 的那几个模型的配置文件和它自动下载的内容不一样
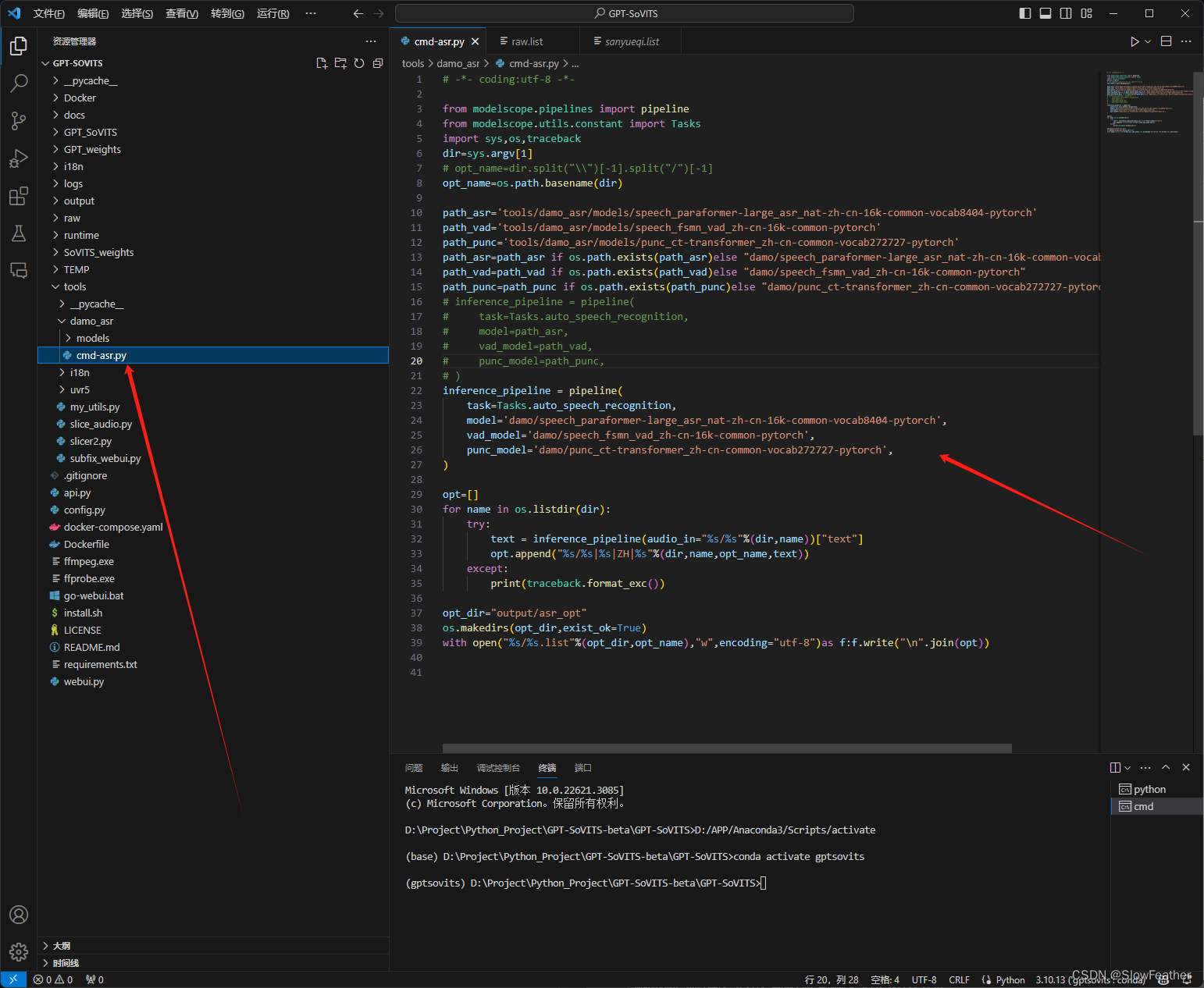
修改后源码如下
# -*- coding:utf-8 -*-from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
import sys,os,traceback
dir=sys.argv[1]
# opt_name=dir.split("\\")[-1].split("/")[-1]
opt_name=os.path.basename(dir)path_asr='tools/damo_asr/models/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch'
path_vad='tools/damo_asr/models/speech_fsmn_vad_zh-cn-16k-common-pytorch'
path_punc='tools/damo_asr/models/punc_ct-transformer_zh-cn-common-vocab272727-pytorch'
path_asr=path_asr if os.path.exists(path_asr)else "damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
path_vad=path_vad if os.path.exists(path_vad)else "damo/speech_fsmn_vad_zh-cn-16k-common-pytorch"
path_punc=path_punc if os.path.exists(path_punc)else "damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"
# inference_pipeline = pipeline(
# task=Tasks.auto_speech_recognition,
# model=path_asr,
# vad_model=path_vad,
# punc_model=path_punc,
# )
inference_pipeline = pipeline(task=Tasks.auto_speech_recognition,model='damo/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-pytorch',vad_model='damo/speech_fsmn_vad_zh-cn-16k-common-pytorch',punc_model='damo/punc_ct-transformer_zh-cn-common-vocab272727-pytorch',
)opt=[]
for name in os.listdir(dir):try:text = inference_pipeline(audio_in="%s/%s"%(dir,name))["text"]opt.append("%s/%s|%s|ZH|%s"%(dir,name,opt_name,text))except:print(traceback.format_exc())opt_dir="output/asr_opt"
os.makedirs(opt_dir,exist_ok=True)
with open("%s/%s.list"%(opt_dir,opt_name),"w",encoding="utf-8")as f:f.write("\n".join(opt))
运行
在环境中输入,即可正常启动
python webui.py
总结
能够有感情的朗读了,不错



连接启动失败can‘t connect to server, please wait)

: 强化练习一)


)







![P8651 [蓝桥杯 2017 省 B] 日期问题](http://pic.xiahunao.cn/P8651 [蓝桥杯 2017 省 B] 日期问题)
)

