说明:
- 面试群,群号: 228447240
- 面试题来源于网络书籍,公司题目以及博主原创或修改(题目大部分来源于各种公司);
- 文中很多题目,或许大家直接编译器写完,1分钟就出结果了。但在这里博主希望每一个题目,大家都要经过认真思考,答案不重要,重要的是通过题目理解所考知识点,好应对题目更多的变化;
- 博主与大家一起学习,一起刷题,共同进步;
- 写文不易,麻烦给个三连!!!
- 操作系统篇
1.说说多路IO复用技术有哪些,区别是什么?
答案:
select:
- select 是最早的多路 I/O 复用技术,适用于所有平台。
- 它通过一个文件描述符集合来监视多个文件描述符的状态变化,包括可读、可写和异常等。
- 使用简单,但有两个主要限制:每次调用都需要线性扫描整个描述符集合,效率较低;同时支持的文件描述符数量有限。
poll:
- poll 是对 select 的改进,同样适用于所有平台。
- 它使用一个结构体数组来存储要监视的文件描述符和事件,不再有文件描述符数量的限制。
- 相比 select,poll 没有了线性扫描的开销,但仍然需要遍历整个结构体数组,对于大量的文件描述符仍然效率较低。
epoll:
- epoll 是 Linux 特有的多路 I/O 复用技术,具有更高的性能。
- 它使用三个系统调用(epoll_create、epoll_ctl、epoll_wait)来操作和管理事件。
- epoll 通过内核事件表来存储需要监控的文件描述符和事件,只返回发生变化的文件描述符,避免了遍历整个列表的开销。
- 支持水平触发和边缘触发两种工作模式,并且可以通过 epoll_ctl 动态地增加、删除或修改监控的文件描述符。
2.epoll为什么高效(拷贝、查询、返回)
答案:
- select,poll实现需要自己不断轮询所有fd集合,直到设备就绪,期间可能要睡眠和唤醒多次交替。而epoll只要判断一下就绪链表是否为空就行了,这节省了大量的CPU时间。
- select,poll每次调用都要把fd集合从用户态往内核态拷贝一次,并且要把当前进程往设备等待队列中挂一次,而epoll只要一次拷贝,而且把当前进程往等待队列上挂也只挂一次,这也能节省不少的开销。
- 当我们调用 epoll_wait() 函数返回的不是实际的描述符,而是一个代表就绪描述符数量的值,这个时候需要去 epoll 指定的一个数组中(epoll_event)定义的结构体依次取得相应数量的 socket 描述符即可,这个数组里面保存的都是可以的文件描述符,而不需要遍历扫描所有的 socket 描述符,因此这里的时间复杂度是 O(1),这里和select的区别是select返回的也是可用的数量,但是并没有告诉你可用的文件描述符是谁,你必须得遍历全部的文件描述符,才知道是那些就绪了。
3.硬链接与软链接
答案:
链接操作实际上是给系统中已有的某个文件指定另外一个可用于访问它的名称。对于这个新的文件名,我们可以为之指定不同的访问权限,以控制对信息的共享和安全性的问题。如果链接指向目录,用户就可以利用该链接直接进入被链接的目录而不用打一大堆的路径名。而且,即使我们删除这个链接,也不会破坏原来的目录。
1>硬链接
硬链接只能引用同一文件系统中的文件。它引用的是文件在文件系统中的物理索引(也称为inode)。当您移动或删除原始文件时,硬链接不会被破坏,因为它所引用的是文件的物理数据而不是文件在文件结构中的位置。硬链接的文件不需要用户有访问原始文件的权限,也不会显示原始文件的位置,这样有助于文件的安全。如果您删除的文件有相应的硬链接,那么这个文件依然会保留,直到所有对它的引用都被删除。
2>软链接(符号链接)
软连接,其实就是新建立一个文件,这个文件就是专门用来指向别的文件的。软连接产生的是一个新的文件,但这个文件的作用就是专门指向某个文件的,删了这个软连接文件,那就等于不需要这个连接,和原来的存在的实体原文件没有任何关系,但删除原来的文件,则相应的软连接不可用。
一句话总结:硬链接是复制,软链接是快捷方式
4.说说静态库和动态库怎么制作及如何使用
答案:
静态库:
静态库名字一般为“libxxx.a”。利用静态库编译生成的可执行文件比较大,因为整个函数库的所有数据都被整合进了可执行文件中。
优点:
(1) 不需要外部函数库支持。
(2) 加载速度快。
缺点:
(1) 静态库升级时,程序需要重新编译。
(2) 多个程序调用相同库,静态库会重复调入内存,造成内存的浪费。
静态库的制作,如下:
$ gcc add.c -o add.o -c
$ ar -rc libadd.a add.o
静态库的使用,例子如下:
$ gcc main.c -o output -ladd -L.
