论文地址:https://arxiv.org/pdf/2401.03989.pdf
代码地址(中稿后开源):GitHub - Atten4Vis/MS-DETR: The official implementation for "MS-DETR: Efficient DETR Training with Mixed Supervision"
摘要 DETR 通过迭代生成多个基于图像特征的目标候选者,并为每个真实目标分配一个候选者,从而实现端到端的目标检测。在原始DETR中使用一对一监督的传统训练方法缺乏对检测候选者的直接监督。
作者旨在通过明确监督候选生成过程,将一对一监督和多对多监督混合,来提高DETR训练效率。MS-DETR简单地将多对多监督应用到用于推理的主要解码器(primary decoder)object query 上。与现有具有多对多监督的DETR变体(如Group DETR和Hybrid DETR)相比,MS-DETR不需要额外的解码器分支或object query ;MS-DETR中主要解码器object query 直接从多对多监督中受益,因此在目标候选预测方面优于其他方法。实验结果表明,MS-DETR优于相关DETR变体,如DN-DETR、Hybrid DETR和Group DETR,并且与相关DETR变体的结合进一步提高了性能。
简单总结:在不引入额外decoder分支和object query的情况下,由object query 同时产生一对一和一对多的预测。在传统DETR的基础上将SA和CA交换了次序,变成先做CA后做SA,并将CA后的query作为一对多的预测,对应下图(c),模型效果进一步提升。在无需额外decoder分支或object query的情况下即可超越DN/Group-DETR

1. Introduction
Detection Transformer(DETR),是一种端到端的目标检测方法,已经引起了大量的研究关注。它由一个卷积神经网络(CNN) Backbone ,一个Transformer编码器和解码器组成。解码器是一个解码器层堆栈,每个层都包括自注意、交叉注意和FFNs,然后是分类器和框预测器。
DETR解码器生成多个物体候选,这些候选以object query 的形式表示,以端到端的方式学习促使每一个候选接近GT,并抑制其他重复候选。这些重复候选,即接近真实目标,如图1所示。候选生成的主要作用由解码器交叉注意力承担。候选去重的主要作用由解码器自注意力和一对一监督共同承担,以确保每个真实物体选择一个单一的候选。与基于NMS的方法(如Faster R-CNN)通常为候选生成引入监督不同,DETR训练过程缺乏明确监督来生成多个目标检测候选。

作者提出了一种监督方式,即混合一对一监督和额外的多对多监督,来提高训练效率。该架构非常简单。作者在一个一对多监督中,添加了一个类似一对一监督中预测头的模块,包括一个框预测器和类别预测器。所得的方法名为MS-DETR,如图3所示。作者想要指出的是,额外的模块仅影响训练过程,而推理过程保持不变。
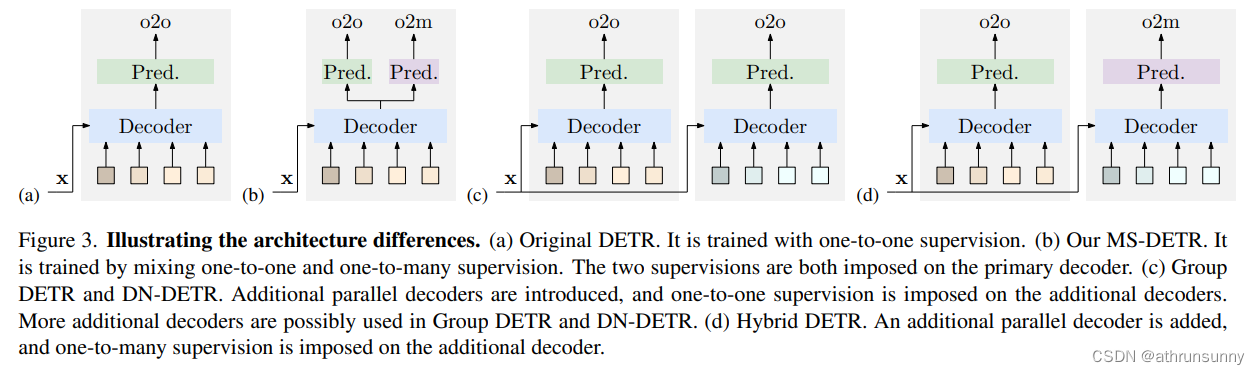
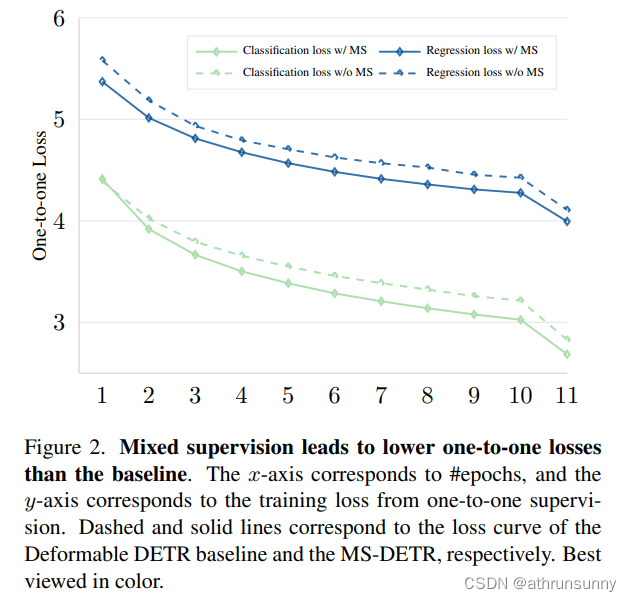
