简介
QuestDB是一个开源的高性能时序数据库,专门用于处理时间序列相关的数据存储与查询;
QuestDB使用列式存储模型。数据存储在表中,每列存储在其自己的文件和其自己的本机格式中。新数据被附加到每列的底部,以便能够按照与摄取数据相同的顺序有机地检索数据。
随着业务快速发展,使得海量数据在传统关系型数据库上性能瓶颈问题,转移到QuestDB时序数据库上后得到性能的极大提升,解决了海量数据高性能快速读写与简易管理问题;
QuestDB能够支持快速增长的时间序列高基数数据,提供强大的极速查询性能,安装维护简单并兼容SQL语法,从而上手使用学习难度低,并且支持RestaApi数据摄取与查询接口,对系统应用服务开发提供良好支持,非常方便系统服务的集成开发与应用;QuestDB采用Java和C++ 从头开始构建,没有依赖项,零垃圾回收;
官方说明:
QuestDB 是一个专门研究 时间序列的开源列式数据库。它提供同类领先的摄取吞吐量和快速 SQL 查询,并且操作简单。QuestDB 有助于降低运营成本并克服摄取瓶颈,并且可以大大简化整体入口基础设施。凭借对 InfluxDB Line Protocol 和 PostgreSQL Wire Protocol 等摄取协议、第三方工具和语言客户端的广泛官方支持,可以快速启动。
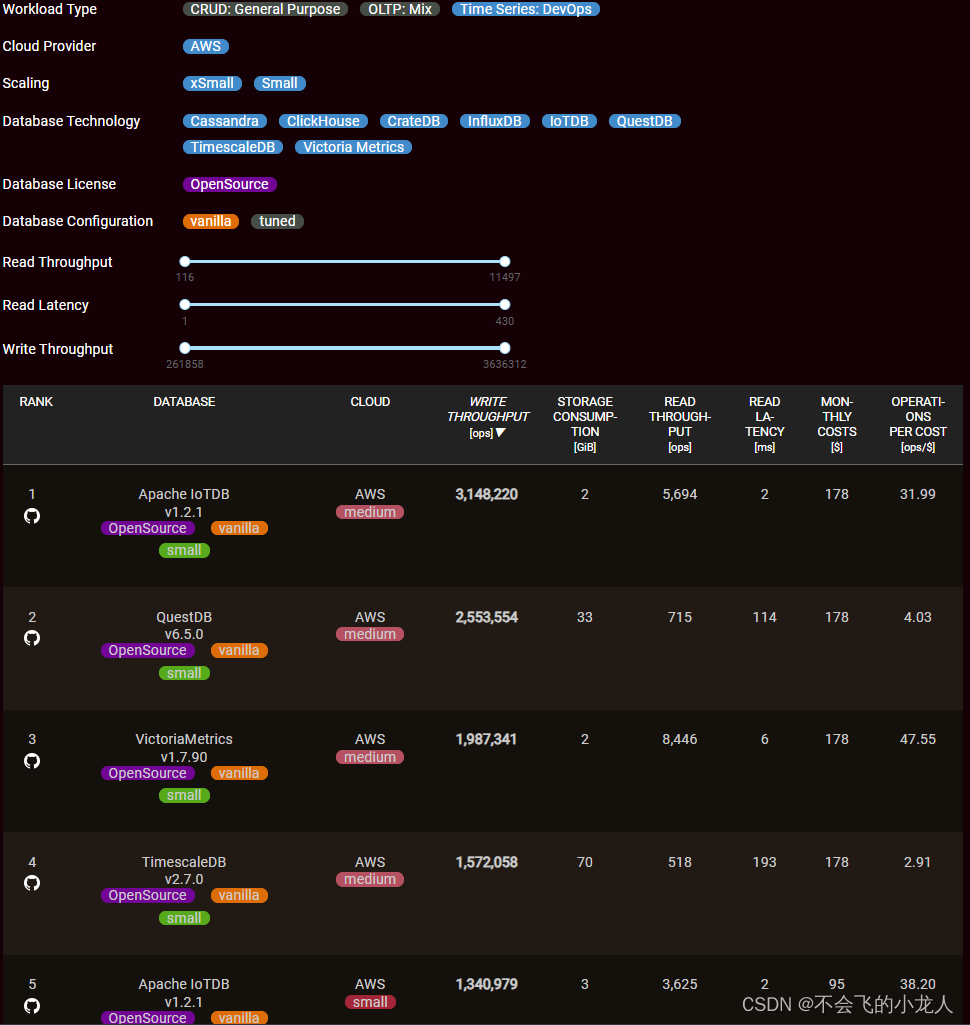
QuestDB在默认原生版本(vanilla)配置下,在知名数据库测试机构benchANT的时序数据库排行榜 Time Series: DevOps 场景写入吞吐量、存储占用、查询响应、成本效益等多项性能表现的第二名(本文编写时间前)。
benchANT 是国际知名的数据库评测机构,以可靠、独立及透明的方法对各种数据库进行性能评测。 benchANT 榜单收录了常见的关系型数据库、NoSQL 数据库、NewSQL 数据库及时序数据库等,通过使用固定的测试负载、相同的测试机器来保证测试结果的公平性。
榜单链接:https://benchant.com/de/ranking/datenbank-ranking
主要功能
1.大规模数据写入:默认使用4个线程,每秒处理速度接近100W行,有极强吞吐性能
2.支持SQL分析:支持SQL语法,可以采用PostgreSQL协议线路客户端查询数据
3.支持数据分区:支持自动对数据按时间进行分区存储,如按小时、天、周、月、年等;
4.提供web控制台:安装后可以在自带的WEB控制台界面管理数据表与数据
5.支持多种数据访问方式:提供基于http的RestAPI,无需集成驱动包;同时支持Postgres协议、InfluxDB协议数据传输;降低集成开发难度;支持csv数据导入;
6.支持多种时间序列SQL扩展:支持按时间间隔、时间范围、窗口时间排序、多表关联序列查询等扩展用法
更多功能请关注官网文档
安装与使用
官网地址:QuestDB | High performance time series
官网文档:Introduction | QuestDB
官方下载:Download QuestDB | QuestDB
github:https://github.com/questdb/questdb
linux环境安装
官方安装指南:Quick start | QuestDB
测试服务器硬件环境: CPU(E5-2609 v3 @ 1.90GHz) *8核,内存*16G,硬盘 > 70G
#下载安装包
wget https://github.com/questdb/questdb/releases/download/7.3.7/questdb-7.3.7-rt-linux-amd64.tar.gz
#解压包
tar -zxvf questdb-7.3.7-rt-linux-amd64.tar.gz
#移动目录
mv questdb-7.3.7-rt-linux-amd64 /opt/questdb-7.3.7
#进入目录
cd /opt/questdb-7.3.7
#创建数据目录
mkdir -p data
#启动数据库
./bin/questdb.sh start -d ./data -t questdb
#查询数据库状态
./bin/questdb.sh status -d ./data
#关闭数据库
./bin/questdb.sh stop -d ./data -t questdb注意:此处安装开源版本是以单机部署;只有企业版才支持集群、权限管理等功能;
访问WEB控制台
QuestDB提供了WebUI版的控制台客户端界面,可通过IP+端口在浏览器中访问,如:http://localhost:9000
启动后QuestDB会启动如下端口:
- 9000:REST API和 Web 控制台
- 9009:InfluxDB线路协议
- 8812:Postgres 有线协议
- 9003:最小健康服务器
注:相关端口与配置可通过 questdb-7.3.7/data/conf/server.conf 中进行更改;
基础使用
官方提供了几个场景类型的示例数据,如:天气、金融等示例数据集;
官方示例数据:https://github.com/questdb/sample-datasets
示例数据集
该数据集约160K行,为美国芝加哥气象站传感器数据;
示例数据:https://github.com/questdb/sample-datasets/tree/main/chicago_sensors
下载:https://github.com/questdb/sample-datasets/blob/main/chicago_sensors/chicago_weather_stations.csv
创建数据表
注意:questDb没有database数据库独立实例,默认为qdb,因此只需要建数据表即可;
CREATE TABLE IF NOT EXISTS chicago_weather_stations (MeasurementTimestamp TIMESTAMP,StationName SYMBOL,AirTemperature DOUBLE,WetBulbTemperature DOUBLE,Humidity INT,RainIntensity DOUBLE,IntervalRain DOUBLE,TotalRain DOUBLE,PrecipitationType INT,WindDirection INT,WindSpeed DOUBLE,MaximumWindSpeed DOUBLE,BarometricPressure DOUBLE,SolarRadiation INT,Heading INT,BatteryLife DOUBLE,MeasurementTimestampLabel STRING,MeasurementID STRING
) timestamp(MeasurementTimestamp) PARTITION BY MONTH WAL
DEDUP UPSERT KEYS(MeasurementTimestamp, StationName);简要说明:MeasurementTimestamp为数据库引擎时序分区字段,此表需要基于MONTH(月)时间分区,必需要有timestamp字段以进行数据写入时自动表分区;

导入csv数据集
curl -F data=@chicago_water_sensors.csv "http://localhost:9000/imp?name=chicago_water_sensors"
SQL演示
官方文档提供了大量SQL使用说明,参阅:SQL execution order | QuestDB
在官方的建议里,一旦创建数据表后,尽可能不要改变表结构,因为大量数据分区存储后,会在变更表过程中造成较大的性能开销,和冷热数据处理;
本章描述几个常见SQL用法;
创建表
-- 创建表,IF NOT EXISTS 如果表不存在则创建;
