文章目录
- 大语言模型在垂直领域落地的三个挑战:
- 什么是 RAG以及为什么能解决大预言模型所带来的的这三个问题
- RAG 不是一项技术而是整体的 Pipeline
- 非参数化 :数据库部分
- 加载到数据库中
- 检索阶段
- 提升检索效率的技术
- 检索前:对query做处理
- use query routing
- Query transformations
- Sentence-window retrieval & Auto-merge retriveal
- 检索中
- 检索后
- Re-ranker
- Meta-data filtering
- Prompt Compression
- 总结
- 参数化的部分:模型的选择和部署
- 评价
- NVIDIA 提供的 RAG 端到端解决方案
- embedding model
- RAPIDS RAFT 加强的index
- 大语言基础模型
- 部署框架 TensorRT-LLM
- NeMo Guardrails
- Evaluating RAG Pipeline
- RAG Pipeline Samples in NVIDIA
- 借助于RAG-Copilot 如何提升工作效率
- RAG 技术和微调技术的比较
- 高级 RAG
- NVIDIA 的加持
大语言模型在垂直领域落地的三个挑战:
- 数据是有一定范围的。大量的数据在一定的时间内训练完成的。确定数据对于基础模型是有一定的范围的。对专业领域,垂直领域的应用场景来说,知识是不够全面的。是缺乏专业的知识的。
- 数据有时间限制的。知识更新迭代快,给的回答可能过时
- 幻觉
RAG 是一种解决的 pipeline.

什么是 RAG以及为什么能解决大预言模型所带来的的这三个问题
RAG对于大语言模型来说类比于开卷考试。
三个步骤
- Retriveal
- Augmentation: 增强的 prompt
- 增强的上下文是有理有据的,减少幻觉
- 参数化的知识,结合传入的数据,生成
技术
- 非参数化的技术:数据库的部分
- 预训练的参数化部分
- 基础大语言模型的选择
- 部署平台的选择,提升用户的体验
RAG 不是一项技术而是整体的 Pipeline
非参数化 :数据库部分

加载到数据库中
准备好数据,需要放进数据库中的数据类型

-
Documents Loader
- langchain 或其他工具提供的加载方式进行数据加载
- 数据本身可能涉及到一些冗余重复的文字,比如统一的公司后缀:这是一个关于。。。之类的文档。。。声明之类,在放进数据库之前,应该统一进行清洗处理。

- Chunk
因为大语言模型对于输入的窗口是有一定的限制的,不能太大。这取决于基础模型在本身的训练过程中或者它的 attention 机制。那么我们在分 chunk 的时候可以有不同的选择。可以用固定大小的chunk,也可以用动态的,动态的是指用一些标志来作为一个分割,比如一个段落按回车符分或者一个完整的句子按句号分,就是尽可能划分为有意义的分块。
针对纯文本,可以增加重叠部分。好处是有一个承上启下的作用,给到模型的时候会附带逻辑。

-
Embedding Model
- 一般是一个 encoder model.
- 可能需要加prompt,才能达到比较好的检索效果

-
Vector Database
- 是否支持分布式部署
- 是否支持需要的索引方式等

检索阶段
应用上线之后,真的来了问题,需要把问题转换成向量,去向量空间里面去做一个近似性搜索,找到相关文档进行返回。
- Database Search
- precision:检出的文档是否是问题相关的上下文
- recall: 和问题相关的文档是否全部检出,只返回一两个可能无法提升rag整体效果
所以如何提高 similarity search 返回整体的精度也是非常重要的一点。

如何采用技术来提升相似性的精确度和准确度。
一个好的向量数据会把含义相近的上下文放在一起,区分单纯的关键词匹配。
索引一般采用的是 ANN 算法。

提升检索效率的技术
分为检索前、检索中、检索后三个阶段,看可以采用的技术。

检索前:对query做处理
use query routing
借助 LLM 的能力,可以理解成有一个小小的 LLM agent,拿到用户的问题之后,会去看问题属于哪一类。
比如会在数据库中建立两类索引,一类是和总结相关的,另外的索引就是常规的明细介绍。如果发现问题是和总结相关的,小agent就应该说你应该去 summay index 里面去做检索。

