开发环境
- Windows 10
- Rust 1.74.1

- VS Code 1.85.1
项目工程
这次创建了新的工程minigrep.
重构改进模块化和错误处理
为了改进我们的程序,我们将修复与程序结构及其处理潜在错误的方式有关的四个问题。首先,我们的main函数现在执行两项任务:解析参数和读取文件。随着我们程序的增长,main处理的独立任务的数量也会增加。随着一个功能获得更多的职责,它变得更难推理、更难测试、更难在不破坏其某个部分的情况下进行更改。最好将功能分开,每个功能负责一项任务。
这个问题还与第二个问题有关:尽管query和file_path是程序的配置变量,但contents等变量也用于执行程序的逻辑。main越长,我们需要纳入范围的变量就越多;范围内的变量越多,就越难跟踪每个变量的用途。最好将配置变量分组到一个结构中,以使其目的明确。
第三个问题是,我们已经使用expect在读取文件失败时打印了一条错误消息,但错误消息只是打印了Should have been able to read the file。读取文件失败的原因有很多:例如,文件可能丢失,或者我们可能没有权限打开它。现在,不管情况如何,我们都会为所有内容打印相同的错误消息,这不会给用户任何信息!
第四,我们重复使用expect来处理不同的错误,如果用户在没有指定足够参数的情况下运行我们的程序,他们将从Rust获得一个索引越界错误,该错误无法清楚地解释问题。如果所有的错误处理代码都在一个地方是最好的,这样将来的维护人员在需要更改错误处理逻辑时就只有一个地方可以查阅代码。将所有错误处理代码放在一个地方还将确保我们打印的消息对最终用户有意义。
让我们通过重构项目来解决这四个问题。
二进制项目的关注点分离
将多项任务的责任分配给main功能的组织问题在许多二元项目中很常见。因此,Rust社区开发了当main开始变大时分割二进制程序的独立关注点的指导方针。该过程包括以下步骤:
- 将你的程序分成一个main.rs和一个lib.rs,并将你的程序逻辑转移到lib.rs。
- 只要您的命令行解析逻辑很小,它就可以保留在main.rs中。
- 当命令行解析逻辑开始变得复杂时,将其从main.rs中提取出来并移动到lib.rs中。
在此流程之后,main函数的职责应仅限于以下方面:
- 使用参数值调用命令行解析逻辑
- 设置其他配置
- 在lib.rs中调用运行函数
- run返回错误时处理错误
这种模式是关于分离关注点的:main.rs处理程序的运行,lib.rs处理手头任务的所有逻辑。因为您不能直接测试main函数,所以这种结构允许您通过将程序的逻辑移入lib.rs中的函数来测试程序的所有逻辑。保留在main.rs中的代码将足够小,可以通过读取它来验证其正确性。让我们按照这个过程重新编写我们的程序。
提取参数解析器
我们将解析参数的功能提取到一个函数中,main将调用该函数来准备将命令行解析逻辑移动到src/lib.rs .示例12-5显示了main调用新函数parse_config的新开始,我们暂时将在src/main.rs中定义该函数。
文件名:src/main.rs
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let (query, file_path) = parse_config(&args);// --snip--println!("With value:\n{} \n{}", query, file_path);
}fn parse_config(args: &[String]) -> (&str, &str) {let query = &args[1];let file_path = &args[2];(query, file_path)
}示例12-5 从main中提取parse_config函数
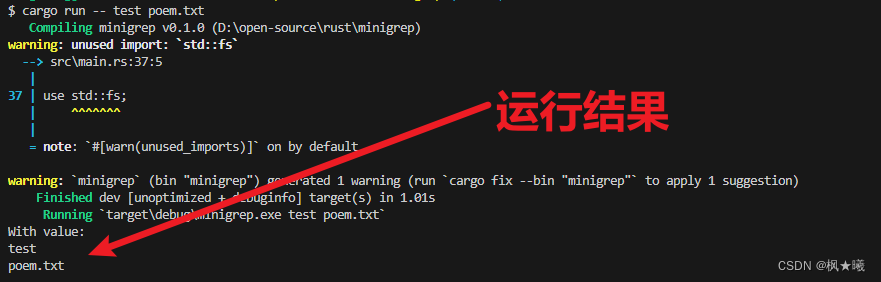
我们仍然将命令行参数收集到一个向量中,但是我们没有将索引1处的参数值分配给变量query,也没有将索引2处的参数值分配给主函数中的变量file_path,而是将整个向量传递给parse_config函数。parse_config函数然后保存逻辑,该逻辑确定哪个参数进入哪个变量并将值传递回main。我们仍然在main中创建query和file_path变量,但是main不再负责确定命令行参数和变量如何对应。
对于我们的小程序来说,这种返工似乎有些过头了,但我们正在以小而渐进的步骤进行重构。在做出这一更改后,再次运行程序以验证参数解析是否仍然有效。经常检查你的进展是有好处的,有助于在问题出现时找出问题的原因。
对配置值进行分组
我们可以采取另一个小步骤来进一步改进parse_config函数。目前,我们正在返回一个元组,但随后我们立即再次将该元组拆分为单独的部分。这表明我们可能还没有正确的抽象概念。
另一个显示还有改进空间的指标是parse_config的config部分,这意味着我们返回的两个值是相关的,并且都是一个配置值的一部分。除了将这两个值分组到一个元组中之外,我们目前没有在数据结构中传达这种含义;相反,我们将把这两个值放入一个结构中,并为每个结构字段赋予一个有意义的名称。这样做将使该代码的未来维护者更容易理解不同值之间的关系以及它们的用途。
示例12-6显示了对parse_config函数的改进。
文件名:src/main.rs
