0. 前序背景
论文:GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL
GLM2的微调教程
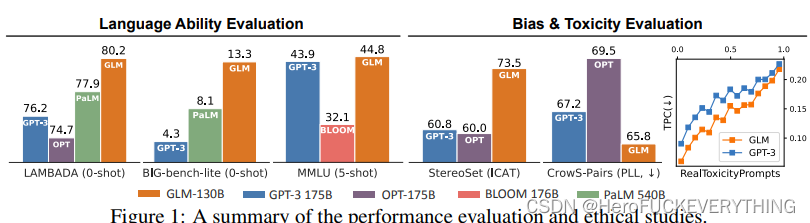
目前GLM2-130B优于或相当GPT-3-175B的性能。
选择130B(1300亿参数)是从硬件性能考虑,可以在单张A100(40Gx8)上进行推理(高端A100 80Gx8),也可以进行INT4量化后在7GB的显存上运行。
GLM130B借鉴了FastTransformer同时使用C++实现,比采用Pytorch实现的BLOOM-176B快7-8倍。
非量化模型约微调0.1%的参数;
量化模型的微调需要借助P-tuning v2平台:P-tuning-v2
全模型参数的微调需要借助微软的DeepSpeed平台:DeepSpeed
1. 运算环境
教程演示是在和鲸平台上的算力,根据算力需求约需要12RMB/h;训练大模型和全参数微调大模型需要使用配套加速套件如由HuggingFace(抱抱脸,不知道为什么起这样一个令人难忘的名字[震惊])团队支持的transformers, transformers包含许多预训练模型,需要从头学习。
部署测试, 使用一片文章作为调试;
FineTurn:使用ADGEN 数据集,任务为根据输入(content)生成一段广告词(summary)如
{ "content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳", "summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}的数据集进行微调训练。
这里有个问题就是微调数据是否都是需要像这样组织,特别是prompt中是否需要“#” 和“*”进行划分。输出的summary比较好理解,就是输出一段话。数据的组织还需要看训练数据是如何组织的。
词符化 (tokenized): 词语符号化,是大模型训练中重要的一环。其目的是将语料库中的词汇形成词汇表并编码,以供学习和预测。


:简单工厂模式)
)







应用)
 FrameDrawer.cc DrawTextInfo)






