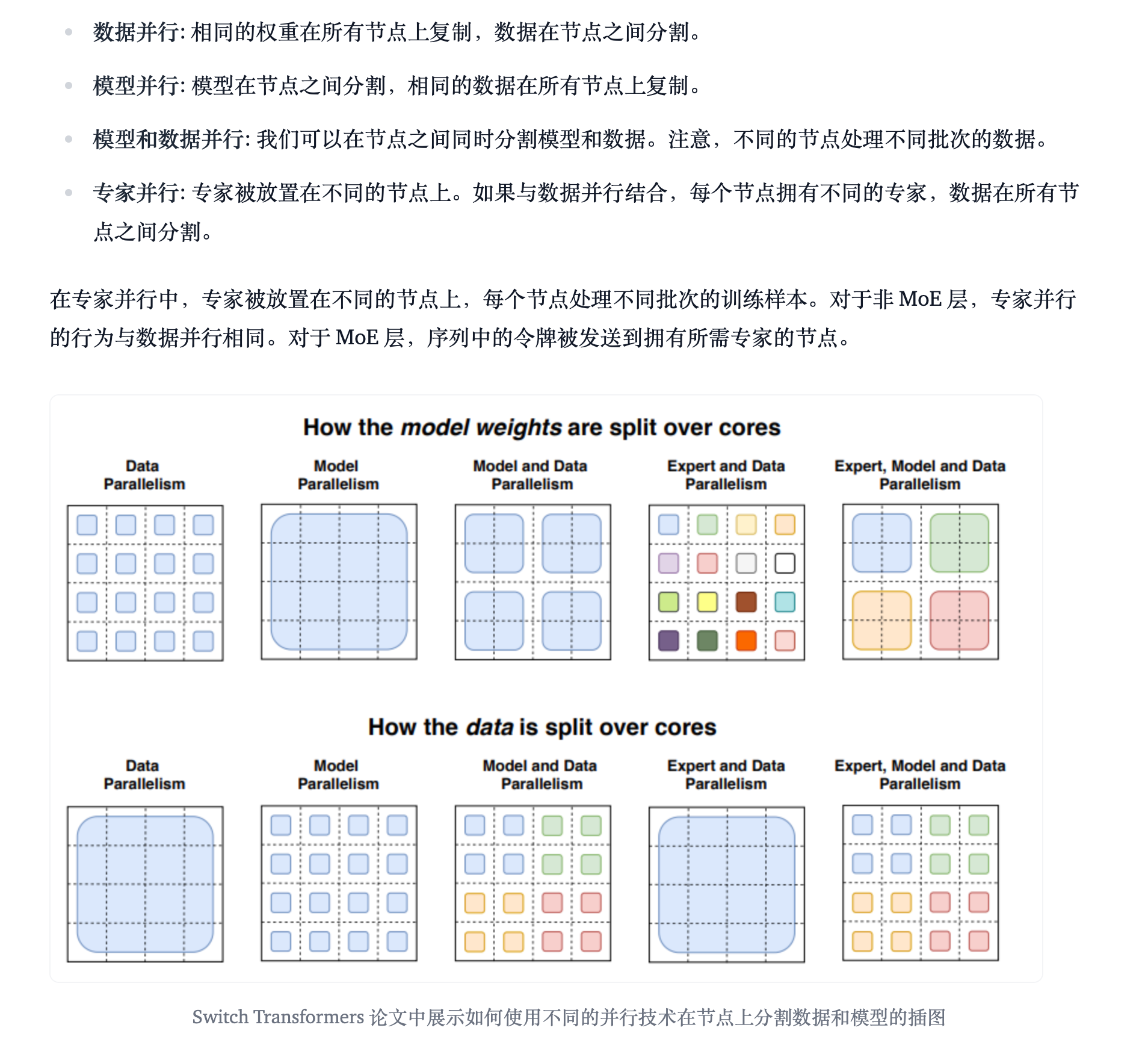
- 和多任务学习的mmoe很像哦(有空再学习一下)
- moe layer的起源:Switch Transformers paper
MoE
moe由两个结构组成:
- Moe Layer :这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
- Router:这个部分用于决定哪些令牌 (token) 被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
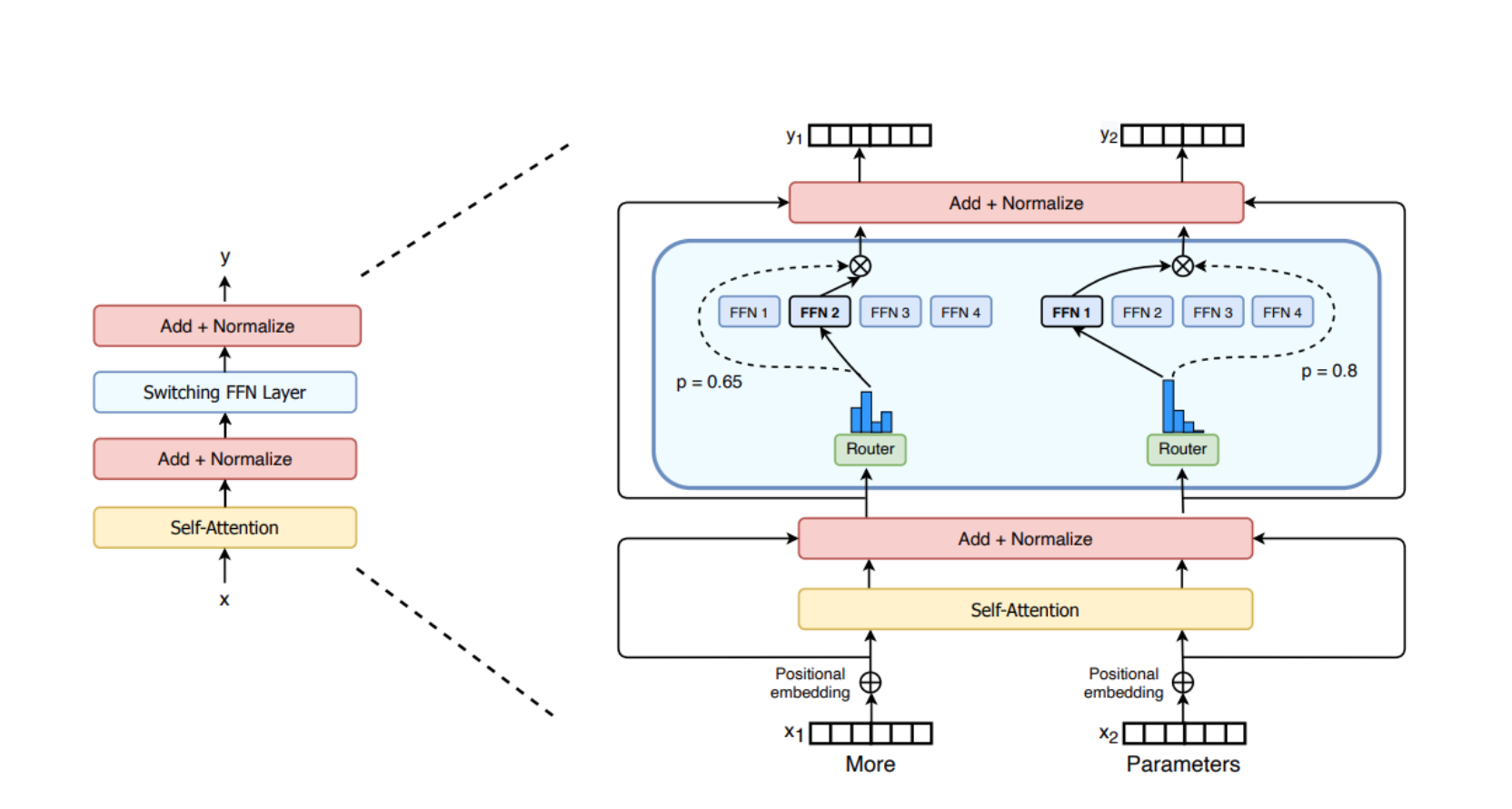
- 总的来说:一个门控网络和若干数量的专家
但是也有两个问题:
- 训练挑战: 虽然 MoE 能够实现更高效的计算预训练,但它们在微调阶段往往面临泛化能力不足的问题,长期以来易于引发过拟合现象。
- 推理挑战: MoE 模型虽然可能拥有大量参数,但在推理过程中只使用其中的一部分,这使得它们的推理速度快于具有相同数量参数的稠密模型。然而,这种模型需要将所有参数加载到内存中,因此对内存的需求非常高。
以 Mixtral 8x7B 这样的 MoE 为例,需要足够的 VRAM 来容纳一个 47B 参数的稠密模型。之所以是 47B 而不是 8 x 7B = 56B,是因为在 MoE 模型中,只有 FFN 层被视为独立的专家,而模型的其他参数是共享的。
一个token发往多个专家的FLOPs:假设每个令牌只使用两个专家,那么推理速度 (以 FLOPs 计算) 类似于使用 12B 模型 (而不是 14B 模型),因为虽然它进行了 2x7B 的矩阵乘法计算,但某些层是共享的。
