这里写目录标题
- 视觉Mamba来了:速度提升2.8倍,内存能省87%
- 一键实景转动画,清华系初创公司全球首发4D骨骼动画框架,还能生成个性化角色
- 如何利用革命性的蛋白质结构工具来发现药物?AlphaFold 发现了数千种可能的致幻剂
- 扎克伯格宣战AGI:Llama 3训练中,今年要囤35万块H100,砸近百亿美元
- 吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了
- 不担心字节跳动、腾讯等大厂竞争,英矽智能CEO Alex Zhavoronkov谈AI药物发现
- 腾讯发布视频生成模型 VideoCrafter2,光影效果大幅提升
- 扎克伯格分享:将继续开源,目前正在训练 Llama 3等!
- AI Agent取代大模型日报小编就在今天:MultiOn实现在 500 多个步骤中保持行动,不失去上下文,单个任务跨越 10 个以上网站操作
- Karpathy分享“AlphaCodium”论文:它提醒我们,在从一个简单的提示:回答范式转变为“流程”范式时,有多少潜在的优势
- 自我奖励的大语言模型
- ChatQA:构建GPT-4级的对话问答模型
- LoMA: 无损压缩内存注意力
- Voila-A: 用用户注视注意力对齐视觉-语言模型
- GPT-SoVITS
- TaskWeaver
- 使用SPIN技术对LLM进行自我博弈微调训练
- MuZero Unplugged
- 改进推荐系统中多兴趣候选匹配的新方法:REMI框架研究
- Inferflow:高效配置的语言模型推理引擎
- 高效地使用SGLang编程大型语言模型
- SetFitABSA: 基于 SetFit 的少样本、方面级情感分析
- Atom Capital: 1000x的超级码农
- Mixtral 8*7B 模型结构分析
- 大模型时代的计算机系统革新
- 程序员源码阅读与提升
- 英伟达发展史
- 微软亚研院段楠团队开展视觉内容生成研究,助力解决多模态生成式AI核心难题
视觉Mamba来了:速度提升2.8倍,内存能省87%

链接:https://news.miracleplus.com/share_link/16215
号称「全面包围 Transformer」的 Mamba,推出不到两个月就有了高性能的视觉版。本周四,来自华中科技大学、地平线、智源人工智能研究院等机构的研究者提出了 Vision Mamba(Vim)。效果如何呢?在 ImageNet 分类任务、COCO 对象检测任务和 ADE20k 语义分割任务上,与 DeiT 等成熟的视觉 Transformers 相比,Vim 实现了更高的性能,同时还显著提高了计算和内存效率。例如,在对分辨率为 1248×1248 的图像进行批量推理提取特征时,Vim 比 DeiT 快 2.8 倍,并节省 86.8% 的 GPU 内存。结果表明,Vim 能够克服对高分辨率图像执行 Transformer 式理解时的计算和内存限制,并且具有成为视觉基础模型的下一代骨干的巨大潜力。