-- PARTITION BY MONTH 表示按MONTH(月)分区存储;
-- WAL表示支持预写入内存再刷新到磁盘,用于数据并发写入;
CREATE TABLE IF NOT EXISTS test_demo (
id INT,
name STRING,
value STRING,
ts TIMESTAMP
) TIMESTAMP(ts) PARTITION BY MONTH WAL;增改查
-- 插入
INSERT INTO test_demo (id, name, value ,ts) VALUES(100,'test','abc', to_timestamp('2023-12-30T00:00:00', 'yyyy-MM-ddTHH:mm:ss'));
INSERT INTO test_demo (id, name, value ,ts) VALUES(101,'test','abc', now());
-- 更改(在questdb表中所有数据落库后,尽量不要update改变记录,目前不提供表记录删除,但支持清空表)
update test_demo set id=102 where ts = to_timestamp('2023-12-30T00:00:00', 'yyyy-MM-ddTHH:mm:ss')
-- 查询
select * from test_demo表删除
-- 删除表指定月分区
ALTER TABLE test_demo DROP PARTITION LIST '2013-12';
-- 清空表(截断)
TRUNCATE TABLE test_demo
-- 删除表
DROP TABLE test_demoshow用法
-- 显示所有表
SHOW TABLES;
-- 显示指定表字段
SHOW COLUMNS FROM test_demo;
-- 显示指定表分区
SHOW PARTITIONS FROM test_demo;
-- 显示参数
SHOW PARAMETERS;
-- 显示版本
SHOW SERVER_VERSION;开发测试
本示例项目依赖Maven + JDK17,此处不再单独描述创建项目过程,请自行准备运行环境与工程;
开发环境硬件:CPU (I5-7500 3.40GHz) * 4核,内存 * 24G
RestAPI请求
QuestDB支持REST API开发模式,可基于标准HTTP功能响应请求,因此可通过http客户端访问。
java示例
package com.example.questdb.restapi;import org.junit.jupiter.api.Test;
import java.net.URI;
import java.net.URLEncoder;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.nio.charset.StandardCharsets;
/*** @Description 通过questDb的restApi接口执行sql脚本* @Version V1.0*/
public class HttpTest {//查询@Testpublic void query() throws Exception {java.net.http.HttpClient client = java.net.http.HttpClient.newHttpClient();String url = "http://192.168.1.3:9000/exec?";//URL 编码的查询文本String queryStr = "query=" + URLEncoder.encode("select * from test_demo", StandardCharsets.UTF_8);//计算行数并返回该值String countStr = "&count=true";//返回前多少行String limitStr = "&limit=2";//拼装url = url + queryStr + countStr + limitStr;System.out.println("请求:" + url);HttpRequest request = HttpRequest.newBuilder().uri(new URI(url)).header("Content-Type", "application/x-www-form-urlencoded;charset=utf-8").header("Statement-Timeout", "5000").GET().build();HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());String body = response.body();System.out.println("响应:" + body);}//插入@Testpublic void insert() throws Exception {java.net.http.HttpClient client = java.net.http.HttpClient.newHttpClient();String url = "http://192.168.1.3:9000/exec?";//URL 编码的查询文本String queryStr = "query=" + URLEncoder.encode("INSERT INTO test_demo (id, name, value ,ts) VALUES(104,'test','abc', now())", StandardCharsets.UTF_8);url = url + queryStr;System.out.println("请求:" + url);HttpRequest request = HttpRequest.newBuilder().uri(new URI(url)).header("Content-Type", "application/x-www-form-urlencoded;charset=utf-8").header("Statement-Timeout", "5000").GET().build();HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());String body = response.body();System.out.println("响应:" + body);}//更改@Testpublic void update() throws Exception {java.net.http.HttpClient client = java.net.http.HttpClient.newHttpClient();String url = "http://192.168.1.3:9000/exec?";//URL 编码的查询文本String queryStr = "query=" + URLEncoder.encode("UPDATE test_demo SET name='test4' WHERE id=104", StandardCharsets.UTF_8);url = url + queryStr;System.out.println("请求:" + url);HttpRequest request = HttpRequest.newBuilder().uri(new URI(url)).header("Content-Type", "application/x-www-form-urlencoded;charset=utf-8").header("Statement-Timeout", "5000").GET().build();HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());String body = response.body();System.out.println("响应:" + body);}