图1说明了额外的监督如何影响候选检测。作者观察到,没有一对多监督的DETR也会为每个真实目标生成多个候选。在添加额外的一对多监督后,作者可以看到预测的框更好,这意味着候选更好。作者观察到,当添加额外的一对多监督时,一对一分类和框回归损失会减小(如图2所示)。这提供了证据,即一对多监督能够改善候选,从而有助于优化一对一监督损失。
MS-DETR通过引入额外的监督来收集图像特征信息,从而改善了object query 的质量。它不同于相关的高效训练方案,并对其进行了补充,如conditional DETR和Deformable DETR,它们修改了交叉注意力架构或改变了 Query 形式。MS-DETR与使用一对多监督的DETR变体不同。具体来说,MS-DETR直接将一对多监督施加在主要解码器object query上。相比之下,Group DETR和Hybrid DETR将监督施加在主要解码器以外的额外解码器中的 Query 。与密切相关方法的区别如图3所示。
实验结果显示,MS-DETR在DETR基础方法上取得了一致的改进,包括修改了交叉注意力或 Query 形式的DETR变体(如Deformable DETR,DAB-DETR),以及其他训练高效的变体(如DN-DETR,Group DETR,Hybrid-DETR)。将MS-DETR与其他具有一对多监督的DETR变体(如Group DETR和Hybrid DETR)结合,可以进一步提高性能,表明MS-DETR可以补充这些变体。此外,作者观察到,由于MS-DETR不包括额外的解码器分支和object query ,因此具有更高的计算和内存效率。
2 Related Work
Decoder cross-attention and query formulation modification.交叉注意力在图像特征和当前object query之间执行交互,以细化以object query的形式表示的检测候选。
Deformable DETR 使用变形注意力,这是DCN的扩展,用于选择高度有用的区域,以替换原始的交叉注意力架构。Conditional DETR 将空间和内容 Query 分开,并计算空间注意力来软选择有用的区域。SMCA 使用高斯类似的权重进行空间注意力计算。DAB-DETR 和Conditional DETR v2 使用Box表示 Query 的位置。 Anchor DETR 使用 Anchor 框作为预定义的参考区域,以帮助检测不同大小的目标。
One-to-many supervision with parallel decoders.一对多监督将一个真实目标分配给多个object query ,以加快DETR训练。现有方法依赖于额外的并行权重共享解码器。
DN-DETR 引入了每个解码器处理一组由添加噪声的真实目标形成的噪声 Query 的并行权重共享解码器。Group DETR 则学习额外解码器的object query 。DN-DETR和Group DETR 对每个object query 组执行一对一监督,从而实现所有目标 Query 组的一对多监督。DINO 类似于DN-DETR,引入了对比去噪 Query 以实现组间一对一监督。DQS 在其独特的 Query 分支之外添加了一个并行密集 Query 分支,并将其与一对一监督的并行分支相结合。Hybrid DETR 添加了一个额外的并行解码器,其中可以直接对附加解码器进行一对多监督。