Query transformations
借助 LLM 的技术,对 query 做一个转换
- 重写问题。问题问得不好,LLM 重写一个问题再去向量数据库中检索
- HyDE, 先不用 RAG 这样的增强方式,就让这个问题直接到大语言模型产生一个答案。然后把问题和答案同时送到向量数据库中去做检索
- 将复杂问题做拆解,拆解之后再进行检索
Sentence-window retrieval & Auto-merge retriveal
chunk 如果太大, 向量表示可能隐藏掉相关文本的语义。
使用从小到大的技术。
- 使用小的chunk 去生成 embedding vector。
但是因为chunk比较小,给到大语言模型的上下文是不足够的,让后就使用 “大”(to big)- Sentence-window retrieval : 把每个句子都去生成一个多维向量,检索的时候是精确检索到了句子,为了提高上下文的丰富性,可以把前5个句子,后5个句子同时送到大语言模型中做一个上下文的增强。
- Auto-merge retriveal:采用树型的存储结构,比如知道一个段落产生了这个 vector, 知道段落属于哪个小节,属于哪章节。检索完小的段落之后,可以找到它的父节点,可以把小节的内容,更丰富的内容送进大模型中去做生成。这样就能够保证检索的精度,同时保证上下文够丰富,能够生成符合我们预期的内容。

检索中
hybrid: 混合的检索方式 keyword+embedddings.
把 keyword 加到 query 里面,做一个精确的检索?具体做法?

检索后
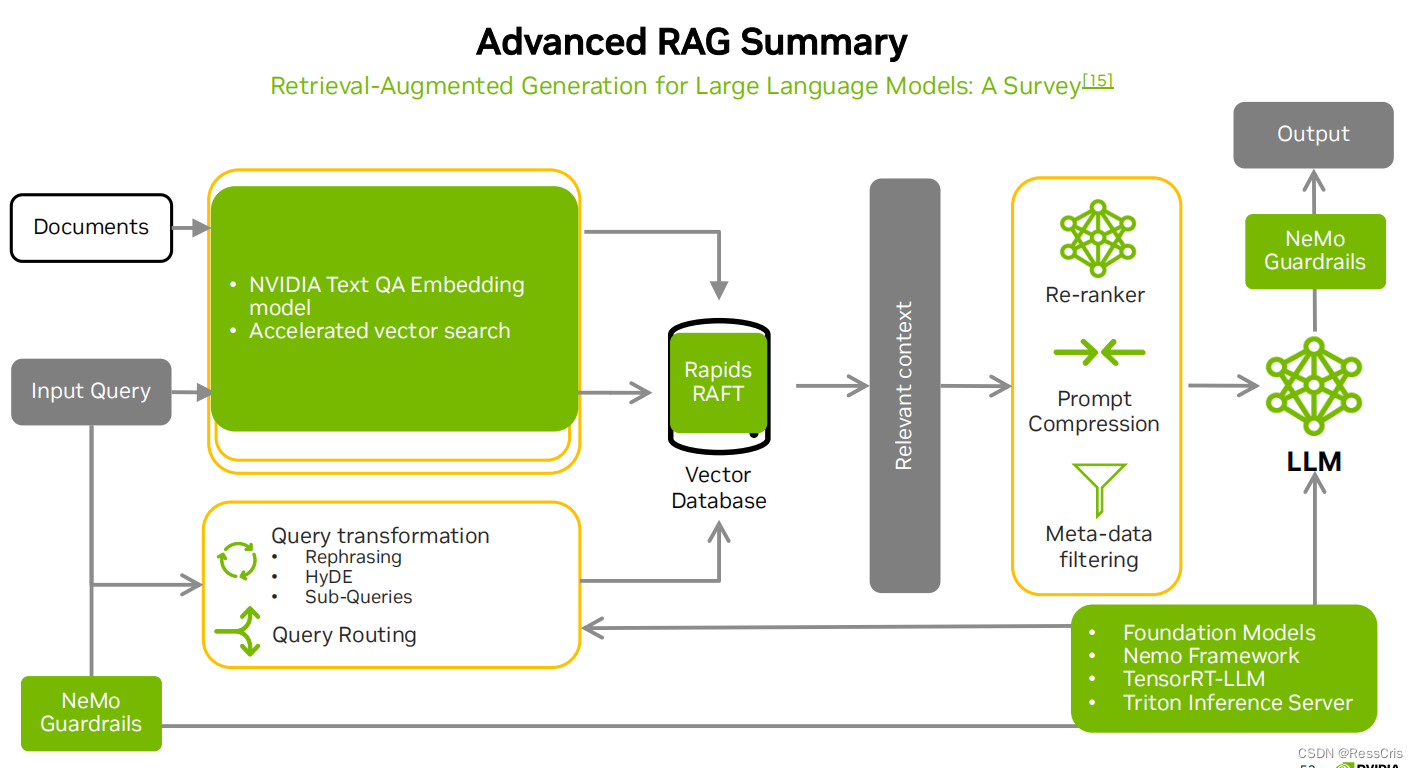
Re-ranker
这个是比较重要的,也是建议刚开始建立原型的话也可以去采用的一个技术.
相似性搜索后,和相关不是百分百对应的。检索出来的上下文不一定是相关的。可以再用一个另外一个小型的模型,输入是用户的问题以及检索出来的文档,去看问题和文档的相关性。
再去做一个排序,做一个二级检索。二级检索的时候就要对前面的检索进行一定的调整。(应该只是对第一轮检索做了一个相关性过滤)
第一轮,检索100个或30个,re-ranker 后用 top5, 放进大语言模型做生成

