- Elasticsearch基础篇(七):分片大小修改和路由分配规则
- 1. 分片
- 1.1 主分片(Primary Shard)
- 1.2 副本分片(Replica Shard)
- 1.3 分片路由(Routing Shard)
- 2. 分片分配的基本策略
- 3. 分片写入验证
- 3.1 数据写入测试
- 3.2 路由机制
- 4. 修改分片数量
- 4.1 修改主分片数量
- 4.2 Reindex修改主分片的数量
- 4.3 修改副分片数量
Elasticsearch基础篇(七):分片大小修改和路由分配规则
1. 分片
在Elasticsearch中,分片是对索引数据的水平划分和分布。索引被分成多个分片,每个分片可以在集群的不同节点上存储。这种分片的设计提供了一种水平扩展的能力,允许将大量数据分布到多个节点上,从而提高性能和可伸缩性。每个分片就是一个Lucene的实例,具有完整的功能。
1.1 主分片(Primary Shard)
每个索引都被划分成若干个主分片,每个主分片都是一个独立的索引。主分片负责处理所有的读和写操作。主分片的数量在索引创建时确定,之后不能更改。
1.2 副本分片(Replica Shard)
为了提高系统的可用性和容错性,每个主分片都可以有零个或多个副本分片。副本分片是主分片的完整复制,位于不同的节点上。如果某个节点故障,系统仍然能够通过副本分片提供服务。副本的数量可以在索引运行时动态调整。
1.3 分片路由(Routing Shard)
数据被分配到特定的分片是通过分片路由机制实现的。默认情况下,Elasticsearch使用文档ID的哈希值进行路由,确保数据在不同主分片上均匀分布。开发者也可以自定义路由值。
2. 分片分配的基本策略
- ES使用数据分片(shard)来提高服务的可用性,将数据分散保存在不同的节点上以降低当单个节点发生故障时对数据完整性的影响,同时使用副本(repiica)来保证数据的完整性。关于分片的默认分配策略,在7.x之前,默认5个primary shard,每个primary shard默认分配一个replica,即5主1副,而7.x之后,默认1主1副
- ES在分配单个索引的分片时会将每个分片尽可能分配到更多的节点上。但是,实际情况取决于集群拥有的分片和索引的数量以及它们的大小,不一定总是能均匀地分布。
- Paimary只能在索引创建时配置数量,而replica可以在任何时间分配,并且primary支持读和写操作,而replica只支持客户端的读取操作,数据由es自动管理,从primary同步。
- ES不允许Primary和它的Replica放在同一个节点中,并且同一个节点不接受完全相同的两个Replica
3. 分片写入验证
es集群,ip: 192.168.0.156,节点端口:9201,9202,9203
