理解KNN 算法原理
KNN是监督学习分类算法,主要解决现实生活中分类问题。
根据目标的不同将监督学习任务分为了分类学习及回归预测问题。
监督学习任务的基本流程和架构:
(1)首先准备数据,可以是视频、音频、文本、图片等等
(2)抽取所需要的一些列特征,形成特征向量(Feature Vectors)。
(3)将这些特征向量连同标记一并送入机器学习算法中,训练出一个预测模型。
(4)然后,采用同样的特征提取方法作用于新数据,得到用于测试的特征向量。
(5)最后,使用预测模型对这些待测的特征向量进行预测并得到结果(Expected Model)。
KNN(K-Nearest Neihbor,KNN)K近邻是机器学习算法中理论最简单,最好理解的算法,是一个非常适合入门的算法,拥有如下特性:
-
思想极度简单,应用数学知识少(近乎为零),对于很多不擅长数学的小伙伴十分友好
-
虽然算法简单,但效果也不错
如果要了解一个人的经济水平,只需要知道他最好的5个朋友的经济能力, 对他的这五个人的经济水平求平均就是这个人的经济水平。这句话里面就包含着kNN的算法思想。
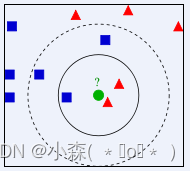
如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
类别的判定
①投票决定,少数服从多数。取类别最多的为测试样本类别。
②加权投票法,依据计算得出距离的远近,对近邻的投票进行加权,距离越近则权重越大,设定权重为距离平方的倒数。
KNN 算法原理简单,不需要训练,属于监督学习算法,常用来解决分类问题
KNN原理:先确定K值, 再计算距离,最后挑选K个最近的邻居进行投票
KNN的应用
KNN即能做分类又能做回归, 还能用来做数据预处理的缺失值填充。由于KNN模型具有很好的解释性,对于每一个预测结果,我们可以很好的进行解释。文章推荐系统中, 对于一个用户A,我们可以把和A最相近的k个用户,浏览过的文章推送给A。
算法的思想:通过K个最近的已知分类的样本来判断未知样本的类别。
KNN三要素:
- 距离度量
- K值选择
- 分类决策准则
鸢尾花数据集
鸢尾花Iris Dataset数据集是机器学习领域经典数据集,鸢尾花数据集包含了150条鸢尾花信息,每50条取自三个鸢尾花中之一:Versicolour、Setosa和Virginica
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifieriris = load_iris() #通过iris.data 获取数据集中的特征值 iris.target获取目标值
# 数据标准化
transformer = StandardScaler()
x_ = transformer.fit_transform(iris.data) # iris.data 数据的特征值# 模型训练
estimator = KNeighborsClassifier(n_neighbors=3) # n_neighbors 邻居的数量,也就是Knn中的K值
estimator.fit(x_, iris.target) # 调用fit方法 传入特征和目标进行模型训练
# 利用模型预测
result = estimator.predict(x_)
print(result)
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 2 11 1 1 1 1 1 1 1 1 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 1 2 2 2 22 2 2 2 2 2 2 2 1 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 2 2 2 2 2 2 2 2 2 2 2 2 22 2]sklearn中自带了几个学习数据集,都封装在sklearn.datasets 这个包中,加载数据后,通过data属性可以获取特征值,通过target属性可以获取目标值。
Demo数据集--kNN分类
1: 库函数导入
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.neighbors import KNeighborsClassifier
from sklearn import datasets2: 数据导入
iris = datasets.load_iris()
X = iris.data[:, :2]
y = iris.target3: 模型训练
k_list = [1, 3, 5, 8, 10, 15]
h = .02
# 创建不同颜色画布
cmap_light = ListedColormap(['orange', 'cyan', 'cornflowerblue'])
cmap_bold = ListedColormap(['darkorange', 'c', 'darkblue'])plt.figure(figsize=(15,14))
