目录
1:云数据库入门,基本概念了解
1.1 云数据库是关系型还是Nosql?
1.2 uniCloud 云数据库和关系型数据库的对比
1.3 官方文档传送门
2: 基本操作表 创建
在uniCloud web控制台 进行创建
数据表的3个组成部分
通过传统方式操作数据库
获取集合的引用
集合 Collection
获取数据 get
添加数据 add :
doc 引用
limit 数量限制
skip 设置起始位置
对结果排序
指定返回字段
带查询条件 where()
查询指令 command
eq 等于
gt 大于
in 在数组中
nin 不在数组中
and 且
or 或
正则则表达式查询
1:云数据库入门,基本概念了解
1.1 云数据库是关系型还是Nosql?
uniCloud提供了一个 JSON 格式的文档型数据库。顾名思义,数据库中的每条记录都是一个 JSON 格式的文档,它是 nosql
非关系型数据库。
1.2 uniCloud 云数据库和关系型数据库的对比
| 关系型 | JSON 文档型 |
|---|---|
| 数据库 database | 数据库 database |
| 表 table | 集合 collection。但行业里也经常称之为“表”。无需特意区分 |
| 行 row | 记录 record / doc |
| 字段 column / field | 字段 field |
| 使用sql语法操作 | 使用MongoDB语法或jql语法操作 |
- 一个
uniCloud服务空间,有且只有一个数据库; - 一个数据库可以有多个表;
- 一个表可以有多个记录;
- 一个记录可以有多个字段。
1.3 官方文档传送门
传送门
2: 基本操作表 创建
在uniCloud web控制台 进行创建
-
打开 uniCloud web控制台 uniCloud控制台
-
创建或进入一个已存在的服务空间,选择 云数据库->云数据库,创建一个新表
比如我们创建一个简历表,名为 resume。点击上方右侧的 创建 按钮即可。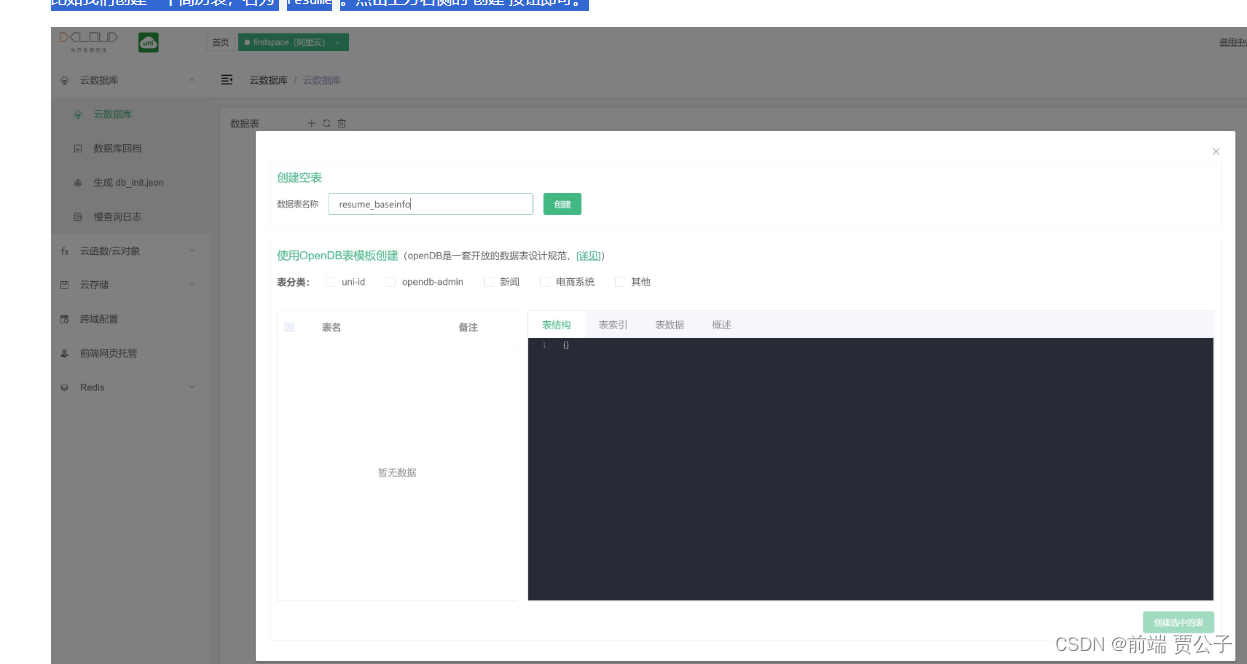
新建表时,支持选择现成的 opendb 表模板,选择一个或多个模板表,可以点击右下方按钮创建。
创建表一共有3种方式:
- 在web控制台创建
- 在HBuilderX中,项目根目录/uniCloud/database点右键新建schema,上传时创建
- 在代码中也可以创建表,但不推荐使用,见下
数据表的3个组成部分
每个数据表,包含3个部分:
- data:数据内容
- index:索引
- schema:数据表格式定义
在uniCloud的web控制台可以看到一个数据表的3部分内容。
数据内容
data,就是存放的数据记录(record)。里面是一条一条的json文档。
record可以增删改查、排序统计。后续有API介绍。
可以先在 web控制台 为之前的 resume 表创建一条记录。
输入一个json
{"name": "张三","birth_year": 2000,"tel": "13900000000","email": "zhangsan@zhangsan.com","intro": "擅于学习,做事严谨"
}
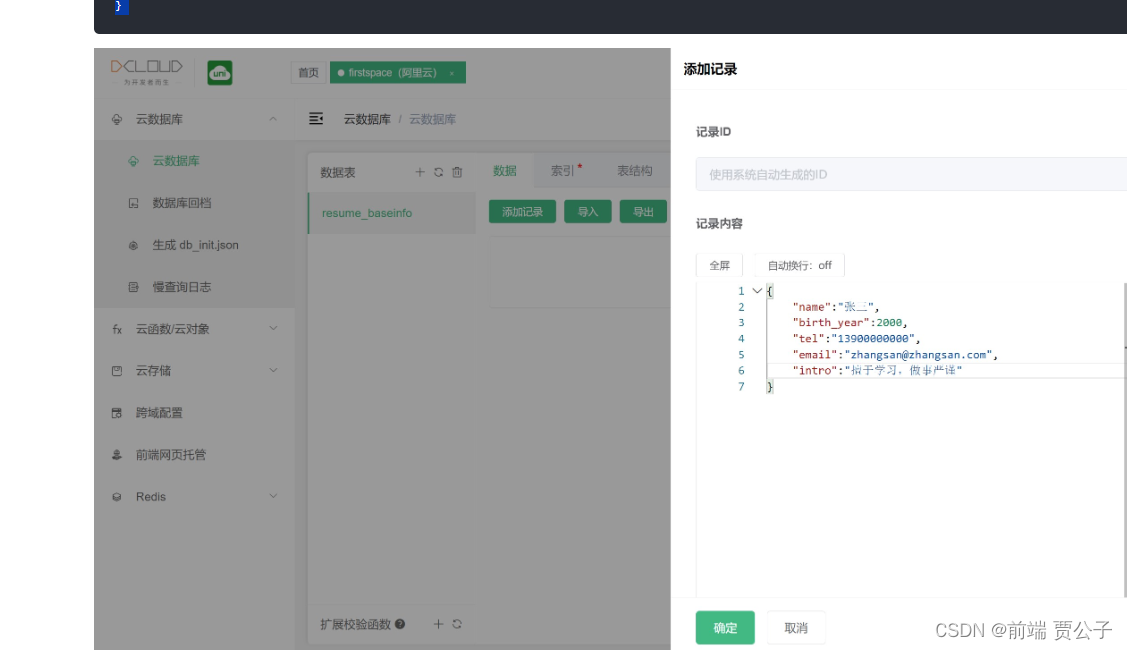
创建一条新记录,是不管在web控制台创建,还是通过API创建,每条记录都会自带一个_id字段用以作为该记录的唯一标志。
_id字段是每个数据表默认自带且不可删除的字段。同时,它也是数据表的索引。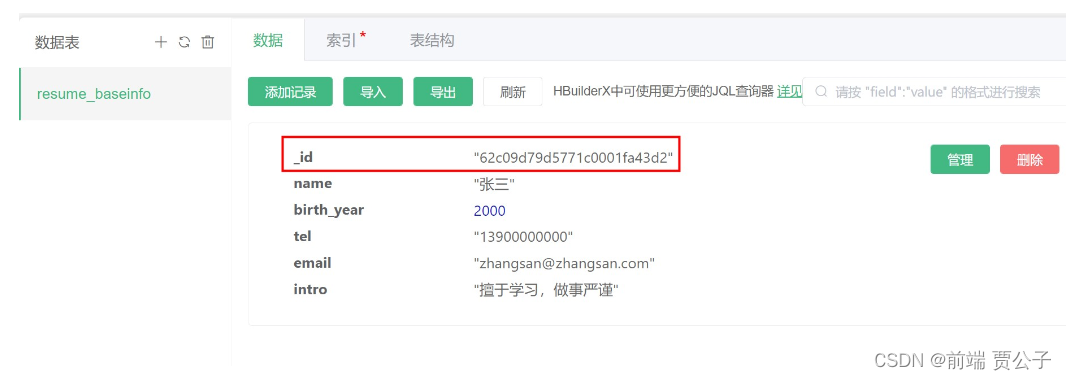
