VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts (NeurIPS 2022)
VLMo 是一种多模态 Transformer 模型,从名字可以看得出来它是一种 Mixture-of-Modality-Experts (MoME),即混合多模态专家。怎么理解呢?主流 VLP 模型分为两种,一种是双塔结构 (Dual Encoder),主要用来做多模态检索任务;一种是单塔结构 (Fusion Encoder),主要用来做多模态分类任务。VLMo 相当于是一个混合专家 Transformer 模型,预训练完成后,使用时既可以是双塔结构实现高效的图像文本检索,又可以是单塔结构成为分类任务的多模态编码器。
作者团队,全部来自于这个微软这个团队近几年,真的是出了很多大名鼎鼎的工作,比如说BEiT v1,v2,v3,还有LayoutLM v1,v2,v3,还有做语音的,做视频的,真的是多模态领域里非常solid的一个组。所以大家如果想做多模态学习,任何一个领域的多模态学习,都可以去看一下他们组发的论文,应该或多或少,都会有一些联系的。这篇论文的贡献,其实有两点,一个就是模型结构上的改进,也就是他这里说的这个mixture of modality experts。另外一个,就是训练方式上的改进,他们做的这种分阶段的这个模型与训练。这两个改进,其实都师出有名,都有非常强的这个研究动机,接下来,我们就直接去引言看一下这两个研究动机。
引言的第二段,作者上来就说了第一个研究动机,就是他们为什么要介绍这个mixture of expert。作者说,在多模态学习领域,大概有两个这个主流的模型结。一个就是像CLIP,ALIGN这种的,采取了双塔结构,图像有一个模型,文本有一个模型,双塔完全分开了,谁跟谁都不染。然后模态之间的交互,就是被一个非常简单的cosine similarity去做的。它的好处,我们上次也说过,非常明显,就是尤其是对这种,这个检索任务来说,极其有效。因为他可以提前把那些特征都抽好,然后接下来直接算similarity就好了,矩阵乘法,还不是飞快,所以说,极其适合这种大规模的这个图像文本的检索,非常具有这个商业价值。但是,它的缺点也由此而体现,就是说如此shallow的这个交互,也就是说只算了一个similarity,是无法做这种多模态之间,非常难的这个各种情形的。比如说,在ViLT这篇论文里的作者就发现,即使CLIP那么的强,CLIP其实在一系列的这个下游任务上,比如说VR,他其实就比不过之前方式。那自然,肯定就有另外一系列的工作,那你之前是双塔,那现在肯定就是单塔,单塔就是这个fusion encoder的方式。就是我先把这个图像文本分开处理一下,但是当做这个模态交互的时候,我用这个transformer encoder,去好好的做一下模态之间的这个交互。这样,就弥补了你之前这个双塔模式的缺陷,所以说在这个VL visual classification task上,也就我们刚才说的VE,VR,VQQ,取得了这个,就是效果特别好,但是,它也有问题,就是当你去做检索任务的时候,又出麻烦了,因为你只有一个模型,你必须同时做这个推理,所以当你这个图像文本对特别多数据集特别大的时候,你就要把所有all possible这个图像文本段全都要同时的去编码。