解析一下,“-L”用来表示库在哪里,上例中库在当前目录里(“.”表示当前目录),“-l”用来表示库的名字(-ladd 表示库 libadd)。
动态库
动态库名字一般为“libxxx.so”,又称共享库。动态库在编译的时候没有被编译进可执行文件,所以可执行文件比较小。程序运行时,操作系统帮我们找到库,并跟程序链接起来。
优点:多个程序可以使用同一个动态库,节省内存。
缺点:加载速度慢。
动态库的制作,如下:
$ gcc -shared -fPIC lib.c -o libtest.so
$ sudo cp libtest.so /usr/lib/
动态库的使用,如下:
$ gcc main.c -L. -ltest -o output
链接时指定库在当前目录,但是运行时用的是/usr/lib 或/lib 目录下的库。
5.简述Linux系统态与用户态,什么时候会进入系统态?
答案:
内核态 是指拥有最高权限,可以访问所有的指令;
用户态 只能访问一部分指令;
什么时候进入内核态:
a.系统调用(主动)
b.异常
c.设备中断
为什么区分用户态和内核态:
在cpu中有些指令比较危险,如果用错就会导致系统崩溃,比如清内存
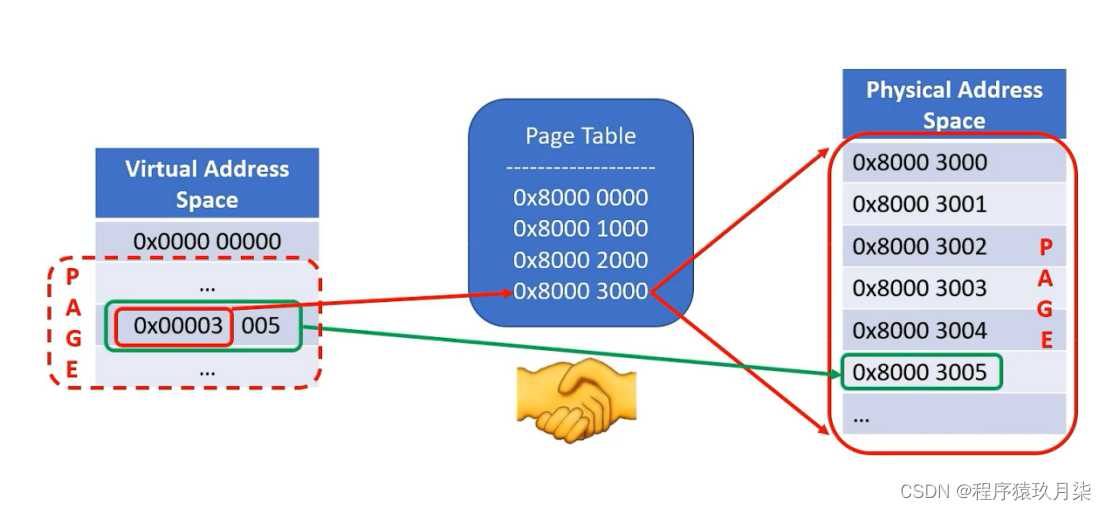
6.什么是页表,为什么要有?
答案:
页表是虚拟内存的概念,虚拟内存映到物理内存的映射表,就是页表。
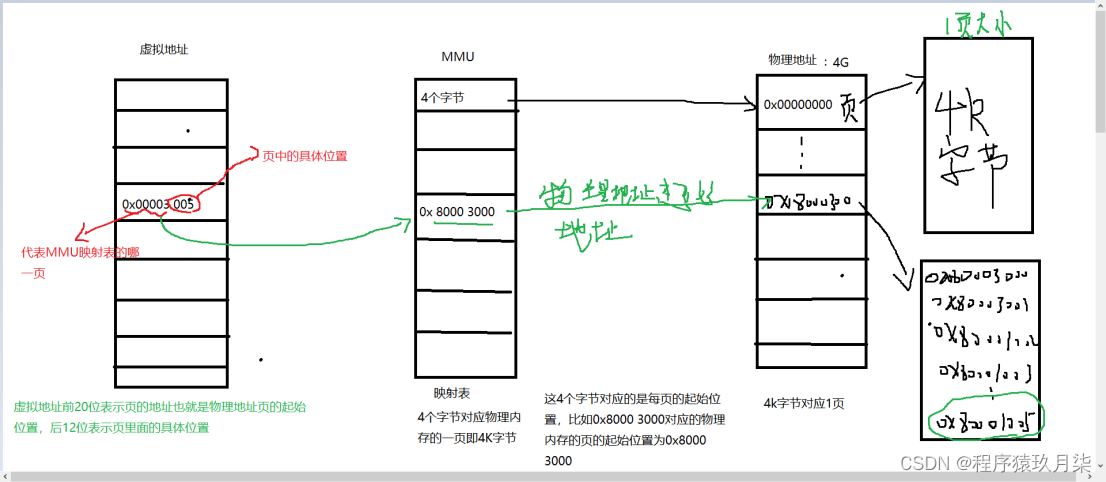
原因:虚拟内存要和物理地址映射起来,就必须要通过映射表找到物理地址,如果将每一个虚拟内存的 Byte 都对应到物理内存的地址,每个条目最少需要 8字节(32位虚拟地址->32位物理地址),在 4G 内存的情况下,就需要 32GB 的空间来存放对照表,那么这张表就大得真正的物理地址也放不下了,于是操作系统引入了页(Page)的概念,使用4个字节的映射就对应物理内存的1页—>4k内存,这样把全部虚拟地址映射到页表就会节省很大空间。
一般来说进程的虚拟地址要想找到物理地址就必须通过MMU,MMU里面放的就是映射表,通过虚拟内存的高20位知道自己在映射表的位置,也就是对应的物理地址的页起始位置,虚拟地址的低12位对应物理地址的页里面的具体地址。
比如:0x00003 005中前20位对应映射表的0x80003000,那么就会去找物理地址0x8000 3000为起始的页,005表示在页中的第几个,这样就可以找到具体物理地址
由于映射表是4个字节就映射物理地址的1页即4k,那么映射完整个物理地址之后就会节省大量空间,不同进程之间的页表是不一样的。
