目录
1.层次分析法(结合某些属性及个人倾向,做出某种决定)
1.1 粗浅理解
1.2 算法过程
1.2.1 构造判断矩阵
1.2.2 计算权重向量
1.2.3 计算最大特征根
1.2.4 计算C.I.值
1.2.5 求解C.R.值
1.2.6 判断一致性
1.2.7 计算总得分
2 神经网络(正向流通反向反馈,调整系数,预测结果)
2.1 粗浅理解
2.2 算法过程
2.2.1 划分数据集
2.2.2 前向传播及反向调整系数(利用梯度下降法)
编辑 编辑
3 决策树(通过若干属性,并进行合理排序,最快做出分类)
3.1 粗浅理解
3.2 算法过程
3.2.1 随机分配属性顺序,计算熵值
3.2.2 条件熵的计算
3.2.3 根据不同的评选方法,得出最优决策树
3.2.4 连续值处理
3.2.5 剪枝处理
3.2.6 补充:K折交叉验证
3.2.7 补充:过拟合和欠拟合
4 拟合与插值(回归预测)
5 时间序列预测(体现时间连续性)
5.1 粗浅理解
5.2 常见方法
5.2.1 朴素预测法(Naive Forecast)
5.2.2 简单平均法(Simple Average)
5.3.3 移动平均法(Moving Average)
5.2.4 加权移动平均(Weighted Moving Average)
5.2.5 简单指数平滑法 (Simple Exponential Smoothing)
5.2.6 霍尔特线性趋势法
5.2.7 Holt-Winters方法(三次指数平滑)
6 K-Means(K-均值)聚类算法(无需分割数据即可分类)
6.1 粗浅理解
6.2 算法过程
6.2.1 选定质心
6.2.2 分配点
6.2.3 评价
7 KNN算法(K近邻算法)
7.1 粗浅理解
7.2 有关距离的介绍
7.2.1 欧氏距离(Euclidean Distance)
7.2.2 曼哈顿距离(Manhattan Distance)
7.2.3 切比雪夫距离 (Chebyshev Distance)
7.2.4 闵可夫斯基距离(Minkowski Distance)
7.2.5 “连续属性”和“离散属性”的距离计算
7.3 算法过程
1.层次分析法(结合某些属性及个人倾向,做出某种决定)
1.1 粗浅理解
举一个例子:我们想选择一个旅游地,对于不用的旅游地有不同属性,而且我们对于不同的属性也有不同的倾向(比如旅游地有景点和旅途两个属性,每个旅游地的属性好坏不同,而且我们可能在选择旅游地时更倾向于景点或旅途,这样得出的决策就会更符合自身实际)

层次分析法就是将一个决策事件分解为目标层(例如选择旅游地),准则层(影响决策的因素,例如景点、旅途等)以及方案层(指的是方案,例如去某地旅游)
层次分析法大致有如下过程:

1.2 算法过程
1.2.1 构造判断矩阵
构造判断矩阵就是通过各要素之间相互两两比较,并确定各准则层对目标层的权重。
简单地说,就是把准则层的指标进行两两判断,通常我们使用Santy的1-9标度方法给出。

初始表格如下(每个属性对于自身的重要性为1):
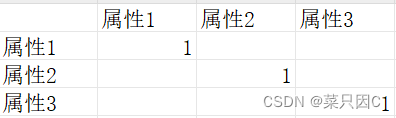
如果我们认为属性2比属性1明显重要,那么:

以此类推,当我们填完这个表格,判断矩阵A就构造出来了
1.2.2 计算权重向量
简单来说,就是将判断矩阵A的列向量归一化,然后求行和得出矩阵后再归一化,这时我们得到一个n行1列的权重向量矩阵W
1.2.3 计算最大特征根
根据公式:
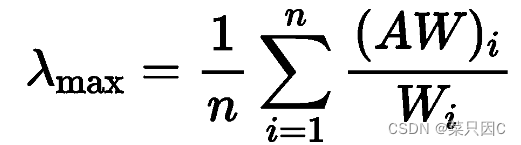
1.2.4 计算C.I.值
根据公式:

1.2.5 求解C.R.值
根据公式:

其中R.I.值我们可以查表得知

1.2.6 判断一致性
C.R.<0.1 时,表明判断矩阵 A 的一致性程度被认为在容许的范围内,此时可用 A 的特征向量开展权向量计算;若 C.R.≥0.1, 说明我们在构建判断矩阵时出现了逻辑错误,这个时候,我们需要对判断矩阵 A 进行修正。
1.2.7 计算总得分
利用权重及得分矩阵来计算,最后得分最高的即为决策方案
2 神经网络(正向流通反向反馈,调整系数,预测结果)
2.1 粗浅理解
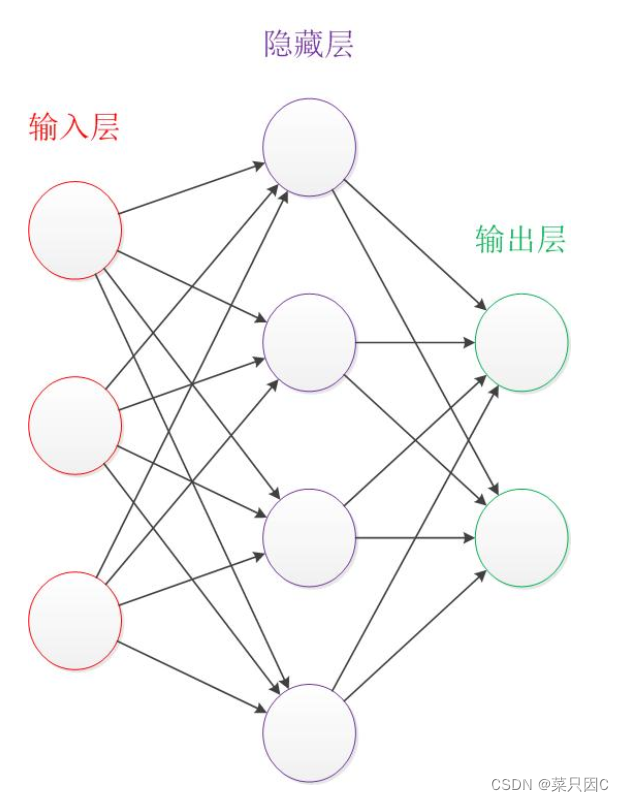
- 设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由指定;
- 神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别;
- 结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
大致过程:
2.2 算法过程
2.2.1 划分数据集
大部分用来做训练集训练模型,小部分用来做验证集和测试集证明模型的完备性(可以没有验证集,只不过准确度会稍差一点)