然后去算这个similarity,而你才能去做这个检索。所以说,它的这个推理时间,就会非常非常的慢,所以对于大规模数据集来说,去做检索的话,基本就不太现实了。那鉴于这种情况,一个很直接的想法就是说,既然你各有各的优缺点,那我能不能把你放到同一个框架里去?然后在做推理的时候,我想把你当做dual-encoder这个来用,我就把你当dual-encoder来用。我想把你当fusion encoder来用,我就把你当fusion encoder来用,那如果能达到这个灵活性,那岂不是特别美好。所以说,作者这里就引出了他们这篇文章提出的,,这个mixture of modality expert。具体的细节,我们会接下来照着图讲。
但简单来说,就是这个自注意力,所有的模态都是共享的。但是在Feed Forward FF层,每个模态就会对应自己不同的Expert。Multi就multi model对应的expert。这样在训练的时候,哪个模态的数据来了,我就训练哪个模态的,然后在推理的时候,我也能根据现在输入的数据,去决定我到底该使用什么样的模型结构,这样就非常优雅的解决了第一个这个研究难题。
那另外一个研究动机,就是在引言的四段。作者上说,其实的时候的这个目标函数,也是ITC,ITM和MLM。所以跟ALBEF是一样,所以在这篇论文里,我都不需要再过多复述。但这样,就会有一个让大家很感兴趣的问题,就是这个训练数据的问题。因为我们都看到了NLP那边用了Transformer,随着这个数据的增加,这个结果就会不停的变好变好变好。在视觉这边,虽然暂时没有看到就是这么好的这个scaling的性能,但是对于多模态来讲,因为他里面也有文本,所以说做多模态学习的任务,他也希望说看到当你这个训练数据集越多的时候,你的这个模型的性能就越好,CLIP,其实已经在某种程度上验证了这一点了。所以大家自然是会想在更多的数据集上去做预训练的。但可惜,在当时做ALBEF,VLMo的时候,LION团队还没有推出400m或者这样可开源的数据集。CLIP用的那个WIT数据集,也并没有开源。所以说对于研究者来说,他们自己如果想去构造这么大规模的一个数据集来说,这个effort是非常大的,那这个时候,一条曲线救国的道路,很自然的就摆在面前。那就是说虽然多模态的训练数据集不够,比如说只有4m setting,或者14m setting。但是,在单个的modality里,就是视觉,或者NLP里有大把大把的数据可以去用,即使你是想有监督的训练,视觉里也有达ImageNet 22K,有14M的数据,那就已经比多这边最大的14m的setting还要大。那如果你是说我想要无监督的预训练,那可用的数据更是多的数不胜数,那文本那边,也是多的数不胜数。所以说,基于这个研究动机,本文作者,就提出了一个stage strategy,就是说我分阶段去训练。既然你这个视觉和NLP领域,都有自己各自的这么大的数据集,那我就先把这个vision expert在视觉数据集这边好。然后我再去把language expert,在language那边的数据集上text only Data上训练好 。那这个时候,这个模型本身这个参数,已经是非常好的被初始化过了,那这个时候,你再在这个多模态的数据上,去做一下被确定效果,应该就会好很多。而事实也确实如此,这个stage策略给带来了很大的提升。那接下,我们就先看一下的模型结构什么样,然后快速看一下它的结果。