}数据表记录
InfluxDB协议
QuestDB TCP接收器使用 InfluxDB 线路协议作为序列化和传输格式。另一方面,InfluxDB使用HTTP协议作为传输,QuestDB主要使用InfluxDB线路协议作为数据序列化格式。因此,现有的InfluxDB客户端库将无法与QuestDB一起使用,必需使用QuestDB官方java驱动包。
pom导入包
<dependency><groupId>org.questdb</groupId><artifactId>questdb</artifactId><version>7.3.7</version>
</dependency>java测试示例
package com.example.questdb.influxdb;import io.questdb.client.Sender;
import org.junit.jupiter.api.Test;
import java.time.temporal.ChronoUnit;
/*** @Description QuestDB可基于InfluxDB协议通过tcp高性能提交数据* https://questdb.io/docs/reference/clients/java_ilp/* @Version V1.0*/
public class InfluxDBTest {//仅支持数据插入,不支持查询与更新@Testpublic void insert(){try (Sender sender = Sender.builder().address("192.168.1.3:9009").build()) {long times = System.currentTimeMillis();//如果表不存在,则自动创建,并且 InfluxDB Line Protocol协议发送数据是基于PARTITION BY DAY分区sender.table("test_demo").longColumn("id", 103).stringColumn("name", "influxDBTest").stringColumn("value", "abc").at(times, ChronoUnit.MILLIS);sender.close();}}
}数据表记录

Postgre协议
QuestDB支持Postgres传输协议。因此,QuestDB能够运行大多数Postgres查询。这意味着您可以将您最喜欢的Postgres客户端或驱动程序与QuestDB结合使用,无需额外成本。
注意:Postgres使用的存储模型与QuestDB使用的存储模型根本不同,因此Postgres的某些功能不适用于QuestDB。
pom导入包
<dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.6.0</version>
</dependency>java示例
package com.example.questdb.postgres;import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import java.sql.*;
import java.util.Properties;
/*** @Description QuestDB支持Postgres协议运行SQL脚本* https://questdb.io/docs/reference/api/postgres/* @Version V1.0*/
public class PostgresTest {static Properties properties = new Properties();static Connection connection;//初始化连接@BeforeAllpublic static void init() throws Exception {//默认adminproperties.setProperty("user", "admin");//默认questproperties.setProperty("password", "quest");//禁用ssl,不支持ssl协议properties.setProperty("sslmode", "disable");//默认数据库qdbconnection = DriverManager.getConnection("jdbc:postgresql://192.168.1.3:8812/qdb", properties);}//插入数据@Testpublic void insert() throws Exception {connection.setAutoCommit(false);try (PreparedStatement preparedStatement = connection.prepareStatement("INSERT INTO test_demo (id, name, value ,ts) VALUES (?, ?, ?, ?)")) {preparedStatement.setInt(1, 104);preparedStatement.setString(2, "postgresTest");preparedStatement.setString(3, "abc");preparedStatement.setTimestamp(4, new Timestamp(System.currentTimeMillis()));preparedStatement.execute();}connection.commit();connection.close();}//查询数据@Testpublic void select() throws Exception {try (PreparedStatement preparedStatement = connection.prepareStatement("SELECT * FROM test_demo")) {try (ResultSet rs = preparedStatement.executeQuery()) {while (rs.next()) {System.out.println(rs.getObject(1));System.out.println(rs.getObject(2));System.out.println(rs.getObject(3));System.out.println(rs.getObject(4));System.out.println("------------------------------------");}}connection.close();}}//更新数据@Testpublic void update() throws Exception {try (PreparedStatement preparedStatement = connection.prepareStatement("UPDATE test_demo SET name='postgresTest5' WHERE id=104")) {preparedStatement.execute();}connection.close();}
}数据表记录

性能测试
QuestDB可以基于InfluxDB协议实现大批量数据高吞吐插入;
本示例通模拟过将约3亿条各城市10年的气象数据,通过InfluxDB协议快速插入到QuestDB数据表中,在基于此规模数据的存储表上进行SQL查询与聚合性能测试;
创建数据表
CREATE TABLE IF NOT EXISTS weather_behavior (
city SYMBOL,
site STRING,
air INT,
temperature DOUBLE,
humidity INT,
windLevel INT,
createTime TIMESTAMP
