Ingest pipeline 为我们摄入数据提供了极大的方便。在我之前的文章中,有非常多的有关 ingest pipeline 的文章。请详细阅读文章 “Elastic:开发者上手指南”。针对一组提供的文档执行摄取管道,可以选择使用替代管道定义。 Simulate ingest API 旨在用于故障排除或管道开发,因为它实际上并不将任何数据索引到 Elasticsearch 中。
注意:这个功能在 Elastic Stack 8.12 开始提供。

准备
为了测试这个 API,我们先来创建几个 pipelines:
创建一个 default pipeline
PUT _ingest/pipeline/default-pipeline
{"description": "This is the default pipeline","processors": [{"set": {"field": "default","value": "default"}}]
}创建一个 final pipeline
PUT _ingest/pipeline/final-pipeline
{"description": "This is a final pipeline","processors": [{"set": {"field": "final","value": "final"}}]
}我们接下来创建一个叫做 my-index 的索引:
PUT my-index
{"settings": {"default_pipeline": "default-pipeline","final_pipeline": "final-pipeline"}
}在上面,我们使用了 default_pipeline 及 final_pipeline。final pipeline 是在任何时候都会被调用的 pipeline。
测试 simulate ingest API
为了测试 ingest pipeline,我们可以尝试如下的例子:
POST /_ingest/_simulate
{"docs": [{"_index": "my-index","_id": "id","_source": {"foo": "bar"}},{"_index": "my-index","_id": "id","_source": {"foo": "rab"}}]