2.2.2 前向传播及反向调整系数(利用梯度下降法)
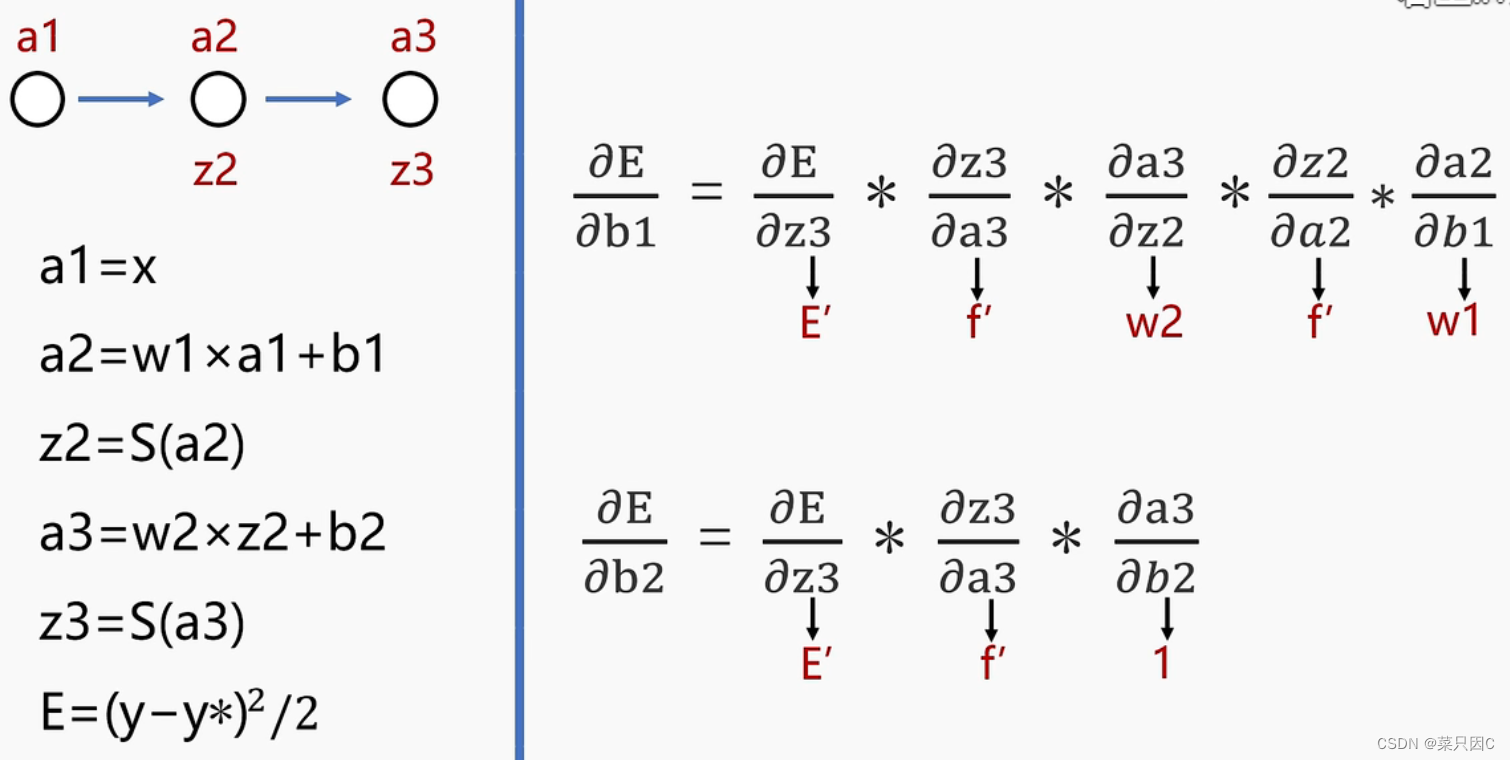
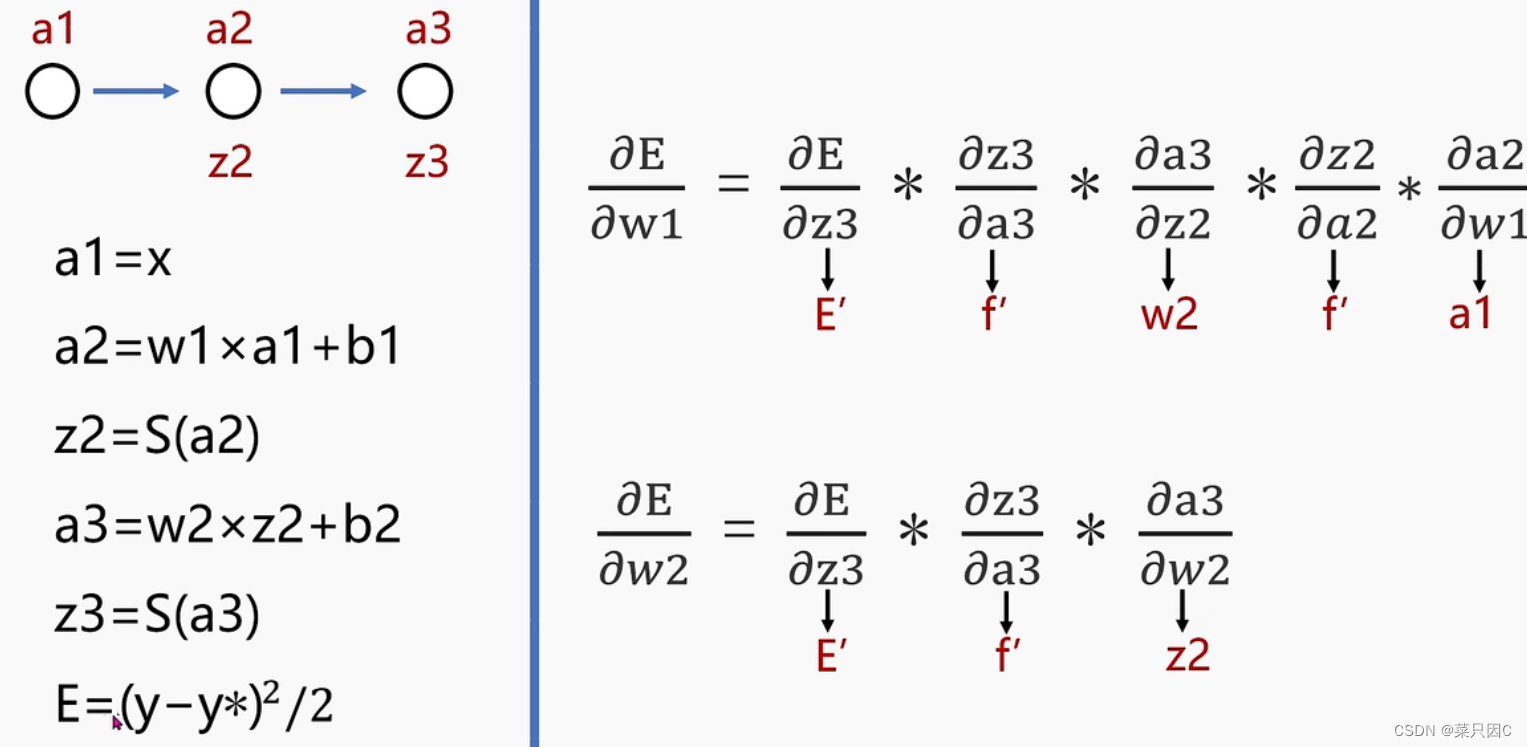
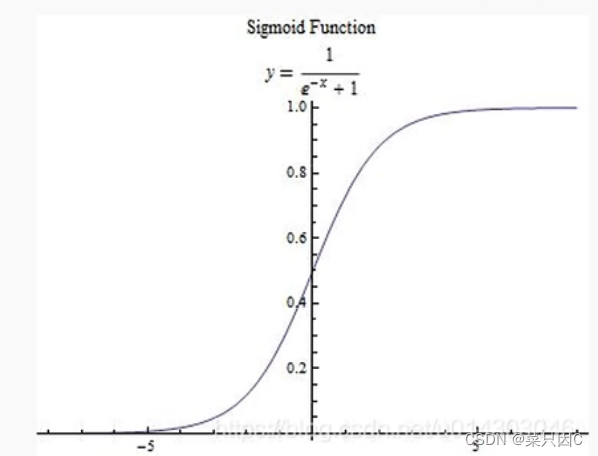
注:这里的S函数是激活函数
3 决策树(通过若干属性,并进行合理排序,最快做出分类)
3.1 粗浅理解
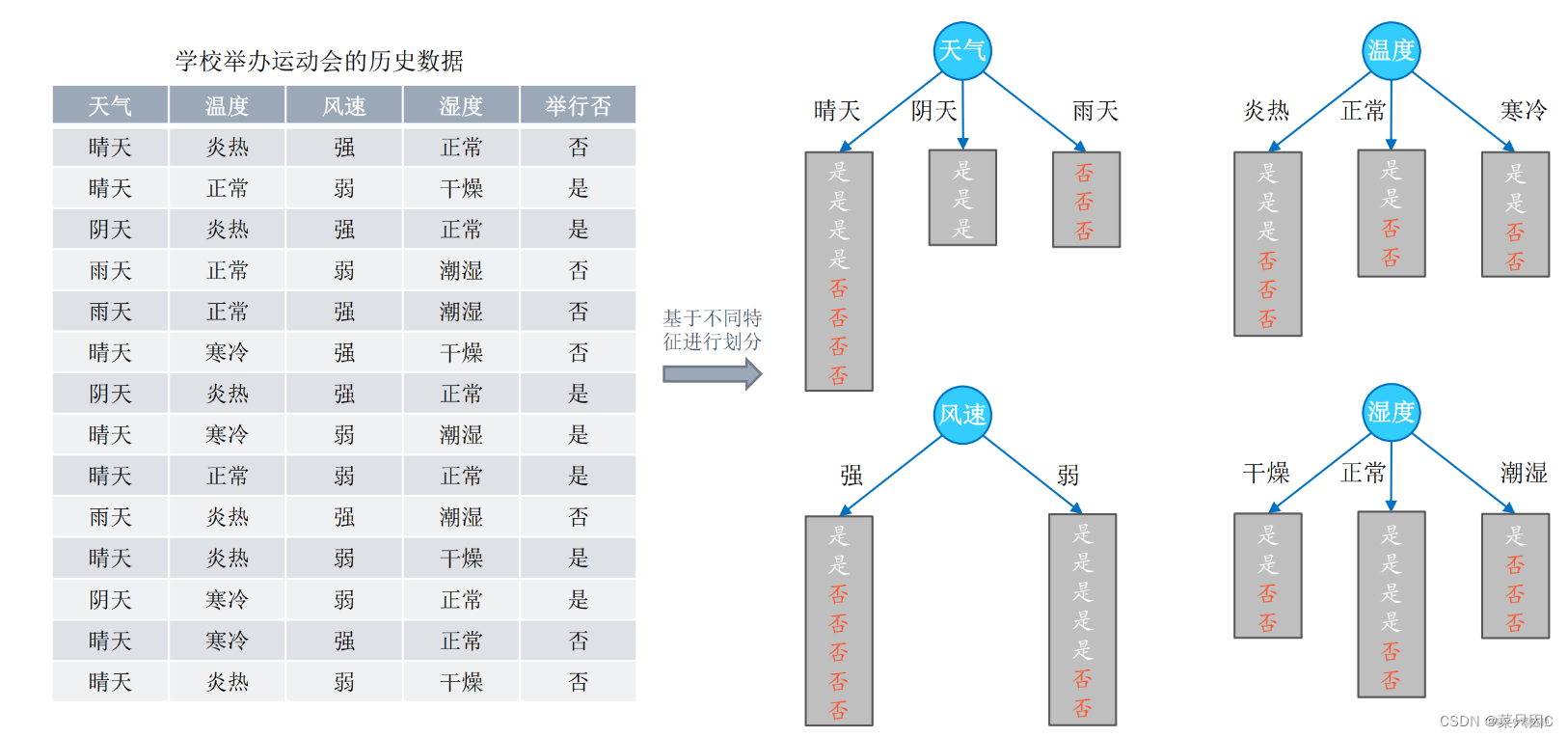
决策树(Decision Tree)是一种分类和回归方法,是基于各种情况发生的所需条件构成决策树,以实现期望最大化的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。它的运行机制非常通俗易懂,因此被誉为机器学习中,最“友好”的算法。下面通过一个简单的例子来阐述它的执行流程。假设根据大量数据(含 3 个指标:天气、温度、风速)构建了一棵“可预测学校会不会举办运动会”的决策树(如下图所示)。

