继续研究超大规模数据场景的问题
一、对20GB文件进行排序
题目要求:假设你有一个20GB的文件,每行一个字符串,请说明如何对这个文件进行排序?
分析:这里给出大小是20GB,其实面试官就在暗示你不要将所有的文件都装入到内存里,因此我们只能将文件划分成一些块,每块大小是xMB,x就是可用内存的大小,例如1GB一块,那我们就可以将文件分为20块。我们先对每块进行排序,然后再逐步合并。这时候我们可以使用两两归并,也可以使用堆排序策略将其逐步合并成一个。相关方法我们在《查找》一章的堆排部分有介绍。这种排序方式也称为外部排序。
二、超大文本中搜索两个单词的最短距离
题目要求:有个超大文本文件,内部是很多单词组成的,现在给定两个单词,请你找出这两个单词在这个文件中的最小距离,也就是像个几个单词。你有办法在O()时间里完成搜索操作吗?方法的空间复杂度如何。
分析:这个题咋看很简单,遍历一下,找到这两个单词w1和w2的位置然后比较一下就可以了,然而这里的w1可能在很多位置出现,而w2也会在很多位置出现,如下图:
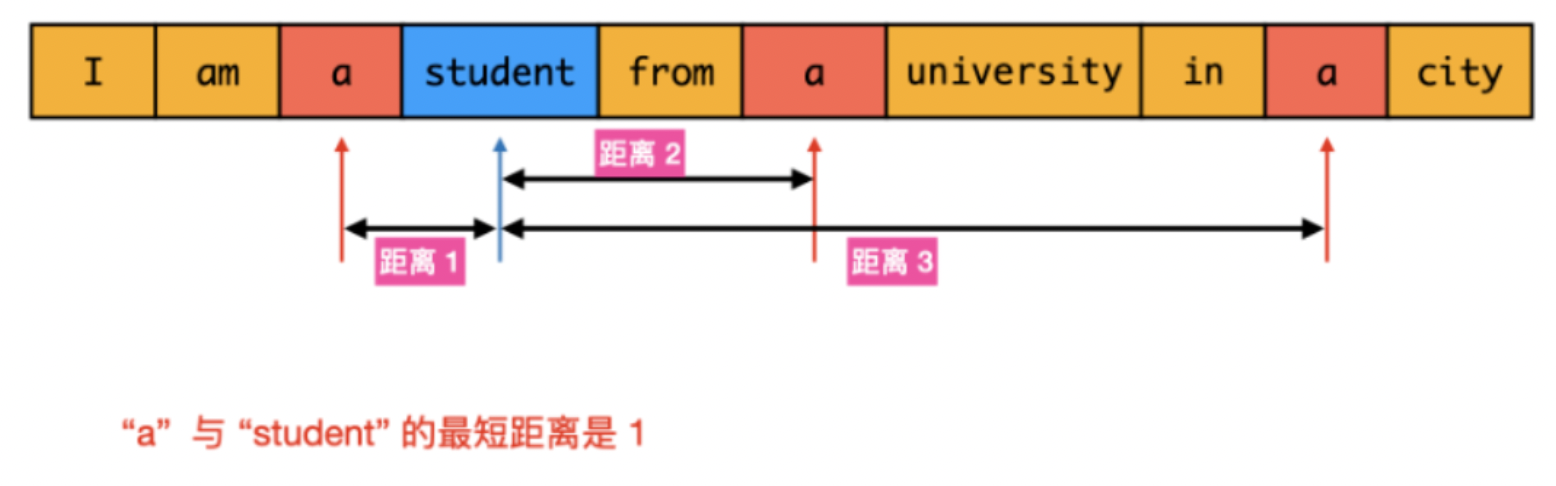
这时候如何比较寻找哪两个是最小距离呢?
最直观的做法是遍历数组words,对于数组中的每个word1,遍历数组words找到每个word2并计算距离。该做法在最坏情况下的时间复杂度是O(n^2),需要优化。
本题我们少不了遍历一次数组,找到所有word1和word2出现的位置,但是为了方便比较,我们可以将其放到一个数组里,例如:
l1stA:{1,2,9,15,25}
listB:{4,10,19}
合并成
list:{1a,2a,4b,9a,10b,15a,19b,25a}
合并成一个之后更方便查找,数字表示出现的位置,后面一个元素表示元素是什么。然后一边遍历一边比较就可以了。
但是对于超大文本,如果文本太大那这个ist可能溢出。如果继续观察,我们会发现其实不用单独构造ist,从左到右遍历数组words,当遍历到word1时,如果已经遍历的单词中存在word2,为了计算最短距离,应该取最后一个已经遍历到的word2所在的下标,计算和当前下标的距离。同理,当遍历到word2时,应该取最后一个已经遍历到的word1所在的下标,计算和当前下标的距离。
基于上述分析,可以遍历数组一次得到最短距离,将时间复杂度降低到O(n)。用index1和index2分别表示数组words已经遍历的单词中的最后一个word1的下标和最后一个word2的下标,初始时index1=index2=-1。遍历数组words,当遇到word2时,执行如下操作:
1.如果遇到word1,则将index1更新为当前下标;如果遇到word2,则将index2更新为当前下标。
2.如果index1和index22都非负,则计算两个下标的距离|index1-index2|,并用该距离更新最短距离。
遍历结束之后即可得到word1和word2的最短距离。
进阶问题如果寻找过程在这个文件中会重复多次,而每次寻找的单词不同,则可以维护一个哈希表记录每个单词的下标列表。遍历一次文件,按照下标递增顺序得到每个单词在文件中出现的所有下标。在寻找单词时,只要得到两个单词的下标列表,使用双指针遍历两个下标链表,即可得到两个单词的最短距离。
三、从10亿数字中寻找最小的100万个数字
题目要求:设计一个算法,给定一个10亿个数字,找出最小的100万的数字。假定计算机内存足以容纳全部10亿个数字。
本题有三种常用的方法,一种是先排序所有元素,然后取出前100万个数,该方法的时间复杂度为O(nlogn)。很明显对于10亿级别的数据,这么做时间和空间代价太高。
第二种方式是采用选择排序的方式,首先遍历10亿个数字找最小,然后再遍历一次找第二小,然后再一次找第三小,直到找到第100万个。很明显这种方式的时间代价是O(m)也就是要执行10亿100万次,这个效率一般的服务器都达不到。
第三种方式,采用大顶堆来解决,堆的原理在《查找》一章专门介绍过,方法思想是一致的,都是“查小用大堆,查大用小堆”。
首先,为前100万个数字创建一个大顶堆,最大元素位于堆顶。然后,遍历整个序列,只有比堆顶元素小的才允许插入堆中,并删除原堆的最大元素。之后继续遍历剩下的数字,最后剩下的就是最小的100万个。
采用这种方式,只需要遍历一次10亿个数字,还可以接受。更新堆的代价是O(nlogn),也勉强能够接受。堆占用的空间是100万4,大约为4MB左右的空间就够了,2因此也能接收。如果数据量没有这么大,也是可以直接使用这三种方式的。如果将10亿数字换成流数据,也可以使用堆来找,而且对于流数据,几乎只能用堆来做。
)














)