作者的方法MS-DETR与那些方法有关,因为MS-DETR也引入了一对多监督。MS-DETR明显与那些不修改原始(主要)解码器监督的方法不同。MS-DETR没有引入额外的解码器、额外的 Query ,并且仅在原始解码器上执行一对多监督。
DETA 直接在带有额外解码器和 Query 的同一解码器上执行一对多监督。不幸的是,它删除了一对一监督,并引入了NMS作为后处理。在单个解码器上混合一对一和一对多监督且不使用NMS的方法还没有得到充分探索。
One-to-many supervision in traditional methods.一对多分配在深度学习方法中广泛应用于目标检测。例如,Faster R-CNN 和 FCOS 通过为一个真实目标分配多个 Anchor 点和多个中心像素来构建目标函数,然后使用NMS后处理进行重复删除。
MS-DETR部分受到DETR与传统方法之间的相似之处的启发:DETR解码器通过交叉注意力与图像特征相互作用来寻找候选者,并通过自注意力和一对一监督来过滤重复候选者。后者部分类似于NMS后处理,而前者部分类似于大多数检测器。因此,作者将一对多监督引入DETR解码器以提高候选质量。
3. MS-DETR
3.1. Preliminaries
DETR architecture.DETR的初始架构包括一个卷积神经网络(CNN)、一个Transformer编码器、一个Transformer解码器以及目标类别和框位置预测器。
输入图像经过编码器,获得图像特征。

可学习的object query 和图像特征
被输入到解码器中,最终得到最终的object query 。

object query 通过预测器被解析为框和分类分数。
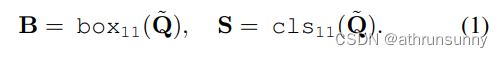
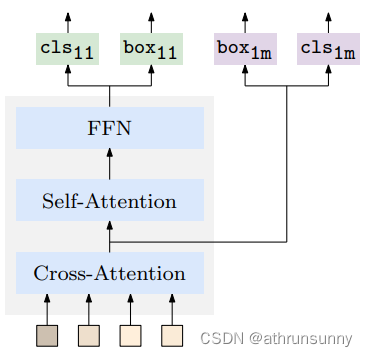
为了简洁起见,作者使用下标11和1m分别表示一对一和一对多。
Decoder.Transformer解码器是一个解码器层的堆叠。有两个主要层:一个自注意层,为每个query收集其他query(候选)的信息,以删除重复的候选,一个交叉注意力层,用于从图像特征中以 Query 的形式收集目标候选者,然后进入一个FFN层,之后是框和分类预测器。
One-to-one supervision.原始的DETR使用一对一监督进行训练。一个候选预测对应一个真实目标,反之亦然。
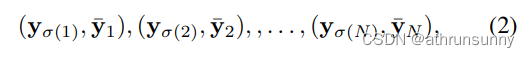
其中是最优的
索引的排列,
对应真实值,并且
。一对一损失函数的计算方式如下:
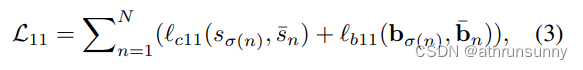
其中表示分类损失,
表示框回归损失。
一对一监督有助于抑制重复候选者并促使每个真实目标只有一个候选者,通过自注意力从其他候选者收集信息,并将每个候选者与所收集的信息进行比较。一对一监督和自注意力共同作用,在object query 之间进行交互,通常起着传统目标检测方法中使用的NMS的作用。