接下来,当我们拿到某个数据时,就能做出对应预测。
在对任意数据进行预测时,都需要从决策树的根结点开始,一步步走到叶子结点(执行决策的过程)。如,对下表中的第一条数据( [ 阴天,寒冷,强 ] ):首先从根结点出发,判断 “天气” 取值,而该数据的 “天气” 属性取值为 “阴天”,从决策树可知,此时可直接输出决策结果为 “举行”。这时,无论其他属性取值为什么,都不需要再执行任何决策(类似于 “短路” 现象)。

决策树的组成:

决策树由结点和有向边组成。结点有两种类型:内部结点(圆)和叶结点(矩形)。其中,内部结点表示一个特征(属性);叶结点表示一个类别。而有向边则对应其所属内部结点的可选项(属性的取值范围)。
在用决策树进行分类时,首先从根结点出发,对实例在该结点的对应属性进行测试,接着会根据测试结果,将实例分配到其子结点;然后,在子结点继续执行这一流程,如此递归地对实例进行测试并分配,直至到达叶结点;最终,该实例将被分类到叶结点所指示的结果中。
但是,对于每一个属性做出决定的先后顺序没有进行解释
3.2 算法过程
3.2.1 随机分配属性顺序,计算熵值
构建决策树的实质是对特征进行层次选择,而衡量特征选择的合理性指标,则是熵。为便于说明,下面先给出熵的定义:设 𝑋 是取值在有限范围内的一个离散随机变量,其概率密度为:



3.2.2 条件熵的计算
根据熵的定义,在构建决策树时我们可采用一种很简单的思路来进行“熵减”:每当要选出一个内部结点时,考虑样本中的所有“尚未被使用”特征,并基于该特征的取值对样本数据进行划分。即有:
对于每个特征,都可以算出“该特征各项取值对运动会举办与否”的影响(而衡量各特征谁最合适的准则,即是熵)。为此,引入条件熵。
我们将“天气”特征展开,以分别求解各取值对应集合的熵。实际上,该式的计算正是在求条件熵。条件熵 𝐻(𝑌 | 𝑋) 表示在已知随机变量 𝑋 的条件下随机变量 𝑌 的不确定性。它的数学定义是:若设随机变量 (𝑋, 𝑌) ,其联合概率密度为
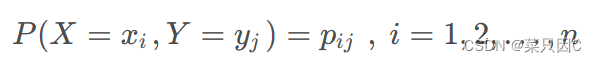
则定义条件熵 𝐻(𝑌 | 𝑋) :在给定 𝑋 的条件下 𝑌 的条件概率分布对 𝑋 的数学期望,即

3.2.3 根据不同的评选方法,得出最优决策树
1、信息增益( ID3 算法选用的评估标准)
信息增益 𝑔(𝐷, 𝑋) :表示某特征 𝑋 使得数据集 𝐷 的不确定性减少程度,定义为集合 𝐷 的熵与在给定特征 𝑋 的条件下 𝐷 的条件熵 𝐻(𝐷 | 𝑋) 之差,即
![]()
2、信息增益率( C4.5 算法选用的评估标准)
以信息增益作为划分数据集的特征时,其偏向于选择取值较多的特征。比如,当在学校举办运动会的历史数据中加入一个新特征 “编号” 时,该特征将成为最优特征。因为给定 “编号” 就一定知道那天是否举行过运动会,因此 “编号” 的信息增益很高。
但实际我们知道,“编号” 对于类别的划分并没有实际意义。故此,引入信息增益率。
信息增益率 𝑔𝑅(𝐷, 𝑋) 定义为其信息增益 𝑔(𝐷, 𝑋) 与数据集 𝐷 在特征 𝑋 上值的熵 𝐻𝑋(𝐷) 之比,即:

![]()
3、基尼系数( CART 算法选用的评估标准)
从前面的讨论不难看出,无论是 ID3 还是 C4.5 ,都是基于信息论的熵模型出发而得,均涉及了大量对数运算。能不能简化模型同时又不至于完全丢失熵模型的优点呢?分类回归树(Classification and Regression Tree,CART)便是答案,它通过使用基尼系数来代替信息增益率,从而避免复杂的对数运算。基尼系数代表了模型的不纯度,基尼系数越小,则不纯度越低,特征越好。注:这一点和信息增益(率)恰好相反。
在分类问题中,假设有 𝑘 个类别,且第 𝑘 个类别的概率为 𝑝𝑘 ,则基尼系数为
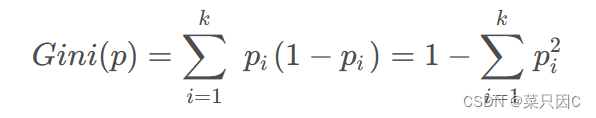
对于给定数据集 𝐷 ,假设有 𝑘 个类别,且第 𝑘 个类别的数量为 𝐶𝑘 ,则该数据集的基尼系数为

由于基尼系数 𝐺𝑖𝑛𝑖(𝐷) 表示集合 𝐷 的不确定性,则基尼系数 𝐺𝑖𝑛𝑖(𝐷, 𝑋) 表示 “基于指定特征 𝑋 进行划分后,集合 𝐷 的不确定性”。该值越大,就表示数据集 𝐷 的不确定性越大,也就说明以该特征 进行划分越容易分乱。
4、基尼增益
同信息增益一样,如果将数据集 𝐷 的基尼系数减去数据集 𝐷 根据特征 𝑋 进行划分后得到的基尼系数
![]()
就得到基尼增益(系数)。显然,采用越好的特征进行划分,得到的基尼增益也越大。基于前面各特征对数据集的划分,可得到其对应的基尼增益。
步骤一:先算出初始数据集合 D 的基尼系数
步骤二:计算基尼系数计算基尼增益率
可见,基尼增益在处理诸如 “编号” 这一类特征时,仍然会认为其是最优特征(此时,可采取类似信息增益率的方式,选用基尼增益率 )。但对常规特征而言,其评估的合理性还是较优的。
5、基尼增益率
基尼增益率 𝐺𝑅(𝐷, 𝑋) 定义为其尼基增益 𝐺(𝐷, 𝑋) 与数据集 𝐷 在特征 𝑋 上的取值个数之比,即
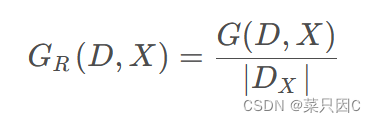
容易看出,基尼增益率考虑了特征本身的基尼系数(此时,当某特征取值类别较多时, 𝐺𝑅(𝐷, 𝑋) 式中的分母也会增大),从而降低了 “偏向取值较多的特征” 这一影响。
从上面的结果可以看出,基尼增益率能明显降低取值较多的特征偏好现象,从而更合理地评估各特征在划分数据集时取得的效果。
3.2.4 连续值处理
在前面的数据集中,各项特征(以及标签)均为离散型数据,但有时处理的数据对象可能会含有连续性数值,为了解决这一问题,我们可以对数据进行离散化处理。此时,可把连续取值的数据值域划分为多个区间,并将每个区间视为该特征的一个取值,如此就完成了从连续性数据到离散性数据的转变。
对于一些有意义的连续值,我们可以通过实际情况来进行划分归类,比如温度:

对于一些无意义的连续值:
62,65,72,86,89,96,102,116,118,120,125,169,187,211,218

3.2.5 剪枝处理
对于决策树而言,当你不断向下划分,以构建一棵足够大的决策树时(直到所有叶子结点熵值均为 0),理论上就能将近乎所有数据全部区分开。所以,决策树的过拟合风险非常大。为此,需要对其进行剪枝处理。
常用的剪枝策略主要有两个:
预剪枝;构建决策树的同时进行剪枝处理(更常用);
后剪枝:构建决策树后再进行剪枝处理。
预剪枝策略可以通过限制树的深度、叶子结点个数、叶子结点含样本数以及信息增量来完成。
这里只讨论预剪枝:
1、限制决策树的深度
下图展示了通过限制树的深度以防止决策树出现过拟合风险的情况。

2、限制决策树中叶子结点的个数
下图展示了通过限制决策树中叶子结点的个数以防止决策树出现过拟合风险的情况。

3、限制决策树中叶子结点包含的样本个数
下图展示了通过限制决策树中叶子结点包含的样本个数以防止决策树出现过拟合风险的情况。

4、限制决策树的最低信息增益
下图展示了通过限制决策树中叶子结点包含的样本个数以防止决策树出现过拟合风险的情况。
 3.2.6 补充:K折交叉验证
3.2.6 补充:K折交叉验证
交叉验证是在机器学习建立模型和验证模型参数时常用的办法,一般被用于评估一个机器学习模型的表现。更多的情况下,我们也用交叉验证来进行模型选择(model selection)。
交叉验证,顾名思义,就是重复的使用数据,把得到的样本数据进行切分,组合为不同的训练集和测试集,用训练集来训练模型,用测试集来评估模型预测的好坏。在此基础上可以得到多组不同的训练集和测试集,某次训练集中的某样本在下次可能成为测试集中的样本,即所谓“交叉”。
那么什么时候才需要交叉验证呢?交叉验证用在数据不是很充足的时候。如果数据样本量小于一万条,我们就会采用交叉验证来训练优化选择模型。如果样本大于一万条的话,我们一般随机的把数据分成三份,一份为训练集(Training Set),一份为验证集(Validation Set),最后一份为测试集(Test Set)。用训练集来训练模型,用验证集来评估模型预测的好坏和选择模型及其对应的参数。把最终得到的模型再用于测试集,最终决定使用哪个模型以及对应参数。
k折交叉验证( k-Folder Cross Validation),经常会用到的。 k折交叉验证先将数据集 D随机划分为 k个大小相同的互斥子集,即 ,每次随机的选择 k-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择 k份来训练数据。若干轮(小于 k )之后,选择损失函数评估最优的模型和参数。注意,交叉验证法评估结果的稳定性和保真性在很大程度上取决于 k取值。
步骤:
1、首先随机地将数据集切分为 k 个互不相交的大小相同的子集;
2、然后将 k-1 个子集当成训练集训练模型,剩下的 (held out) 一个子集当测试集测试模型;
3、将上一步对可能的 k 种选择重复进行 (每次挑一个不同的子集做测试集);
4、这样就训练了 k 个模型,每个模型都在相应的测试集上计算测试误差,得到了 k 个测试误差,对这 k 次的测试误差取平均便得到一个交叉验证误差。这便是交叉验证的过程。
k折交叉验证最大的优点:
所有数据都会参与到训练和预测中,有效避免过拟合,充分体现了交叉的思想。
交叉验证可能存在 bias 或者 variance。如果我们提高切分的数量 k,variance 会上升但 bias 可能会下降。相反得,如果降低 k,bias 可能会上升但 variance 会下降。bias-variance tradeoff 是一个有趣的问题,我们希望模型的 bias 和 variance 都很低,但有时候做不到,只好权衡利弊,选取他们二者的平衡点。通常使用10折交叉验证,当然这也取决于训练数据的样本数量。
3.2.7 补充:过拟合和欠拟合
• 欠拟合(Underfitting)是指模型不能获取数据集的主要信息,在训练集及测试集上的表示都十分糟糕。
• 过拟合(Overfitting)是指模型不仅获取了数据集的信息还提取了噪声数据的信息是的模型在训练集有非常好的表现但在测试集上的表现及其糟糕。
4 拟合与插值(回归预测)
问题的引入:
已经测得海洋的某深度的及其对应的水温:

如何根据这些已有的数据如何估计其他深度(比如600,700,800米处)的水温?我们很自然想到深度和水温之间是否存在某种函数关系。
 函数的表达式可能无法给出,只能通过实验或者观察得到有限数量的数据点,那么如何通过数据点得到其他的点函数值?
函数的表达式可能无法给出,只能通过实验或者观察得到有限数量的数据点,那么如何通过数据点得到其他的点函数值?

