个人学习笔记(整理不易,有帮助点个赞)
笔记目录:学习笔记目录_pytest和unittest、airtest_weixin_42717928的博客-CSDN博客
目录
一:参数化方法
1)用户定义的变量
2)函数助手
3)从文件中读取((可以格式是.csv或txt))
4)用户参数
二:jp@gc - Dummy Sampler
三:Jmeter关联
1)使用正则表达式实现接口关联
2)使用Jsonpath表达式实现接口关联(只能作用于返回值是Json的)
3)XPath提取器
4)json path extractor
5)beanshell后置处理器
6)跨线程组关联
一:参数化方法
脚本在运行时,根据需要选取不同的参数值作为输入,该方式称为数据驱动测试(Data Driven Test),而参数的取值范围被称为数据池(Data Pool)
1)用户定义的变量
配置元件-用户定义的变量
常用于设置一些全局变量,适用于测试计划中不需要随迭代发生改变的参数(只取一次值的参数),比如URL,host,port等
2)函数助手
函数助手自带丰富的函数,
比如随机函数,${_Random(100,999,)}
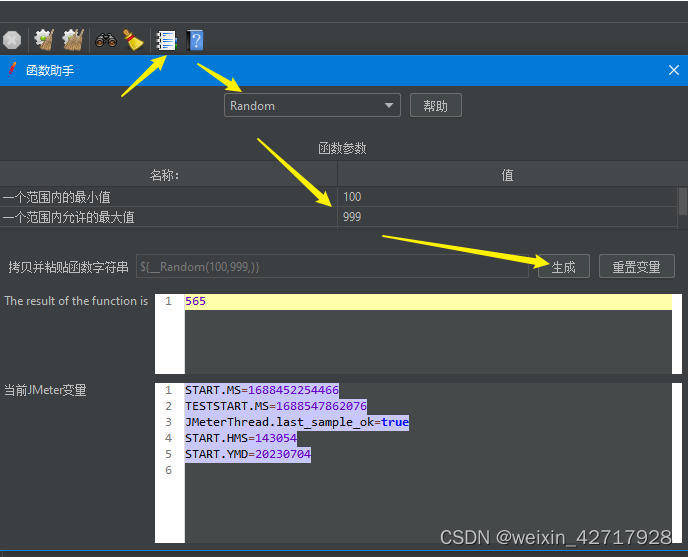