稀疏性
稀疏性的概念采用了条件计算的思想。
条件计算的概念:
每个样本的基础上激活网络的不同部分,使得在不增加额外计算负担的情况下扩展模型规模成为可能
在传统的稠密模型中,所有的参数都会对所有输入数据进行处理。相比之下,稀疏性允许我们仅针对整个系统的某些特定部分执行计算。这意味着并非所有参数都会在处理每个输入时被激活或使用,而是根据输入的特定特征或需求,只有部分参数集合被调用和运行。
计算挑战:尽管较大的批量大小通常有利于提高性能,但当数据通过激活的专家时,实际的批量大小可能会减少。
比如,假设我们的输入批量包含 10 个令牌, 可能会有五个令牌被路由到同一个专家,而剩下的五个令牌分别被路由到不同的专家。这导致了批量大小的不均匀分配和资源利用效率不高的问题

门控机制改进:
其中包括带噪声的 TopK 门控 (Noisy Top-K Gating)。这种门控方法引入了一些可调整的噪声,然后保留前 k 个值

- 通过使用较低的 k 值 (例如 1 或 2),我们可以比激活多个专家时更快地进行训练和推理。
- 为什么不仅选择最顶尖的专家呢?最初的假设是,需要将输入路由到不止一个专家,以便门控学会如何进行有效的路由选择,因此至少需要选择两个专家
我们为什么要添加噪声呢?这是为了专家间的负载均衡!
负载均衡
不均衡的原因:
如果所有的令牌都被发送到只有少数几个受欢迎的专家,那么训练效率将会降低。在通常的混合专家模型 (MoE) 训练中,门控网络往往倾向于主要激活相同的几个专家。这种情况可能会自我加强,因为受欢迎的专家训练得更快,因此它们更容易被选择。\
解决方法:
为了缓解这个问题,引入了一个 辅助损失,旨在鼓励给予所有专家相同的重要性。这个损失确保所有专家接收到大致相等数量的训练样本,从而平衡了专家之间的选择。
- transformers 库中,可以通过 aux_loss 参数来控制辅助损失
MoEs 更新 Transformers
谷歌使用 GShard 尝试将 Transformer 模型的参数量扩展到超过 6000 亿并不令人惊讶。
GShard 将在编码器和解码器中的每个前馈网络 (FFN) 层中的替换为使用 Top-2 门控的混合专家模型 (MoE) 层。
下图展示了编码器部分的结构。这种架构对于大规模计算非常有效: 当扩展到多个设备时,MoE 层在不同设备间共享,而其他所有层则在每个设备上复制。
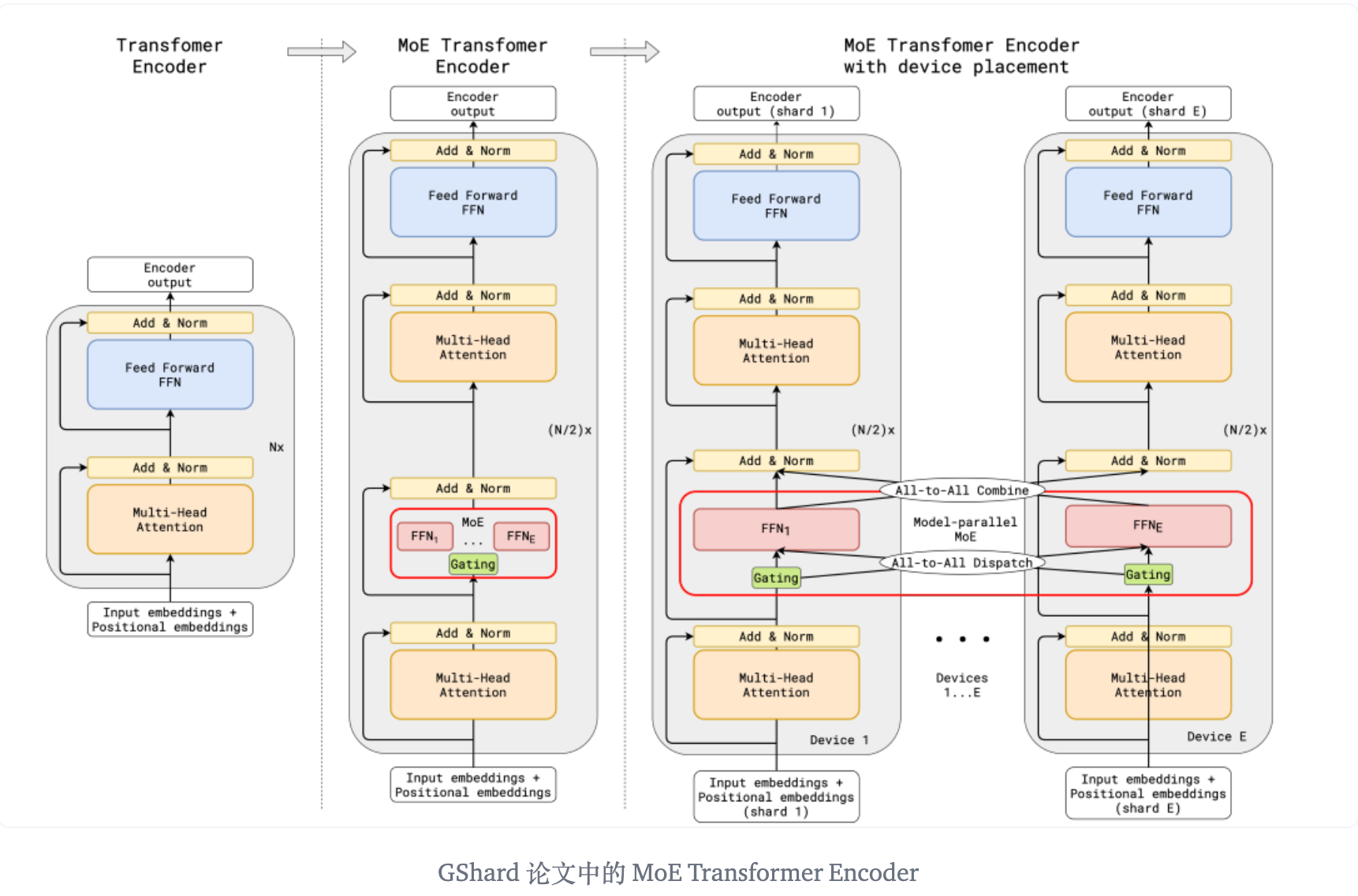
核心关键点:
- 随机路由: 在 Top-2 设置中,我们始终选择排名最高的专家,但第二个专家是根据其权重比例随机选择的。
- 专家容量: 我们可以设定一个阈值,定义一个专家能处理多少令牌。如果两个专家的容量都达到上限,令牌就会溢出,并通过残差连接传递到下一层,或在某些情况下被完全丢弃。
专家容量是 MoE 中最重要的概念之一。为什么需要专家容量呢?因为所有张量的形状在编译时是静态确定的,我们无法提前知道多少令牌会分配给每个专家,因此需要一个固定的容量因子。
注意: 在推理过程中,只有部分专家被激活。同时,有些计算过程是共享的,例如自注意力 (self-attention) 机制,它适用于所有令牌。这就解释了为什么我们可以使用相当于 12B 稠密模型的计算资源来运行一个包含 8 个专家的 47B 模型。如果我们采用 Top-2 门控,模型会使用高达 14B 的参数。但是,由于自注意力操作 (专家间共享) 的存在,实际上模型运行时使用的参数数量是 12B。