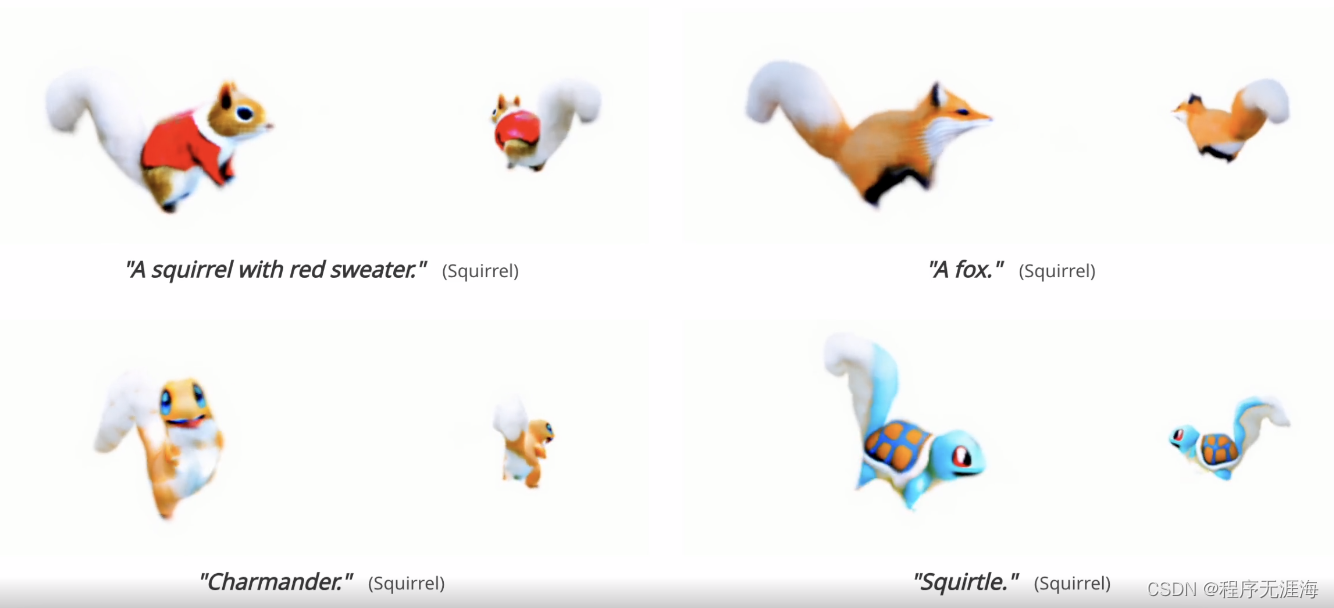
一键实景转动画,清华系初创公司全球首发4D骨骼动画框架,还能生成个性化角色
链接:https://news.miracleplus.com/share_link/16216
前几日,苹果宣布首款虚拟头显设备 Vision Pro 将于 2 月 2 日正式发售,XR 设备作为下一代终端预计将迎来快速发展。未来随着虚拟显示设备的普及,数字交互将从平面走向立体,立体模型、立体动画将成为未来主流的内容形态,虚实融合下的多维沉浸式交互也将成为潮流。面向该前沿领域,清华系创业团队生数科技开展了系列研究和产品研发,于近期联合清华大学、同济大学等高校推出全球首个基于「骨骼动画」的 4D 动画生成框架「AnimatableDreamer」,能够直接将 2D 视频素材一键转成动态立体模型(即 4D 动画),支持自动提取骨骼动作、一键转换动画效果并可通过文字输入进行个性化角色生成。
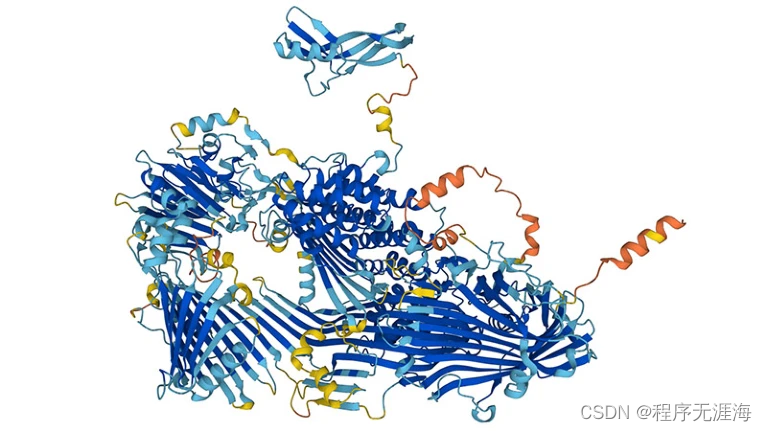
如何利用革命性的蛋白质结构工具来发现药物?AlphaFold 发现了数千种可能的致幻剂
链接:https://news.miracleplus.com/share_link/16217
AlphaFold2 (AF2)和 RosettaFold 极大地扩展了可用于基于结构的配体发现的结构的数量,尽管它们在这一目标中的直接作用提出了质疑。加州大学的研究团队已经使用蛋白质结构预测工具 AlphaFold 识别出数十万种潜在的新型迷幻(psychedelic)分子,这可能有助于开发新型抗抑郁药。该研究首次表明,只需按一下按钮即可进行 AlphaFold 预测,对于药物发现来说,它与通过实验得出的蛋白质结构一样有用,而后者可能需要数月甚至数年才能确定。
扎克伯格宣战AGI:Llama 3训练中,今年要囤35万块H100,砸近百亿美元

链接:https://news.miracleplus.com/share_link/16218
为了通用人工智能(AGI)的宏大目标,扎克伯格正在给 Meta 的 AI 研究部门进行大幅度的改组。本周四,Meta 首席执行官马克・扎克伯格宣布,他的公司正在致力于为人工智能助手构建「通用智能」并「负责任地开源」,Meta 正在将其两个主要研究小组(FAIR 和 GenAI)合并在一起以实现这一目标 。有第三方投资机构的研究估算,英伟达面向 Meta 的 H100 出货量在 2023 年能达到 15 万块,这个数字与向微软的出货量持平,并且至少是其他公司的三倍。扎克伯格表示,如果算上英伟达 A100 和其他人工智能芯片,到 2024 年底,Meta 的 GPU 算力将达到等效近 60 万 H100。
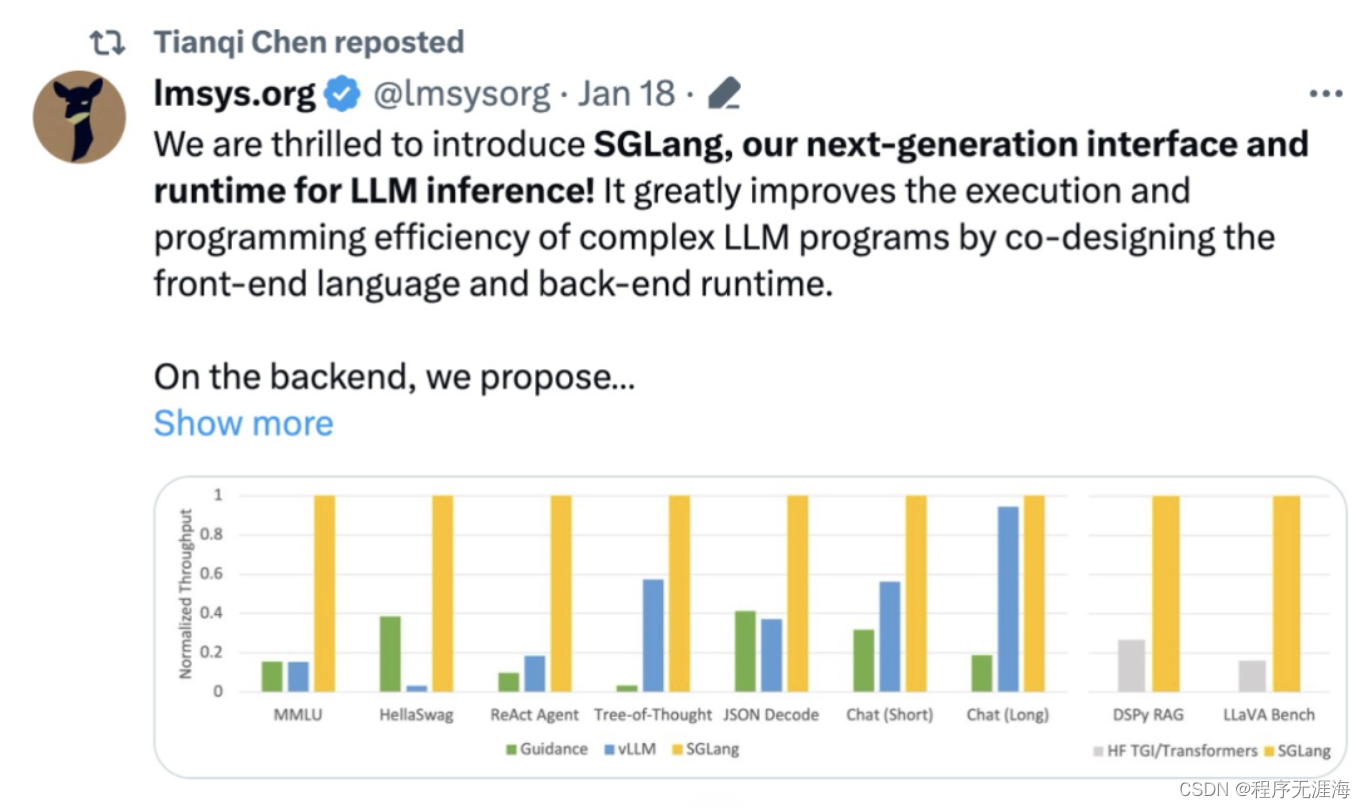
吞吐量提升5倍,联合设计后端系统和前端语言的LLM接口来了
链接:https://news.miracleplus.com/share_link/16219