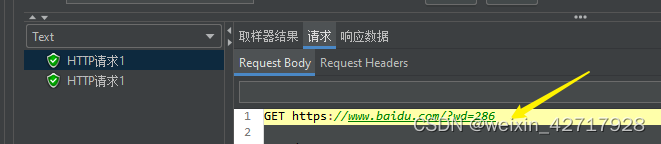
如果生成的随机数要被多处引用,可以这样


Jmeter在执行内置函数后,会将结果保存到到全局变量中
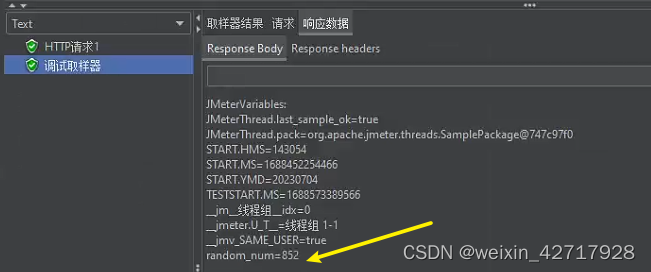
比如“CSVRead"函数,用来读取外部的CSV文件
在D盘创建一个data.csv文件,注意以逗号分隔
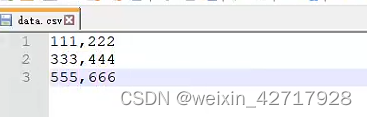
ps:数据需求多的话,直接数据库查,导出去用即可
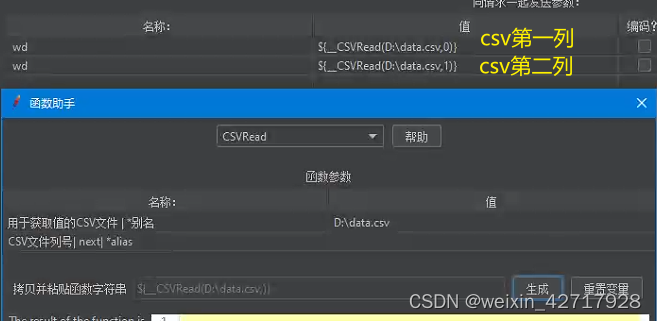
设置三个线程数(三个用户)
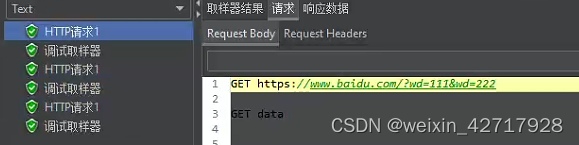
ps:__CSVRead函数规定每个线程都只读取一行数据。如果设置4个线程数,则第四个线程又会读取第一行,循环的
3)从文件中读取((可以格式是.csv或txt))
"CSV数据文件设置"这个元件对__CSVRead函数做了一定的扩展,使其更加的灵活
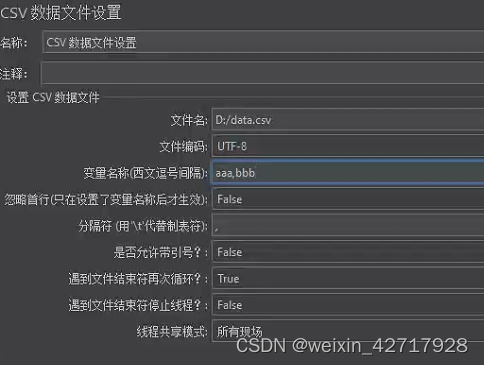

- 变量名称:之前是用0代表第一列,1代表第二列,这里可以为列起变量名
- 分割符:默认是逗号,也可以自己指定分隔符
- 当文件所有行读取完毕后,遇到文件结束符后再次循环?和遇到文件结束符停止线程?的关系是互斥的,也就是一个如果设置为true则另一个要设置为false
4)用户参数
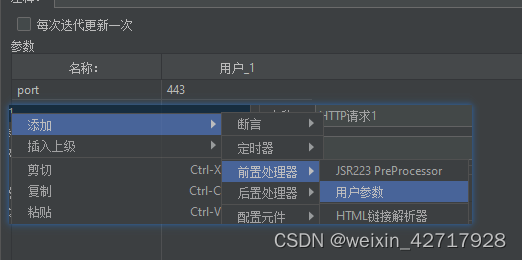
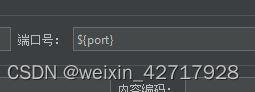
二:jp@gc - Dummy Sampler
本质是一个取样器,可以自己模拟请求与返回,类似mock服务(可以设置响应吗,响应信息,延迟时间(latency),响应时间,模仿响应时间,请求数据,响应数据,当服务器还没开发完成的时候,帮助调试脚本)
下载plugins-manager.jar包:Install :: JMeter-Plugins.org