7.简述操作系统中malloc的实现原理
答案:
malloc底层实现:
当开辟的空间小于 128K 时,调用 brk()函数;
当开辟的空间大于 128K 时,调用mmap();
malloc采用的是内存池的管理方式,以减少内存碎片。先申请大块内存作为堆区,然后将堆区分为多个内存块。当用户申请内存时,直接从堆区分配一块合适的空闲快。采用隐式链表将所有空闲块记录,每一个空闲块记录了一个未分配的、连续的内存地址。
8.简述操作系统中的缺页中断。
答案:
malloc和mmap函数在内存分配时只是建立了进程的虚拟地址,并没有分配虚拟地址对应的物理内存,当进程访问这些没有建立映射关系的虚拟内存时,处理器自动触发一个缺页异常,引发缺页中断。
缺页异常后将产生一个缺页中断,此时操作系统会根据页表中的外存地址在外存中找到所缺的一页,将其调入内存。
9.简述mmap的原理和使用场景
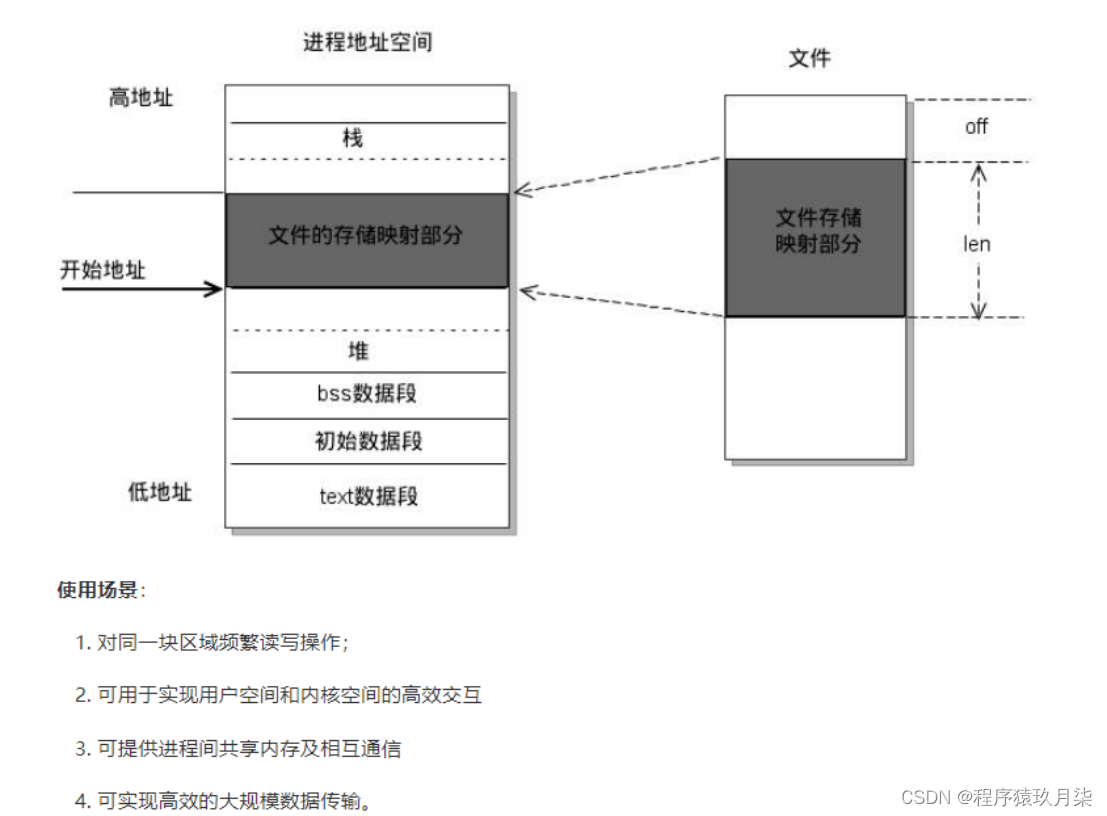
答案:
原理: mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read, write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享
10.为什么使用虚拟内存
答案:
(1)扩大地址空间。每个进程独占一个4G空间,虽然真实物理内存没那么多。
(2)内存保护:防止不同进程对物理内存的争夺和践踏,可以对特定内存地址提供写保护,防止恶意篡改。
(3)可以实现内存共享,方便进程通信。
(4)可以避免内存碎片,虽然物理内存可能不连续,但映射到虚拟内存上可以连续。
11.用户空间和内核空间的通信方式
答案:
1. 使用内核提供的API函数
copy_from_user函数的原型:
unsigned long copy_from_user(void *to, const void __user *from, unsigned long n)
它的作用是从用户空间将数据拷贝到内核空间。参数to是目标缓冲区的指针,from是源缓冲区的指针,n是要拷贝的字节数。该函数返回成功拷贝的字节数,如果出错则返回未成功拷贝的字节数。
copy_to_user函数的原型:
unsigned long copy_to_user(void __user *to, const void *from, unsigned long n)
它的作用是从内核空间将数据拷贝到用户空间。参数to是目标缓冲区的指针,from是源缓冲区的指针,n是要拷贝的字节数。该函数返回成功拷贝的字节数,如果出错则返回未成功拷贝的字节数。