大型语言模型 (LLM) 越来越多地用于需要多个链式生成调用、高级 prompt 技术、控制流以及与外部环境交互的复杂任务。然而,用于编程和执行这些应用程序的现有高效系统存在着明显的缺陷。现在,开源社区的研究者们面向 LLM 提出了一种结构化生成语言(Structured Generation Language)——SGLang。SGLang 能够增强与 LLM 的交互,通过联合设计后端运行时系统和前端语言,使 LLM 更快、更可控。机器学习领域知名学者、CMU 助理教授陈天奇还转发了这项研究。
不担心字节跳动、腾讯等大厂竞争,英矽智能CEO Alex Zhavoronkov谈AI药物发现

链接:https://news.miracleplus.com/share_link/16220
人工智能在生物制药领域的应用越来越广泛,其应用超出了发现设备的范畴。2024 年 1 月 8 日-11 日,在旧金山举行的第 42 届摩根大通医疗保健大会( J.P. Morgan Healthcare Conference)上,这是一个热点问题。在会议刚刚开始之际,礼来公司和诺华公司甚至宣布与 Alphabet 的 Isomorphic Labs 达成数百万美元的发现协议。在人工智能的热潮中,外媒与英矽智能(Insilico Medicine)首席执行官 Alex Zhavoronkov 进行了座谈。去年夏天,该公司成为第一家使用生成人工智能开发的疗法进入 II 期临床试验的公司。Zhavoronkov 谈到了 AI 在行业中的作用以及 Insilico 何时可能在市场上推出产品。除了将于今年夏天在美国和中国测试肺部疾病特发性肺纤维化疗法的 II 期试验外,Insilico 本月刚刚与美纳里尼集团(Menarini Group)签署了一项许可协议,将其另一种药物商业化。
腾讯发布视频生成模型 VideoCrafter2,光影效果大幅提升

链接:https://news.miracleplus.com/share_link/16221
腾讯宣布,推出视频生成模型 VideoCrafter 的升级版 VideoCrafter 2,在光影效果等方面有大幅度改进。VideoCrafter 2 可以根据用户提出的文字来生成几秒钟的高质量视频。相比之前的版本,新版在画面质量、人物动作等方面有大幅改进,生成的视频内容真实度更高。
扎克伯格分享:将继续开源,目前正在训练 Llama 3等!
链接:https://news.miracleplus.com/share_link/16222
扎克伯格的最新消息:
-
将继续开源
-
目前正在训练 Llama 3
-
AI + 元宇宙
-
将拥有 350,000 块 H100 和约 600 块 H100 等效的计算能力 🤯
-
理想的 AI 形态是 🕶️
AI Agent取代大模型日报小编就在今天:MultiOn实现在 500 多个步骤中保持行动,不失去上下文,单个任务跨越 10 个以上网站操作
链接:https://news.miracleplus.com/share_link/16223
我们刚刚解决了与代理长期规划和执行相关的问题 🤯!