3.2. Mixed Supervision
One-to-many supervision.一对多监督在传统的检测方法中用于学习和提供更好的候选者以便进行NMS后处理。例如,Faster R-CNN如果预测框与真实目标有足够的重叠,则动态地将真实目标分配给预测框。FCOS将真实目标分配给目标中心的像素。
鉴于NMS与自注意力和一对一监督之间的相似之处,作者提出使用一对多分配监督来明确提高object query 的质量,从而相应地提高检测候选的质量。作者采用一个额外的模块进行一对多预测。
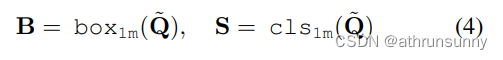
一对多的损失函数:
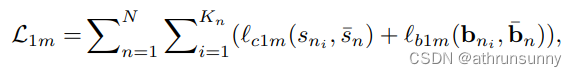
其中 是被分配给第
个真实目标的预测。
是第
个真实目标的匹配预测数量。
One-to-many matching.一对多匹配是基于从一对多预测器(one-to-many predictors)得到的预测和真实值
之间的匹配分数。匹配分数是将IoU(Intersection over Union,交并比)和分类分数组合在一起得到的。
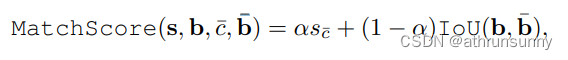
作者选择每个真实目标的匹配分数的前个 Query ,然后过滤掉匹配分数低于阈值
的 Query ,形成匹配 Query 集。作者还将从一对一匹配中获得的Query 包含到每个GT的匹配Query集中,这带来了更好的增益(+0.2 mAP)。
3.3. Implementation
用于一对多监督的额外模块包括框预测器和类别预测器,它们与一对一监督中使用的相同。框预测器实现为一个三层MLP(多层感知器)结构,使用ReLU激活,而类别预测器实现为一个单线性层。

一种直接的实现方式(图4(a))是在每个解码器层的输出object query 上执行一对多预测,这与一对一预测相似。作者将一对一的框预测合并到一对多框预测中。对于一个真实目标,其损失函数由三部分组成:一对一分类损失、一对多框回归损失和一对一分类损失。
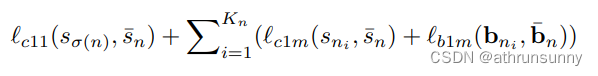
考虑到DETR交叉注意力的作用是根据图像特征生成多个候选者,而自注意力的作用是收集其他候选者的信息以便进行重复移除,作者改变了解码器层组件的顺序,将其从自注意交叉注意力FFN更改为交叉注意力自注意FFN。
这(如图4(b)所示)类似于传统方法,如Faster R-CNN:首先为每个目标生成多个候选者,然后使用NMS移除重复候选者。这几乎不影响性能。
然后作者在经过交叉注意力处理并输出FFN的内部object query 上放置一对多监督(如图4(c)所示)。作者假设经过交叉注意力处理的解码器层内部object query 包含关于每个候选者的大量信息,而经过自注意力处理的解码器层输出object query 还包含关于其他候选者的信息。因此,在内部object query 上施加一对多监督(来自交叉注意力)可能有助于训练,这在Table 5中得到了实证验证。