2. proc文件系统
3. mmap系统调用
12.中断的响应执行流程?听说过顶半部和底半部吗?
答案:
cpu接收中断----->
保存中断上下文跳转到中断的处理函数----->
执行中断上半部分----->
执行中断的下半部分----->
恢复中断的上下文。
顶半部(上半部)执行一般是比较紧急的任务,比如清中断,底半部(下半部)执行的一些不太紧急的人任务可以节省中断处理时间。
注意:在中断中要避免休眠的操作。
13.busybox是什么?根文件系统是什么?
答案:
busybox: 缩小版的uinx系统常用命令工具箱。
根文件系统: 内核启动时所挂载的第一个文件系统,内核代码映像文件保存在根文件系统中。
14.自旋锁是什么?信号量是什么?二者有什么区别?
答案:
自旋锁:---->不会进入睡眠
自旋锁只有两个状态,锁定和解锁,在锁定期间其他进程我是不能进行访问资源,比如B想访问只能在外面等到A解锁之后才能访问,如果B等待的时间过长那么就要考虑使用互斥锁。
信号量:------>会进入睡眠
信号量是个计数器,用来统计资源的可用次数,比如B进程想使用资源,当资源可用的是时候就会去通知B,而不是让B在哪里等着,不会一直占用CPU,这样就可以提高系统的执行效率。
区别:
- 信号量会让等待信号的的进程进入睡眠,所以信号量适用于锁会被长时间持有的情况。
- 自旋锁会一直在那里循环判断锁是否可用,占用极高CPU所以不适用长时间持有所的情况。
- 自旋锁禁止处理器抢占,信号量允许,这也就是为什么自旋锁不能睡眠的原因,如果自旋锁睡眠,那么就无法通过抢占唤醒睡眠的自旋锁。
- 信号量不能用于中断中,因为信号量会引起休眠,中断不能睡眠,自旋锁可以。
15.为什么堆的空间不是连续的?
答案:
动态分配:堆的特点是可以在程序运行时进行动态内存分配和释放。当程序请求分配一块内存时,堆管理器会在堆中找到足够大的空闲内存块,并将其分配给程序。这意味着堆中的内存块可能是离散的,不连续的。
内存碎片:频繁的内存分配和释放操作可能导致内存碎片的产生。当程序释放内存时,这块内存变为空闲状态,但它周围的内存可能被其他已分配的内存所占用,形成了两种类型的内存碎片:外部碎片和内部碎片。这些碎片使得堆中的空闲内存块分散,造成了不连续的情况。
动态增长:堆的大小通常是可变的,可以根据需要进行动态增长。当堆中的内存空间不足以满足程序的内存需求时,堆管理器会通过分配更多的内存来扩展堆的大小。这可能导致堆的空间在物理上不是连续的。

)



HTML5基础与CSS3应用)







)

Html版本)