阿里云使用的是标准的mongoDB,_id是自增的,后创建的记录的_id总是大于先生成的_id。传统数据库的自然数自增字段在多物理机的大型数据库下很难保持同步,大型数据库均使用_id这种长度较长、不会重复且仍然保持自增规律的方式。
腾讯云使用的是兼容mongoDB的自研数据库,_id并非自增
插入/导入数据时也可以自行指定_id而不使用自动生成的_id,这样可以很方便的将其他数据库的数据迁移到uniCloud云数据库。
通过传统方式操作数据库
云函数中支持对云数据库的全部功能的操作。本章节主要讲解如何在云函数内通过传统api操作数据库,如需在云函数内使用JQL语法操作数据库,请参考:云函数内使用JQL语法
获取集合的引用
const db = uniCloud.database();
// 获取 `user` 集合的引用
const collection = db.collection('user');
集合 Collection
通过 db.collection(name) 可以获取指定集合的引用,在集合上可以进行以下操作
| 类型 | 接口 | 说明 |
|---|---|---|
| 写 | add | 新增记录(触发请求) |
| 计数 | count | 获取符合条件的记录条数 |
| 读 | get | 获取集合中的记录,如果有使用 where 语句定义查询条件,则会返回匹配结果集 (触发请求) |
| 引用 | doc | 获取对该集合中指定 id 的记录的引用 |
| 查询条件 | where | 通过指定条件筛选出匹配的记录,可搭配查询指令(eq, gt, in, ...)使用 |
| skip | 跳过指定数量的文档,常用于分页,传入 offset | |
| orderBy | 排序方式 | |
| limit | 返回的结果集(文档数量)的限制,有默认值和上限值 | |
| field | 指定需要返回的字段 |
查询及更新指令用于在 where 中指定字段需满足的条件,指令可通过 db.command 对象取得。
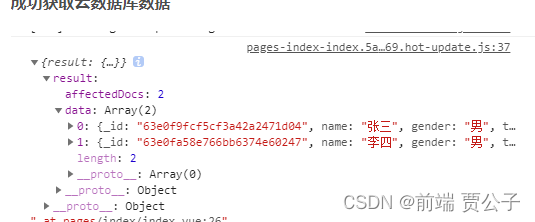
获取数据 get
'use strict';
// 连接云数据库
const db = uniCloud.database()
exports.main = async (event, context) => {// 获取 `user` 集合的引用const collection = db.collection('users');// 读let res = await collection.get()return res
};成功获取云数据库数据
添加数据 add :
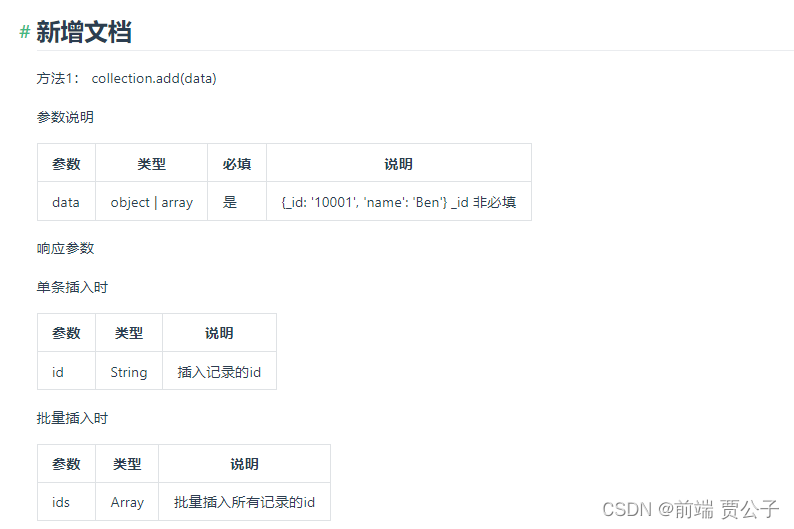
'use strict';
// 连接云数据库
const db = uniCloud.database()
exports.main = async (event, context) => {// 获取 `user` 集合的引用const collection = db.collection('users');// 添加 addlet res = await collection.add({name: "610",gender: "666888666"})return res
};添加成功

doc 引用
获取到具体的某一条制定数据
'use strict';
const db = uniCloud.database()
exports.main = async (event, context) => {const collection = db.collection('users');// 读 getlet res = await collection.doc("63e0fa58e766bb6374e60247").get()return res
