文章目录
- 前言
- 一、爬虫的分类
- 二、跳转页面的爬取
- 三、网页去重
- 四、综合案例
- 1. 案例三
上篇:Java-网络爬虫(二)
前言
上篇文章介绍了 webMagic,通过一个简单的入门案例,对 webMagic 的核心对象和四大组件都做了简要的说明,以下内容则是继续对 webMagic 的讲解
一、爬虫的分类
爬虫按照系统结构和实现技术,大致可以分为以下几种类型:
通用网络爬虫(General Purpose Web Crawler)
也被称为全网爬虫,这种爬虫的爬取目标资源在全互联网中,爬取目标数据巨大。它主要用于为大型搜索引擎和门户网站采集数据。这类爬虫对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求相对较低,同时由于待刷新的页面比较多,通常采用并行工作方式,但需要较长时间才能刷新一次页面,简单的说就是互联网上抓取所有数据。通用网络爬虫的基本构成包括初始 URL 集合、URL 队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等。
聚焦网络爬虫(Focused Web Crawler)
也被称为主题网络爬虫,这种爬虫选择性地爬取那些与预先定义好的主题相关的页面。聚焦网络爬虫的目标是只抓取互联网上某一种数据。和通用网络爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于少量而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
量式网络爬虫(Incremental Web Crawler)
这种爬虫会不断爬取数据,但仅爬取新产生的或者已经发生变化的网页,它能够在一定程度上保证所爬行的页面是尽可能新的页面。和周期性爬行和刷新页面的网络爬虫相比,增量式爬虫只会在需要的时候爬行新产生或发生更新的页面,并不重新下载没有发生变化的页面,可有效减少数据下载量,及时更新已爬行的网页,减小时间和空间上的耗费,但是增加了爬行算法的复杂度和实现难度。
深层网络爬虫(Deep Web Crawler)
也被称为深网爬虫,这种爬虫主要抓取隐藏在搜索表单后的、不能通过静态链接获取的网页。这些页面只有当用户提交一些关键词才能获得。
二、跳转页面的爬取
