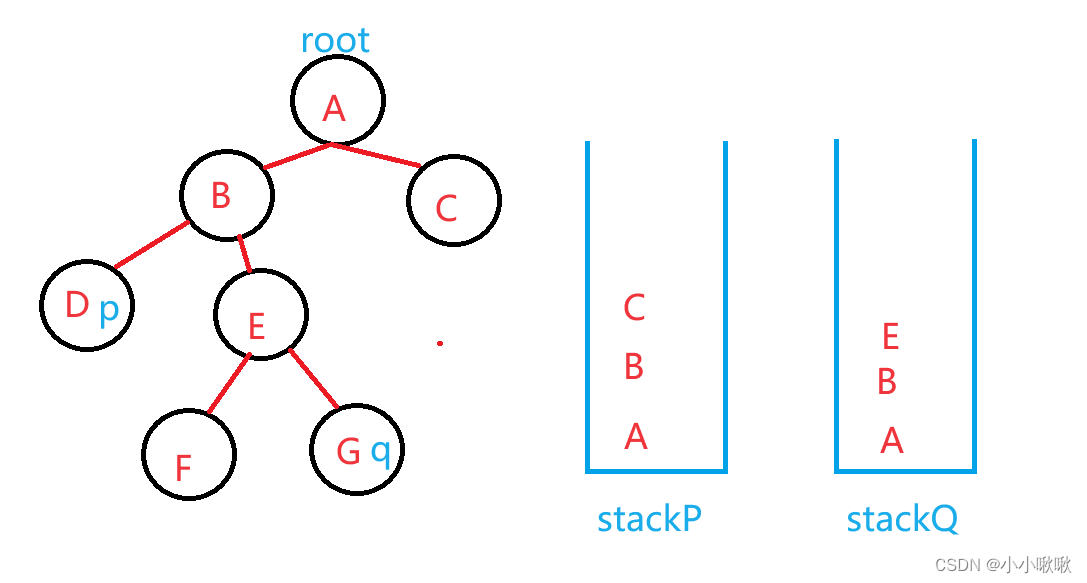
一、安装scala环境
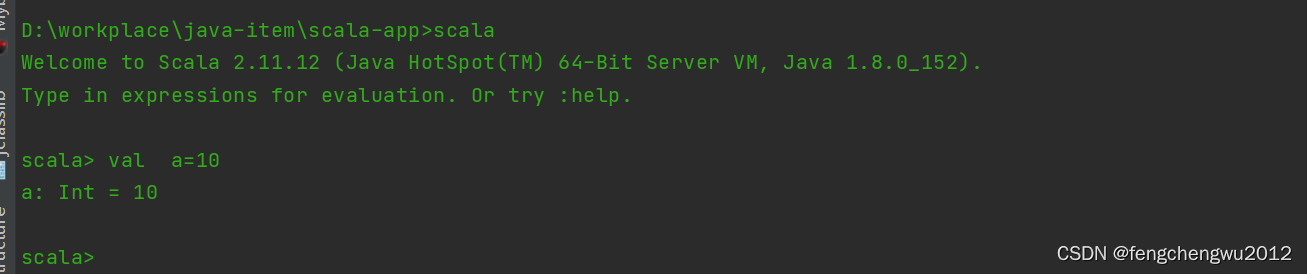
官网下载地址 Download | The Scala Programming Language,本次使用版本为sacla2.11.12,将压缩包解压至指定目录,配置好环境变量,控制台验证是否安环境是否可用:
 二、添加pom依赖
二、添加pom依赖
创建一个maven项目
1、添加scala的sdk依赖
<properties><scala.version>2.11.12</scala.version></properties><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-compiler</artifactId><version>${scala.version}</version></dependency><dependency><groupId>org.scala-lang</groupId><artifactId>scala-reflect</artifactId><version>${scala.version}</version></dependency>2、添加spark依赖
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.11</artifactId><version>2.4.8</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>2.4.8</version><scope>provided</scope></dependency>三、入门应用
1、数据源
test_spark.txt
中国 河南
中国 浙江
河南 郑州
浙江 杭州
河南 洛阳
浙江 宁波
美国 纽约
纽约 华尔街
美国 吉利福尼亚
加利福尼亚 落砂机2、编码实现
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}object SparkWordCount {def main(args: Array[String]): Unit = {///使用本地模式连接sparkval conf = new SparkConf().setAppName("WordCount").setMaster("local")val sc = new SparkContext(conf)///读取文件中每一行字符 存入到是数据集合RDD中val lines: RDD[String] = sc.textFile("D:/workplace/java-item/res/file/test_spark.txt")/// 将数据集合进行扁平化操作 以字符空格分割val tuples = lines.flatMap(_.split(" ")).groupBy(word => word).map({ case (w, l) => (w, l.size) }).collect()tuples.foreach(println)}
}
![[pytorch] 2. tensorboard](https://img-blog.csdnimg.cn/direct/81e5d2ae868f4f7787eaefef0fe0056b.png)

![[小程序]基于token的权鉴测试](https://img-blog.csdnimg.cn/direct/40acf7c0bfaa4c6790d340be0ac3bcf4.png)