) TIMESTAMP(createTime) PARTITION BY MONTH WAL;createTime为时间序列字段,基于时间序列创建月度分区存储数据,并开启WAL预写入,提升多线程下并发请求能力;
InfluxDB写入示例
使用java开发,基于influxDB协议将数据写入questDB表,开发前请在pom.xml中配置questdb-7.3.7包引入;
java示例
package com.example.questdb;import io.questdb.client.Sender;
import org.apache.commons.lang3.RandomUtils;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.lang3.time.DateUtils;
import java.math.BigDecimal;
import java.time.Instant;
import java.time.temporal.ChronoUnit;
import java.util.Calendar;
import java.util.Date;
/*** @Description 向questdb发送模拟各省市的天气采集数据* @Version V1.0*/
public class WeatherToQuestdbExample {static String cityNames = "海门,鄂尔多斯,招远,舟山,齐齐哈尔,盐城,赤峰,青岛,乳山,金昌,泉州,莱西,日照,胶南,南通,拉萨," +"云浮,梅州,文登,上海,攀枝花,威海,承德,厦门,汕尾,潮州,丹东,太仓,曲靖,烟台,福州,瓦房店,即墨,抚顺,玉溪,张家口," +"阳泉,莱州,湖州,汕头,昆山,宁波,湛江,揭阳,荣成,连云港,葫芦岛,常熟,东莞,河源,淮安,泰州,南宁,营口,惠州,江阴,蓬莱," +"韶关,嘉峪关,广州,延安,太原,清远,中山,昆明,寿光,盘锦,长治,深圳,珠海,宿迁,咸阳,铜川,平度,佛山,海口,江门,章丘," +"肇庆,大连,临汾,吴江,石嘴山,沈阳,苏州,茂名,嘉兴,长春,胶州,银川,张家港,三门峡,锦州,南昌,柳州,三亚,自贡,吉林," +"阳江,泸州,西宁,宜宾,呼和浩特,成都,大同,镇江,桂林,张家界,宜兴,北海,西安,金坛,东营,牡丹江,遵义,绍兴,扬州,常州," +"潍坊,重庆,台州,南京,滨州,贵阳,无锡,本溪,克拉玛依,渭南,马鞍山,宝鸡,焦作,句容,北京,徐州,衡水,包头,绵阳,乌鲁木齐," +"枣庄,杭州,淄博,鞍山,溧阳,库尔勒,安阳,开封,济南,德阳,温州,九江,邯郸,临安,兰州,沧州,临沂,南充,天津,富阳,泰安," +"诸暨,郑州,哈尔滨,聊城,芜湖,唐山,平顶山,邢台,德州,济宁,荆州,宜昌,义乌,丽水,洛阳,秦皇岛,株洲,石家庄,莱芜,常德," +"保定,湘潭,金华,岳阳,长沙,衢州,廊坊,菏泽,合肥,武汉,大庆";/*** 主程入口* questdb参考:https://questdb.io/docs/reference/clients/java_ilp/* 注意:客户端仅支持 TCP。它不支持UDP作为传输。* @param args*/public static void main(String[] args) throws Exception {//生产者发送消息Sender sender = Sender.builder().address("192.168.110.36:9009").build();String table = "weather_behavior";String [] citys = StringUtils.split(cityNames, ",");long i = 1;System.out.println("开始执行数据导入,time:" + new Date());//从指定时间开始生成10年的假数据,10年约315532800秒,模拟每秒产生1条数据,平均每天产生86400条,一年约3153万条,起始时间:2014-01-01 00:00:00,结束时间:2024-01-01 00:00:00Date dateTime = DateUtils.parseDate("2014-01-01 00:00:00", "yyyy-MM-dd HH:mm:ss");java.util.Calendar calendar = Calendar.getInstance();calendar.setTime(dateTime);while(true){String city = citys[RandomUtils.nextInt(0, citys.length)] ;String site = String.format("%s-%s",city,RandomUtils.nextInt(0, 100));int air = RandomUtils.nextInt(10, 200);double temperature = RandomUtils.nextDouble(0.0, 40.00);BigDecimal temperatureBig = new BigDecimal(temperature);temperature = temperatureBig.setScale(2, BigDecimal.ROUND_HALF_UP).doubleValue();int humidity = 0;int windLevel = 0;if (temperature<0){humidity = RandomUtils.nextInt(0, 5);windLevel = RandomUtils.nextInt(0, 6);}else if (temperature>0 && temperature<15){humidity = RandomUtils.nextInt(5, 25);windLevel = RandomUtils.nextInt(0, 8);} else {humidity = RandomUtils.nextInt(25, 75);windLevel = RandomUtils.nextInt(0, 10);}//每循环递增1秒calendar.add(Calendar.SECOND, 1);//向questdb发送数据:地市,站点,PM2.5,温度,湿度,风速,采集时间sender.table(table)//symbol索引字段.symbol("city", city)//string UTF-16 编码字符的长度前缀序列,其长度存储为带符号的 32 位整数.stringColumn("site", site)//long 有符号整数,pm2.5 = 0~250.longColumn("air", air)//double 双精度 IEEE 754 浮点值。.doubleColumn("temperature", temperature).longColumn("humidity", humidity).longColumn("windLevel", windLevel)//设置分区数据时间戳取系统纳秒//.at(System.nanoTime(), ChronoUnit.NANOS);//指定业务时间.at(calendar.getTimeInMillis(), ChronoUnit.MILLIS);//每5000行提交一次if (i % 5000 == 0) {sender.flush();}//当达到10年总秒数,则退出if (i >= 315532800) {break;}i ++ ;}sender.close();System.out.println("批量数据导入成功,time:" + new Date());}
}写入性能测试
IDEA控制台打印日志,单线程循环插入3亿多条记录,
每5000条批量提交一次,累计用时:12分52秒( 772s);平均每秒:315532800记录 / 772s用时 = 约408721记录(s);
略 ...
