项目结构:
1.1 Insert方法
// 插入一条记录
// T 就是要插入的实体对象
// 默认主键生成策略为雪花算法(后面讲解)
//返回值是影响条数
int insert(T entity);
1.2 Delete方法
// 根据 entity 条件,删除记录
int delete(@Param(Constants.WRAPPER) Wrapper<T> wrapper);// 删除(根据ID 批量删除)
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);// 根据 ID 删除
int deleteById(Serializable id);// 根据 columnMap 条件,删除记录
int deleteByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);

何为Wrapper wrapper ?
执行语句时我们可能存在多个条件,例如同时要求年龄大于18,且为女生,此时把多个条件封装进其中,本质就是一个条件封装对象
何为Map<String,Object> ?
与Wrapper很相似 , 可以将 age =18 , sex = 1装入Map中 , 即封装多个键值对
Map map = new HashMap();
map.put("age",20);
int rows = userMapper.deleteByMap(map);
1.3 Update方法
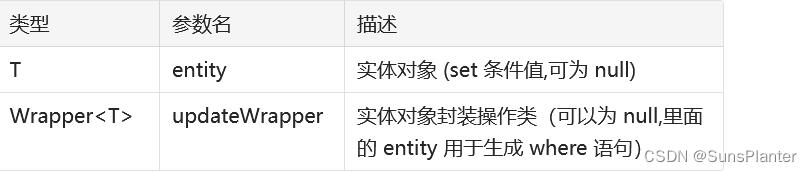
// 第一个参数是要改的实体 , 第二个条件是判断的参数 ,根据 whereWrapper 条件,更新记录
int update(@Param(Constants.ENTITY) T updateEntity, @Param(Constants.WRAPPER) Wrapper<T> whereWrapper);// 根据 ID 修改 主键属性必须存在
int updateById(@Param(Constants.ENTITY) T entity);
//updateById,根据传入对象的主键值去更新剩余值
User user = new User();
user.setId(1L);
user.setAge(19);
//等价于 update user set age = 30 where id = 1
int rows = userMapper.updateById(user);//update
User user = new User();
user.setAge(22);
//等价于 update user set age = 22 ,省略了判断条件,更新所有行的age为22
int rows = userMapper.update(user,null);
1.4 Select方法
// 根据 ID 查询
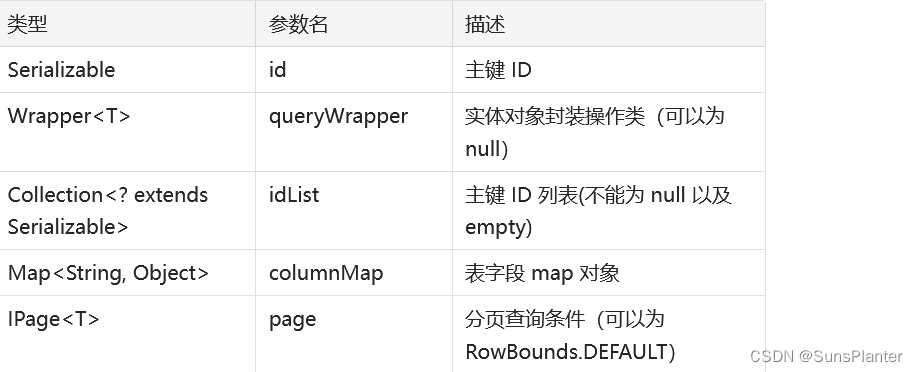
T selectById(Serializable id);// 根据 entity 条件,查询一条记录
T selectOne(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 查询(根据ID 批量查询)
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);// 根据 entity 条件,查询全部记录
List<T> selectList(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 查询(根据 columnMap 条件)
List<T> selectByMap(@Param(Constants.COLUMN_MAP) Map<String, Object> columnMap);// 根据 Wrapper 条件,查询全部记录
List<Map<String, Object>> selectMaps(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 根据 Wrapper 条件,查询全部记录。注意: 只返回第一个字段的值
List<Object> selectObjs(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 根据 entity 条件,查询全部记录(并翻页)
IPage<T> selectPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 根据 Wrapper 条件,查询全部记录(并翻页)