插值的概念:
在实际问题中,一个函数y=f(x)往往是通过实验观察到的,仅已知函数f(x)在某个区间[a,b]上一系列点的值
![]()
当需要这些节点
![]()
之间的某点x的函数值时,常用较为简单的,满足一定的条件的函数𝑃(𝑥)去代替真实的,难以得出的𝑓(𝑥),插值法是一种常用的方法,其插值函数满足
![]()
拟合的概念:
拟合也是有限个数据点,求近似函数。但是拟合只要求整体上逼近,而不要求一定满足上面的条件,即不要求拟合得到的曲线一定过数据点,但是要求在某种意义上这些点的总偏差最小。

其中样本点较少时(泛指样本点小于30个)采用插值方法,主要有拉格朗日插值算法、牛顿插值、双线性内插和双三次插值
当样本点较多时(泛指样本点大于30个)则采用拟合函数
5 时间序列预测(体现时间连续性)
5.1 粗浅理解
时间序列,通俗的字面含义为一系列历史时间的序列集合。比如2013年到2022年我国全国总人口数依次记录下来,就构成了一个序列长度为10的时间序列。
专业领域里,时间序列定义为一个随机过程,是按时间顺序排列的一组随机变量的序列集,记为。并用 或者 表示该随机序列的N有序观测值。
5.2 常见方法
5.2.1 朴素预测法(Naive Forecast)
如果数据集在一段时间内都很稳定,我们想预测第二天的价格,可以取前面一天的价格,预测第二天的值。这种假设第一个预测点和上一个观察点相等的预测方法就叫朴素法,即

5.2.2 简单平均法(Simple Average)
这种方法预测的期望值等于所有先前观测点的平均值,称为简单平均法。。
物品价格会随机上涨和下跌,平均价格会保持一致。我们经常会遇到一些数据集,虽然在一定时期内出现小幅变动,但每个时间段的平均值确实保持不变。这种情况下,我们可以认为第二天的价格大致和过去的平均价格值一致。这种将预期值等同于之前所有观测点的平均值的预测方法就叫简单平均法。即
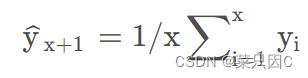
由图可见,这种方法并没有提高结果的准确度。因此,可以推断出,当每个时间段的平均值保持不变时,这种方法效果最好。

5.3.3 移动平均法(Moving Average)
移动平均法也叫滑动平均法,取前面n个点的平均值作为预测值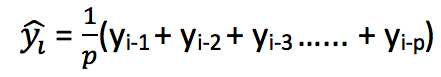
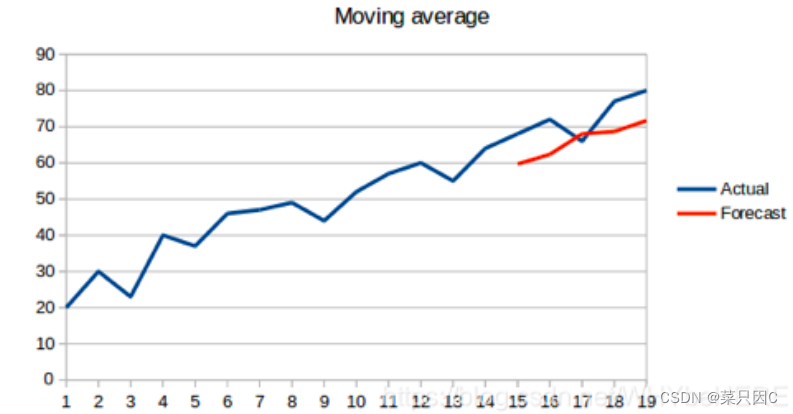
从图表中我们可以推断出,过去的观测值在这段时间里有很大幅度的上涨。如果使用简单平均法,我们必须使用所有历史数据的平均值,但是使用所有数据得出的结果并不正确。
因此,作为改进,我们只取最近几个时期的平均价格。显然,这里的想法是,只有最近的价值才重要。这种利用时间窗计算平均值的预测技术称为移动平均法。移动平均值的计算有时包括一个大小为n的“滑动窗口”。
计算移动平均值涉及到一个有时被称为“滑动窗口”的大小值p。使用简单的移动平均模型,我们可以根据之前数值的固定有限数p的平均值预测某个时序中的下一个值。这样,对于所有的 i>p
利用一个简单的移动平均模型,我们预测一个时间序列中的下一个值是基于先前值的固定有限个数“p”的平均值。因此,对于所有i>p
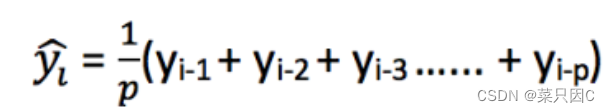
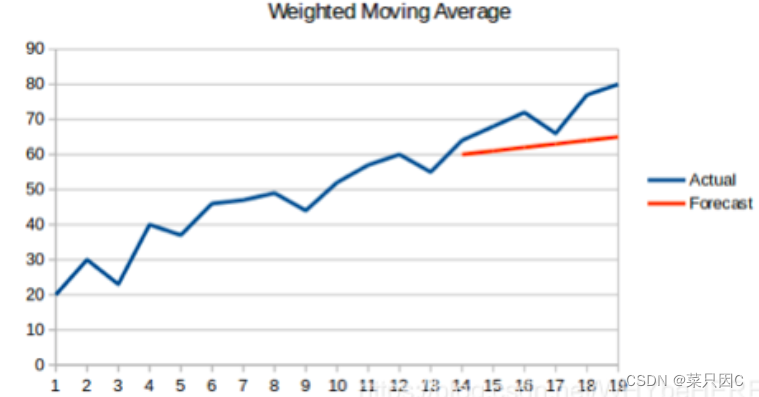
5.2.4 加权移动平均(Weighted Moving Average)
加权移动平均法是对移动平均法的一个改进。在如上所述的移动平均法中,我们对过去的n个观测值进行了同等的加权。但我们可能会遇到这样的情况:过去“n”的每一个观察结果都会以不同的方式影响预测。这种对过去观测值进行不同加权的技术称为加权移动平均法。
加权移动平均法其实还是一种移动平均法,只是“滑动窗口期”内的值被赋予不同的权重,通常来讲,最近时间点的值越重要。即
这种方法并非选择一个窗口期的值,而是需要一列权重值(相加后为1)。例如,如果我们选择[0.40, 0.25, 0.20, 0.15]作为权值,我们会为最近的4个时间点分别赋给40%,25%,20%和15%的权重。
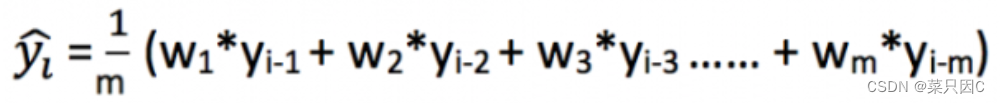
5.2.5 简单指数平滑法 (Simple Exponential Smoothing)
我们注意到简单平均法和加权移动平均法在选取时间点的思路上存在较大的差异:简单平均法将过去数据一个不漏地全部加以同等利用;移动平均法则不考虑较远期的数据,并在加权移动平均法中给予近期更大的权重。我们就需要在这两种方法之间取一个折中的方法,在将所有数据考虑在内的同时也能给数据赋予不同非权重。
指数平滑法相比更早时期内的观测值,越近的观测值会被赋予更大的权重,而时间越久远的权重越小。它通过加权平均值计算出预测值,其中权重随着观测值从早期到晚期的变化呈指数级下降,最小的权重和最早的观测值相关:
![]()