相比之下,在交叉注意力和自注意力交换顺序的情况下,在内部object query 上施加一对多监督(如图4(d)所示)会导致性能下降。原因可能是监督放置与交叉注意力和自注意力的角色不一致:交叉注意力主要生成多个候选者,而自注意力主要收集其他候选者的信息,主要是为了推广获胜候选者。
4. Experiments
4.1. Object Detection
Setting.作者在各种代表性的基于DETR检测器上验证MS-DETR,例如DAB-DETR,Deformable DETR及其强大的扩展Deformable-DETR++,该方法实现了三个额外的技巧:mixed query selection, look forward twice, and zero dropout rate。
作者将结果与具有一对多监督代表性的DETR变体进行比较,包括DN-DETR,Hybrid DETR,Group DETR和DINO。使用ResNet-50作为CNN Backbone 。模型主要用于训练12个epochs,部分为24个epochs。模型在COCO train2017上进行训练,并在COCO val2017上进行评估。
Comparison against DETR variants with one-to-many supervision.结果如表1所示。MS-DETR在不同的DETR Baseline 上都带来了持续的改进。具体来说,在12个周期下,相对于DAB-Deformable-DETR,Deformable DETR和Deformable DETR++,其mAP提高了3.7,3.7和1.8。
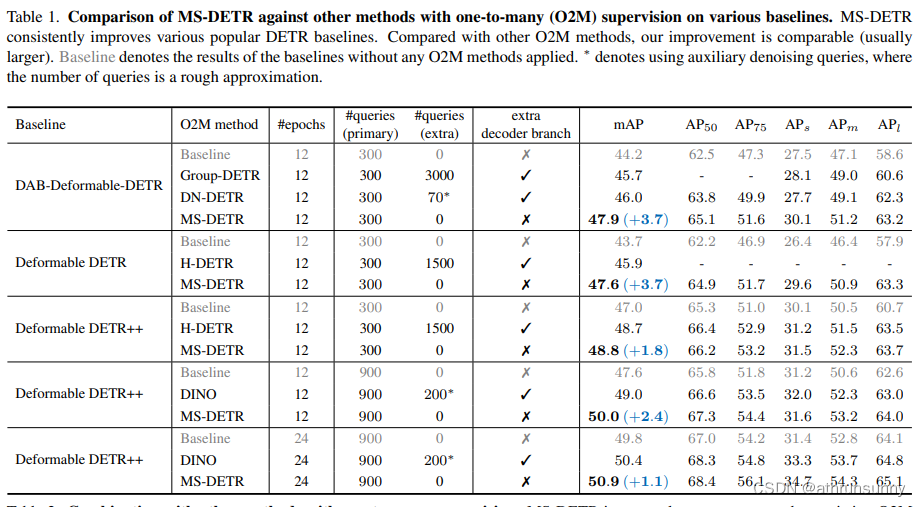
与具有单一监督的DETR变体进行比较,MS-DETR相对于Group DETR和DN-DETR在DAB-Deformable-DETR上的改进更大:在12个epochs下,相对于Group DETR和DN-DETR,作者的改进分别为 +1.5mAP和+3.7 AP,+1.8mAP和+3.7 mAP。
作者的改进也大于基于Deformable DETR和Deformable DETR++的Hybrid DETR:在12个epochs下,相对于Hybrid DETR,改进分别为 +2.2mAP vs +3.7mAP,+1.7 mAP vs +1.8 mAP。与具有单一监督的DINO进行比较,改进也更大:相对于DINO,改进分别为 +1.4mAP vs +2.4mAP,+0.8 mAP vs +1.1mAP,分别对应在12个epochs和24个epochs下。
相对于具有单一监督的DETR变体,MS-DETR的优势在于MS-DETR直接对主解码器中的目标 Query 施加一对多监督。
Combination with DETR variants with one-to-many supervision.表2显示了将MS-DETR与其他具有单一监督的DETR变体组合的结果。MS-DETR在这些方法上始终有所改进。在12个epochs下,相对于DN-DETR(-DCS) ,Group-DETR,DAC-DETR,Hybrid DETR和DINO,MS-DETR分别取得了2.0,0.6,1.0,0.8和1.3的mAP提升。MS-DETR在更长的训练计划(24个epochs)下进一步改进了DINO的性能,使其mAP提高了1.3。