}; 

limit 数量限制
限制获取数据的数量
let res = await collection.limit(2).get()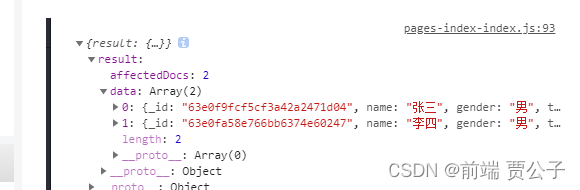
skip 设置起始位置
collection.skip(value)
参数说明
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| value | Number | 是 | 跳过指定的位置,从位置之后返回数据 |
使用示例
let res = await collection.skip(4).get()
复制代码
注意:数据量很大的情况下,skip性能会很差,尽量使用其他方式替代,参考:skip性能优化
对结果排序
collection.orderBy(field, orderType)
参数说明
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| field | string | 是 | 排序的字段 |
| orderType | string | 是 | 排序的顺序,升序(asc) 或 降序(desc) |
如果需要对嵌套字段排序,需要用 "点表示法" 连接嵌套字段,比如 style.color 表示字段 style 里的嵌套字段 color。
同时也支持按多个字段排序,多次调用 orderBy 即可,多字段排序时的顺序会按照 orderBy 调用顺序先后对多个字段排序
使用示例
let res = await collection.orderBy("name", "asc").get()
注意
- 排序字段存在多个重复的值时排序后的分页结果,可能会出现某条记录在上一页出现又在下一页出现的情况。这时候可以通过指定额外的排序条件比如
.orderBy("name", "asc").orderBy("_id", "asc")来规避这种情况
指定返回字段
collection.field()
从查询结果中,过滤掉不需要的字段,或者指定要返回的字段。
参数说明
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
| - | object | 是 | 过滤字段对象,包含字段名和策略,不返回传false,返回传true |
使用示例
collection.field({ 'age': true }) //只返回age字段、_id字段,其他字段不返回
复制代码
注意
- field内指定是否返回某字段时,不可混用true/false。即{'a': true, 'b': false}是一种错误的参数格式
- 只有使用{ '_id': false }明确指定不要返回_id时才会不返回_id字段,否则_id字段一定会返回。
带查询条件 where()
//查询 username 等于zhangsan
db.collection('user').where({username:'zhangsan',}).get()
// 查询 username 等于zhangsan 和猪八戒db.collection('user').where("username in ['zhangsan','猪八戒']").get()
//查询 username 等于zhangsan 或者_id==65814f6f652341901b75d140db.collection('user').where("username=='zhangsan' || _id=='65814f6f652341901b75d140'").get()