把它放到jmeter安装的lib/ext目录下,然后重新启动jmeter
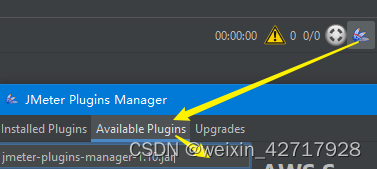
但是我这里不知道为毛线没有,搜索一下dum,发现这里也有能安装的,版本低了点,将就一下
点击线程组–>取样器–>Dummy Sampler
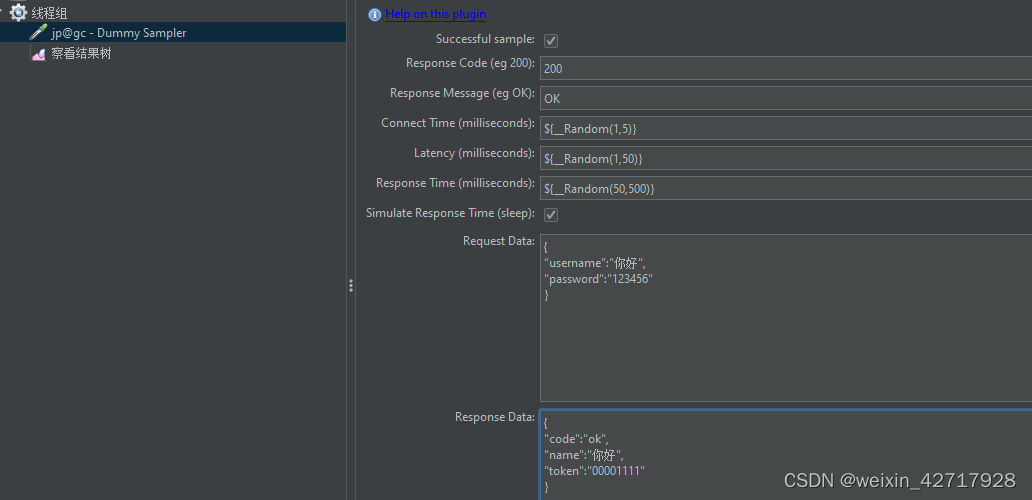
如果响应数据中的中文乱码,在安装目录/bin中的jmeter.properties,增加或者修改:sampleresult.default.encoding=GBK
三:Jmeter关联
关联就是说两个或多个请求之间是有先后顺序的、有联系的。比如上一个请求的响应内容是下一个请求的参数
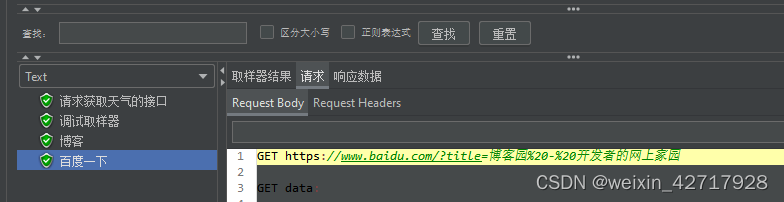
1)使用正则表达式实现接口关联
新建一个请求:http://www.weather.com.cn/data/sk/101010100.html

运行能看到结果

如果出现乱码,可以添加一个BeanShell后置处理程序,加上代码:prev.setDataEncoding("utf-8");