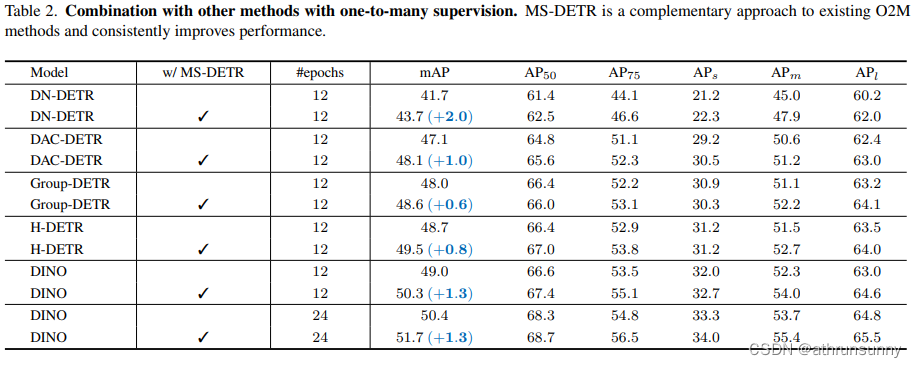
这些方法在额外的解码器分支上应用一对多监督,而主解码器分支上的 Query 仍然以一对一的方式进行监督。相比之下,MS-DETR直接在主解码器分支上的 Query 上应用一对多监督,从而实现了对这些方法的良好的互补。
Computation and memory efficiency.表3报告了 Baseline (使用300个 Query 的Deformable DETR++)以及Hybrid DETR,Group DETR和作者的MS-DETR的计算成本和内存成本。所有方法的基本批量大小相同。每个周期的训练时间是通过在12个周期内平均时间得出的。
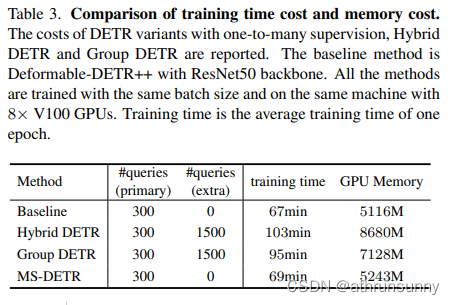
可以看到,对于MS-DETRMS-DETR,多对多监督带来的额外时间非常小:相对于 Baseline 的时间成本增加了2分钟。相比之下,Group DETR和Hybrid DETR的额外时间成本分别为+36和+28分钟,远大于MS-DETR。MS-DETR在内存效率方面也更具优势。例如,与 Baseline 相比,MS-DETR只增加了127M的内存(约2%),而Hybrid DETR和Group DETR的内存增加分别达到了 Baseline 的近60%和40%。原因在于Hybrid DETR和Group DETR引入了更多的 Query ,从而导致了更多的计算开销。
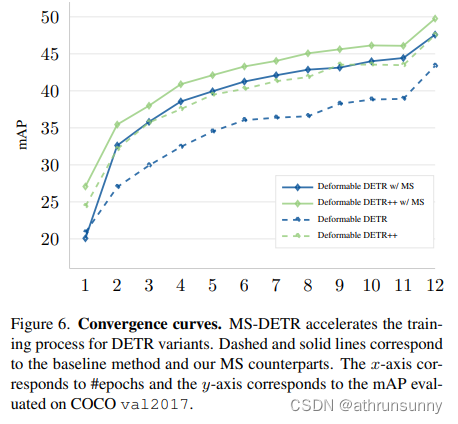
Convergence curves.在图6中,作者呈现了MS-DETR与相应 Baseline 的收敛曲线,分别是具有300个 Query 的Deformable DETR和具有900个 Query 的Deformable DETR++。这些模型都使用了ResNet-50作为 Backbone 架构,并经过12个周期的训练。作者观察到,在MS-DETR中引入混合监督可以加速训练收敛。
Combination with IoU-aware loss.作者研究了将MS-DETR与另一项改进DETR的IoU感知损失的工作相结合。作者在基于DINO Baseline 的Align-DETR上应用MS-DETR。表4显示,在12和24个周期的训练计划下,MS-DETR分别将Align-DETR的性能提高了0.5 AP和0.6 AP。这表明MS-DETR也可以补充IoU感知损失。

4.2. Ablation Study
Hyperparameters in one-to-many matching.作者说明了一对一匹配中的三个超参数的影响。
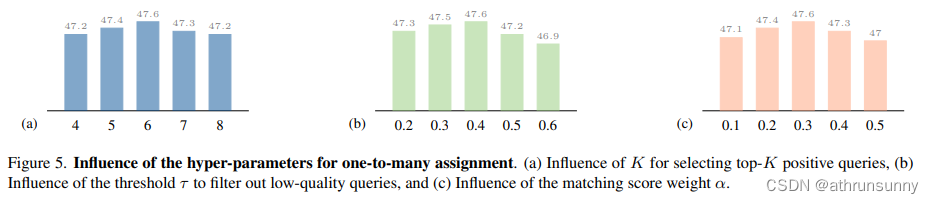
图5(a)说明了超参数对top Query 选择的影响。实际发现,当
时,MS-DETR达到了最优性能。较小的
值会减少阳性 Query 的数量。较大的
值会导致目标不平衡问题。
图5(b)可视化了用于过滤一对多监督中低质量 Query 的阈值的影响。MS-DETR在时取得了最佳结果。降低