}上面的命令返回如下的结果:
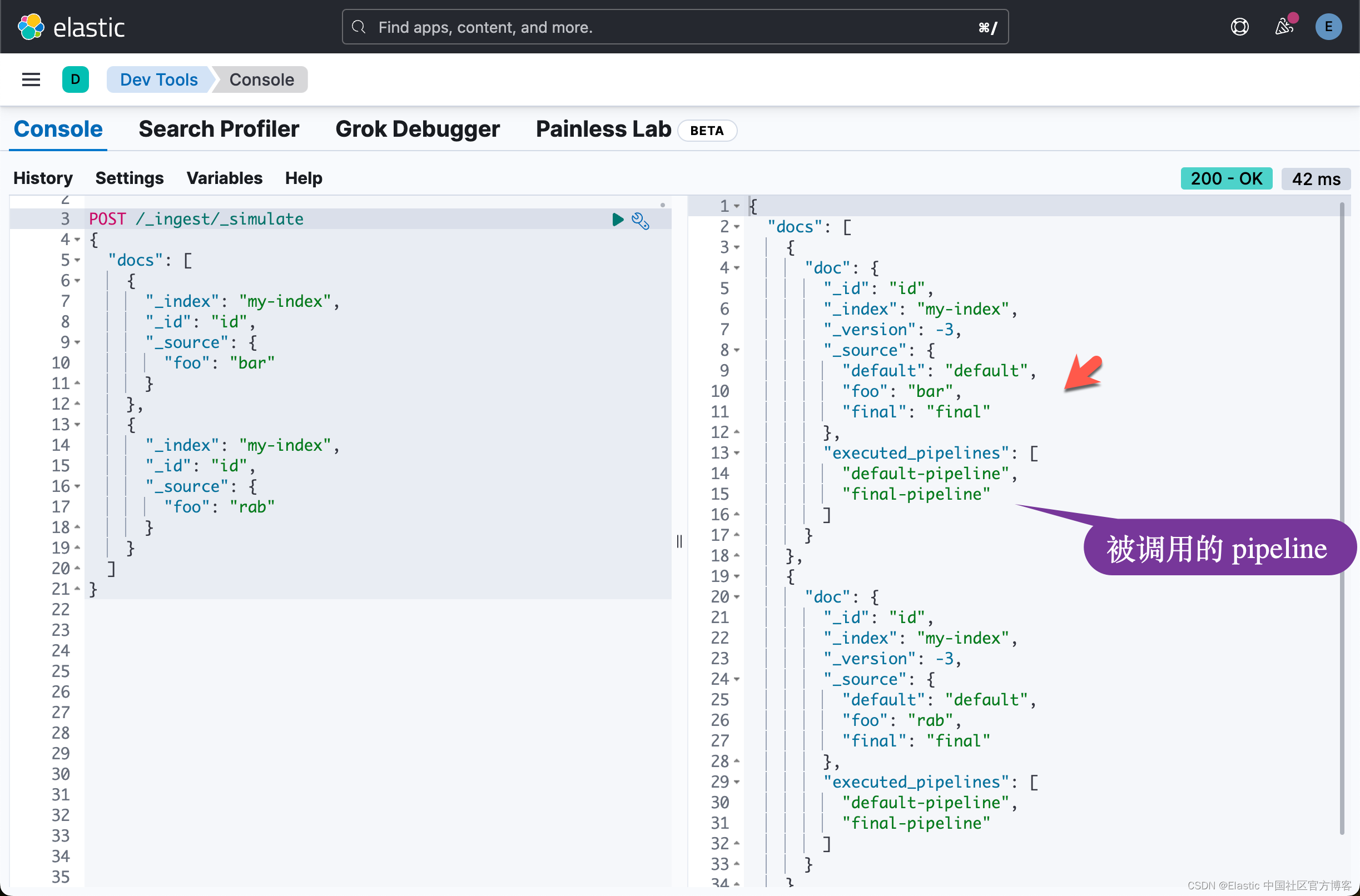
从上面的结果中,我们可以看出来在不传入任何的 pipeline 的情况下,default pipeline 及 final pipeline 都被调用。
我们还可以替换掉上面的 default pipeline,比如:
POST /_ingest/_simulate
{"docs": [{"_index": "my-index","_id": "id","_source": {"foo": "bar"}},{"_index": "my-index","_id": "id","_source": {"foo": "rab"}}],"pipeline_substitutions": {"default-pipeline": {"processors": [{"set": {"field": "test","value": "test"}}]}}
}在上面,我们替换在索引中配置的 default-pipeline。我们运行上面的命令,结果如下:
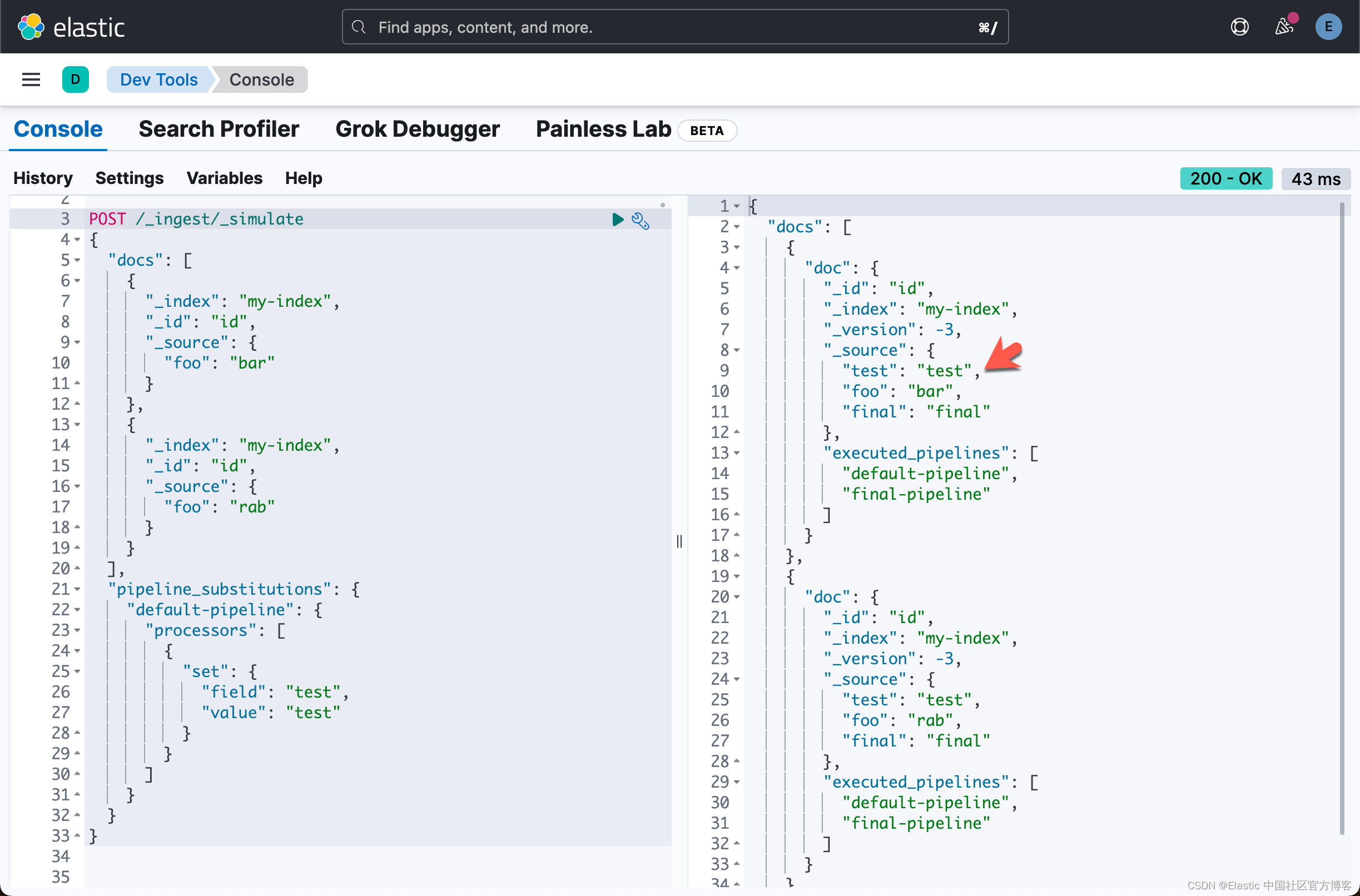
很显然尽管 executed_pipelines 里显示的还是 default-pipeline,但是我们的结果里增加的字段是 test。显然我们的 pipeline 已经被置换了。
使用同样的方法,我们也可以替换掉 final_pipeline:
POST /_ingest/_simulate
{"docs": [{"_index": "my-index","_id": "id","_source": {"foo": "bar"}},{"_index": "my-index","_id": "id","_source": {"foo": "rab"}}],"pipeline_substitutions": {"final-pipeline": {"processors": [{"set": {"field": "final-test","value": "final-test"}}]}}
}
请求