在查看结果树这里可以查看结果,也可以进行一些测试,比如正则表达式的测试:
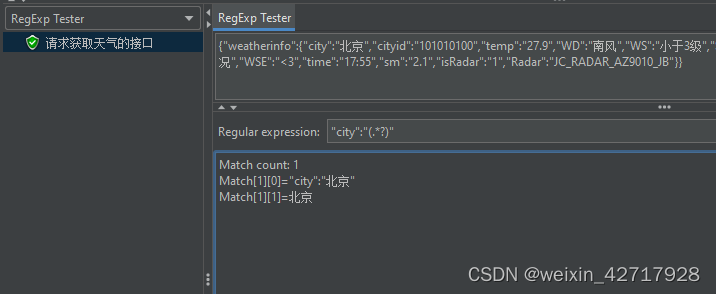
其中:
():封装了待返回的字符串.:匹配任意一个字符(除了回车键)*:限定符,匹配(*之前的符号)0次或多次,默认是贪婪模式+:限定符,匹配(+之前的符号)1次或多次,默认是贪婪模式?:限定符,匹配0次或1次,在找到第一个匹配项后停止.*:匹配连续0个/多个字符.+:匹配连续1个/多个字符\ :转义,\.表示匹配字符.本身
^:边界限定,字符串的开始位置
$:边界限定,字符串的结束位置
| :模式限定符,从中任选一个匹配
PS: 这个怎么理解,.是提取一个,但是使用了*或者+,那就会一直提取到最后一个字符串,?表示第一个匹配到第一个项就停止(也就是北京,然后有“,就停止了),所以如果不加?,则一直匹配到B为止
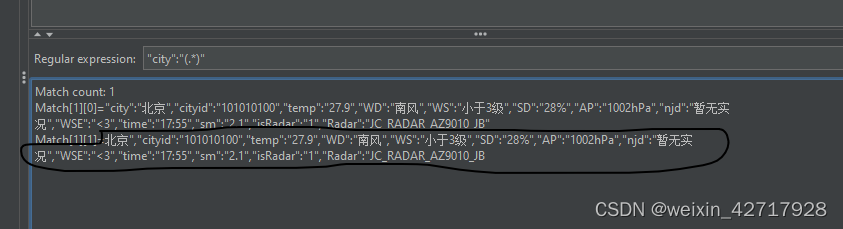
添加一个后置处理器:正则表达式提取器
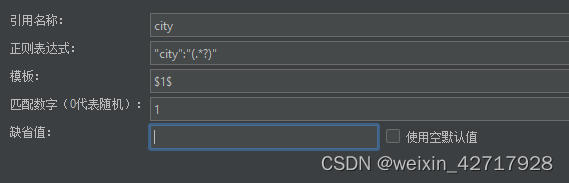
其中:
$1$表示解析到的第1个值,$$是固定写法
匹配数字:0代表随机取值,1表示匹配返回数组的第一个元素内容
缺省值:如果参数没有取得到值,那默认给一个值让它取
如果是取2个值就这样
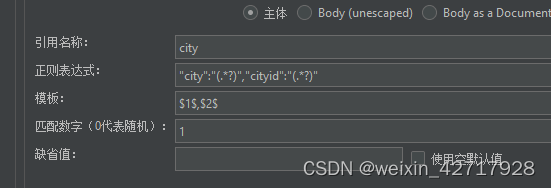
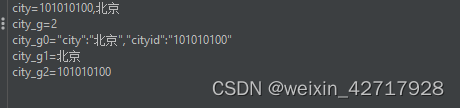
增加一个调试取样器,用于查看结果有没有取值到