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let config = parse_config(&args);println!("Searching for {}", config.query);println!("In file {}", config.file_path);let contents = fs::read_to_string(config.file_path).expect("Should have been able to read the file");// --snip--println!("With text:\n{contents}");
}struct Config {query: String,file_path: String,
}fn parse_config(args: &[String]) -> Config {let query = args[1].clone();let file_path = args[2].clone();Config { query, file_path }
}示例12-6:重构parse_config以返回一个Config结构的实例

我们添加了一个名为Config的结构,该结构定义了名为query和file_path的字段。parse_config的签名现在表明它返回一个配置值。在parse_config的主体中,我们曾经返回引用args中的字符串值的字符串片段,现在我们将Config定义为包含拥有的字符串值。main中的args变量是参数值的所有者,并且只让parse_config函数借用它们,这意味着如果Config试图获取args中的值的所有权,我们将违反Rust的借用规则。
我们可以通过多种方式管理String数据;最简单的方法是对值调用clone方法,尽管这种方法有些低效。这将为Config实例创建数据的完整副本,这比存储对字符串数据的引用花费更多的时间和内存。然而,克隆数据也使我们的代码非常简单,因为我们不必管理引用的生存期;在这种情况下,牺牲一点性能来获得简单性是值得的。
使用克隆的利弊
许多Rust开发者倾向于避免使用clone来解决所有权问题,因为它的运行时成本很高。在后续章节中,你将学习如何在这种情况下使用更有效的方法。但是现在,复制几个字符串以继续取得进展是可以的,因为您将只复制这些副本一次,并且您的文件路径和查询字符串非常小。最好有一个效率稍低的工作程序,而不是第一次就试图过度优化代码。随着您对Rust的经验越来越丰富,开始使用最有效的解决方案将变得更加容易,但就目前而言,调用clone是完全可以接受的。
我们已经更新了main,因此它将parse_config返回的config实例放入名为config的变量中,并且我们更新了以前使用单独的query和file_path变量的代码,因此它现在改为使用Config结构上的字段。
现在我们的代码更清楚地传达了query和file_path是相关的,它们的目的是配置程序将如何工作。任何使用这些值的代码都知道在config实例中为其目的命名的字段中找到它们。
为配置创建构造函数
到目前为止,我们已经从main中提取了负责解析命令行参数的逻辑,并将其放在parse_config函数中。这样做有助于我们看到查询和file_path值是相关的,并且这种关系应该在我们的代码中传达。然后,我们添加了一个配置结构来命名query和file_path的相关用途,并能够从parse_config函数中将值的名称作为结构字段名返回。
既然parse_config函数的目的是创建一个配置实例,我们可以将parse_config从一个普通函数更改为一个名为new的函数,该函数与配置结构相关联。进行这一更改将使代码更符合习惯。我们可以通过调用String::new在标准库中创建类型的实例,例如String。类似地,通过将parse_config更改为与config相关联的新函数,我们将能够通过调用Config::new来创建Config的实例。示例12-7显示了我们需要进行的更改。
文件名:src/main.rs
use std::env;
use std::fs;fn main() {let args: Vec<String> = env::args().collect();let config = Config::new(&args);// --snip--println!("With config:\n{} \n {}", config.query, config.file_path);
}// --snip--impl Config {fn new(args: &[String]) -> Config {let query = args[1].clone();let file_path = args[2].clone();Config { query, file_path }}
}示例12-7:将parse_config更改为Config::new

我们更新了main中调用parse_config的地方,改为调用Config::new。我们已经将parse_config的名称改为new,并将其移动到impl块中,该块将新函数与config相关联。请再次尝试编译此代码以确保它正常工作。
修复错误处理
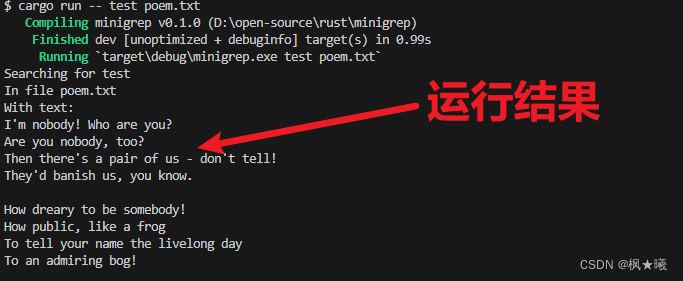
现在我们将修复我们的错误处理。回想一下,如果args向量包含的项少于三项,则尝试访问索引1或索引2处的args向量中的值将导致程序崩溃。尝试不带任何参数运行程序;它将看起来像这样:
$ cargo runCompiling minigrep v0.1.0 (file:///projects/minigrep)Finished dev [unoptimized + debuginfo] target(s) in 0.0sRunning `target/debug/minigrep`
thread 'main' panicked at 'index out of bounds: the len is 1 but the index is 1', src/main.rs:27:21
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
index out of bounds: the len is 1 but the index is 1,是一条针对程序员的错误消息。它不会帮助我们的最终用户理解他们应该做什么。让我们现在解决这个问题。
改进错误信息
在示例12-8中,我们在new函数中添加了一个检查,它将在访问索引1和2之前验证切片是否足够长。如果切片不够长,程序会惊慌并显示更好的错误消息。
文件名:src/main.rs
// --snip--fn new(args: &[String]) -> Config {if args.len() < 3 {panic!("not enough arguments");}// --snip--
示例12-8:添加对参数数量的检查
当value参数超出有效值范围时。在这里,我们不是检查值的范围,而是检查args的长度至少为3,并且函数的其余部分可以在满足该条件的假设下运行。如果args的项目少于三个,则该条件将为真,我们称之为panic!宏立即结束程序。
有了new中的这几行额外代码,让我们再次不带任何参数运行程序,看看错误现在是什么样子的:
$ cargo runCompiling minigrep v0.1.0 (file:///projects/minigrep)Finished dev [unoptimized + debuginfo] target(s) in 0.0sRunning `target/debug/minigrep`
thread 'main' panicked at 'not enough arguments', src/main.rs:26:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
这个输出更好:我们现在有了一个合理的错误消息。然而,我们也有不想给用户的无关信息。也许使用我们在之前的示例9-13中使用的技术在这里不是最好的:恐慌的呼唤!更适合于编程问题而不是使用问题。
返回结果而不是调用panic!
相反,我们可以返回一个Result,该值在成功的情况下将包含一个Config实例,并在错误的情况下描述问题。我们还将把函数名从new改为build,因为许多程序员希望新函数永远不会失败。当Config::build与main通信时,我们可以使用结果类型来表示有问题。然后,我们可以更改main,将Err变体转换为更实用的错误,这样用户就不用担心周围的关于线程“main”和RUST_BACKTRACE的panic!原因。
示例12-9显示了我们需要对我们现在调用的Config::build函数的返回值以及返回结果所需的函数体进行的更改。请注意,直到我们更新main之后才会编译,我们将在下一个清单中更新main。
文件名:src/main.rs
impl Config {fn build(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let file_path = args[2].clone();Ok(Config { query, file_path })}
}示例12-9:从Config::build返回Result
我们的build函数在成功情况下返回一个带有Config实例的Result,在错误情况下返回一个&‘static str。我们的错误值将总是具有“static生存期”的字符串文字。 我们在函数体中做了两处修改:不再调用panic!当用户没有传递足够的参数时,我们现在返回一个Err值,并且我们已经将配置返回值包装在Ok中。这些更改使函数符合其新的类型签名。
从Config::build返回一个Err值允许main函数处理从build函数返回的Result,并在出错时更干净地退出进程。
调用Config::build并处理错误
为了处理错误情况并打印用户友好的消息,我们需要更新main来处理Config::build返回的Result,如示例12-10所示。我们还将负责退出命令行工具,并给出一个非零错误代码,以免引起panic!而是手动实现。非零退出状态是一种惯例,它向调用我们程序的进程发出信号,表明程序以错误状态退出。
文件名:src/main.rs
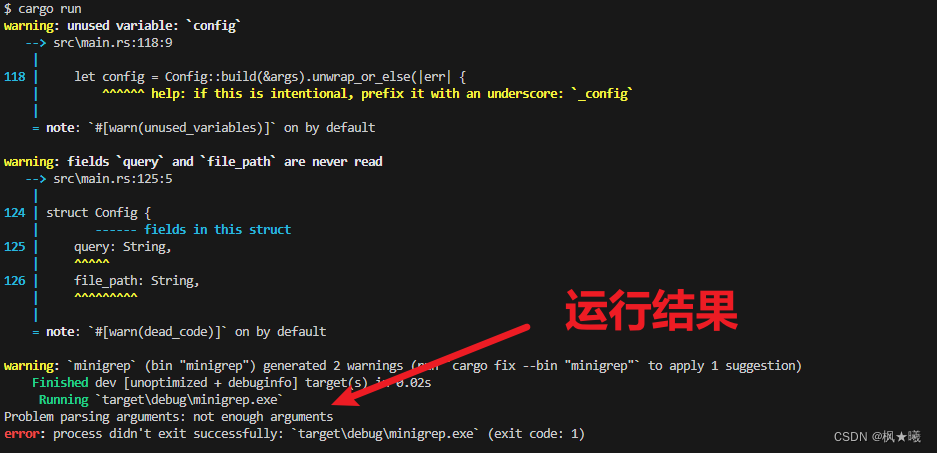
use std::process;fn main() {let args: Vec<String> = env::args().collect();let config = Config::build(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {err}");process::exit(1);});// --snip--// 全部代码
use std::env;