Meta-data filtering
存储时可以把作者存入
检索时可以增加作者这个元数据去做二次过滤,去提升检索效果

Prompt Compression
大语言模型有 window 限制, 找到的 chunk,尽管用了一些方法,但是还是存在一些噪声,和query不太相关,但是却不太能把它删除。
再借助另一个语言模型,把增强型的prompt再进行一个压缩,把有用的信息增强,把不相关的信息减弱。

总结

参数化的部分:模型的选择和部署

模型:适合场景的模型,比如代码类,问答类会有对应的模型
部署:低延迟、高吞吐率。是否支撑换模型。
评价
在产品阶段不是一蹴而就,需要多次迭代。需要看实践是否满足需求。如何评价整个 RAG 流程的工作效率是非常重要的一环。
- RAGAS
- truelens
- standford ARES
不同的评估标准的指标都不一样,对标准的计算公式也不太一样,难度也不同,按需选择。

NVIDIA 提供的 RAG 端到端解决方案

embedding model
nvidia text qa embedding model

RAPIDS RAFT 加强的index
提升检索速度
GPU 加速的 ANN 索引


大语言基础模型

部署框架 TensorRT-LLM

NeMo Guardrails
为输出提供围栏?具体没说,已经开源,可以查看文档。
已经开源,可以查看文档

