整理了GMU(ICLR2017 GATED MULTIMODAL UNITS FOR INFORMATION FUSION)论文的阅读笔记
- 背景
- 模型
- 实验
论文地址: GMU
背景
多模态指的是同一个现实世界的概念可以用不同的视图或数据类型来描述。比如维基百科有时会用音频的混合来描述一个名人;来自社交网络的用户用文本和多媒体附件(图像/视频/音频)评论音乐会或体育比赛等事件。医疗记录由图像、声音、文本和信号等的集合表示。之前的方法往往是基于单模态的,这很明显是不完善的,多模态的必要性已经在论文What Makes Multi-modal Learning Better than Single (Provably)中被证明。
多模态融合的任务往往寻求生成单一表示,在构建分类器或其他预测器时使自动分析任务变得更容易。一种简单的方法是连接特征以获得最终表示,虽然这是一个直截了当的策略,但它忽略了不同模式之间的内在相关性
在这项工作中,基于门的思想设计了一个新的模块,被称为门控多模态单元(GMU)它可以结合多个信息源,并对最终目标目标函数进行了优化,用于选择输入的哪些部分更有可能正确地生成所需的输出。使用同时为各种特征分配重要性的乘法门,创建一个丰富的多模态表示,不需要手动调整,而是直接从训练数据中学习。

图中是多模态任务的一个例子,描述了仅根据一种模态的使用为特定电影分配类型的任务。根据输入方式预测的类型标签。红色和蓝色标签分别表示假阳性和真阳性。可以看到,基于单模态的预测结果往往是不完善的或是有误的,在GMU中,使用门控单元的模型将能够学习依赖于输入的门激活模式,该模式决定了每个模态如何对隐藏单元的输出做出贡献。
模型
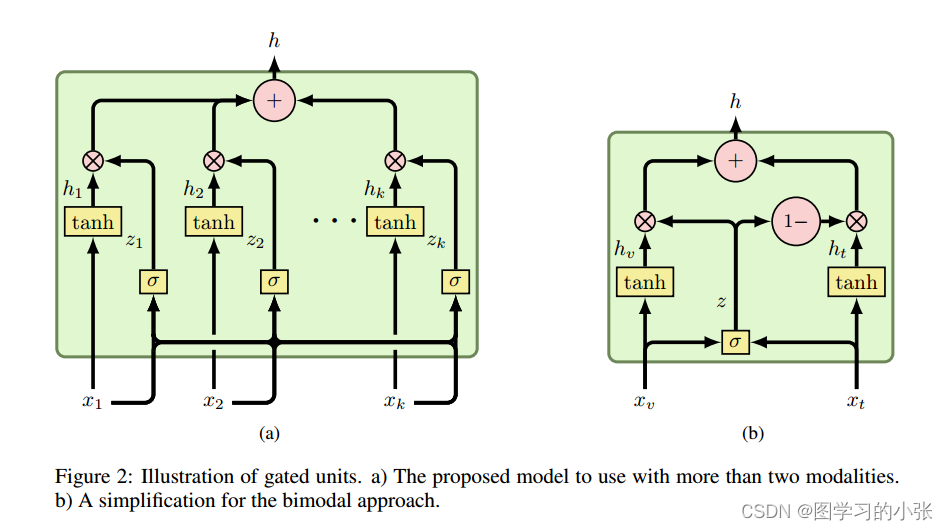
本文的GMU模块,左图是多模态的情况下,右图是双峰情况,对来自不同模态的单峰特征进行融合。
在左图中每个 x i x_i xi对应一个与模态 i i i相关的特征向量。每个特征向量经过激活函数后提供给融合单元,该函数旨在基于特定模态编码一个内部表示特征。对于每个输入模态 x i x_i xi,都有一个门神经元(在图中由 σ \sigma σ节点表示) x i x_i xi计算的特征对模块整体输出的贡献。当一个新的样本被输入到网络中时,与模态 i i i相关联的门神经元接收来自所有模态的特征向量作为输入,并使用它们来决定模态 i i i是否对特定输入样本的内部编码的贡献程度。
右图显示了两种输入模态的GMU的简化版本, x v x_v xv(视觉模态)和 x t x_t xt(文本模态),这将在本文的其余部分中使用。应该注意的是,这两个模型不是完全等效的,因为在双峰情况下闸门是捆绑的,只用了一个 σ \sigma σ。本文的实验都是基于右图双峰状态下的GMU。
公式:

x v x_v xv(视觉模态)和 x t x_t xt(文本模态)分别先经过一个线性变换和一个激活函数引入非线性,生成所谓的内部表示特征, σ \sigma σ门在文中使用的是一个sigmoid函数,产生0,1之间的值,相当于权重,最后根据这个值进行特征融合。
实验
实验中在电影分类(MM-IMDb)数据集上进行,其中包含27000部电影。不包含海报图像的电影被过滤掉。最终得到的MM-IMDb数据集包括25959部电影及其情节、海报、类型和其他50个额外的元数据字段,如年份、语言、作家、导演、宽高比等。
实验中使用的多模态模型中单峰特征分别来自预训练的VGG和Word2vec,经过实验认为这两个是最好的。数据集的统计:
图4是电影海报的尺寸和长度分布,图5是文本的长度分布。
对比的baseline:平均、concat、线性映射到相同维度再融合、专家网络。