use std::process;fn main() {let args: Vec<String> = env::args().collect();let config = Config::build(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {err}");process::exit(1);});
}struct Config {query: String,file_path: String,
}impl Config {fn build(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let file_path = args[2].clone();Ok(Config { query, file_path })}
}示例12-10:如果构建Config失败,退出并显示错误代码
在这个示例中,我们使用了一个尚未详细介绍的方法:unwrap_or_else,它是由标准库在Result<T, E>上定义的。使用unwrap_or_else允许我们定义一些自定义的、非紧急的!错误处理。如果结果是一个Ok值,该方法的行为类似于unwrap:它返回Ok正在换行的内部值。但是,如果该值是一个Err值,该方法将调用闭包中的代码,这是一个我们定义的匿名函数,并作为参数传递给unwrap_or_else。我们将在后续章节更详细地讨论闭包。现在,您只需要知道unwrap_or_else将把err的内部值传递给出现在竖线之间的参数Err中的闭包,在本例中,该值是我们在示例12-9中添加的静态字符串“not follow arguments”。闭包中的代码可以在运行时使用err值。
我们添加了一个新的use行,将标准库中的process纳入范围。在错误情况下运行的闭包中的代码只有两行:我们打印err值,然后调用process::exit。process::exit函数将立即停止程序并返回作为退出状态代码传递的数字。这类似于panic!我们在示例12-8中使用的基于的处理,但是我们不再得到所有额外的输出。让我们来试试:
$ cargo runCompiling minigrep v0.1.0 (file:///projects/minigrep)Finished dev [unoptimized + debuginfo] target(s) in 0.48sRunning `target/debug/minigrep`
Problem parsing arguments: not enough arguments
太好了!这个输出对我们的用户更友好。
从main提取逻辑
现在我们已经完成了配置解析的重构,让我们转向程序的逻辑。正如我们在“二进制项目的关注点分离”中所述,我们将提取一个名为run的函数,该函数将保存main函数中当前不涉及设置配置或处理错误的所有逻辑。当我们完成时,main将简洁并易于检查验证,我们将能够为所有其他逻辑编写测试。
示例12-11显示了提取的run函数。目前,我们只是对提取函数进行了微小的、渐进的改进。我们仍在定义src/main.rs中的函数。
文件名:src/main.rs
fn main() {// --snip--println!("Searching for {}", config.query);println!("In file {}", config.file_path);run(config);
}fn run(config: Config) {let contents = fs::read_to_string(config.file_path).expect("Should have been able to read the file");println!("With text:\n{contents}");
}// --snip--
// 全部代码
use std::env;
use std::process;
use std::fs;fn main() {// --snip--let args: Vec<String> = env::args().collect();let config = Config::build(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {err}");process::exit(1);});println!("Searching for {}", config.query);println!("In file {}", config.file_path);run(config);
}struct Config {query: String,file_path: String,
}fn run(config: Config) {let contents = fs::read_to_string(config.file_path).expect("Should have been able to read the file");println!("With text:\n{contents}");
}impl Config {fn build(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let file_path = args[2].clone();Ok(Config { query, file_path })}
}
示例12-11:提取包含剩余程序逻辑的run函数
run函数现在包含main中所有剩余的逻辑,从读取文件开始。run函数将Config实例作为参数。
从运行函数返回错误
