2-7 门控循环单元(GRU)_哔哩哔哩_bilibili

GRU LSTM


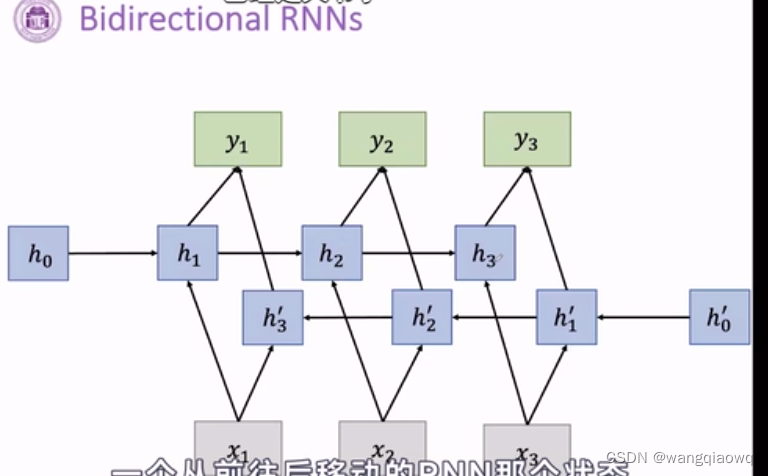
双向RNN
CNN 卷积神经网络
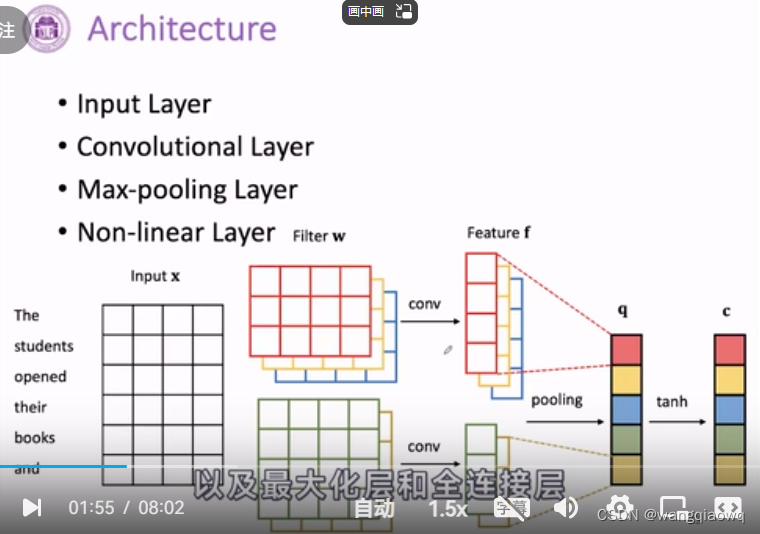
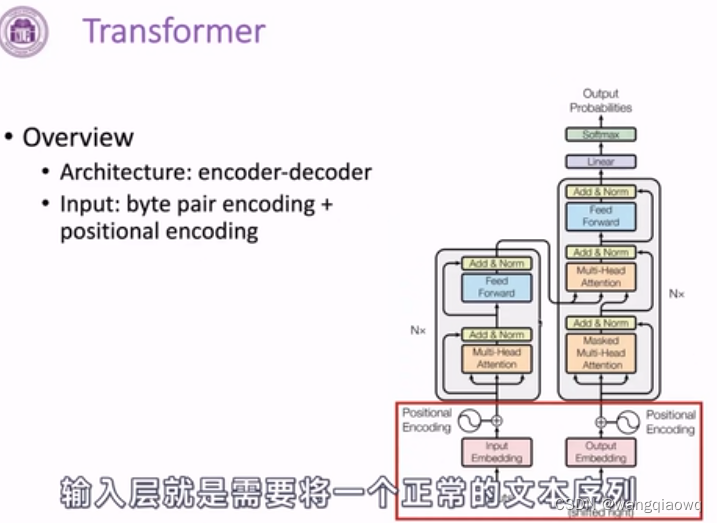
输入层 转化为向量表示



dropout
ppl



标量
在物理学和数学中,标量(Scalar)是一个只有大小、没有方向的量。它只用一个数值就可以完全描述,且满足交换律。例如,质量、温度、时间、体积、密度、功、能量等都是标量。
在向量代数中,标量与向量是相对的概念,标量可以与向量相乘,从而改变向量的长度但不改变其方向。例如,在三维空间中,如果一个向量的长度为3,一个标量为2,那么这个标量乘以向量的结果将得到一个长度为6,方向不变的新向量。