Switch-Transformer
- Switch Transformers 提出了一个 Switch Transformer 层,它接收两个输入 (两个不同的令牌) 并拥有四个专家。
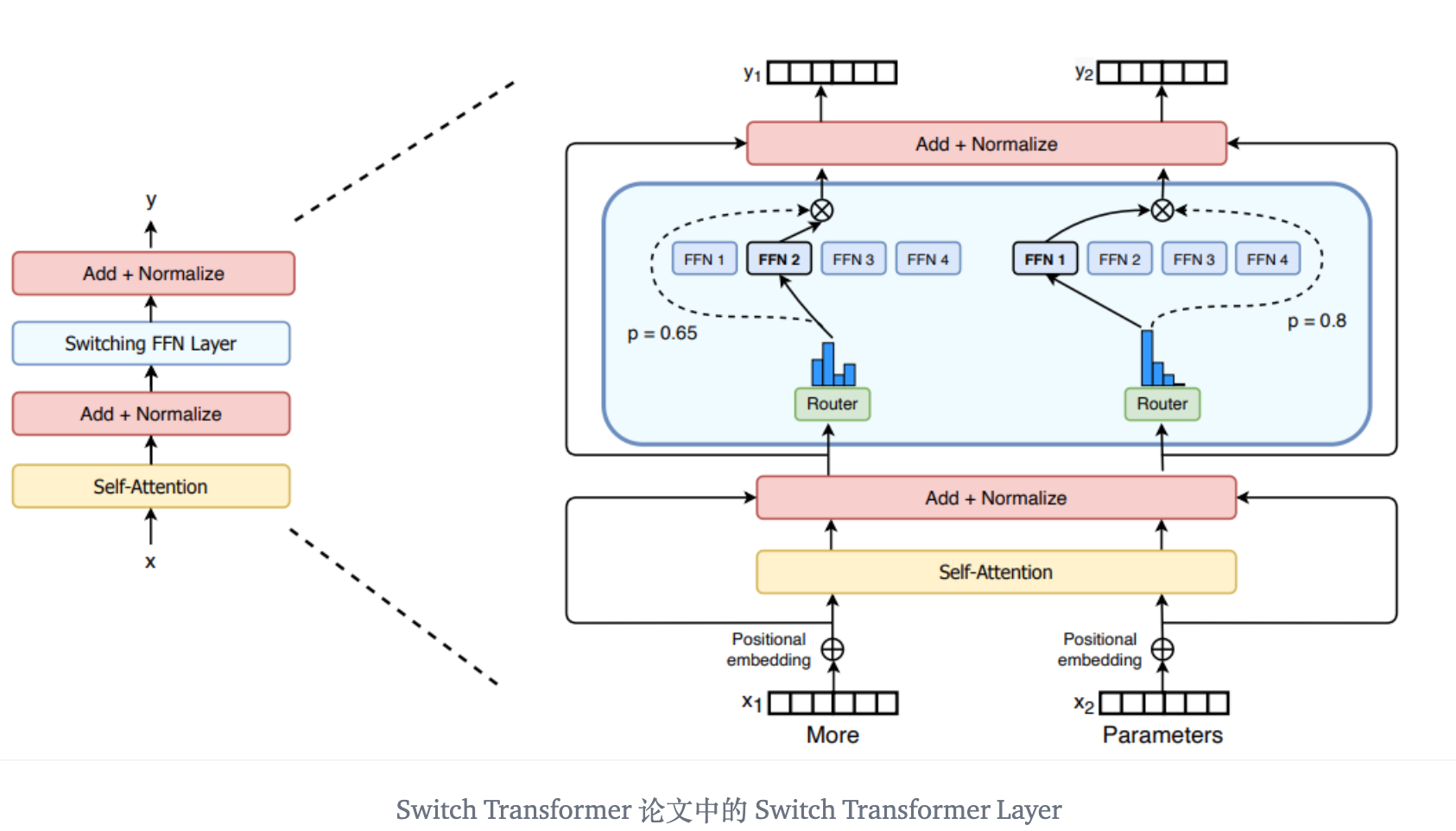

容量因子
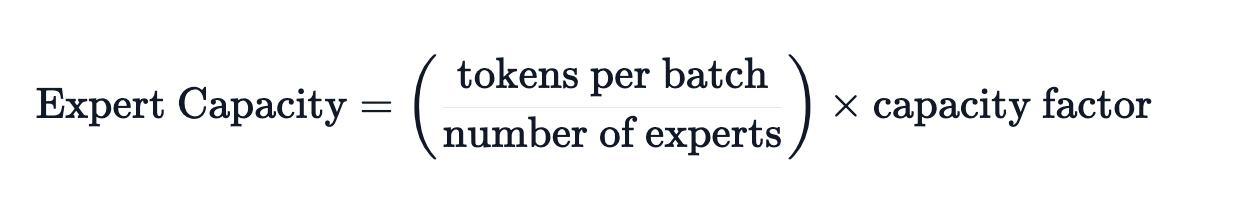
上述建议的容量是将批次中的令牌数量均匀分配到各个专家。如果我们使用大于 1 的容量因子,我们为令牌分配不完全平衡时提供了一个缓冲。
- 增加容量因子会导致更高的设备间通信成本,因此这是一个需要考虑的权衡。
- 特别值得注意的是,Switch Transformers 在低容量因子 (例如 1 至 1.25) 下表现出色。
- 在训练期间,对于每个 Switch 层的辅助损失被添加到总模型损失中。这种损失鼓励均匀路由,并可以使用超参数进行加权。
微调指南:
- https://colab.research.google.com/drive/1aGGVHZmtKmcNBbAwa9hbu58DDpIuB5O4?usp=sharing
混合精度的问题
当专家和门控网络都使用 bfloat16 精度训练时,出现了不稳定的训练现象。
- 这种不稳定性特别是由路由计算引起的,因为路由涉及指数函数等操作,这些操作对精度要求较高。
- 因此,为了保持计算的稳定性和精确性,保持更高的精度是重要的。为了减轻不稳定性,路由过程也使用了全精度。
GLaM