2024-01-04T11:50:45.215547Z I i.q.c.l.t.PlainTcpLineChannel Send buffer size change from 65536 to 131072
开始执行数据导入,time:Thu Jan 04 19:50:47 CST 2024
批量数据导入成功,time:Thu Jan 04 20:03:39 CST 2024
略 ... 从统计数据上来看,通过InfluxDB协议写入QuestDB性能极强,如果客户端是多线程写入,相信性能还会有一定提升;
在写入QuestDB所在服务器(虚拟机)为8核 CPU+16G内存,在大量写入过程中,CUP使用率较高均值在70%左右,内存使用比较少并且无较大波动,Java进程大约在1G上下(QuestDB采用Java和C++开发);
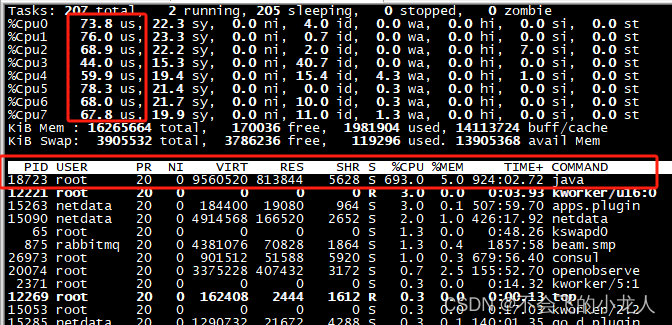
未插入数据前服务器磁盘空间已用为16G;
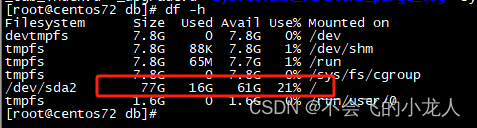
数据入表后磁盘空间已使用了51G,3亿数据增长了35G,推测questDB数据存储文件未做压缩,因此个人觉得占用磁盘空间偏大;

SQL查询与聚合
统计全表数量,查询已入库记录315532800条(3亿)多条
select count(1) from weather_behavior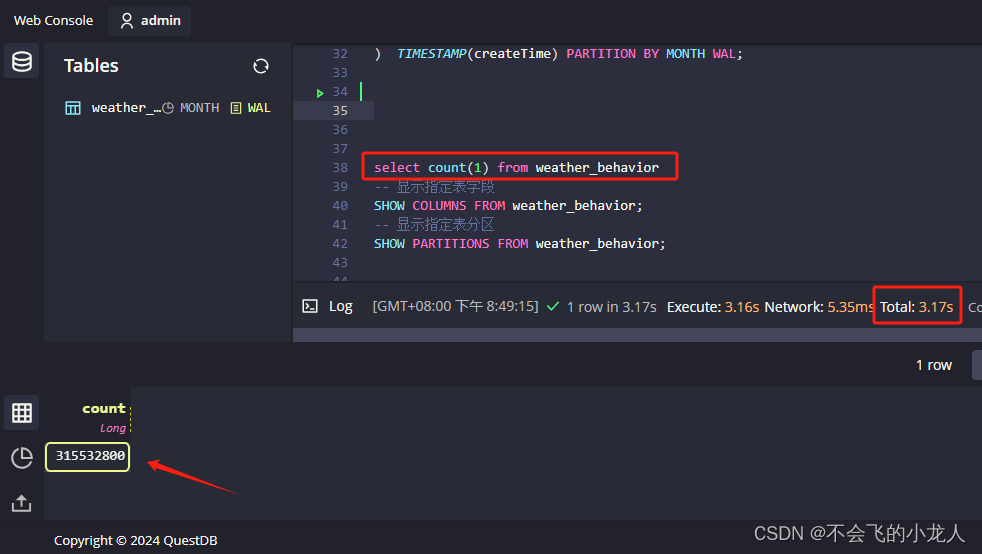
按月建立分区后,查询分区信息,总共121个分区
SHOW PARTITIONS FROM weather_behavior;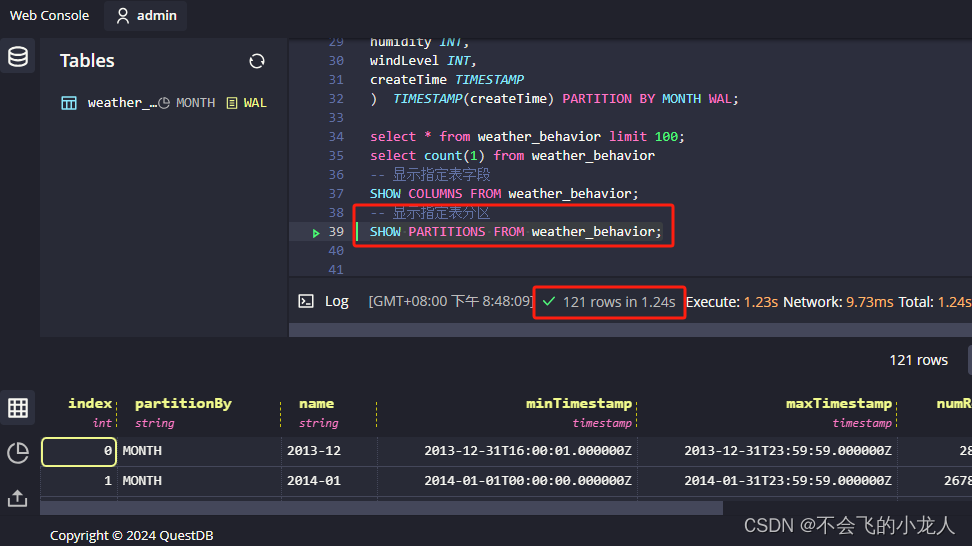
查询pm大于150的城市上报次数
select city,count(1) from weather_behavior where air>=150 group by city limit 100;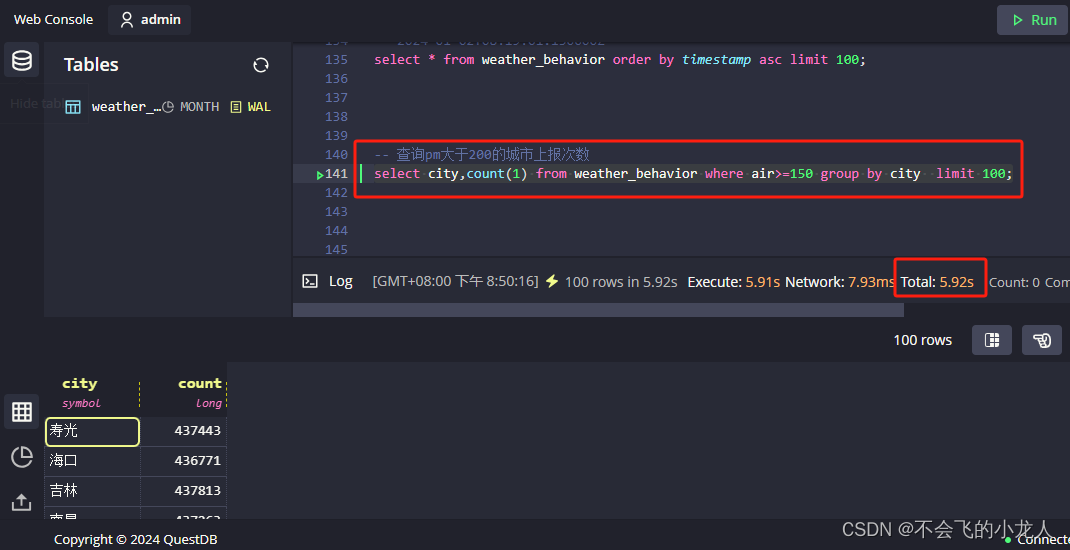
查询2022年全年pm大于150的城市上报次数(前100条)
select city,count(1) as upNum from weather_behavior
where air>=150 and
createTime >= to_timestamp('2022-12-31T16:00:00', 'yyyy-MM-ddTHH:mm:ss') and createTime <= to_timestamp('2023-12-31T15:59:59', 'yyyy-MM-ddTHH:mm:ss')