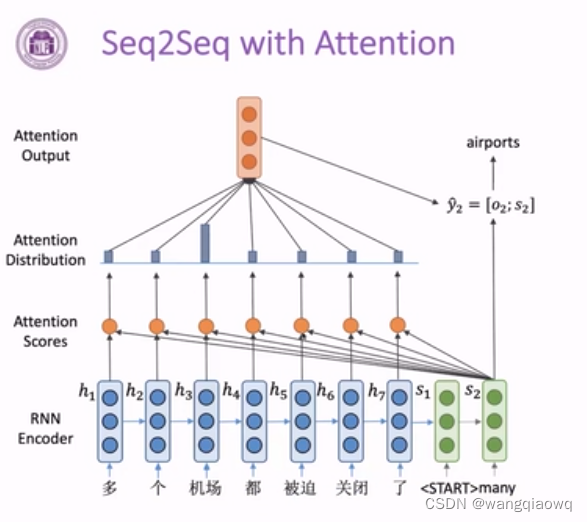
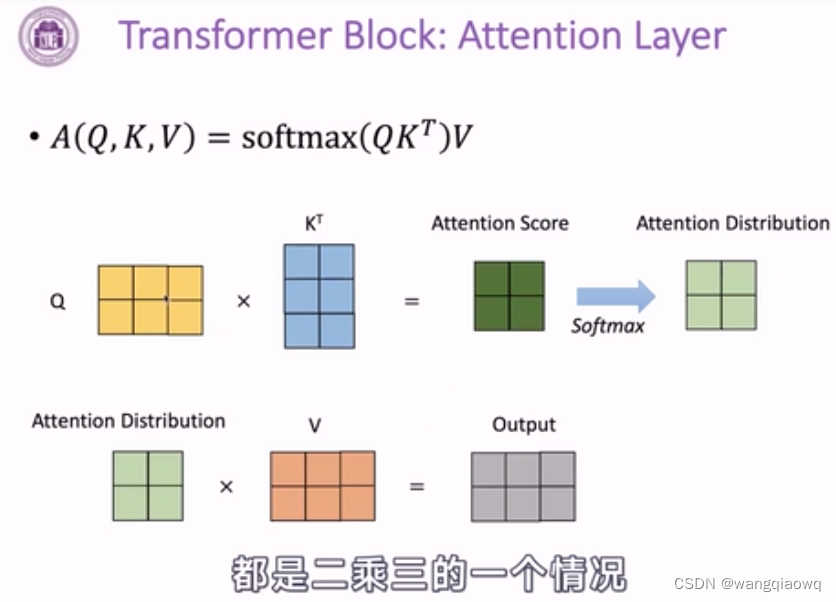
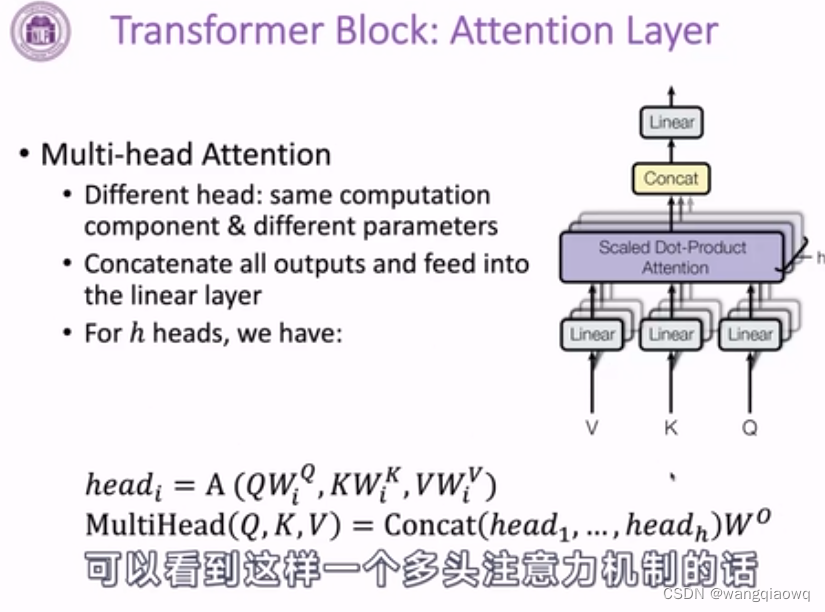
注意力分数
隐向量
隐向量(Latent Vector)是机器学习和深度学习中一个重要的概念,特别是在自然语言处理、推荐系统、图像识别等领域。隐向量是用来表示复杂数据的一种低维实数向量,它通过训练学习到的,并试图捕捉原始高维数据中的潜在结构和语义信息。
在推荐系统中:
- 隐向量通常用来表示用户和物品(如电影、音乐等),每个用户和每件物品都被映射到一个固定维度的向量空间中。
- 例如,在因子分解机(FM,Factorization Machines)模型中,各个特征(比如用户ID或商品ID)对应的隐向量可以通过矩阵分解得到,这些隐向量的内积可以用来预测用户对商品的评分或者偏好。
在自然语言处理中:
- 单词或文档也可以用隐向量来表示,这种表示方法常被称为词嵌入(Word Embeddings),如Word2Vec、GloVe等模型生成的向量。
- 这些隐向量可以捕获单词之间的语义相似性,使得在向量空间中距离相近的单词具有类似的含义。
在深度学习架构中:
- 在神经网络中,Embedding层就是用来将离散的高维输入(如one-hot编码)转换为连续的低维隐向量,以便进行后续的计算和模式挖掘。
总的来说,隐向量是一种压缩和抽象的表示形式,它有助于模型理解和处理高维稀疏数据,并能够发现数据内部隐藏的模式和联系。