IPage<Map<String, Object>> selectMapsPage(IPage<T> page, @Param(Constants.WRAPPER) Wrapper<T> queryWrapper);// 根据 Wrapper 条件,查询总记录数
Integer selectCount(@Param(Constants.WRAPPER) Wrapper<T> queryWrapper);
1.5 自定义查询方法
如上所述,MP只为我们定义了单表的很多查询方法,如果是单表的一些特殊查询,亦或是多表查询,就需要自己编写语句了,方法如下:
在application.yaml中声明MP的默认mapperxml位置
mybatis-plus: # mybatis-plus的配置# 默认位置 private String[] mapperLocations = new String[]{"classpath*:/mapper/**/*.xml"}; mapper-locations: classpath:/mapper/*.xml
自定义mapper方法:
package com.sunsplanter.mapper
public interface UserMapper extends BaseMapper<User> {//正常自定义方法!//可以使用注解@Select或者mapper.xml实现List<User> queryAll();
}
基于mapper.xml实现:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""https://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namespace = 接口的全限定符 -->
<mapper namespace="com.sunsplanter.mapper.UserMapper"><select id="queryAll" resultType="user" >select * from user</select>
</mapper>
2 基于Service接口实现CRUD
原本 , service层提供逻辑服务 , 具体接触数据库由mapper实现:
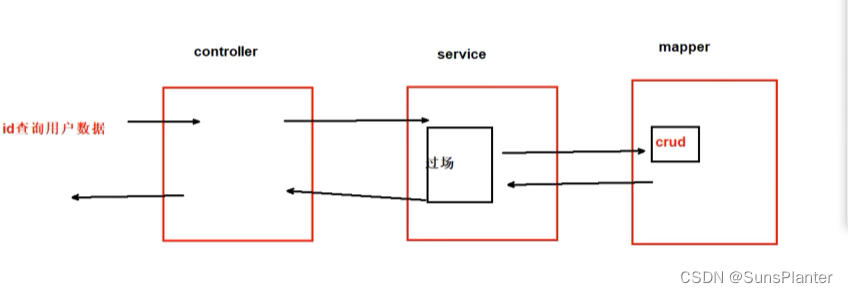
现在 , 在service中也增加访问数据库的方式 , 于是 , 对于一些简单的项目(例如无需业务逻辑) , 就没必要再写mapper.
2.1 对比Mapper接口CRUD区别:
- service添加了批量方法
- service层的方法自动添加事务
2.2 使用Iservice接口方式
通用 Service CRUD 封装IService 接口,进一步封装 CRUD。采用 get 查询单行 remove 删除 list 查询集合 page 分页 前缀命名方式区分 Mapper 层避免混淆,
定义一个UserService接口继承IService接口
//IService中包含了很多CRUD方法 , 只要指定实体类泛型即可
public interface UserService extends IService<User> {}
定义一个UserServiceImpl类继承ServiceImpl实现类+实现UserService接口,获得完整的CRUD方法
@Service
//在继承了ServiceImpl的同时实现了UserService接口
//实现了UserService,而UserService继承自IService, IService实现了一半的CRUD,故实现UserService接口即可获得一半的CRUD
//继承了SericeImpl,获得另一半的CRUD方法
//ServiceImpl第一个参数为继承自BaseMapper的xxxMapper,第二个参数为实体对象
public class UserServiceImpl extends ServiceImpl<UserMapper,User> implements UserService{}
public interface UserMapper extends BaseMapper<User> {//之前,mapper接口内要声明抽象方法,然后再mapper.xml中具体写查询语句//List<User> queryAll();//现在,继承自BaseMapper,其内已定义了几乎所有单表查询语句//故UserMapper也拥有了这些方法,无需再写
}
结构如图,在test中编写测试方法.