group by city order by upNum desc limit 100;
查询2022年全年上报最多top100的城市(前100条)
select city,count(1) as upNum from weather_behavior
where createTime >= to_timestamp('2022-12-31T16:00:00', 'yyyy-MM-ddTHH:mm:ss') and createTime <= to_timestamp('2023-12-31T15:59:59', 'yyyy-MM-ddTHH:mm:ss')
group by city order by upNum desc limit 100;
注:因该命中了questDB数据缓存分区,所以重复执行对2022年数据做聚合统计时,速度极快;
查询2022年全年pm最大值top100的城市(前100条)
select city,max(air) as aitNum from weather_behavior
where createTime >= to_timestamp('2022-12-31T16:00:00', 'yyyy-MM-ddTHH:mm:ss') and createTime <= to_timestamp('2023-12-31T15:59:59', 'yyyy-MM-ddTHH:mm:ss')
group by city order by aitNum desc limit 10;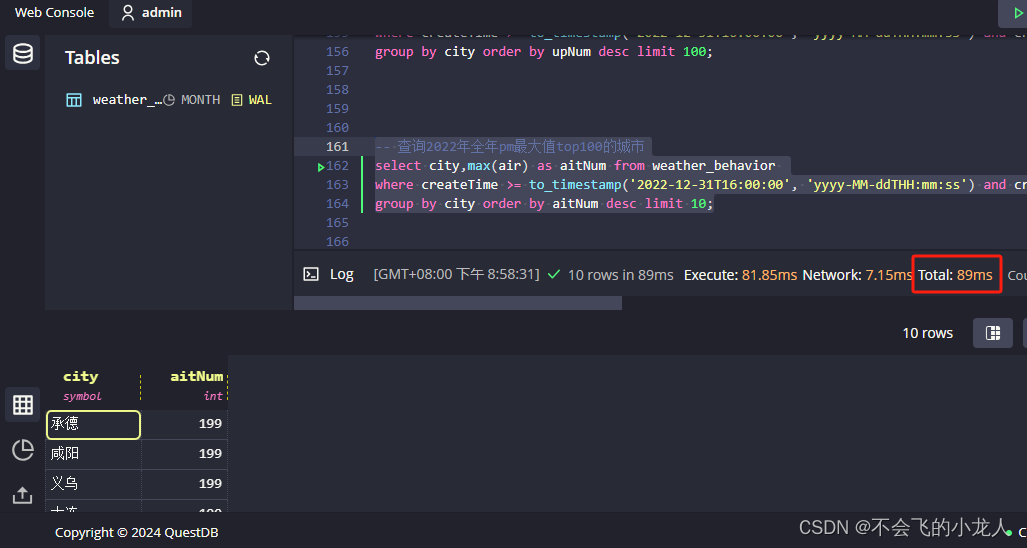
按2022年全年pm排名查询topN条记录,条件:每城市只取站点排名第一(前100条)
select * from (
select city, site,maxnum,row_number() OVER (partition by city order by maxnum desc) as ranking from (
select city, site, max(air) as maxnum from weather_behavior
where createTime >= to_timestamp('2022-12-31T16:00:00', 'yyyy-MM-ddTHH:mm:ss') and createTime <= to_timestamp('2023-12-31T15:59:59', 'yyyy-MM-ddTHH:mm:ss')
group by city,site