那我们直接来看文章的图一,首先,我们来看一下图一的左边,也就是VLMo这篇论文的一个核心。
它也是一个transformer encoder的结构,但是,它在每个block里面,做了一些改动,也就是他们提出的这个MoME Transformer。具体来说,其实我都知道。一本标注的transformer blcok里面,就是先有一个layer norm,然后MSA multi-head self-attention,然后再有一个layer norm,再有FFN feed-forward network,最后有一个residual。
这个不是一个network,而是针对不同的这个输入,不同的modality,它有这个vision FFN,language FFN,还有这个vision language FFN。也就是他这里说的这个switching modality expert,从而构建出了的MoME transformer block这个模型结构。

那这里面其实一个比较有意思的点,就是说虽然后面这个FFN层,它没有share 权重,它是各自modality有各自的这个FFN层,但是之前,这个self attention层,是完全share weights的。也就是说,不论你是图像信号,还是这个文本信号,还是图像文本信号,你任何的这个token sequence进来,我的这个self attention的model weight全都是一样的,都是shares的。所以这也就是我为什么觉得,Transform这个结构很好,或者说多模态学习接下来会是一个趋势,因为这个多模态学习,搭配上这个transformer,真的是一个绝佳的组合,Transformer这个自注意操作,它真的是用了最少的这个inductive bais,它不挑输入。基本上我们现在已经看到了很多的这个证据,就是说同样的这个self attention weights它可以用来做不同的,这个图像,文本,音频,视频,很多这样的任务,你是不需要重新去训练这个自注意力参数的。
那接下来,这篇论文在分阶段训练里面,我们还可以看到更强的这个evidence,更加的有意思。
VLMo也是用ITC、ITM、MLM 3个loss去训练的。所以说训练loss,是完全一致的。那至于他是怎么去算这个loss,它的fusion encoder这个到底长什么样,其实跟ALBEF也差不多,只不过更比灵活一些。如说我们这个ITC,就是图像这边,VLMo就化身CLIP模型,就单独只有图像的输入,然后进去了一个ViT,它里面的FFN,都用的是vision FFN。这个L,如果你用的vision transformer base,那就是12层的transformer。那文本这边,就是文本的token,单独进去这个language model,后面用的是这个language expert,就是一个12层的BERT base。所以说如果你只看这个ITC这块,它就是一个CLIP模型。然后当我们去看这个ITM,或者说这个MLM的时候。它又化身成了fusion encoder的形式,就是说这个图像和文本的这个输入,一起进去,一起进这个MSA。