softmax函数是一种在机器学习和深度学习中广泛使用的归一化指数函数,主要用于多分类问题的输出层计算预测类别概率分布。

激活函数
注意力机制解决信息瓶颈问题
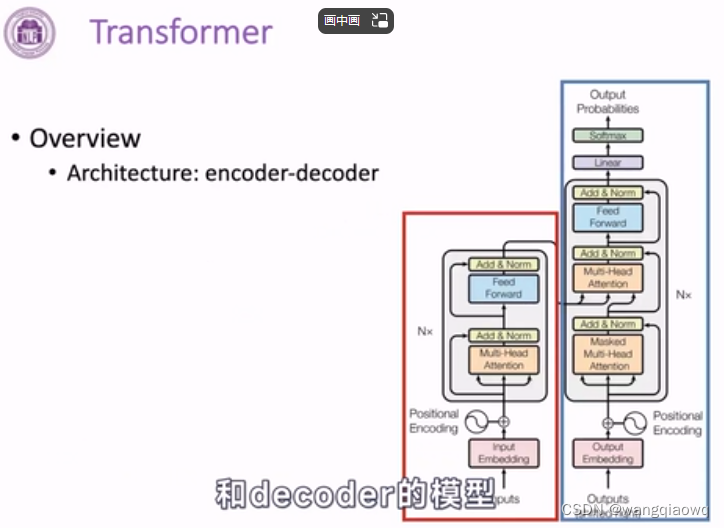
Transformer
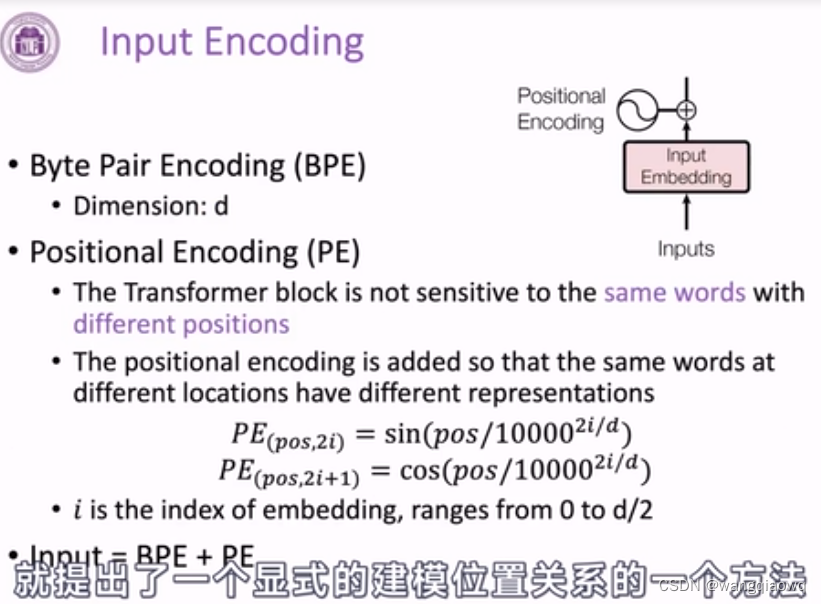
BPE
交叉熵