) tt ) ttt where ranking<2 order by city limit 100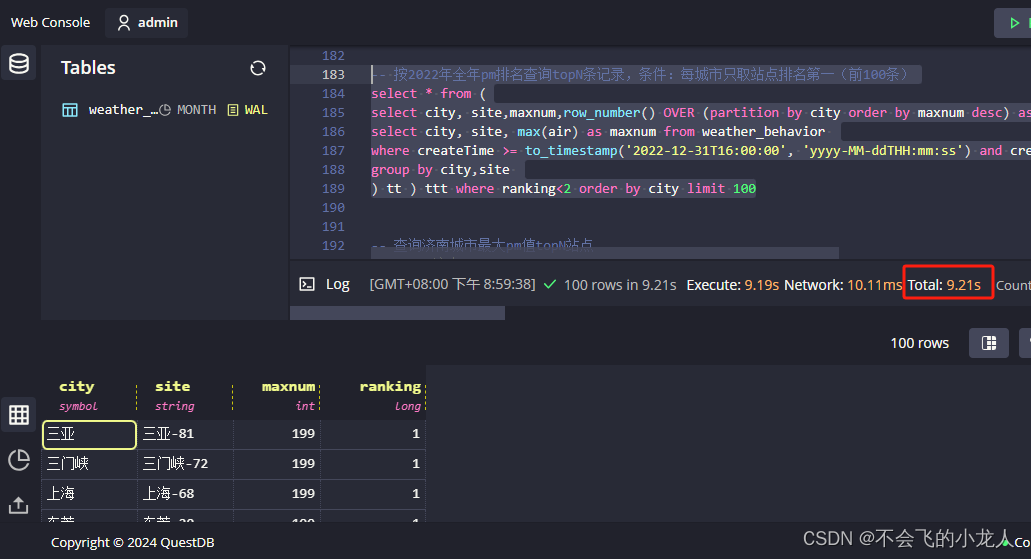
按2022年全年计算指定城市每个月的PM2.5的最大值,最小值,平均值,总值,总记录数,月度排名,以及每个月递增的平均总记录数、月递增的平均值
select month,city,maxAir,minAir,avgAir,sumAir,airCount,
row_number() OVER (partition by city order by avgAir desc) as ranking,
avg(airCount) over (PARTITION BY city ORDER BY month) moving_air_count,
avg(avgAir) over (PARTITION BY city ORDER BY month) moving_avg_air
from (select
city,max(air) as maxAir, min(air) as minAir,avg(air) as avgAir, sum(air) as sumAir, count(1) as airCount, date_trunc('month', dateadd('h', 8, createTime)) month
from weather_behavior where city='济南' and
createTime >= to_timestamp('2022-12-31T16:00:00', 'yyyy-MM-ddTHH:mm:ss') and createTime <= to_timestamp('2023-12-31T15:59:59', 'yyyy-MM-ddTHH:mm:ss')
group by city,month
) tt order by month desc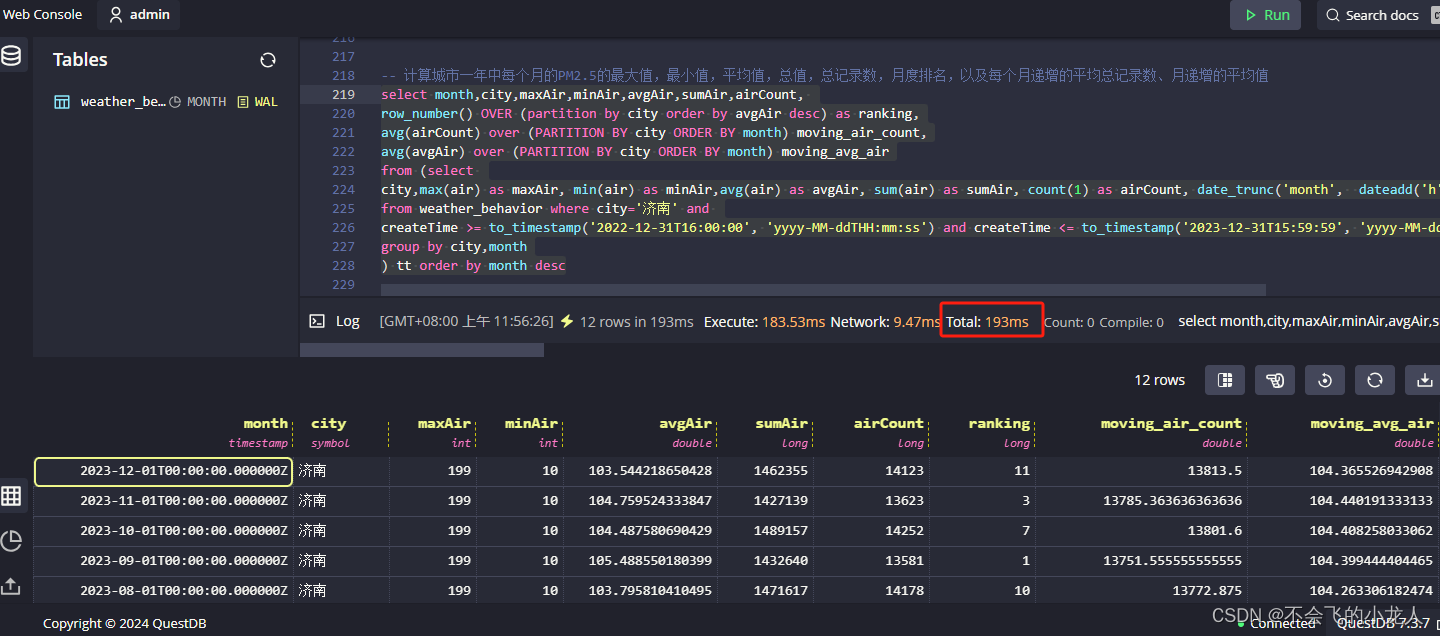
查询城市济南10年中每年的PM2.5的最大值,最小值,平均值,总值,总记录数(查全表3亿多条)
select
city,max(air) as maxAir, min(air) as minAir,avg(air) as avgAir, sum(air) as sumAir, count(1) as airCount, date_trunc('year', dateadd('h', 8, createTime)) as year
from weather_behavior where city='济南'