但这里的这个self attention跟之前的self attention,和后面的self attention这些,都是share weights的,都是一样的,不管你是什么modality,自注意力参数,都是不变的,都是share。然后,在前面的L-F层,就在transform block里,它是对这个视觉和文本信号,分别去做模型FFN,就是分别去用这个vision expert和这个language expert。只有在最后的这Fx层,他才去用了这个vision language expert。
在论文的最后的时间细节里,作者说如果你用的是一个transformer base模型,L-F就是前10层,后面这个F,就是2,也就是说后面,只有2层transformer block,去做这个模态之间的融合。然后ITM对吧,就是一个分类任务。然后,Mask language model,就是去预测这些被mask掉的单词。
那我们看完整套的这个模型结构和训练方式之后,我们就会发现,VLMo这篇论文的好处,它就是灵活。那训练的时候,你可以通过这个各种modality,你可以去选择,我到底训练中间哪个modality expert。然后在做推理的时候,你也可以去做选择,因为所有的模型参数都在那里,如果你想做这个检索任务,,你就像CLIP一样,就用这个两个模型就可以了。如果你想做这些vision,这些分类任务,VR,VQA,那你就下面的这个模式就可以。但是,它的灵活也不是白来了,那就像我们在ALBEF里说的一样,因为它有的时候用这个mask的输入,有的时候不用这个mask输入,所以ALBEF里,就要做两次。而在VLMo里面,他应该也是至少做了两次甚至三次的这个前过程。作者在后面说,VLMo,这个base模型,在4m setting下训练,用64 张 32G V100的卡,也要训练两天,所以说比ALBEF要慢。
但总之,这个模型结构,真的是很灵活,也很有趣,所以作者团队,在接下来时间中还在继续打磨。
那讲完了模型结构上的改进,我们就来说一下第二个文章的contribution,就是这个分阶段的训练策略。因为作者,想利用那些大量的这些图片文本,去做这种很好的预训练,提供一个更好的模型初始化,所以说作者,就先去做了这个vision training,去做language training,然后最后,才去做这个vision language training。是modality modeling,那最后,Vision,就是我们刚才说的那三个R目标函数。
但是这里面特别有趣的一个点,就是作者在训练的过程中,到底哪些层是冻住的,哪些层是不冻住的,需要仔细看一下。
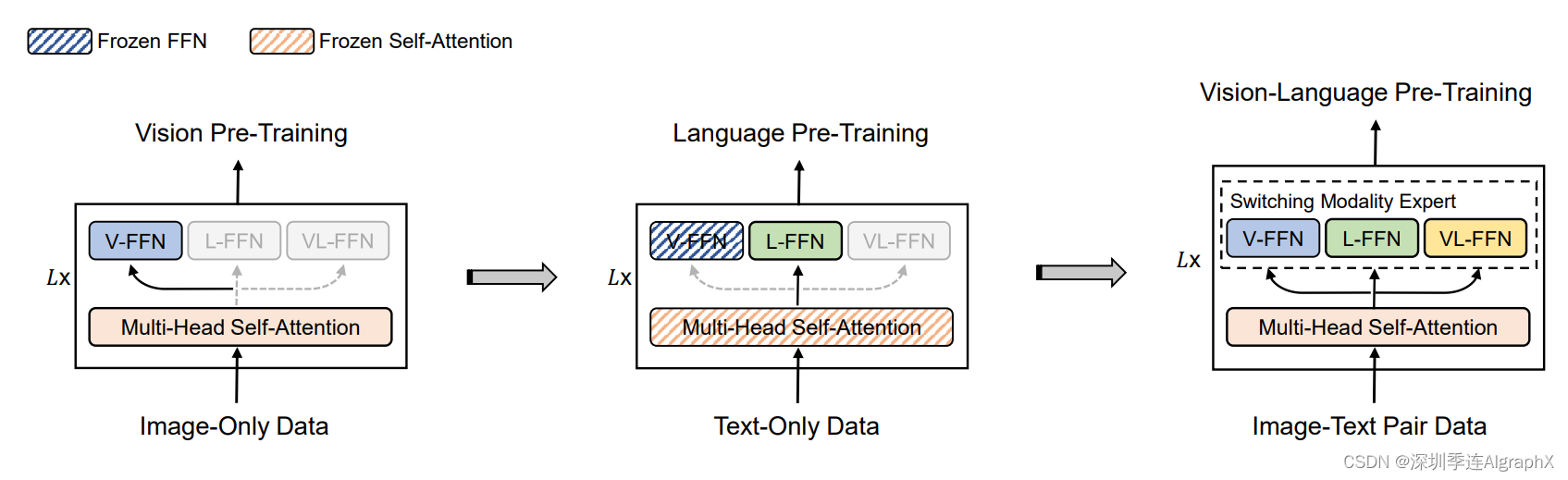