Evaluating RAG Pipeline
RAGAS: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines
RAG Pipeline Samples in NVIDIA
NVIDIA/GenerativeAIExamples
借助于RAG-Copilot 如何提升工作效率
Example: ChipNemo
一个借助于RAG制造芯片的例子。里面是结合了RAG和微调两种技术。
Custom tokenizers| Domain-adaptive continued pretraining |
Supervised fine-tuning (SFT) with domain-specific instructions | domain-adapted retrieval models.
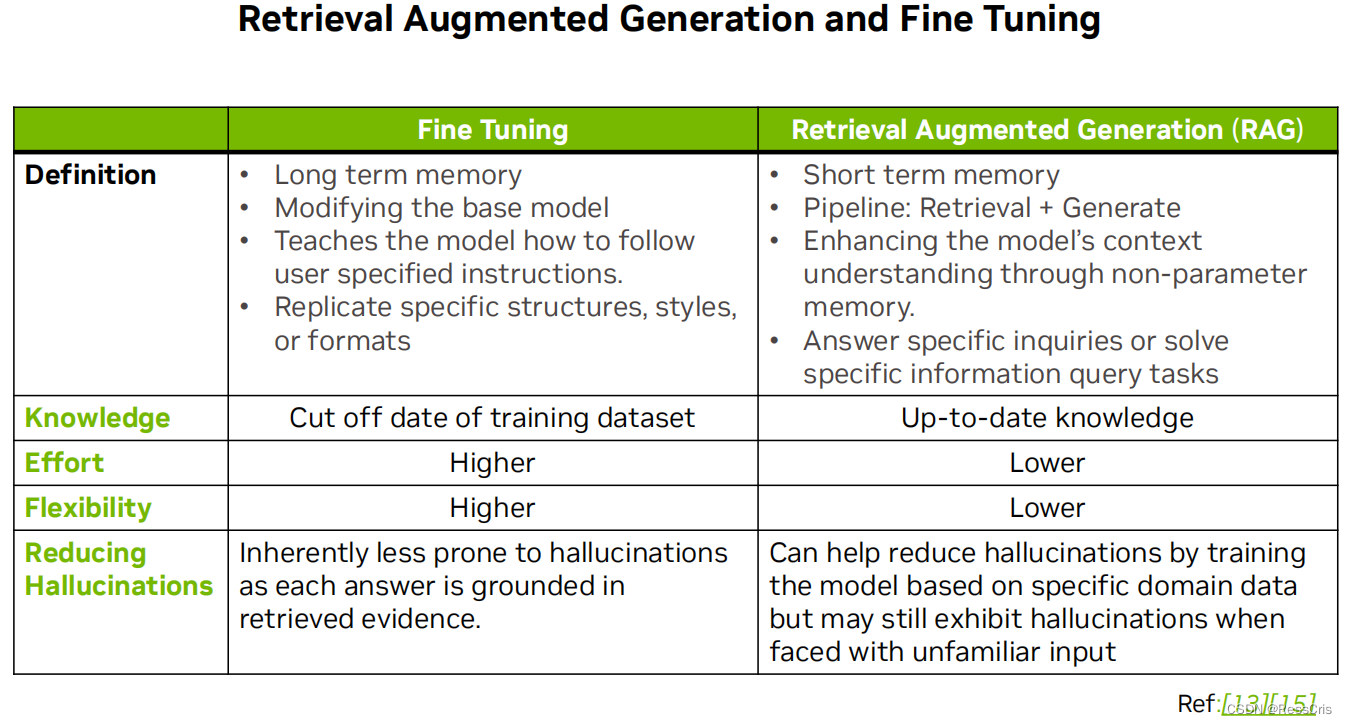
RAG 技术和微调技术的比较
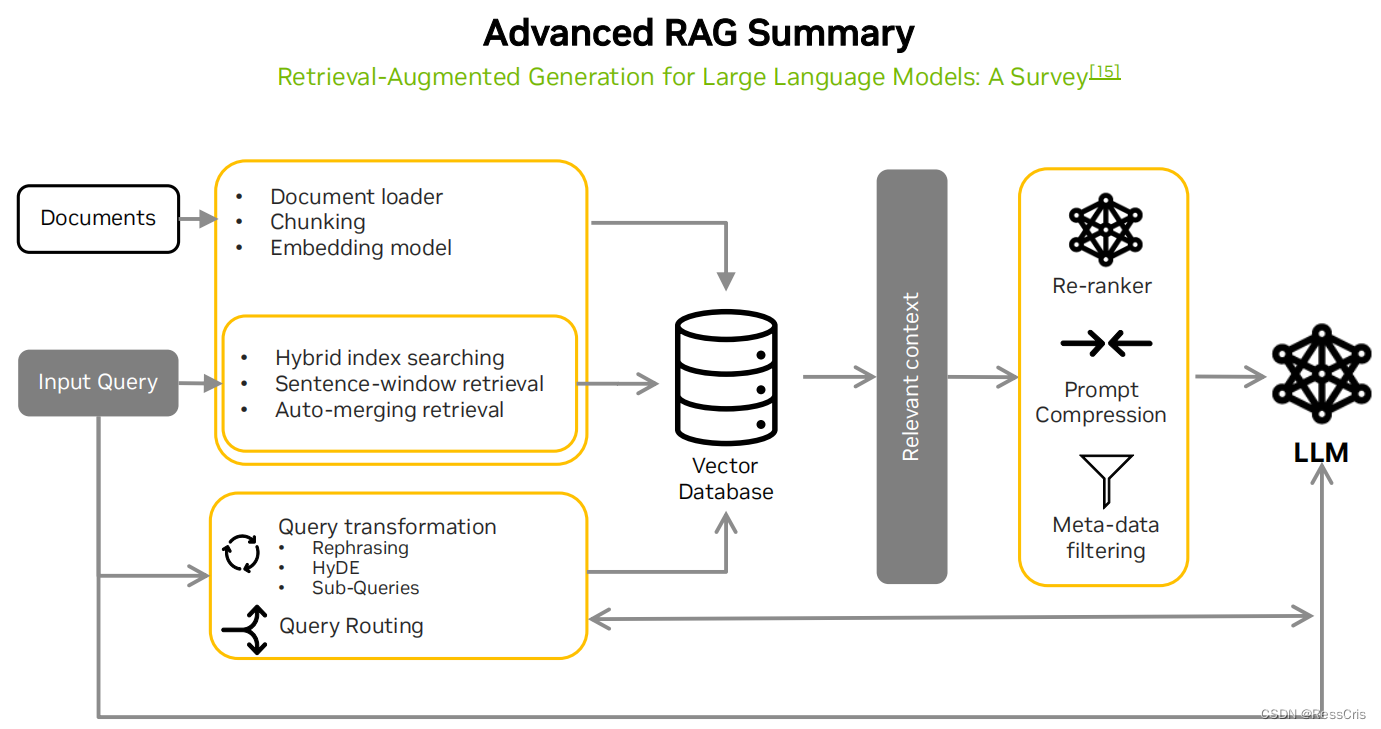
高级 RAG
NVIDIA 的加持










![[AI]文心一言爆火的同时,ChatGPT-4.5的正确打开方式](https://img-blog.csdnimg.cn/direct/1ceb3fd255254ceeaa91ded1c5c1ddba.png)