很高兴宣布,@MultiON_AI 现在能够在 500 多个步骤中保持行动,不会失去上下文,并且能在单个任务中跨越 10 个以上的网站进行操作 🤩!!
我们的最新升级解决了长期困扰像 AutoGPT 这样的代理的目标偏差和循环问题 🔥
这里有一个演示,展示它作为一个 AI 新闻研究代理的工作情况,它持续搜索最新的 AI 新闻并每天自动发推 🚀:
🔊
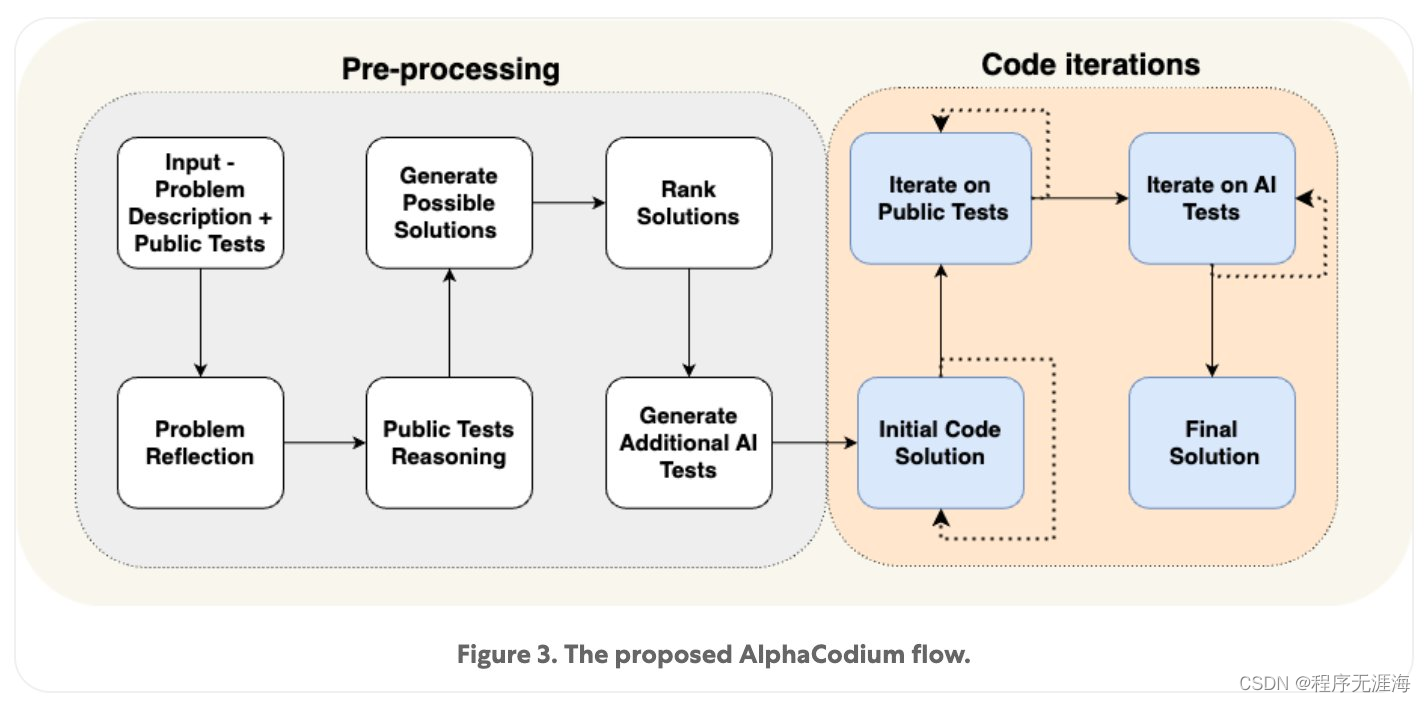
Karpathy分享“AlphaCodium”论文:它提醒我们,在从一个简单的提示:回答范式转变为“流程”范式时,有多少潜在的优势
链接:https://news.miracleplus.com/share_link/16224
提示工程(或者更准确地说是“流程工程”)在代码生成领域的应用日益加强。这是一篇很好的阅读材料,它提醒我们,在从一个简单的提示:回答范式转变为“流程”范式时,有多少潜在的优势(通过率从 19% 提升至 44%)。在“流程”范式中,答案是通过迭代构建的。
自我奖励的大语言模型

链接:https://news.miracleplus.com/share_link/16231
我们认为,为了实现超人类智能体,未来的模型需要超人类的反馈来提供足够的训练信号。目前,常见的方法是根据人类偏好来训练奖励模型,但这可能受限于人类的性能水平,而且这些独立的冻结奖励模型在LLM训练期间无法学习改进。在这项工作中,我们研究了自我奖励语言模型,即在训练过程中使用语言模型本身通过LLM作为评判者提供自己的奖励。我们展示了在迭代DPO训练中,不仅指令跟随能力得到改善,而且提供高质量奖励的能力也得到了提高。通过对Llama 2 70B进行三次迭代的微调,我们得到了一个在AlpacaEval 2.0排行榜上胜过许多现有系统的模型,包括Claude 2、Gemini Pro和GPT-4 0613。虽然这只是一项初步研究,但这项工作为模型在两个方向上不断改进的可能性打开了大门。
ChatQA:构建GPT-4级的对话问答模型

链接:https://news.miracleplus.com/share_link/16232
在这项工作中,我们介绍了ChatQA,一类实现了GPT-4级准确性的对话问答(QA)模型。具体来说,我们提出了一种两阶段指令微调方法,可以显著提高大语言模型(LLMs)在零样本对话式QA上的结果。为了处理对话式QA中的检索问题,我们在一个多轮QA数据集上对密集型检索器进行了微调,这可以提供与使用最先进的查询重写模型相当的结果,同时大大减少了部署成本。值得注意的是,我们的ChatQA-70B在10个对话式QA数据集的平均得分上优于GPT-4(54.14 vs. 53.90),而不依赖于OpenAI GPT模型的任何合成数据。
LoMA: 无损压缩内存注意力
链接:https://news.miracleplus.com/share_link/16235