POST /_ingest/_simulateGET /_ingest/_simulatePOST /_ingest/<target>/_simulateGET /_ingest/<target>/_simulate前提条件
如果启用了Elasticsearch安全功能,你必须具有 index 或 create 索引权限才能使用此 API。
描述
Simulate ingest API 模拟将数据摄取到索引中。 它针对请求正文中提供的一组文档执行该索引的 default 和 final pipeline。 如果管道包含 reroute processor,它将遵循该重新路由处理器到新索引,以与非模拟摄取相同的方式执行该索引的管道。 没有数据被索引到 Elasticsearch 中。 相反,将返回转换后的文档,以及已执行的管道列表以及如果这不是模拟则文档将被索引的索引名称。 这与 simulate pipeline API 的不同之处在于,你为该 simulate pipeline API 指定单个管道,并且它仅运行该管道。Simulate pipeline API 对于开发单个管道更有用,而 simulate ingest API 对于对摄取到索引时应用的各种管道的交互进行故障排除更有用。
默认情况下,使用系统中当前的管道定义。 但是,你可以在请求正文中提供替代管道定义。 这些将用于代替系统中已有的管道定义。 这可用于替换现有的管道定义或创建新的管道定义。 管道替换仅在此请求中使用。
路径参数
<target>
- (可选,字符串)模拟摄取的索引名称。 这可以通过在每个文档上指定索引来覆盖。 如果你在请求路径中提供 <target>,它将用于任何未显式指定索引参数的文档。
查询参数
pipeline
- (可选,字符串)用作默认管道的管道。 这可用于覆盖正在摄取的索引的默认管道。
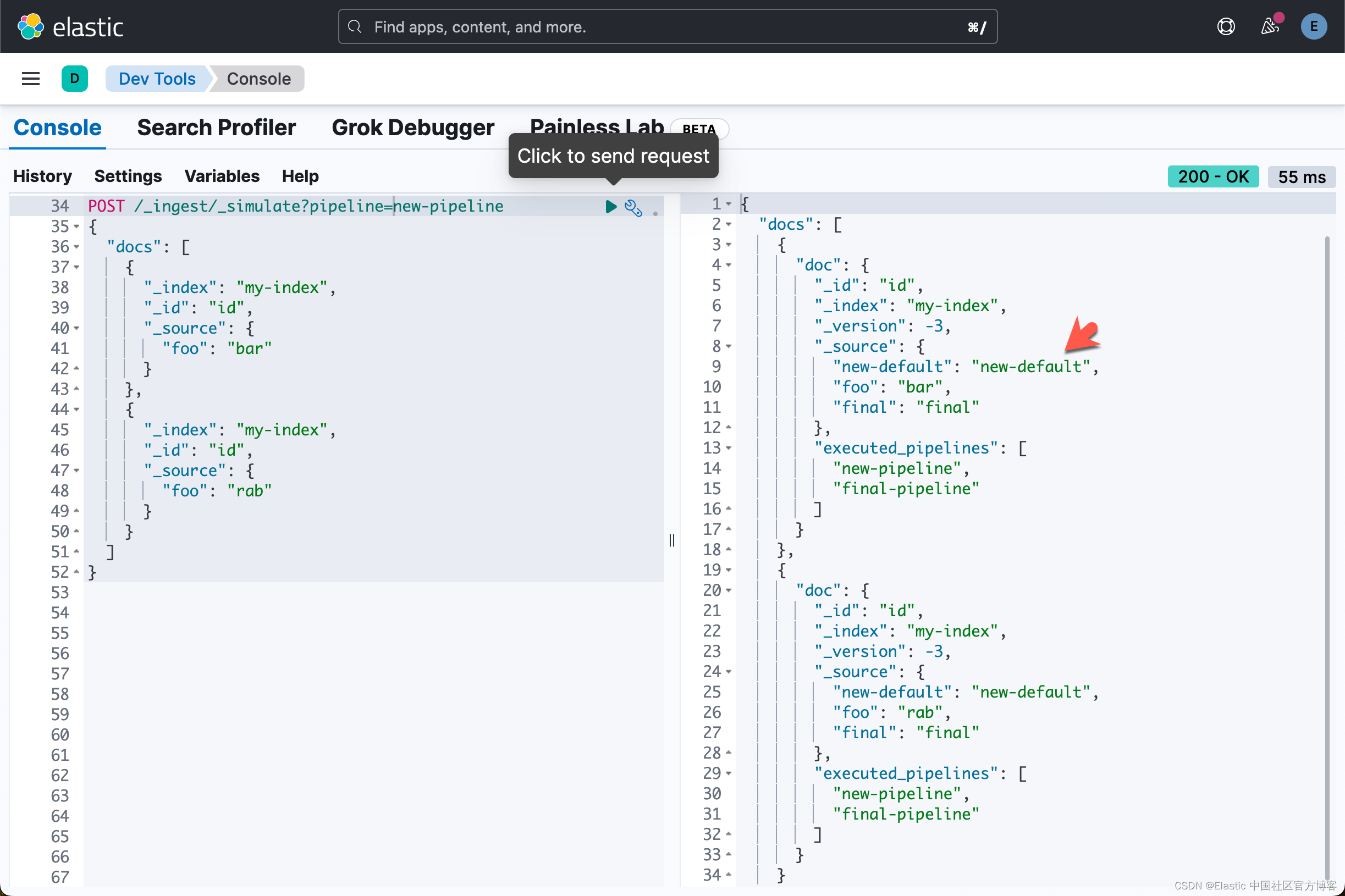
PUT _ingest/pipeline/new-pipeline
{"description": "This is a new pipeline","processors": [{"set": {"field": "new-default","value": "new-default"}}]