那我们看到在做第一阶段的,这个vision的时候,因为你是刚开始训练嘛,你肯定没有什么需要冻住的,因为所有的东西都是随机初始化的。那所以说,这12层的这个transformer block,也就是包括前面这个自注意力,和和后面的这个vision expert,都是打开训练的。但是,当你到第二阶段,去做这个文本的预训练的时候,我们会看到,这个vision,被冻住了,因为你现在是文本数据嘛,你不需要去训练那个vision,所以vision的那个FFN层,参数就固定下来了。我是要去训练这个language expert的。但是非常有意思的事儿,是他把这个self attention给冻住了,意思就是说,我完全拿一个,在视觉数据上,训练好的这么一个模型,在视觉token sequence上,训练好的一个自助力模型,我可以直接拿来,对这个文本数据进行建模。我都不需要fine tune,他这个self attention,就工作的很好,我就能让这个模型,一样能把这个完形填空做得很好。之前也有一些工作也证明可以这样,就是我现在language这上去训练,然后再在vision上冻住去做,好像结果不太好,但是,如果是先用vison训练,然后再在text上直接去用这个self attention,已经在很多工作里证明是有效的。
这个对我而言,很奇怪,也很有趣,如果对这个现象感兴趣的同学,也可以继续去深挖一下,看看是不是真的所有的modality,都能用同样的这个,而且是为什么。
那到了第三阶段,因为这时候做的就是我们想要的这个动作态了,所以说该打开的,就全打开了,不光是这个self attention,还是后面的这三个,就都打开去做。那这个,就是本文所讲的第二个contribution,分阶段的训练策略。
那讲完了方法部分,我们快速的看一下VLMo的这个实验结果。
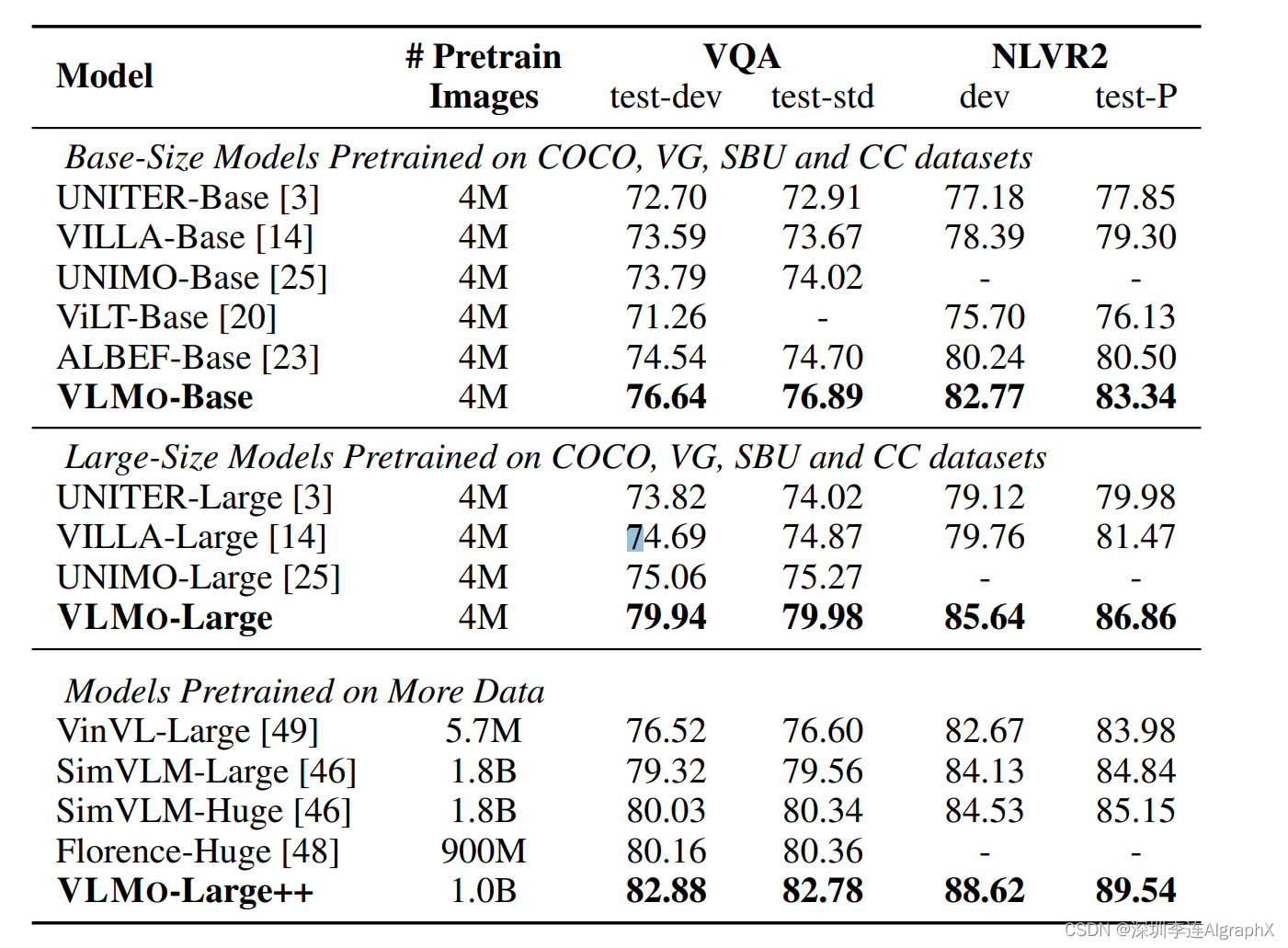
总之,还是非常有效的,他在4m上这个数据的表,就已经非常亮眼了,他跟ALBEF去做这种公对比的时候,是比ALBEF都要高的,要两到三个点,所以算是很大进步。然后,如果用了更大的模型,或者甚至在更大的数据集上去做预训练完之后,这个性能的提升,就更不用说了。
鉴于BEiT v3,也使用了VLMo这种模型结构,而且它又这么灵活。所以大家可以好好感受一下,如何用很小的改动,就是把一个FFN做成多个,但是就带来了这么巨大的提升,这肯定也是很多经验积累出来的。VLMo这篇论文,其实实验做的也是非常的详尽,他这个分阶段的预训练策略很有效,还有它这个模型,很灵活,所以它在这个单独的视觉数据集上,也取得了很好的效果。
还有去做这种图文检索的时候,也取得了很好的效果,和这个推理时间都很好。
我更想说一下的,是VLMo这篇论文的这个结语部分,作者说了很多,就是说在未来,我们会做很多,继续去提升这个VLMo的方式。作者团队,是真的做到了,而且一一都deliver。
那比如说,第一个最直白的,就是直接去scaling,就是把这个模型变大。这个,作者接下来的BEiT v3里就实现了,他就用了ViT Giant有1.9billion的参数。第二个,就是做更多的这个下游的这个vision language task,比如说其中,有一个更著名的这个image captioning,就是图像字幕。那做captioning,一般是需要一个这个transformer decoder,所以,我们这一期讲了这些和都不太适合去做,那在接下来,作者在这个VL-BEiT,BEiT v3里,都去做了这个尝试。