# 根据不同的k值进行可视化
for ind,k in enumerate(k_list):clf = KNeighborsClassifier(k)clf.fit(X, y)x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)plt.subplot(321+ind) plt.pcolormesh(xx, yy, Z, cmap=cmap_light)plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold,edgecolor='k', s=20)plt.xlim(xx.min(), xx.max())plt.ylim(yy.min(), yy.max())plt.title("3-Class classification (k = %i)"% k)plt.show()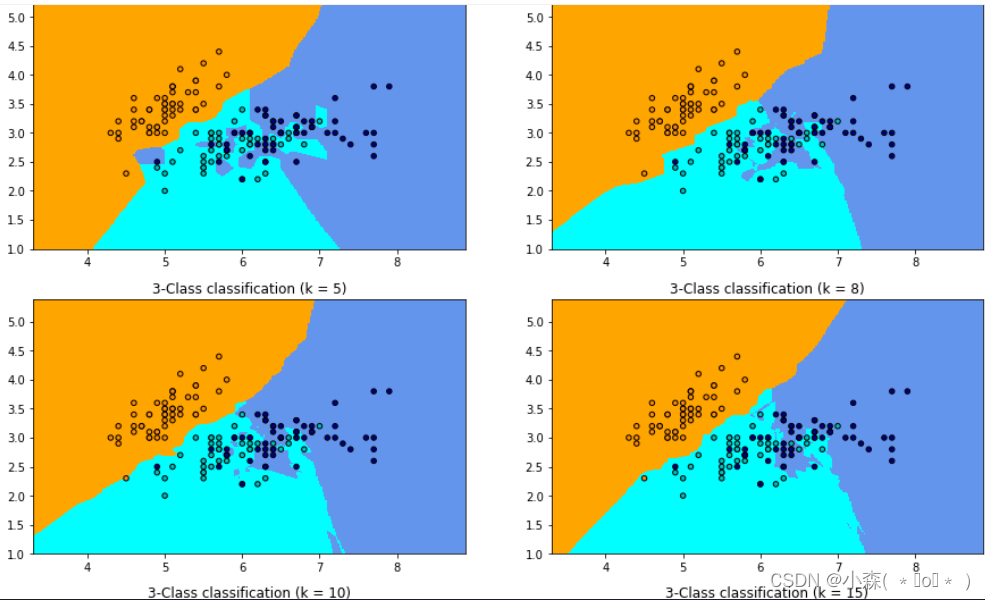
当k=1的时候,在分界点位置的数据很容易受到局部的影响,图中蓝色的部分中还有部分绿色块,主要是数据太局部敏感。当k=15的时候,不同的数据基本根据颜色分开,当时进行预测的时候,会直接落到对应的区域。
数据集划分
不能将所有数据集全部用于训练,为了能够评估模型的泛化能力,可以通过实验测试对学习器的泛化能力进行评估,进而做出选择。因此需要使用一个测试集来测试学习器对新样本的判别能力。
测试集要代表整个数据集、与训练集互斥、测试集与训练集建议比例: 2比8、3比7。
数据集划分的方法
1.将数据集划分成两个互斥的集合:训练集,测试集。
- 训练集用于模型训练
- 测试集用于模型验证
2.将数据集划分为训练集,验证集,测试集
- 训练集用于模型训练
- 验证集用于参数调整
- 测试集用于模型验证
1:将数据集 D 划分为两个互斥的集合,其中一个集合作为训练集 S,另一个作为测试集 T。
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import ShuffleSplit
from collections import Counter
from sklearn.datasets import load_irisdef te1():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)print('随机类别分割:', Counter(y_train), Counter(y_test))x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y)print('分层类别分割:', Counter(y_train), Counter(y_test))def te2():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 40)# 2. 多次划分spliter = ShuffleSplit(n_splits=5, test_size=0.2, random_state=0)for train, test in spliter.split(x, y):print('随机多次分割:', Counter(y[test]))spliter = StratifiedShuffleSplit(n_splits=5, test_size=0.2, random_state=0)for train, test in spliter.split(x, y):print('分层多次分割:', Counter(y[test]))if __name__ == '__main__':te1()te2()# 随机类别分割: Counter({0: 43, 2: 40, 1: 37}) Counter({1: 13, 2: 10, 0: 7})
# 分层类别分割: Counter({1: 40, 2: 40, 0: 40}) Counter({2: 10, 1: 10, 0: 10})
随机多次分割: Counter({1: 13, 0: 11, 2: 6})
随机多次分割: Counter({1: 12, 2: 10, 0: 8})
随机多次分割: Counter({1: 11, 0: 10, 2: 9})
随机多次分割: Counter({2: 14, 1: 9, 0: 7})
随机多次分割: Counter({2: 13, 0: 12, 1: 5})分层多次分割: Counter({0: 10, 1: 10, 2: 10})
分层多次分割: Counter({2: 10, 0: 10, 1: 10})
分层多次分割: Counter({0: 10, 1: 10, 2: 10})
分层多次分割: Counter({1: 10, 2: 10, 0: 10})
分层多次分割: Counter({1: 10, 2: 10, 0: 10}) K-Fold交叉验证,将数据随机且均匀地分成k分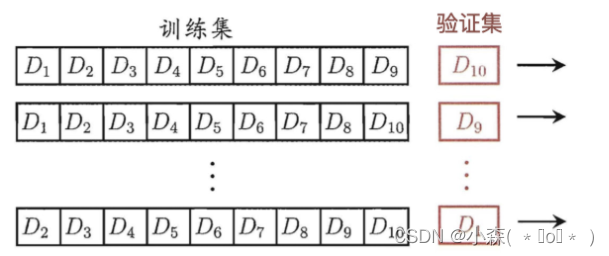
- 第一次使用标号为0-8的共9份数据来做训练,而使用标号为9的这一份数据来进行测试,得到一个准确率