这篇工作探索了如何使用仅为原来 1/3 的计算资源 (因为 MoE 模型在训练时需要的计算量较少,从而能够显著降低碳足迹) 来训练与 GPT-3 质量相匹配的模型来提高这些模型的规模。
作者专注于仅解码器 (decoder-only) 的模型以及少样本和单样本评估,而不是微调。
- 他们使用了 Top-2 路由和更大的容量因子。
- 此外,他们探讨了将容量因子作为一个动态度量,根据训练和评估期间所使用的计算量进行调整。
用 Router z-loss 稳定模型训练
平衡损失aux_loss 可能会导致稳定性问题
- 引入 dropout 可以提高稳定性,但会导致模型质量下降。
- 另一方面,增加更多的乘法分量可以提高质量,但会降低模型稳定性。
ST-MoE 引入的 Router z-loss 在保持了模型性能的同时显著提升了训练的稳定性。
- 这种损失机制通过惩罚门控网络输入的较大 logits 来起作用,目的是促使数值的绝对大小保持较小,这样可以有效减少计算中的舍入误差。这一点对于那些依赖指数函数进行计算的门控网络尤其重要
训练结论
- 编码器中不同的专家倾向于专注于特定类型的令牌或浅层概念。
例如,某些专家可能专门处理标点符号,而其他专家则专注于专有名词等。与此相反,解码器中的专家通常具有较低的专业化程度。
- 增加更多专家可以提升处理样本的效率和加速模型的运算速度,但这些优势随着专家数量的增加而递减 (尤其是当专家数量达到 256 或 512 之后更为明显)
- Switch Transformers 的研究表明,其在大规模模型中的特性在小规模模型下也同样适用,即便是每层仅包含 2、4 或 8 个专家。
- 稀疏模型更易于出现过拟合现象,因此在处理这些模型时,尝试更强的内部正则化措施是有益的,比如使用更高比例的 dropout。