那第三点,作者想说的就是说这个unimodality,能够帮助这个multi-modality,那同样的,Multi-modaality,也有可能能帮助这个unimodality。同样的,在这个BEiT v3的工作里,他把这个文本和这个图像的各个数据集,也全刷了一遍,效果都非常好。那最后,一个更宏观的目标,就是说我不光是想做这个vision language,我肯定有更多的模态,更多的这个应用场景,比如说speech,viedo或者structured knowledge。那其实者团队,也做了很多这方面的工作,比如说speech在这边,有WAVLM。在这个structured konwledge这边,就有Layout LM v1,v2,v3。还有,就是去支持general purpose这种多模态学习,也也是最近比较火,就是统一用这当文本当作一个interface。这样所有的任务,都可以通过一个prompt,然后去生成文本这种结构去实现,那作者团队这边,也出了一个MetaLM的工作。所以算是一步一步把他们之前提出的这个future work全都实现了,这个还是非常难能可贵的。
那这里我更想说的,其实就是做研究,是一点一点积累上来的.作者团队,做了这么多有影响力的工作,其实,也是一步一步迭代出来的,咱们来看看,在22年,这一系列的工作的发展历程。

那这个BEiT,在21年六份就出来了,然后接下来,在21年11份的时候,就出了VLMo这篇论文。
然后因为这个时候,图像也可以用mask modeling去做,文本也可以用mask modeling去做,所以很自然的到22年6月份的时候,作者团队就推出了VL-BEiT,就是同时用mask modeling去做vison language,然后接下来,又过了2个月,这个BEiT v2就出来了。那BEiT v2,其实是BEiT一个升级,还做的是这个视频dataset是不做multi-modality。那同样的月份22年8份,又出了BEiT v3,那BEiT v3,其实就是之前所有这些的一个集大成者,就是一个多模态网络,但是同时也做unimodality。
所以就是在这一步一步的积累过程之中,才能做出来这么多solid的工作。
那在多模态的下期串讲之中,主要就会讲一些最近的,基于这个encoder,decoder的工作来看一下多模态学习,以及它的发展又到了哪个阶段。
摘录
多模态论文串讲·上【论文精读·46】_哔哩哔哩_bilibili
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
https://arxiv.org/abs/2111.02358
)
![[软件工具]通用OCR识别文字识别中文识别服务程序可局域网访问](http://pic.xiahunao.cn/[软件工具]通用OCR识别文字识别中文识别服务程序可局域网访问)

——建立时间)


补题)


 抽象类篇)

![P1125 [NOIP2008 提高组] 笨小猴——C++](http://pic.xiahunao.cn/P1125 [NOIP2008 提高组] 笨小猴——C++)

 入门示例及通过CoreAPI访问与操作数据库)