的值会增加低质量 Query 的包含,而提高
的值则会减少有资格进行一对多监督的阳性 Query 的数量。
在图5(c)中呈现了一对多匹配分数中的分数权重的影响。较高的
值会增加分类分数的重要性,而较低的
值会增加IoU分数的重要性。在实践中发现,当
设置为0.4时,MS-DETR达到了最佳性能。
One-to-many supervision placement.报告了将一对多监督放置在解码器层内部和输出目标 Query 上的实际结果,以及跨注意力和自注意力的层内放置顺序的两种配置。这四个变体如图4所示。
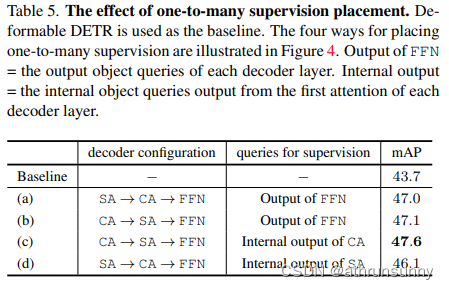
结果如表5所示。四个MS-DETR变体在 Baseline 上获得了显著的改进。直接将一对多监督放置在每个解码器层上的简单变体,在mAP方面获得了3.3的改进,而交换注意力和自注意力的顺序不会影响结果。如果将一对多监督放置在交叉注意力自注意力FFN配置的内部目标 Query 输出上,则可以进一步获得0.6的改进。这证实了第3.3节的分析。
Weight sharing for predictors of one-to-many and one-to-one supervision.作者对一对一和一对多监督的预测器之间的权重共享进行了实证分析。结果如表6所示。

可以看到,将权重共享给Box和类别预测器都取得了最佳性能。共享Box的预测器权重相对容易理解:一对多监督和一对一监督的Box预测器都需要提取相同的特征进行Box预测,而在某种意义上共享权重会增加监督。
作者假设将类别预测器的权重共享会导致:
-
为训练某些对一对多和一对一分类都有效的预测器权重添加更多的监督;
-
留下从一对一监督中学习到的为重复候选者评分的权重,这些权重不会影响一对多监督的预测。
Illustration of better candidate prediction from one-to-many supervision.在图7中通过一对多监督提高候选者预测质量的更多示例进行了说明。这些预测来自最终的物体 Query 。将IoU得分作为检测结果可视化。在顶部一行中展示了仅通过一对一监督训练的Deformable DETR Baseline 的检测结果。底部一行显示了MS-DETR的检测结果。可以看出,在混合监督下产生的候选者具有更好的质量,这证明了提高候选者质量的有效性。

4.3. Application to Instance Segmentation
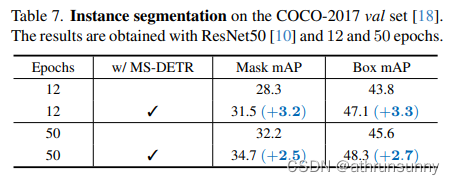
作者报告了实例分割的结果,以进一步证明其有效性。在Mask-Deformable-DETR Baseline 在COCO-2017 val集上的实例分割结果。在ResNet50 Backbone 上进行了12和50个epoch的实验。表7显示,在12个epoch的训练计划下,MS-DETR在 Baseline 的mask mAP上显著提高了3.2 mAP。在更长的50个epoch的训练计划下,它可以进一步提高 Baseline 的mask mAP,达到2.5 mAP。




)








:SQL函数之地理位置函数)

)


的原理和方案)