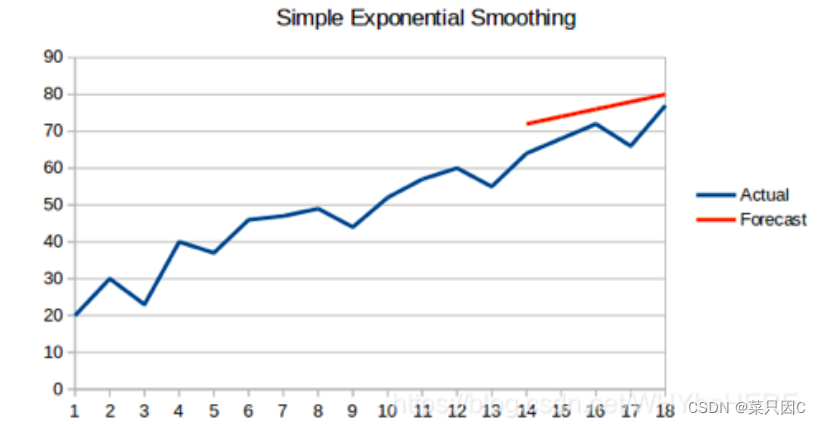
5.2.6 霍尔特线性趋势法
Holts线性趋势模型,霍尔特线性趋势法,该方法考虑了数据集的趋势,即序列的增加或减少性质。
尽管这些方法中的每一种都可以应用趋势:简单平均法会假设最后两点之间的趋势保持不变,或者我们可以平均所有点之间的所有斜率以获得平均趋势,使用移动趋势平均值或应用指数平滑。
但我们需要一种无需任何假设就能准确绘制趋势图的方法。这种考虑数据集趋势的方法称为霍尔特线性趋势法,或者霍尔特指数平滑法。
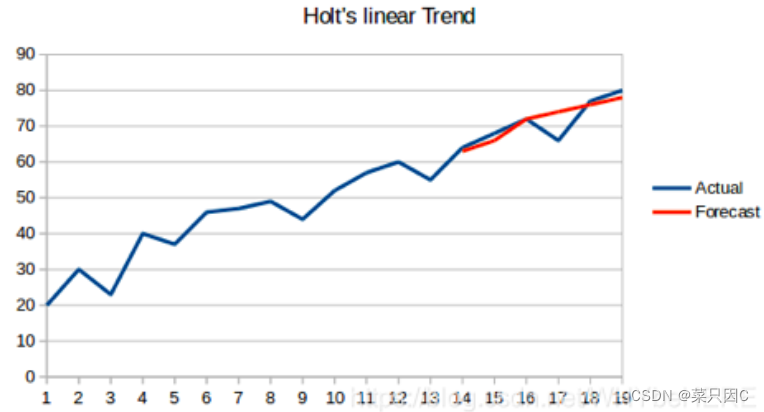
5.2.7 Holt-Winters方法(三次指数平滑)
霍尔特-温特(Holt-Winters)方法,有的地方也叫三次指数平滑法。Holt-Winters 方法在 Holt模型基础上引入了 Winters 周期项(也叫做季节项),可以用来处理月度数据(周期 12)、季度数据(周期 4)、星期数据(周期 7)等时间序列中的固定周期的波动行为。引入多个 Winters 项还可以处理多种周期并存的情况。
当一个序列在每个固定的时间间隔中都出现某种重复的模式,就称之具有季节性特征,而这样的一个时间间隔称为一个季节性特征。
例如酒店的预订量在周末较高,工作日较低,并且每年都在增加, 表明存在一个一周的季节性和增长趋势。
这里只介绍简单的预测模型
6 K-Means(K-均值)聚类算法(无需分割数据即可分类)
6.1 粗浅理解
聚类,简单来说,就是将一个庞杂数据集中具有相似特征的数据自动归类到一起,称为一个簇,簇内的对象越相似,聚类的效果越好。它是一种无监督的学习(Unsupervised Learning)方法,不需要预先标注好的训练集。聚类与分类最大的区别就是分类的目标事先已知,例如猫狗识别,你在分类之前已经预先知道要将它分为猫、狗两个种类;而在你聚类之前,你对你的目标是未知的,同样以动物为例,对于一个动物集来说,你并不清楚这个数据集内部有多少种类的动物,你能做的只是利用聚类方法将它自动按照特征分为多类,然后人为给出这个聚类结果的定义(即簇识别)。例如,你将一个动物集分为了三簇(类),然后通过观察这三类动物的特征,你为每一个簇起一个名字,如大象、狗、猫等,这就是聚类的基本思想。
至于“相似”这一概念,是利用距离这个评价标准来衡量的,我们通过计算对象与对象之间的距离远近来判断它们是否属于同一类别,即是否是同一个簇。至于距离如何计算,科学家们提出了许多种距离的计算方法,其中欧式距离是最为简单和常用的,除此之外还有曼哈顿距离和余弦相似性距离等。
我们常用的是:
对于x点坐标为(x1,x2,x3,...,xn)和 y点坐标为(y1,y2,y3,...,yn),两者的欧式距离为:

K-Means 是发现给定数据集的 K 个簇的聚类算法, 之所以称之为 K-均值 是因为它可以发现 K 个不同的簇, 且每个簇的中心采用簇中所含值的均值计算而成.
簇个数 K 是用户指定的, 每一个簇通过其质心(centroid), 即簇中所有点的中心来描述.
聚类与分类算法的最大区别在于, 分类的目标类别已知, 而聚类的目标类别是未知的.
优点:
1.属于无监督学习,无须准备训练集
2.原理简单,实现起来较为容易
3.结果可解释性较好
缺点:
1.需手动设置k值。 在算法开始预测之前,我们需要手动设置k值,即估计数据大概的类别个数,不合理的k值会使结果缺乏解释性
2.可能收敛到局部最小值, 在大规模数据集上收敛较慢
3.对于异常点、离群点敏感
几个名词:
1.簇: 所有数据的点集合,簇中的对象是相似的。
2.质心: 簇中所有点的中心(计算所有点的均值而来).
3.SSE: Sum of Sqared Error(误差平方和), 它被用来评估模型的好坏,SSE 值越小,表示越接近它们的质心. 聚类效果越好。由于对误差取了平方,因此更加注重那些远离中心的点(一般为边界点或离群点)
6.2 算法过程
6.2.1 选定质心
随机确定 K 个初始点作为质心(不必是数据中的点)
6.2.2 分配点
将数据集中的每个点分配到一个簇中, 具体来讲, 就是为每个点找到距其最近(上面提到的欧氏距离)的质心, 并将其分配该质心所对应的簇. 这一步完成之后, 每个簇的质心更新为该簇所有点的平均值.
重复上述过程直到数据集中的所有点都距离它所对应的质心最近时结束
6.2.3 评价
k-means算法因为手动选取k值和初始化随机质心的缘故,每一次的结果不会完全一样,而且由于手动选取k值,我们需要知道我们选取的k值是否合理,聚类效果好不好,那么如何来评价某一次的聚类效果呢?也许将它们画在图上直接观察是最好的办法,但现实是,我们的数据不会仅仅只有两个特征,一般来说都有十几个特征,而观察十几维的空间对我们来说是一个无法完成的任务。因此,我们需要一个公式来帮助我们判断聚类的性能,这个公式就是SSE (Sum of Squared Error, 误差平方和 ),它其实就是每一个点到其簇内质心的距离的平方值的总和,这个数值对应kmeans函数中clusterAssment矩阵的第一列之和。 SSE值越小表示数据点越接近于它们的质心,聚类效果也越好。 因为对误差取了平方,因此更加重视那些远离中心的点。一种肯定可以降低SSE值的方法是增加簇的个数,但这违背了聚类的目标。聚类的目标是在保持簇数目不变的情况下提高簇的质量。
7 KNN算法(K近邻算法)
7.1 粗浅理解
根据你的“邻居”来推断出你的类别
K Nearest Neighbor算法⼜叫KNN算法,这个算法是机器学习⾥⾯⼀个⽐较经典的算法, 总体来说KNN算法是相对⽐ 较容易理解的算法
如果⼀个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的⼤多数属于某⼀个类别,则该样本也属于这个 类别。
7.2 有关距离的介绍
7.2.1 欧氏距离(Euclidean Distance)
这里不再赘述
7.2.2 曼哈顿距离(Manhattan Distance)
在曼哈顿街区要从⼀个⼗字路⼝开⻋到另⼀个⼗字路⼝,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是 “曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)



7.2.3 切比雪夫距离 (Chebyshev Distance)
国际象棋中,国王可以直⾏、横⾏、斜⾏,所以国王⾛⼀步可以移动到相邻8个⽅格中的任意⼀个。国王从格⼦(x1,y1) ⾛到格⼦(x2,y2)最少需要多少步?这个距离就叫切⽐雪夫距离。

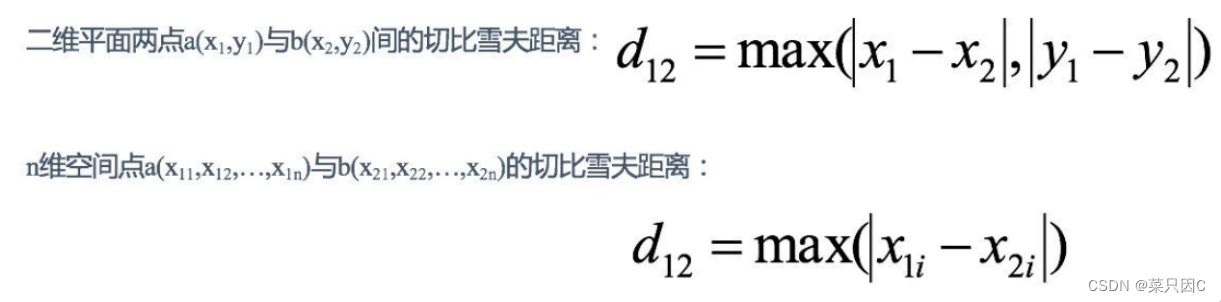
7.2.4 闵可夫斯基距离(Minkowski Distance)
闵⽒距离不是⼀种距离,⽽是⼀组距离的定义,是对多个距离度量公式的概括性的表述。 两个n维变量a(x11,x12,…,x1n)与b(x21,x22,…,x2n)间的闵可夫斯基距离定义为:


根据p的不同,闵⽒距离可以表示某⼀类/种的距离
小结:
闵氏距离,包括曼哈顿距离、欧氏距离和切比雪夫距离,都存在明显的缺点:
e.g. ⼆维样本(身高[单位:cm],体重[单位:kg]),现有三个样本:a(180,50),b(190,50),c(180,60)。 a与b的闵氏距离(无论是曼哈顿距离、欧氏距离或切比雪夫距离)等于a与c的闵氏距离。但实际上身⾼的10cm并不能 和体重的10kg划等号。
闵氏距离的缺点: (1)将各个分量的量纲(scale),也就是“单位”相同的看待了; (2)未考虑各个分量的分布(期望,方差等)可能是不同的
7.2.5 “连续属性”和“离散属性”的距离计算
我们常将属性划分为 “连续属性” (continuous attribute)和 “离散属性” (categorical attribute),前者在定义域上有⽆穷多个 可能的取值,后者在定义域上是有限个取值.
若属性值之间存在序关系,则可以将其转化为连续值,例如:身⾼属性“⾼”“中等”“矮”,可转化为{1, 0.5, 0}。 闵可夫斯基距离可以⽤于有序属性。
若属性值之间不存在序关系,则通常将其转化为向量的形式,例如:性别属性“男”“⼥”,可转化为{(1,0), (0,1)}。
7.3 算法过程
略

| 光伏发电分析 |数学建模完整代码+建模过程全解全析)


——内存碎片优化)
)

![DataXCloud部署与配置[智数通]](http://pic.xiahunao.cn/DataXCloud部署与配置[智数通])


)



——代码随想录算法训练营Day07)