group by city,year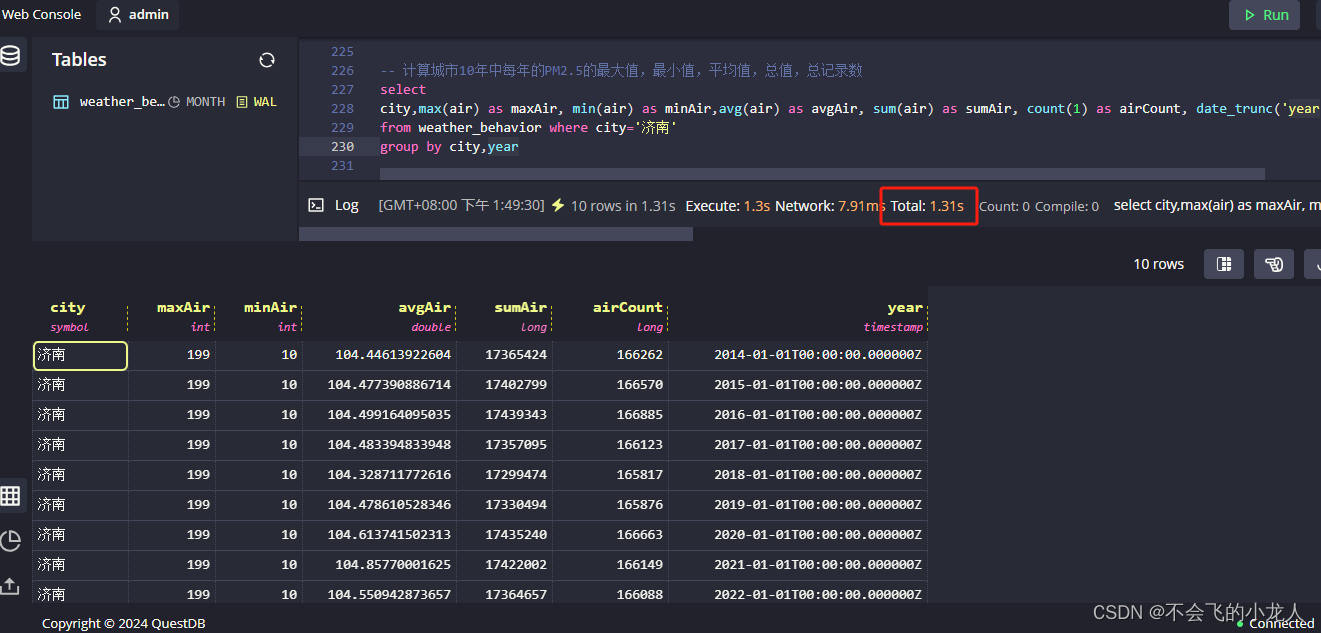
总结
QuestDB开箱即用,没有什么安装配置难度,官方文档编写详细易懂(纯英文,用插件翻译即可),学习与使用曲线低,很容易上手;QuestDB在性能方面有极强的优势,吞吐量大,数据写入速度快,基于InfuluxDB线路协议写入性能最佳,默认设置下可以达到每秒约40W条(本示例硬件条件下,不同环境可能会存在差异),PostgreSQL协议则最贴合项目开发过程中使用SQL语法,基于http请求则无需额外驱动包集成从而简化使用成本,因此可以根据业务需要与性能选择不同的技术方案;在基于时间维度建立分区后,存储的大量数据按时间序例,拆分存储在不同分区内,支持按小时、天、周、月、年建立分区,数据写入过程中按分区时间字段自动存储在时间维度分区中;在大规模数据下基于时间序例条件查询数据,查询速度快,如:在单表约3亿数据存储(121个月分区)规模上,按某一年度范围查询基本上在1秒以内响应,全表搜索并进行复杂聚合统计约在10秒内响应;因此在大规模存储数据下,相对于传统事务型数据库来说,有着跨越式的性能差距;可应用在历史数据存储、高基数时间序列等场景,如:监控指标数据、日志数据、历史订单数据、用户行为明细数据、物联网数据、游戏上报数据、业务备份数据等,适用于写入到表里后不在频繁变更以及基于时间序例追溯的数据;
QuestDB在使用过程中,也存一些限制与不足,如:权限管理、支持对象存储、高可用集群等部份功能需要企业授权版才能支持,社区开源免费版不提供以上功能,因此使用者需要根据实际情况选择QuestDB版本;根据个人的体验,单实例运行性能是最好的,无需考虑集群过程中的数据交付与节点通讯等性能开销与维护事项,在中小企业中,如果不涉及到大量高并发查询使用(每次查询会使用较多硬件资源,高并发下会超成资源竞争,降低查询性能),在足够大的磁盘空间与合理的内存、CPU、分区等软硬件条件下,社区开源版已足够支持TB级的数据交付使用;QuestDB在对SQL的兼容性上已经能覆盖大部份标准查询,但可能还存在部份语法不能满足(使用过程中有遇到,未做详细记录),基本SQL开发是足够使用的;QuestDB不支持表行级数据delete删除操作,QuestDB则采取删除分区的方式来删除数据,不适用数据细颗粒度管理,官方建议数据一旦入库尽量不在做更新;
更多使用体验与学习,请参考官方网站资源;



)

 和 count(*) 区别是什么?)

![[小脚本] maya 命令行常用操作](http://pic.xiahunao.cn/[小脚本] maya 命令行常用操作)



)
: 资源加载和网络栈)