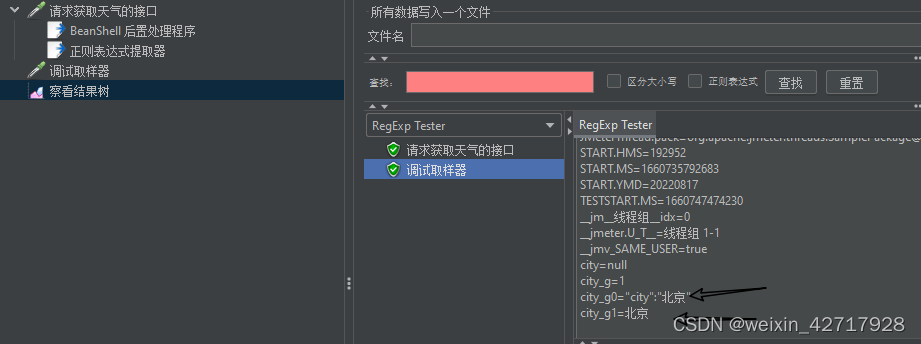
看到能提取想要的值后,就能在下一个请求去使用了
2)使用Jsonpath表达式实现接口关联(只能作用于返回值是Json的)
1)从根目录开始找(绝对路径):$.weatherinfo.temp
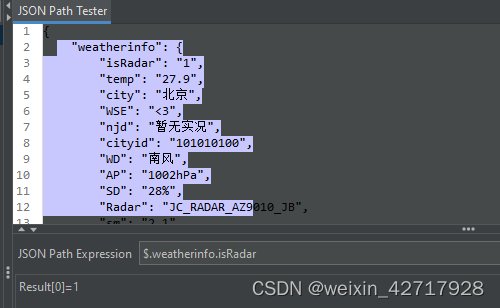
2)从任意目录开始找(相对路径):$..city
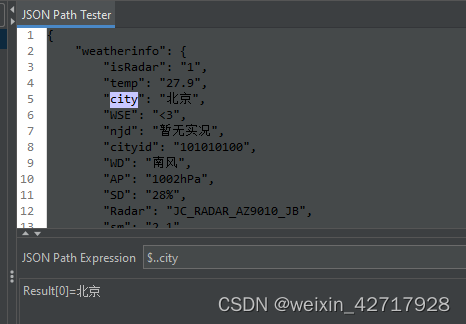
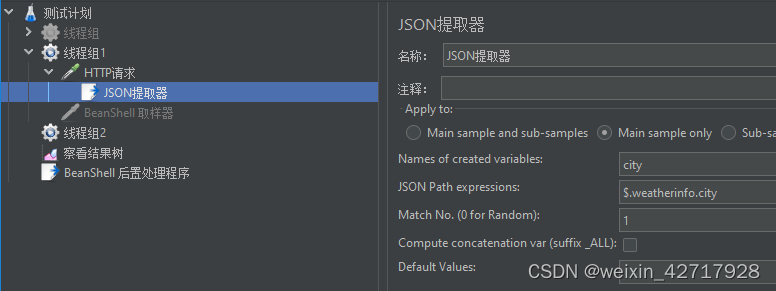
创建一个Json提取器,填写的内容和正则表达式类似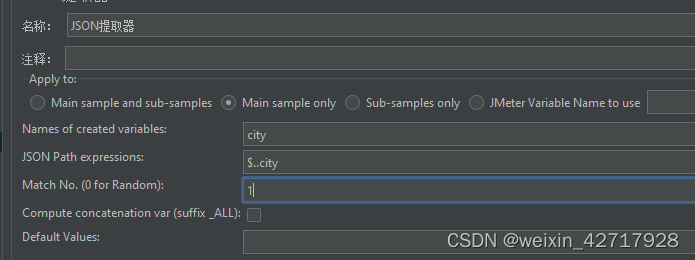
- Names of created variables:存放提取出的值的参数
- JSON Path Expressions:JSON路径表达式
- Match No.(0 for Random):取第几个
- Compute concatenation var(suffix _ALL):是否同级所有,即将匹配到的所有值保存,名为‘变量名_ALL’
- Default Values:缺省值,没取到就用这里填的值
- 注:获取多个值时,变量名、json、匹配值、缺省值要用分号间隔开
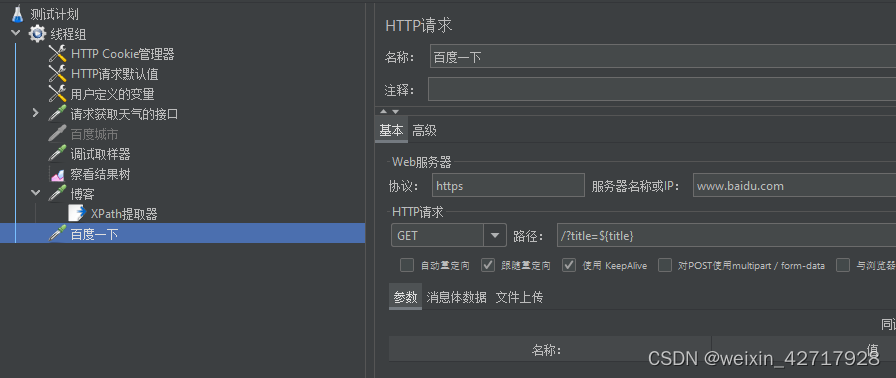
3)XPath提取器
如果请求返回的消息为xml或html格式的,可以用XPath提取器来提取需要的数据
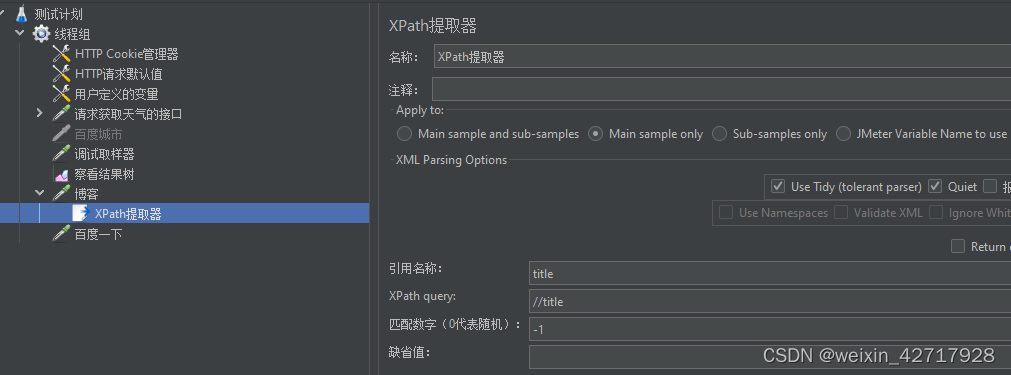
APPly to:作用范围(返回内容的断言范围)
- Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
- Main sample only:仅作用于父节点的取样器
- Sub-samples only:仅作用于子节点的取样器
- JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
ML Parsing Options:要解析的XML参数
- Use Tidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中
- Quiet表示只显示需要的HTML页面,Report errors表示显示响应报错,Show warnings表示显示警告
- Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨
- Validate XML:根据页面元素模式进行检查解析
- Ignore Whitespace:忽略空白内容
- Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容
Return entire XPath fragment of text content:返回文本内容的整个XPath片段
- 引用名称:存放提取出的值的参数
- XPath Query:用于提取值的XPath表达式
- 匹配数字:如果XPath路径查询导致许多结果,则可以选择提取哪个作为变量
0:表示随机
-1:表示提取所有结果(默认值),它们将被命名为<变量名>_N(其中N从1到结果的个数)
X:表示提取第X个结果。如果这个x大于匹配项的数量,则不返回任何内容。将使用默认值
- 缺省值:参数的默认值
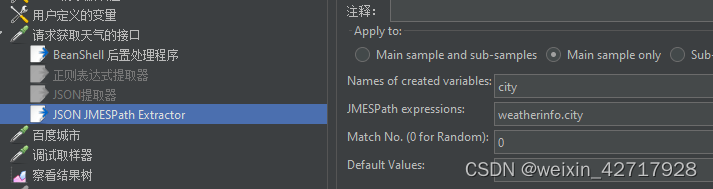
4)json path extractor
json extractor的使用与json path extractor基本相同,语法上有差别
做http接口测试,返回的数据是json串,Jmeter不支持直接处理json串,如果要获取到返回结果中指定的值,必须要要通过正则表达式来获取到,正则表达式比较麻烦,json是通过key-value来存值,可以通过json path extractor的插件(Jmeter3自带)