2.3 CRUD方法介绍
保存:
// 插入一条记录(选择字段,策略插入)
boolean save(T entity);
// 插入(批量)
boolean saveBatch(Collection<T> entityList);
// 插入(批量)
boolean saveBatch(Collection<T> entityList, int batchSize);//修改或者保存:
// 查询该entity的id去数据库中查询,如果存在对应的表项则更新,否则插入
boolean saveOrUpdate(T entity);
// 根据updateWrapper尝试更新,否继续执行saveOrUpdate(T)方法
boolean saveOrUpdate(T entity, Wrapper<T> updateWrapper);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList);
// 批量修改插入
boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize);移除:
// 根据 queryWrapper 设置的条件,删除记录
boolean remove(Wrapper<T> queryWrapper);
// 根据 ID 删除
boolean removeById(Serializable id);
// 根据 columnMap 条件,删除记录
boolean removeByMap(Map<String, Object> columnMap);
// 删除(根据ID 批量删除)
boolean removeByIds(Collection<? extends Serializable> idList);更新:
// 根据 UpdateWrapper 条件,更新记录 需要设置sqlset
boolean update(Wrapper<T> updateWrapper);
// 根据 whereWrapper 条件,更新记录
boolean update(T updateEntity, Wrapper<T> whereWrapper);
// 根据 ID 选择修改
boolean updateById(T entity);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList);
// 根据ID 批量更新
boolean updateBatchById(Collection<T> entityList, int batchSize);数量:
// 查询总记录数
int count();
// 根据 Wrapper 条件,查询总记录数
int count(Wrapper<T> queryWrapper);查询:
// 根据 ID 查询
T getById(Serializable id);
// 根据 Wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last("LIMIT 1")
T getOne(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
T getOne(Wrapper<T> queryWrapper, boolean throwEx);
// 根据 Wrapper,查询一条记录
Map<String, Object> getMap(Wrapper<T> queryWrapper);
// 根据 Wrapper,查询一条记录
<V> V getObj(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);集合:
// 查询所有
List<T> list();
// 查询列表
List<T> list(Wrapper<T> queryWrapper);
// 查询(根据ID 批量查询)
Collection<T> listByIds(Collection<? extends Serializable> idList);
// 查询(根据 columnMap 条件)
Collection<T> listByMap(Map<String, Object> columnMap);
// 查询所有列表
List<Map<String, Object>> listMaps();
// 查询列表
List<Map<String, Object>> listMaps(Wrapper<T> queryWrapper);
// 查询全部记录
List<Object> listObjs();
// 查询全部记录
<V> List<V> listObjs(Function<? super Object, V> mapper);
// 根据 Wrapper 条件,查询全部记录
List<Object> listObjs(Wrapper<T> queryWrapper);
// 根据 Wrapper 条件,查询全部记录
<V> List<V> listObjs(Wrapper<T> queryWrapper, Function<? super Object, V> mapper);
1. 分页查询
- 在启动类MainApplication中配置拦截器(插件).MP有一个拦截器集合MybatisPlusInterceptor(包括分页插件/乐观锁) , new出这个拦截器集合后 , 将分页拦截器加入该集合 . 再将这个集合对象返回 ,
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();//PaginationInnerInterceptor(DbType.MYSQL)即指定分页拦截器,其中DbType指定数据库,注意DbType要选择MP的(Druid也有这个方法)interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;
}
- 使用分页查询
@Test
public void testPageQuery(){//设置分页参数Page<User> page = new Page<>(1, 5);userMapper.selectPage(page, null);//获取分页数据List<User> list = page.getRecords();list.forEach(System.out::println);System.out.println("当前页:"+page.getCurrent());System.out.println("每页显示的条数:"+page.getSize());System.out.println("总记录数:"+page.getTotal());System.out.println("总页数:"+page.getPages());System.out.println("是否有上一页:"+page.hasPrevious());System.out.println("是否有下一页:"+page.hasNext());
}
- 自定义的mapper方法使用分页
xxxMapper接口中中:
//传入参数携带Ipage接口
//返回结果为IPage
IPage<User> selectPageVo(IPage<User?> page, Integer id);实现mapper接口的xxxMapper文件
<select id="selectPageVo" resultType="xxx.xxx.xxx.User">SELECT * FROM user WHERE id > #{id}
</select>
测试
@Test
public void testQuick(){IPage page = new Page(1,2);userMapper.selectPageVo(page,2);long current = page.getCurrent();System.out.println("current = " + current);long pages = page.getPages();System.out.println("pages = " + pages);long total = page.getTotal();System.out.println("total = " + total);List records = page.getRecords();System.out.println("records = " + records);}





)






)





)