摘要:处理长文本是大语言模型(LLM)的最重要能力之一,但随着文本长度的增加,资源的消耗也大幅增加。目前,通过压缩KV缓存来减少资源消耗是一种常见的方法。尽管存在许多现有的压缩方法,但它们都有一个共同的缺点:压缩不是无损的。也就是说,在压缩过程中不可避免地会丢失信息。如果压缩率很高,丢失重要信息的概率会大幅增加。我们提出了一种新方法,即无损压缩内存注意力(LoMA),它可以根据一组压缩比将信息无损地压缩成特殊的内存令牌KV对。我们的实验证明,LoMA可以高效训练,并具有非常有效的性能。
Voila-A: 用用户注视注意力对齐视觉-语言模型

链接:https://news.miracleplus.com/share_link/16236
近年来,视觉和语言理解的整合已经在人工智能领域取得了重要进展,尤其是通过Vision-Language Models(VLMs)。然而,现有的VLMs在处理复杂场景和多个对象的真实应用时面临挑战,同时也需要与人类用户的多样化注意力模式相结合。在本文中,我们引入了由AR或VR设备可行地收集的注视信息作为人类注意力的代理,以指导VLMs,并提出了一种新的方法Voila-A,用于注视对齐,以增强这些模型在真实应用中的可解释性和效果。首先,我们收集了数百分钟的注视数据,以证明我们可以使用局部化叙述来模拟人类注视模式。然后,我们设计了一个自动数据注释流程,利用GPT-4生成VOILA-COCO数据集。此外,我们创新使用Voila Perceiver模块将注视信息集成到VLMs中,同时保留它们的预训练知识。我们使用一个保留验证集和一个新收集的VOILA-GAZE Testset对Voila-A进行评估,该数据集采用了注视追踪设备捕捉到的真实场景。我们的实验结果表明,Voila-A明显优于几种基准模型。通过将模型的注意力与人类视线模式对齐,Voila-A为更直观、以用户为中心的VLMs铺平了道路,并促进了在各种应用领域中引人入胜的人工智能与人类互动。
GPT-SoVITS
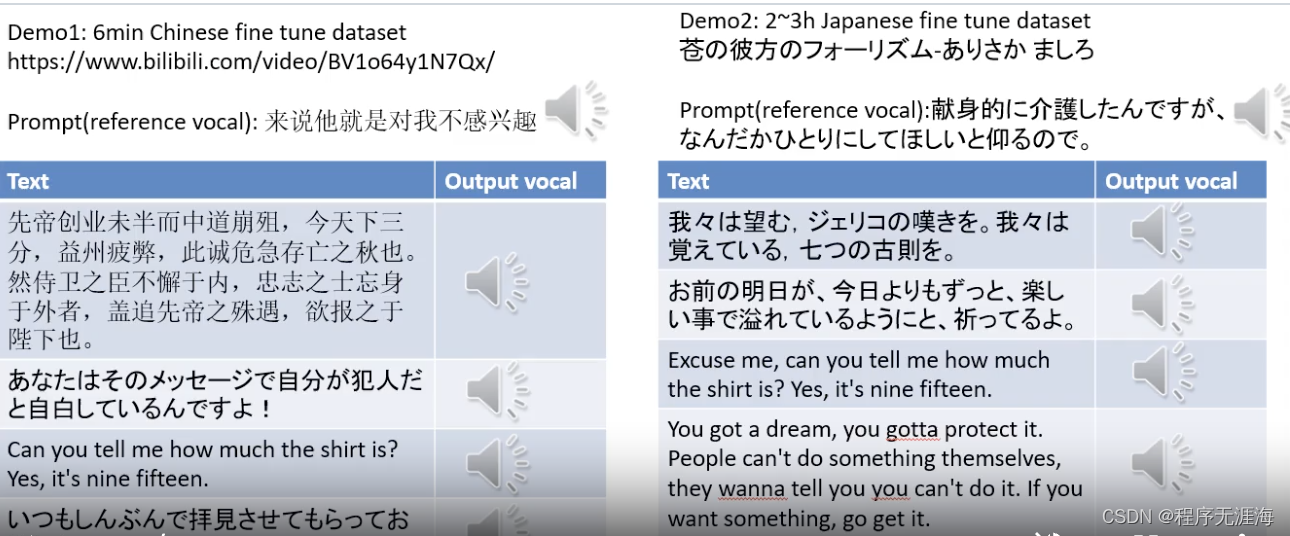
链接:https://news.miracleplus.com/share_link/16237
实现1分钟的语音数据训练一个好的TTS模型。
-
零样本 TTS:输入 5 秒的人声样本,体验即时文本到语音转换。
-
Few-shot TTS:只需 1 分钟的训练数据即可对模型进行微调,以提高语音相似度和真实感。
-
跨语言支持:使用与训练数据集不同的语言进行推理,目前支持英语、日语和中文。
-
WebUI工具:集成了语音伴奏分离、自动训练集分割、中文ASR、文本标注等功能,帮助初学者创建训练数据集和GPT/SoVITS模型。
TaskWeaver
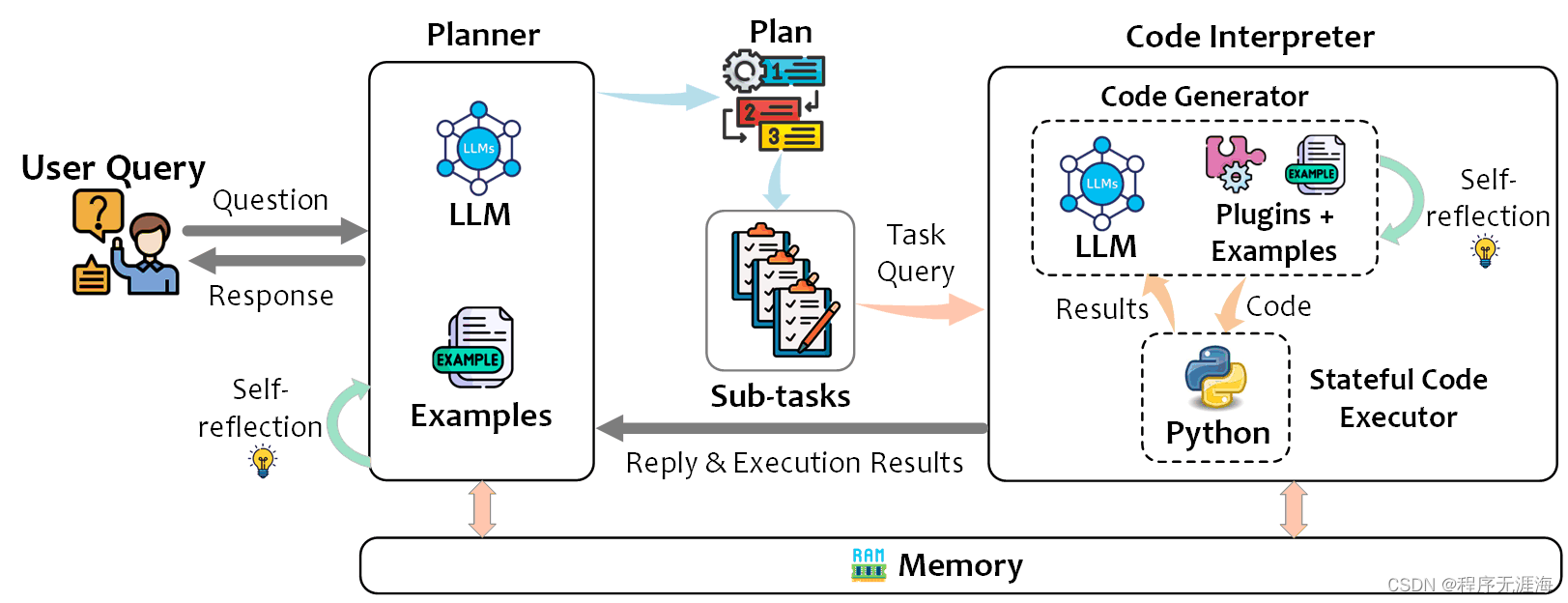
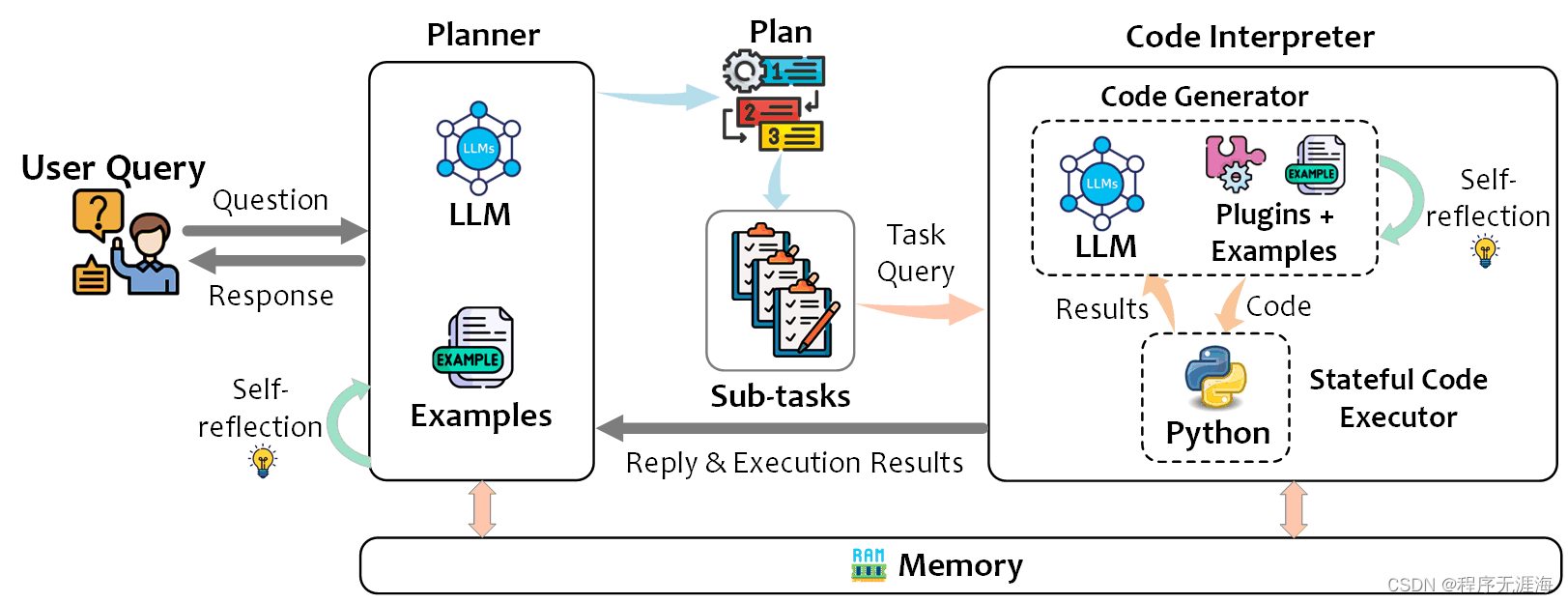