实验结果:
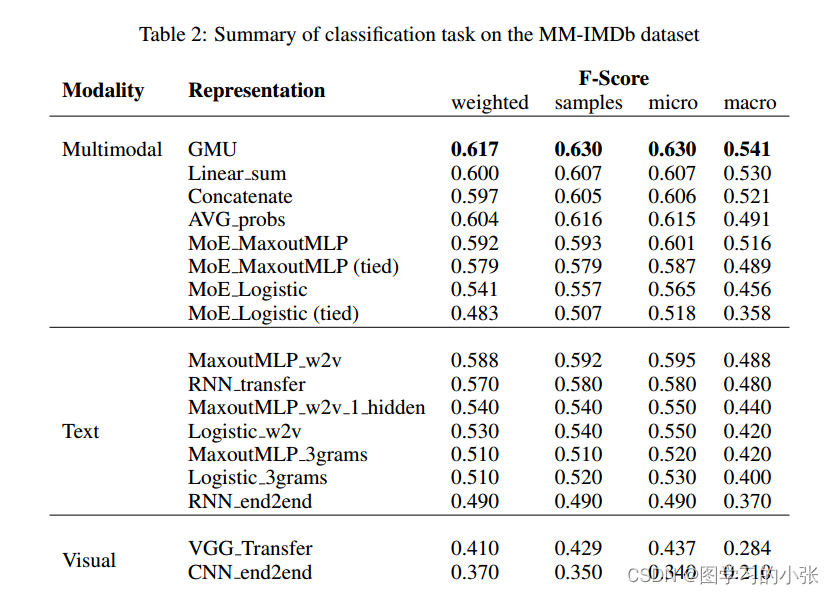
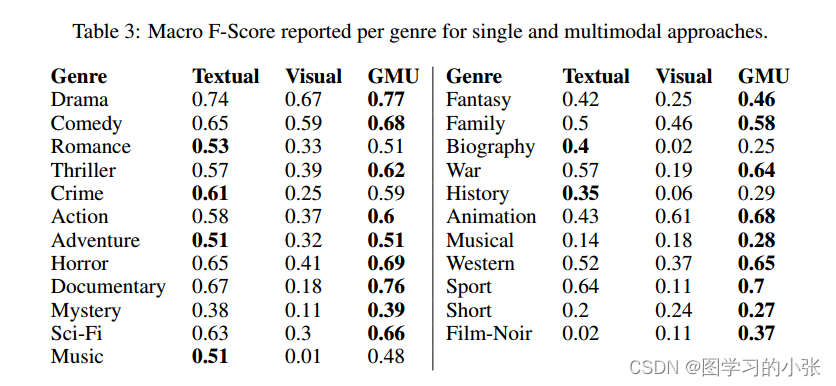
表二是整体的准确率,表三是在不同类别样本上单模和多模模型的变现,GMU在25个类别中的16个超过了最好的单峰模型的表现,作者统计了不同类别样本的多模权重均值:
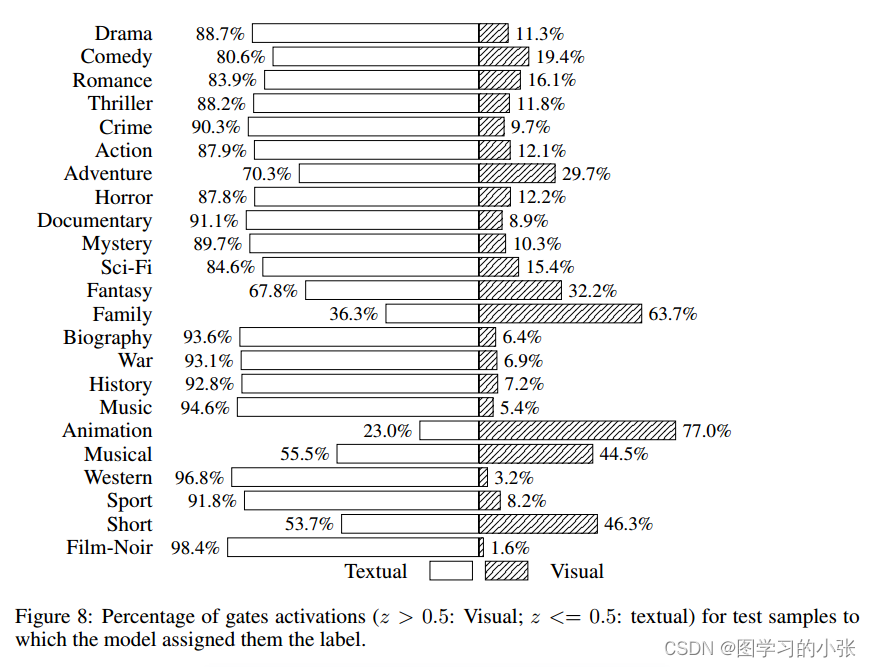
在表3中我们发现在这个任务上文本模型常常比图像模型更有效,而我们得到的权重正如预期的那样,模式通常更受文本情态的影响。但是,在动画或家庭类型等特殊情况下,视觉形式对模型的影响更大。这也与表3的结果一致,视觉模型在这些类别上有更好的表现。几个实验的例子:


基于CNN-Bi_LSTM的多维回归预测(卷积神经网络-双向长短期记忆网络))



:模型预测)





JavaScript事件分析)


Goal-Auxiliary Actor-Critic for 6D Robotic Grasping with Point Clouds)