正则化

加权平均是一种统计方法,用于计算一组数值的平均值时,考虑到每个数值的重要性(权重)不同。在普通平均数中,所有数据点都同等重要,而在加权平均中,每个数据点有一个与其对应的权重值,这个权重反映了该数据点在最终结果中的相对影响程度。
加权平均的计算公式为:
加权平均数=∑(每个数据值×对应权重)∑(所有权重)加权平均数=∑(所有权重)∑(每个数据值×对应权重)
例如,在学校教育场景中,一个学生的学期总评成绩可能由平时测验、期中考试和期末考试的成绩按不同比例(权重)综合得出:
- 平时测验:80 分,权重 20%
- 期中考试:90 分,权重 30%
- 期末考试:95 分,权重 50%
那么,该学生的学期总评成绩可以通过以下步骤计算:
学期总评成绩=(80×0.2)+(90×0.3)+(95×0.5)0.2+0.3+0.5学期总评成绩=0.2+0.3+0.5(80×0.2)+(90×0.3)+(95×0.5)
此外,在财务领域,加权平均法常用于库存管理,计算存货的单位成本。例如,考虑一段时间内多次购入商品的情况,每次购入的数量和单价不同,这时会根据各批次进货的数量(作为权重)和其相应的单价来计算整个库存的平均单位成本。






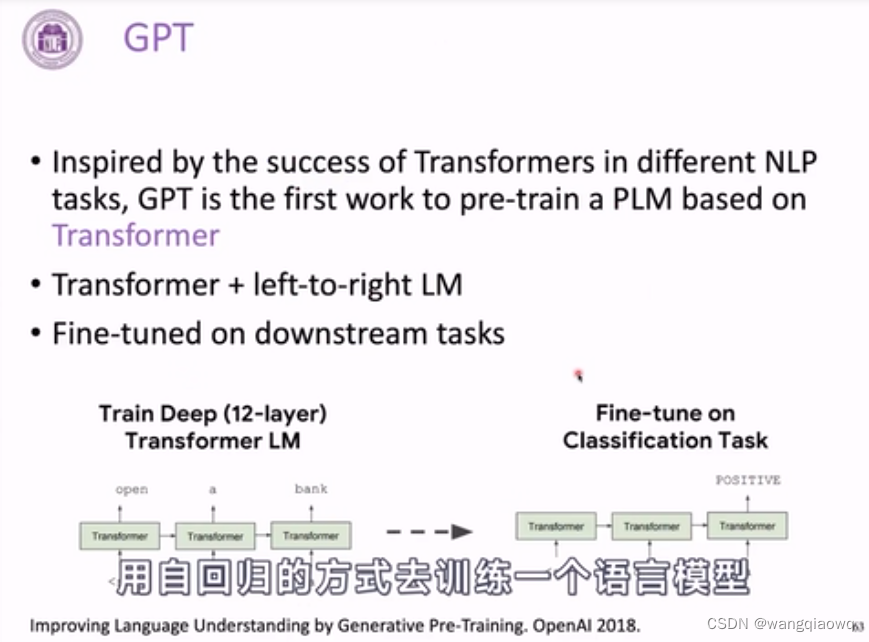




3-13 预训练语言模型--PLM介绍_哔哩哔哩_bilibili




的应用场景)








![[git] windows系统安装git教程和配置](http://pic.xiahunao.cn/[git] windows系统安装git教程和配置)
)
)

)

![P1065 [NOIP2006 提高组] 作业调度方案题目](http://pic.xiahunao.cn/P1065 [NOIP2006 提高组] 作业调度方案题目)