设置索引分片数量
http://192.168.0.156:9201/test_index/
{"settings": {"index": {"number_of_shards": "3","number_of_replicas": "2"}}
}
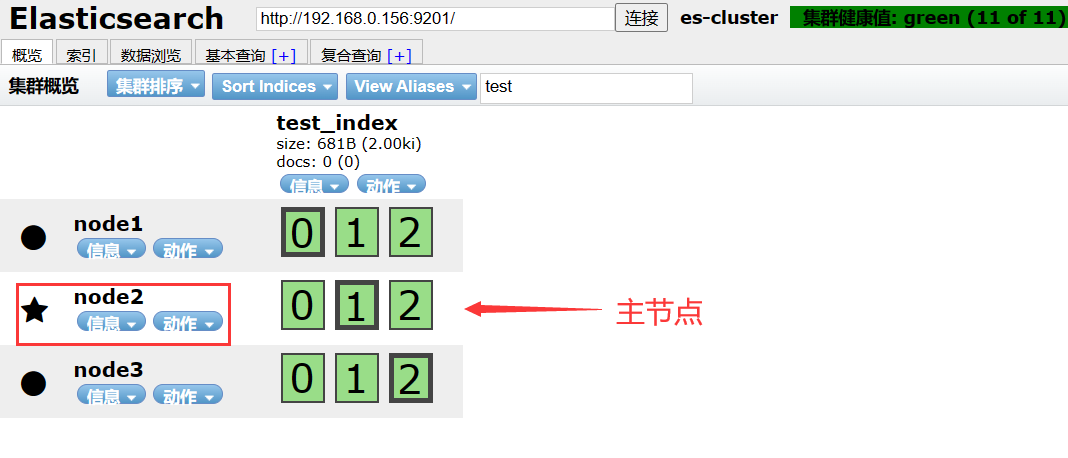
包含三个节点(node1、node2、node3)的ES集群,每个主分片有3个主分片和2个副分片,分片分布如下:
- Node1: 主分片0、副本1、副本2
- Node2: 主分片1、副本0、副本2
- Node3: 主分片2、副本0、副本1
#查看所有索引的分片信息
http://192.168.0.156:9201/_cat/indices?vhealth status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open test_index sX7MP6snQ7m3XjX5LXfM3w 3 2 0 0 1.9kb 681b
参数说明:
- index: 索引名称
- docs.count:文档总数
- docs.deleted:已删除文档数
- store.size: 存储的总容量
- pri.store.size:主分片的存储总容量
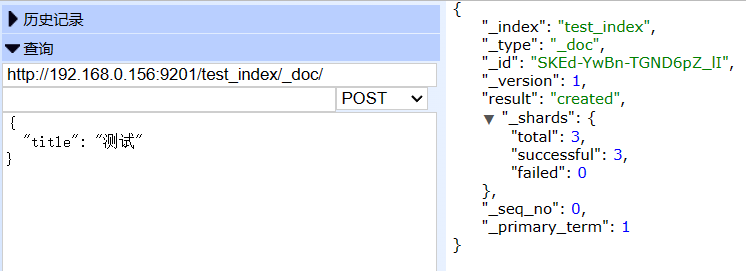
3.1 数据写入测试
新增一条测试数据
# 查看数据写入分片信息
http://192.168.0.156:9201/_cat/shards/test_index?v
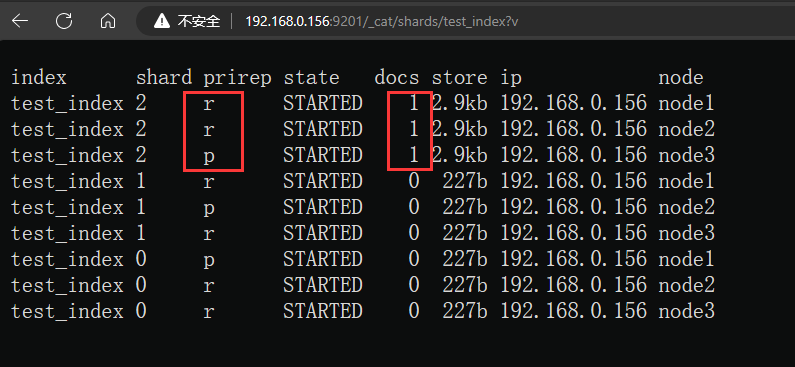
当新增一条数据时,该数据将被写入到其中一个主分片,并且它的两个副本被分配到其他两个节点上。这样设计可以提高系统的可用性和容错性,因为数据的多个副本分布在不同的节点上,即使某个节点发生故障,系统仍然可以继续工作。总的来说,具体的分配取决于Elasticsearch的集群配置和负载均衡策略。系统会尽量保证数据在不同节点上的均匀分布,以提高性能和可靠性。
3.2 路由机制
往索引中增加100条数据,文档分布如下:三个主分片的文档数量正好为100,随着文档数量的增加,三个主分片的数量会越来越均衡
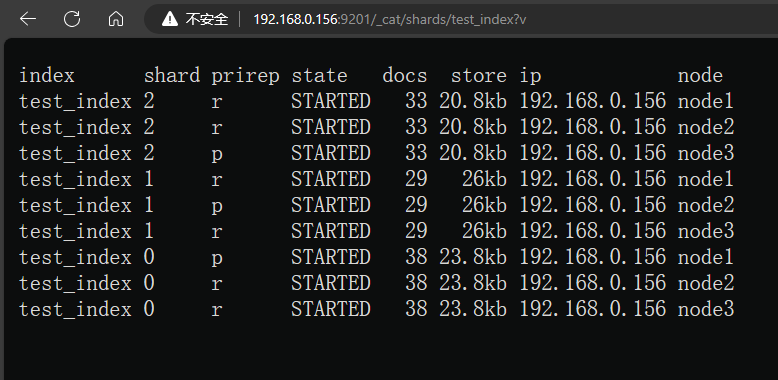
es 中的路由机制是通过哈希算法,将具有相同哈希值的文档放到一个主分片中,分片位置的计算方式如下:
shard=hash(routing) % number_of_primary_shards# 路由公式参数说明:
shard_num:最终选择分片序号
routing:路由ID,不指定则为文档ID
number_of_primary_shards:主分片数量