- 第二次使用标记为1-9的共9份数据进行训练,而使用标号为0的这份数据进行测试,得到第二个准确率
- 共进行10次训练,最后模型的准确率为10次准确率的平均值,避免了数据划分而造成的评估不准确。
from sklearn.model_selection import KFold
from sklearn.model_selection import StratifiedKFold
from collections import Counter
from sklearn.datasets import load_irisdef test():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 30)# 2. 随机交叉验证spliter = KFold(n_splits=5, shuffle=True, random_state=0)for train, test in spliter.split(x, y):print('随机交叉验证:', Counter(y[test]))print('*' * 30)# 3. 分层交叉验证spliter = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)for train, test in spliter.split(x, y):print('分层交叉验证:', Counter(y[test]))test()
数据划分结果:
随机交叉验证: Counter({1: 13, 0: 11, 2: 6})
随机交叉验证: Counter({2: 15, 1: 10, 0: 5})
随机交叉验证: Counter({0: 10, 1: 10, 2: 10})
随机交叉验证: Counter({0: 14, 2: 10, 1: 6})
随机交叉验证: Counter({1: 11, 0: 10, 2: 9})
****************************************
分层交叉验证: Counter({0: 10, 1: 10, 2: 10})
分层交叉验证: Counter({0: 10, 1: 10, 2: 10})
分层交叉验证: Counter({0: 10, 1: 10, 2: 10})
分层交叉验证: Counter({0: 10, 1: 10, 2: 10})
分层交叉验证: Counter({0: 10, 1: 10, 2: 10})
留一法:每次抽取一个样本做为测试集。
from sklearn.model_selection import LeaveOneOut
from sklearn.model_selection import LeavePOut
from sklearn.datasets import load_iris
from collections import Counterdef test01():# 1. 加载数据集x, y = load_iris(return_X_y=True)print('原始类别比例:', Counter(y))print('*' * 40)spliter = LeaveOneOut()for train, test in spliter.split(x, y):print('训练集:', len(train), '测试集:', len(test), test)test01()分类算法的评估
-
利用训练好的模型使用测试集的特征值进行预测
-
将预测结果和测试集的目标值比较,计算预测正确的百分比
-
百分比就是准确率, 准确率越高说明模型效果越好
确定合适的K值
K值过小:容易受到异常点的影响
k值过大:受到样本均衡的问题,K一般取一个较小的数值。
使用 scikit-learn 提供的 GridSearchCV 工具, 配合交叉验证法可以搜索参数组合
x, y = load_iris(return_X_y=True)# 分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, stratify=y, random_state=0)estimator = KNeighborsClassifier()
grid = {'n_neighbors': [1, 3, 5]}
estimator = GridSearchCV(estimator, param_grid=grid, cv=5)
estimator.fit(x_train, y_train)K近邻算法的优缺点:
- 优点:简单,易于理解,容易实现
- 缺点:算法复杂度高,结果对K取值敏感,容易受数据分布影响
knn算法中我们最需要关注两个问题:k值的选择和距离的计算。
距离/相似度的计算:
样本之间的距离的计算,我们一般使用对于一般使用Lp距离进行计算。当p=1时候,称为曼哈顿距离,当p=2时候,称为欧氏距离,当p=∞时候,称为极大距离。一般采用欧式距离较多。






![[C++]:12:模拟实现list](https://img-blog.csdnimg.cn/direct/48a71ddd24cd455cb05f9107cb3c898a.png)