链接:https://news.miracleplus.com/share_link/12238
TaskWeaver 是一个代码优先的代理框架,用于无缝规划和执行数据分析任务。这个创新的框架通过编码的片段来解释用户请求,并以函数的形式有效地协调各种插件,以有状态的方式执行数据分析任务。
使用SPIN技术对LLM进行自我博弈微调训练
链接:https://news.miracleplus.com/share_link/16238
SPIN(Self Play fIne tuNing)是一种用于大型语言模型(LLM)微调训练的技术,它受到AlphaGo Zero等游戏中自我对弈机制的启发。SPIN技术通过让LLM参与自我游戏,消除了对专业注释者的需求。它涉及训练一个新的语言模型,并通过迭代来区分自己生成的响应和人类生成的响应,目标是使模型产生的反应与人类无异。SPIN技术包括主模型和对手模型,主模型学习区分人类和机器生成的响应,而对手模型则努力生成逼真的响应。通过这种方式,SPIN能够提高LLM的连贯性和信息丰富性,且在某些基准测试中表现出色,甚至超过直接偏好优化(DPO)模型。
MuZero Unplugged
链接:https://news.miracleplus.com/share_link/16239
这篇文章介绍了MuZero Unplugged算法,它是在MuZero基础上发展出的一种适用于在线和离线强化学习场景的统一算法。MuZero Unplugged通过Reanalyse算法框架,利用模型对现有数据点生成新的训练目标,提高了样本效率。文章还探讨了Reanalyse算法在不同数据预算下的应用,包括提升样本效率、离线强化学习和从演示中学习。实验结果表明,MuZero Unplugged在Atari游戏和DM Control Suite上均表现出色,超越了基线算法。这项工作展示了基于模型的规划算法在强化学习中的潜力,并朝着统一算法解决广泛强化学习应用的目标迈进。
改进推荐系统中多兴趣候选匹配的新方法:REMI框架研究
链接:https://news.miracleplus.com/share_link/16240
Code: https://github.com/Tokkiu/REMI
这篇文章专注于改进推荐系统中的多兴趣候选匹配。研究发现,传统训练目标和路由机制在多兴趣学习中存在问题,导致效果不佳。为解决这些问题,提出了REMI框架,包含两个主要创新:感兴趣的硬负采样策略(IHN)和路由正则化(RR)。IHN通过理想采样分布和蒙特卡罗策略强调硬负样本,而RR防止路由崩溃,保持多兴趣表示的丰富性。这些技术显著提升了推荐系统的效果,易于实现且计算开销小。
Inferflow:高效配置的语言模型推理引擎
链接:https://news.miracleplus.com/share_link/16241