//查询 username 等于zhangsan 并且_id==65814f6f652341901b75d140db.collection('user').where("username=='zhangsan' && _id=='65814f6f652341901b75d140'").get()
//正则匹配 username 里面包含李四的数据db.collection('user').where("/李四/.test(username)").get()
查询指令 command
查询指令以dbCmd.开头,包括等于、不等于、大于、大于等于、小于、小于等于、in、nin、and、or。
下面的查询指令以以下数据集为例:
// goods表[{"type": {"brand": "A","name": "A-01","memory": 16,"cpu": 3.2},"category": "computer","quarter": "2020 Q2","price": 2500
},{"type": {"brand": "X","name": "X-01","memory": 8,"cpu": 4.0},"category": "computer","quarter": "2020 Q3","price": 6500
},{"type": {"brand": "S","name": "S-01","author": "S-01-A"},"category": "book","quarter": "2020 Q3","price": 20
}]eq 等于
表示字段等于某个值。eq 指令接受一个字面量 (literal),可以是 number, boolean, string, object, array。
const dbCmd = db.command
const myOpenID = "xxx"
let res = await db.collection('articles').where({quarter: dbCmd.eq('2020 Q2')
}).get()// 查询返回值
{"data":[{"type": {"brand": "A","name": "A-01","memory": 16,"cpu": 3.2},"category": "computer","quarter": "2020 Q2","price": 2500}]
}
gt 大于
字段大于指定值。
如筛选出价格大于 3000 的计算机:
const dbCmd = db.command
let res = await db.collection('goods').where({category: 'computer',price: dbCmd.gt(3000)
}).get()// 查询返回值
{"data":[{"type": {"brand": "X","name": "X-01","memory": 8,"cpu": 4.0},"category": "computer","quarter": "2020 Q3","price": 6500}]
}in 在数组中
字段值在给定的数组中。
筛选出内存为 8g 或 16g 的计算机商品:
const dbCmd = db.command
let res = await db.collection('goods').where({category: 'computer',type: {memory: dbCmd.in([8, 16])}
}).get()// 查询返回值