这个json串,cityid在weatherinfo这个集合里面存着,那就要先取到weatherinfo里面的值,再取weatherinfo里面的第三个元素


5)beanshell后置处理器
下载fastjson包,并放到\lib\ext下,重启jmeter(我这自带了)
https://mvnrepository.com/artifact/com.alibaba/fastjson
这里省略
6)跨线程组关联
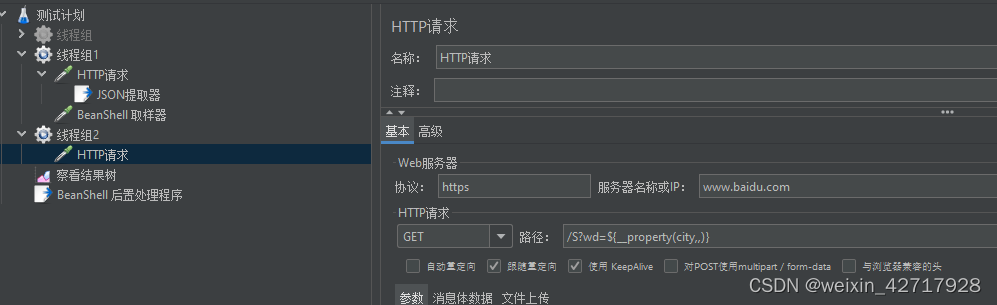
当有依赖关系的两个请求(一个请求的入参是另一个请求返回的数据),放入到不同的线程组中时,就不能使用提取器保存的变量来传递参数值,而是要使用Jmeter属性来传递。
jmeter属性配置方法
函数实现
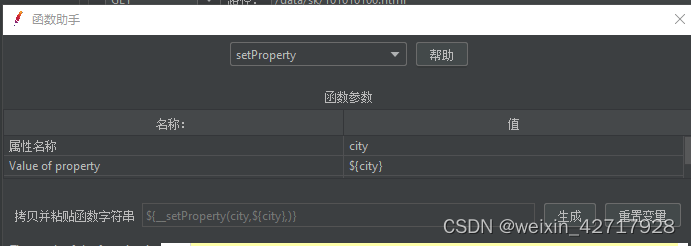
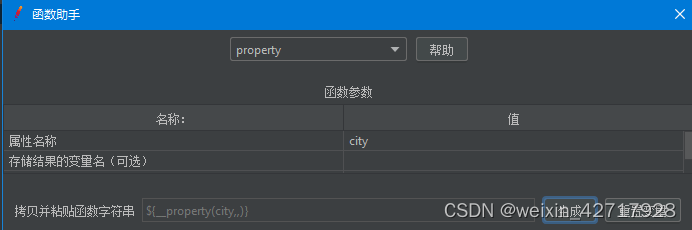
__setProperty函数:将值保存成jmeter属性
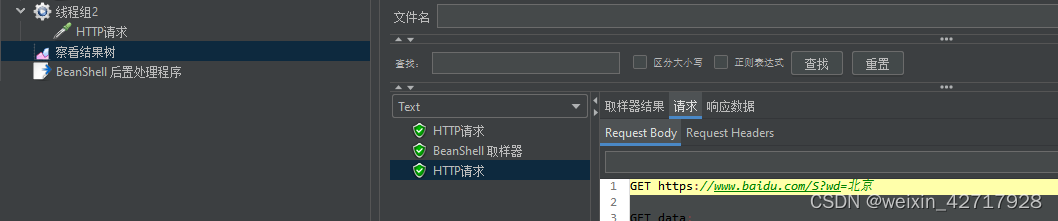
__property函数:在其他线程组中使用的property函数读取属性
注:__setProperty函数需要通过BeanShell取样器来执行(BeanShell取样器作用:执行函数和Java脚本)
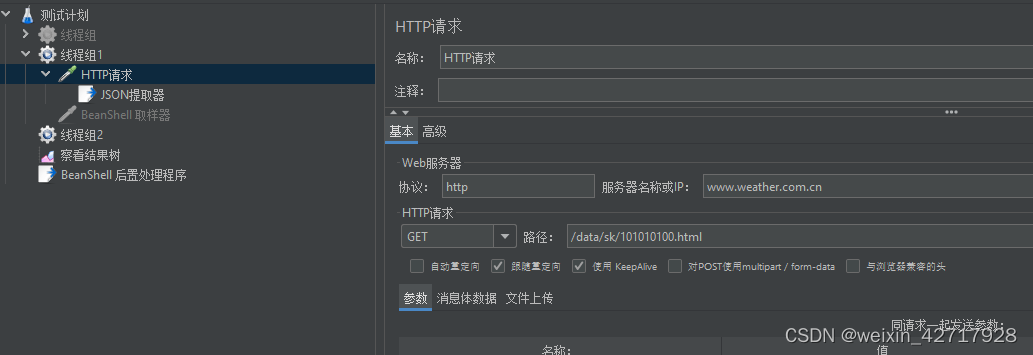
函数助手创建函数
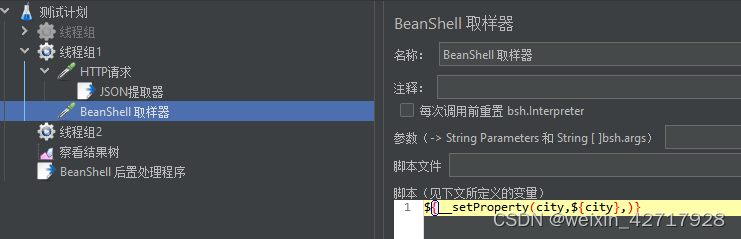
设置读取变量

如何在两台运行Ubuntu 20.04的系统上建立RabbitMQ集群)









)

:c++ array)