routing 可以是一个任意字符串,es 默认是将文档的 id 作为 routing 值,通过哈希函数根据 routing 生成一个数字,然后将该数字和分片数取余,取余的结果就是分片的位置。
默认的这种路由模式,最大的优势在于负载均衡,这种方式可以保证数据平均分配在不同的分片上。劣势在查询时候无法确定文档的位置,此时 会将请求广播到所有的分片上去执行
4. 修改分片数量
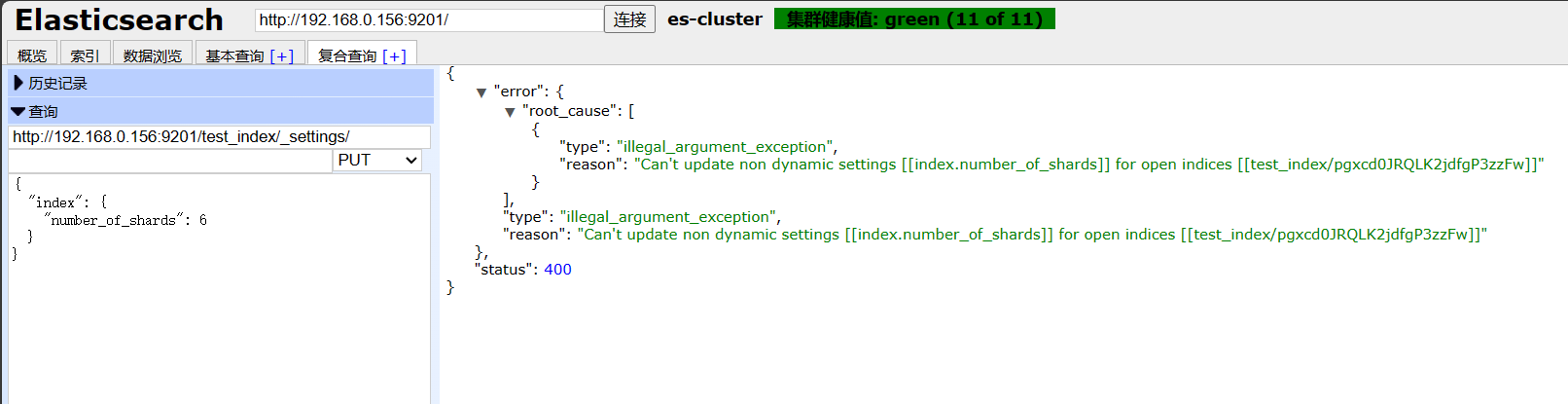
4.1 修改主分片数量
PUT test_index/_settings
{"index" : {"number_of_shards" : 6}
}
报错信息如下:证明索引创建后无法修改分片数
4.2 Reindex修改主分片的数量
[Reindex API | Elasticsearch Guide 8.11] | Elastic
在Elasticsearch中,一旦索引创建时确定了主分片的数量,就不能直接修改。主分片的数量是索引创建时固定的,因为这个值与数据的分布和索引结构有关。要修改主分片的数量,需要采取以下步骤:
-
创建新索引: 创建一个新的索引,设置新的主分片数量。这个步骤需要提前计划,因为主分片数量一旦确定,就不能更改。
-
重新索引(Reindex): 使用Elasticsearch的Reindex API将旧索引中的数据重新索引到新创建的索引中。这一步会消耗一些计算和存储资源,因此在生产环境中可能需要谨慎操作。
-
切换到新索引: 在完成重新索引后,将应用中的写操作切换到新的索引,确保新数据写入新的索引。
-
删除旧索引(可选): 如果确认新索引运行正常且数据完整,可以选择删除旧索引释放资源。
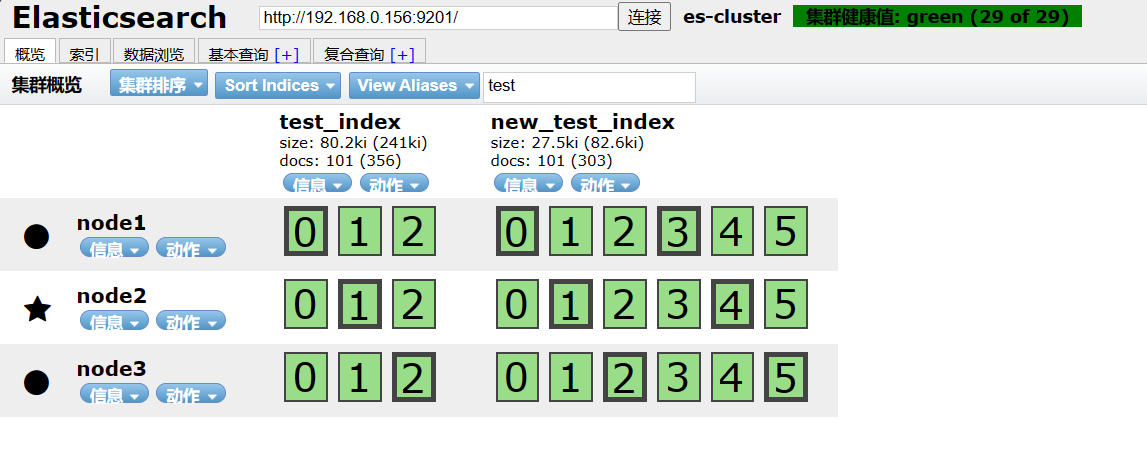
通过创建新索引来修改主分片的数量示例:
# 创建新索引(示例中主分片数量为6)
PUT new_test_index
{"settings": {"index": {"number_of_shards": "6","number_of_replicas": "2"}}
}# 使用Reindex API将旧索引数据重新索引到新索引
POST _reindex
{"source": {"index": "test_index"},"dest": {"index": "new_test_index"}
}# 切换应用中的写操作到新索引# 可选:删除旧索引
DELETE /old_index
4.3 修改副分片数量
PUT test_index/_settings
{"index" : {"number_of_replicas" : 1}
}
)

| 尾页栏目均衡(Last Page Column Equalization))

)










模式)