{"data":[{"type": {"brand": "A","name": "A-01","memory": 16,"cpu": 3.2},"category": "computer","quarter": "2020 Q2","price": 2500},{"type": {"brand": "X","name": "X-01","memory": 8,"cpu": 4.0},"category": "computer","quarter": "2020 Q3","price": 6500}]
}
nin 不在数组中
字段值不在给定的数组中。
筛选出内存不是 8g 或 16g 的计算机商品:
const dbCmd = db.command
db.collection('goods').where({category: 'computer',type: {memory: dbCmd.nin([8, 16])}
})// 查询返回值
{"data":[]
}
and 且
表示需同时满足指定的两个或以上的条件。
如筛选出内存大于 4g 小于 32g 的计算机商品:
const dbCmd = db.command
db.collection('goods').where({category: 'computer',type: {memory: dbCmd.and(dbCmd.gt(4), dbCmd.lt(32))}
})or 或
表示需满足所有指定条件中的至少一个。如筛选出价格小于 4000 或在 6000-8000 之间的计算机:
const dbCmd = db.command
db.collection('goods').where({category: 'computer',type: {price: dbCmd.or(dbCmd.lt(4000), dbCmd.and(dbCmd.gt(6000), dbCmd.lt(8000)))}
})如果要跨字段 “或” 操作:(如筛选出内存 8g 或 cpu 3.2 ghz 的计算机)
const dbCmd = db.command
db.collection('goods').where(dbCmd.or({type: {memory: dbCmd.gt(8)}},{type: {cpu: 3.2}}
))// 查询返回值
{"data":[{"type": {"brand": "A","name": "A-01","memory": 16,"cpu": 3.2},"category": "computer","quarter": "2020 Q2","price": 2500},{"type": {"brand": "X","name": "X-01","memory": 8,"cpu": 4.0},"category": "computer","quarter": "2020 Q3","price": 6500}]
}
正则则表达式查询
db.RegExp
根据正则表达式进行筛选
例如下面可以筛选出 version 字段开头是 "数字+s" 的记录,并且忽略大小写:
根据正则表达式进行筛选
例如下面可以筛选出 version 字段开头是 "数字+s" 的记录,并且忽略大小写:
// 可以直接使用正则表达式
db.collection('articles').where({version: /^\ds/i
})// 也可以使用new RegExp
db.collection('user').where({name: new RegExp('^\\ds', 'i')
})// 或者使用new db.RegExp,这种方式阿里云不支持
db.collection('articles').where({version: new db.RegExp({regex: '^\\ds', // 正则表达式为 /^\ds/,转义后变成 '^\\ds'options: 'i' // i表示忽略大小写})
}





)







)


+ pytorch学习)