例如,我们可以为稠密层设定一个较低的 dropout 率,而为稀疏层设置一个更高的 dropout 率,以此来优化模型性能。
- 在微调过程中是否使用辅助损失是一个需要决策的问题。ST-MoE 的作者尝试关闭辅助损失,发现即使高达 11% 的令牌被丢弃,模型的质量也没有显著受到影响。令牌丢弃可能是一种正则化形式,有助于防止过拟合。
- 在相同的预训练困惑度下,稀疏模型在下游任务中的表现不如对应的稠密模型,特别是在重理解任务 (如 SuperGLUE) 上
- 知识密集型任务 (如 TriviaQA),稀疏模型的表现异常出色
- 在微调过程中,较少的专家的数量有助于改善性能
- 模型在小型任务上表现较差,但在大型任务上表现良好
- 一种可行的微调策略是尝试冻结所有非专家层的权重。实践中,这会导致性能大幅下降,但这符合我们的预期,因为混合专家模型 (MoE) 层占据了网络的主要部分。
- 我们可以尝试相反的方法: 仅冻结 MoE 层的参数。实验结果显示,这种方法几乎与更新所有参数的效果相当。这种做法可以加速微调过程,并降低显存需求。
- 稀疏模型往往更适合使用较小的批量大小和较高的学习率,这样可以获得更好的训练效果。
MoEs Meets Instruction Tuning
这篇论文进行了以下实验:
- 单任务微调
- 多任务指令微调
- 多任务指令微调后接单任务微调
结论:
-
Flan-MoE 相比原始 MoE 的性能提升幅度超过了 Flan T5 相对于原始 T5 的提升,这意味着 MoE 模型可能从指令式微调中获益更多,甚至超过了稠密模型。
-
此外,MoE 在多任务学习中表现更佳。与之前关闭 辅助损失 函数的做法相反,实际上这种损失函数可以帮助防止过拟合。