}POST /_ingest/_simulate?pipeline=new-pipeline
{"docs": [{"_index": "my-index","_id": "id","_source": {"foo": "bar"}},{"_index": "my-index","_id": "id","_source": {"foo": "rab"}}]
}
请求正文
docs
- (必需,对象数组)要在管道中测试的示例文档。
- docs 对象的属性
| _id | (可选,字符串)文档的唯一标识符。 |
| _index | (可选,字符串)文档将被提取到的索引的名称。 |
| _source | (必需,对象)文档的 JSON 正文。 |
pipeline_substitutions
- (可选,字符串到对象的映射)用于替换管道定义对象的管道 ID 映射。
- pipeline 定义对象的属性
| description | (可选,字符串)摄取管道的描述。 |
| on_failure | (可选,处理器对象数组)处理器发生故障后立即运行的处理器。 每个处理器都支持处理器级 on_failure 值。 如果没有 on_failure 值的处理器发生故障,Elasticsearch 将使用此管道级参数作为后备。 该参数中的处理器按照指定的顺序依次运行。 Elasticsearch 不会尝试运行管道的剩余处理器。 |
|
| (必需,处理器对象数组)用于在索引之前对文档执行转换的处理器。 处理器按照指定的顺序依次运行。 |
| version | (可选,整数)外部系统用于跟踪摄取管道的版本号。 有关版本属性的使用方式,请参阅上面的 if_version 参数。 |
| _meta | (可选,对象)有关摄取管道的可选元数据。 可能有任何内容。 该 map 不是由 Elasticsearch 自动生成的。 |
| deprecated | (可选,布尔值)将此摄取管道标记为已弃用。 当创建或更新未弃用的索引模板时,将已弃用的摄取管道引用为默认或最终管道时,Elasticsearch 将发出弃用警告。 |

)







-NEON 介绍)




:多媒体)