Inferflow是一款高度可配置的推理引擎,专注于为大型语言模型提供高效服务。其主要特点包括极大的可扩展性,允许用户通过编辑配置文件而无需编写源代码来为新模型提供服务。该引擎还引入了3.5位量化技术,提供了多GPU推理的划分策略,包括混合划分,这在其他推理引擎中较为罕见。此外,Inferflow支持广泛的文件格式,可安全加载pickle数据,并且能够处理多种类型的变换器模型。最重要的是,它支持GPU/CPU混合推理,为用户提供了更大的灵活性和性能优势,使其成为处理大型语言模型的强大工具。
高效地使用SGLang编程大型语言模型
链接:https://news.miracleplus.com/share_link/16242
https://arxiv.org/abs/2312.07104
SGLang是一种专为大型语言模型(LLMs)设计的结构化生成语言。通过共同设计前端语言和运行时系统,它可以使您与LLMs的交互更快速、更可控。
SGLang的核心特点包括:
灵活的前端语言:这允许轻松编写LLM应用程序,支持多个链接的生成调用、高级提示技术、控制流、多模式、并行处理以及外部交互。
高性能的运行时与RadixAttention:该功能通过在多个调用之间自动重复使用KV缓存,显著加速复杂LLM程序的执行。它还支持其他常见技术,如连续批处理和张量并行处理。
SetFitABSA: 基于 SetFit 的少样本、方面级情感分析
链接:https://news.miracleplus.com/share_link/16245
SetFitABSA 是一种先进的少样本学习技术,专门用于方面级情感分析(ABSA),能够从文本中准确识别和评估特定方面的正面或负面情绪。这项技术由英特尔实验室与Hugging Face共同开发,它通过三步流程:提取候选方面、筛选真实方面、判断情感极性,并且不需要依赖复杂的提示,训练速度快。SetFitABSA 在少样本场景下表现出色,甚至在参数量较小的情况下也能超越大型模型如Llama2。这一技术的应用潜力巨大,尤其是在需要快速训练和高效分析用户反馈的领域。
Atom Capital: 1000x的超级码农
链接:https://news.miracleplus.com/share_link/16246
AI编程正经历快速发展,GPT等大模型在编程中的应用尤为突出,显著提升了编程效率。GitHub Copilot等工具已成为程序员的得力助手。未来,AI编程有望实现软件自动化开发,通过理解并生成复杂代码集,与人类工程师协作,颠覆软件行业。关键技术RAG(检索增强生成)将帮助AI构建复杂代码集的全局地图,实现增量开发。AI编程的未来可能朝着AI Engineer Agent发展,实现完全自主的软件开发。
Mixtral 8*7B 模型结构分析
链接:https://news.miracleplus.com/share_link/16247