-
提高容量因子 (Capacity Factor, CF) 可以增强模型的性能,但这也意味着更高的通信成本和对保存激活值的显存的需求。在设备通信带宽有限的情况下,选择较小的容量因子可能是更佳的策略。
-
一个合理的初始设置是采用 Top-2 路由、1.25 的容量因子,同时每个节点配置一个专家。
让MoE起飞
为了使模型更适合部署,下面是几种有用的技术:
- 预先蒸馏实验: Switch Transformers 的研究者们进行了预先蒸馏的实验。他们通过将 MoE 模型蒸馏回其对应的稠密模型,成功保留了 30-40%的由稀疏性带来的性能提升。预先蒸馏不仅加快了预训练速度,还使得在推理中使用更小型的模型成为可能。
- 任务级别路由: 最新的方法中,路由器被修改为将整个句子或任务直接路由到一个专家。这样做可以提取出一个用于服务的子网络,有助于简化模型的结构。
- 专家网络聚合: 这项技术通过合并各个专家的权重,在推理时减少了所需的参数数量。这样可以在不显著牺牲性能的情况下降低模型的复杂度。

- mixtral8x7B部署:https://huggingface.co/blog/zh/mixtral
- https://huggingface.co/blog/zh/moe










![[C++] mutable的使用](http://pic.xiahunao.cn/[C++] mutable的使用)

![[计算机提升] 切换(域)用户](http://pic.xiahunao.cn/[计算机提升] 切换(域)用户)



图文详解)
 用RouterChain确定客户意图)