通过将剩余的程序逻辑分离到run函数中,我们可以改进错误处理,就像我们在示例12-9中对Config::build所做的那样。当出现问题时,run函数将返回Result<T, E>,而不是通过调用expect让程序崩溃。这将让我们以用户友好的方式进一步巩固main中处理错误的逻辑。示例12-12显示了我们需要对run的签名和主体进行的更改。
文件名:src/main.rs
use std::error::Error;// --snip--fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.file_path)?;println!("With text:\n{contents}");Ok(())
}// 全部代码
use std::error::Error;
use std::env;
use std::process;
use std::fs;fn main() { let args: Vec<String> = env::args().collect();let config = Config::build(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {err}");process::exit(1);});println!("Searching for {}", config.query);println!("In file {}", config.file_path);run(config);
}struct Config {query: String,file_path: String,
}fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.file_path)?;println!("With text:\n{contents}");Ok(())
}impl Config {fn build(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let file_path = args[2].clone();Ok(Config { query, file_path })}
}示例12-12:将run函数更改为返回Result
我们在这里做了三个重大改变。首先,我们将run函数的返回类型更改为Result<(),Box<dyn Error>>。该函数先前返回了单元类型(),我们将其作为Ok情况下的返回值。
对于错误类型,我们使用了trait对象Box<dyn Error>并且我们将std::error::Error纳入了范围,并在顶部使用了一条use语句)。我们将在后续章节讨论特征对象。现在,只需知道Box<dyn Error>意味着函数将返回实现错误特征的类型,但我们不必指定返回值将是什么特定类型。这给了我们在不同错误情况下返回不同类型的错误值的灵活性。dyn关键字是“dynamic”的缩写 。
其次,我们删除了对expect的调用,转而使用?运算符,正如我们在前面章节中讨论的那样。而不是panic!出错时?将从当前函数返回错误值供调用方处理。
第三,run函数现在在成功的情况下返回一个Ok值。我们已经在签名中将run函数的成功类型声明为(),这意味着我们需要将单元类型值包装在Ok值中。这个Ok(())语法一开始看起来可能有点奇怪,但是像这样使用()是惯用的方式,表明我们调用run只是为了它的副作用;它没有返回我们需要的值。
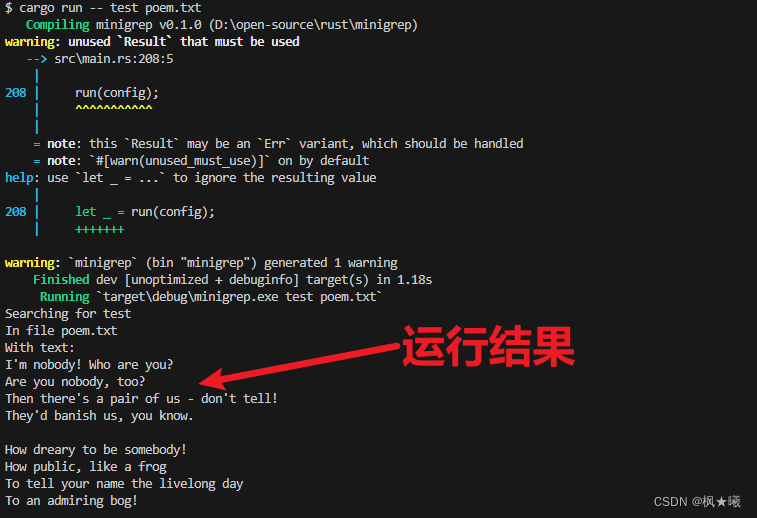
当您运行此代码时,它会编译,但会显示一条警告:
$ cargo run the poem.txtCompiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used--> src/main.rs:19:5|
19 | run(config);| ^^^^^^^^^^^|= note: this `Result` may be an `Err` variant, which should be handled= note: `#[warn(unused_must_use)]` on by defaultwarning: `minigrep` (bin "minigrep") generated 1 warningFinished dev [unoptimized + debuginfo] target(s) in 0.71sRunning `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!Rust告诉我们,我们的代码忽略了Result,Result可能表明发生了错误。但是我们没有检查是否有错误,编译器提醒我们这里可能有一些错误处理代码!让我们现在纠正这个问题。
处理运行main返回的错误
我们将使用与示例12-10中的Config::build类似的技术来检查错误并处理它们,但略有不同:
文件名:src/main.rs
fn main() {// --snip--println!("Searching for {}", config.query);println!("In file {}", config.file_path);if let Err(e) = run(config) {println!("Application error: {e}");process::exit(1);}
}// 全部代码
use std::error::Error;
use std::env;