Mixtral 8x7B是Mistral AI团队开发的先进稀疏专家混合模型,采用Apache 2.0开源许可。它在多项基准测试中超越了Llama 2 70B,且推理速度快6倍。Mixtral模型通过稀疏混合块(MoE)技术,实现了高效的模型压缩和加速,同时保持了强大的性能。其模型结构包括自注意力机制和专家模型,这些专家模型实际上是多个MLP层,通过门控层动态选择,以提高模型的效率和效果。
大模型时代的计算机系统革新
链接:https://news.miracleplus.com/share_link/16248
文章探讨了大模型时代计算机系统的革新,强调了随着人工智能技术的发展,传统计算机系统需要在规模、分布式和智能化方面进行革新。微软亚洲研究院提出了三个革新方向:创新超大规模计算机系统以支持AI发展;重构云计算平台以适应AI智能体;设计分布式系统以适应广泛分布的智能需求。这些革新将推动计算机系统自我进化,满足未来AI发展的需求,并具备自我演化的能力。
程序员源码阅读与提升
链接:https://news.miracleplus.com/share_link/16249
文章强调程序员阅读源代码的重要性,认为这是提升编码、设计和架构能力的关键。建议从Java基础包开始,逐步扩展到开源项目。阅读源码的步骤包括选择阅读范围、获取信息、编写单元测试和总结输出。作者通过Netty框架的实战经验,展示了如何通过源码阅读来深入理解技术细节。同时,文章讨论了AI编码助手在提升编码效率方面的作用,以及对传统编程实践的影响。
英伟达发展史
链接:https://news.miracleplus.com/share_link/16250
英伟达(NVIDIA)自1993年成立以来,经历了从创业初期的艰难到成为AI芯片领域的领导者。公司通过不断的技术创新和市场策略调整,逐步在高性能计算和图形处理领域确立了领先地位。特别是在AI和深度学习的兴起中,英伟达的GPU产品因其强大的计算能力和CUDA平台的推出,成为AI研究和应用的关键。2022年起,英伟达进一步扩大了其在AI、游戏、自动驾驶等领域的影响力,推出了RTX 40系列显卡和Grace CPU等新产品,同时在AI科研领域也取得了显著成就。2024年,英伟达继续在AI和计算领域推出新产品,如RTX SUPER桌面端GPU,以及面向游戏和应用程序的Avatar Cloud Engine(ACE)。
微软亚研院段楠团队开展视觉内容生成研究,助力解决多模态生成式AI核心难题
链接:https://news.miracleplus.com/share_link/16251
微软亚洲研究院的段楠团队致力于视觉内容生成研究,解决了多模态生成式AI的核心难题。他们开发了业界首个开放域视觉内容生成预训练模型NUWA(女娲)及其后续版本,如NUWA-Infinity、NUWA-XL和DragNUWA,这些模型能够生成高清图片、任意分辨率图像、超长视频和可控视频。段楠团队的研究不仅具有商业价值,也是构建通用型人工智能的关键部分,旨在通过多模态生成模型辅助人类进行更好的规划和决策。













)



)
:教程选择)