use std::process;
use std::fs;fn main() { let args: Vec<String> = env::args().collect();let config = Config::build(&args).unwrap_or_else(|err| {println!("Problem parsing arguments: {err}");process::exit(1);});println!("Searching for {}", config.query);println!("In file {}", config.file_path);if let Err(e) = run(config) {println!("Application error: {e}");process::exit(1);}
}struct Config {query: String,file_path: String,
}fn run(config: Config) -> Result<(), Box<dyn Error>> {let contents = fs::read_to_string(config.file_path)?;println!("With text:\n{contents}");Ok(())
}impl Config {fn build(args: &[String]) -> Result<Config, &'static str> {if args.len() < 3 {return Err("not enough arguments");}let query = args[1].clone();let file_path = args[2].clone();Ok(Config { query, file_path })}
}
我们使用if let而不是unwrap_or_else来检查run是否返回Err值,如果返回则调用process::exit(1)。run函数不会像Config::build返回Config实例那样返回我们想要解开的值。因为run在成功的情况下返回(),所以我们只关心检测到错误,所以我们不需要unwrap_or_else来返回未包装的值,它只会是()。
if let和unwrap_or_else函数的主体在两种情况下是相同的:我们打印错误并退出。
将代码拆分到一个Carte中
我们的minigrep项目到目前为止看起来不错!现在我们将拆分src/main.rs文件,并将一些代码放入src/lib.rs文件中。这样我们就可以测试代码,并得到一个责任更少的src/main.rs文件。
让我们将所有不是main函数的代码从src/main.rs移到src/lib.rs:
- run函数定义
- 相关的use声明
- Config的定义
- Config::build函数定义
src/lib.rs的内容应该具有示例12-13所示的签名(为了简洁起见,我们省略了函数体)。注意,在我们修改示例12-14中的src/main.rs之前,这不会编译。
文件名:src/lib.rs
use std::error::Error;
use std::fs;pub struct Config {pub query: String,pub file_path: String,
}impl Config {pub fn build(args: &[String]) -> Result<Config, &'static str> {// --snip--}
}pub fn run(config: Config) -> Result<(), Box<dyn Error>> {// --snip--
}示例12-13:将Config和run移入src/lib.rs
我们已经自由地使用了pub关键字:在Config、它的字段和build方法以及run函数上。我们现在有一个库箱,它有一个我们可以测试的公共API!
现在我们需要将移动到src/lib.rs的代码放入src/main.rs中的二进制crate的范围内,如示例12-14所示。
文件名:src/main.rs
use std::env;
use std::process;use minigrep::Config;fn main() {// --snip--if let Err(e) = minigrep::run(config) {// --snip--}
}示例12-14:在src/main.rs中使用minigrep crate
我们添加一个use minigrep::Config行,将库crate中的配置类型引入二进制crate的范围,并在run函数前面加上crate名称。现在,所有功能都应该连接起来并正常工作。用cargo run运行程序,并确保一切正常。
咻!这是一项艰巨的任务,但我们已经为未来的成功做好了准备。现在处理错误要容易得多,我们已经使代码更加模块化。从现在开始,我们几乎所有的工作都将在src/lib.rs中完成。
让我们利用这一新发现的模块性,做一些在旧代码中很难但在新代码中很容易做到的事情:我们将编写一些测试!
本章重点
-
重构项目的意义:模块化,错误处理
-
项目分离的意义和操作步骤
-
如何提取参数解析器
-
对配置值分组的操作
-
修复和改进错误处理
-
错误处理的主要方法


)


:Git概述)




暨小程送书)
![[STM32F407ZET6] GPIO](http://pic.xiahunao.cn/[STM32F407ZET6] GPIO)

(一))





)