在很多情况下,当我们爬取一个页面的信息时,要通过一些链接进入到其它的页面,进而继续爬取更多的信息
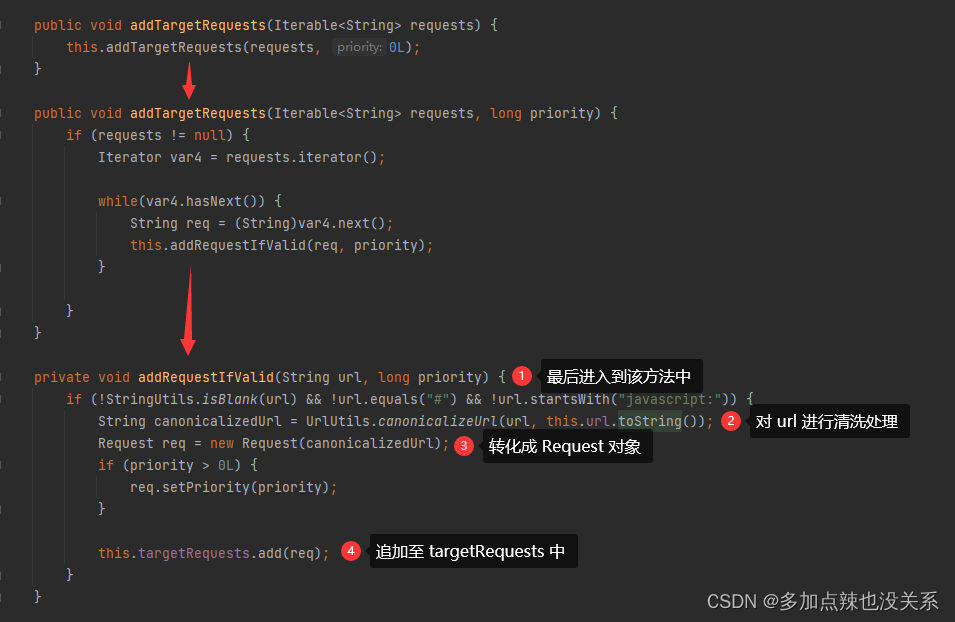
从上文介绍 webMagic 的原理中可以知道,只需要将待处理的 Request 放入 Scheduler 中就行了,Spider 会从 Scheduler 拉取 Requset 进行抓取,可以通过 page.addTargetRequests(Iterable<String> requests) 实现这一步,代码如下:
@Overridepublic void process(Page page) {// 解析处理...// 待抓取的 URLList<String> waitUrls = new ArrayList<>();waitUrls.add("url_1");waitUrls.add("url_2");waitUrls.add("url_3");// 将待抓取的 URL 追加到 targetRequests 中page.addTargetRequests(waitUrls);// 持久化处理...}
同样我们可以去追寻源码,进入到 addTargetRequests(Iterable<String> requests) 方法中:
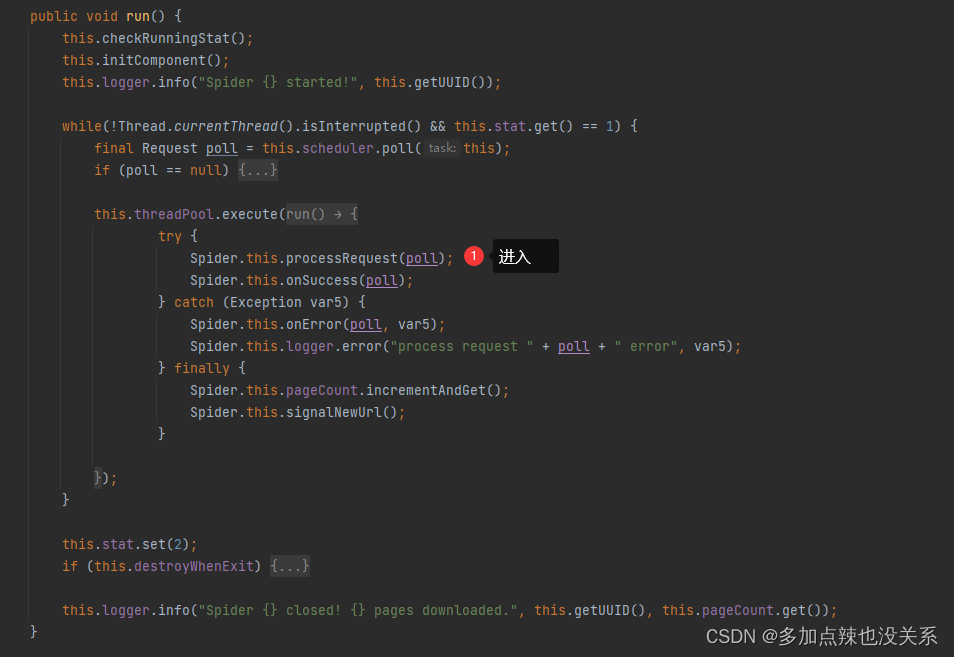
好像也没有看到将 Request 放入到 Scheduler 中,再看回 spider.run() 方法:
进入到 processRequest(Request request) 方法:
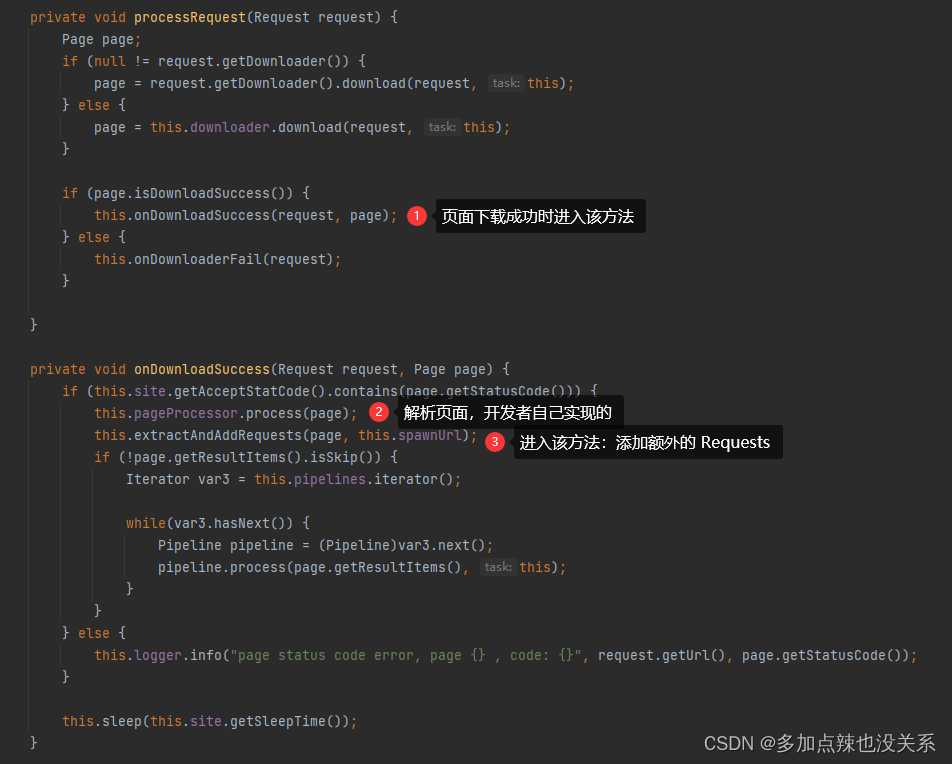
从上述源码可知,在运行完 process() 方法后会进入到一个 extractAndAddRequests() 方法来添加一些额外的 Requests,而这些 Requests 其实就是前面通过 page.addTargetRequests() 添加进去的,不妨再看看 extractAndAddRequests() 这个方法
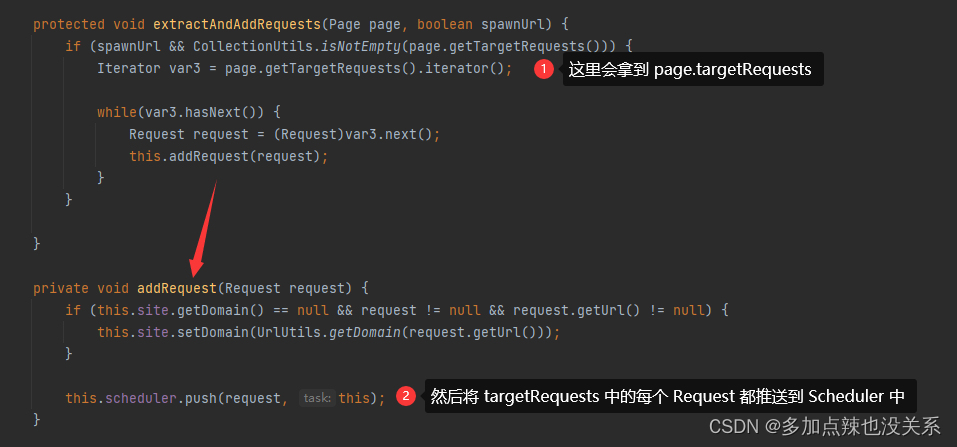
到这里就可以看到通过 page.addTargetRequests() 这个方法确实会将待处理的 URL 全部推送至 Scheduler 中
三、网页去重
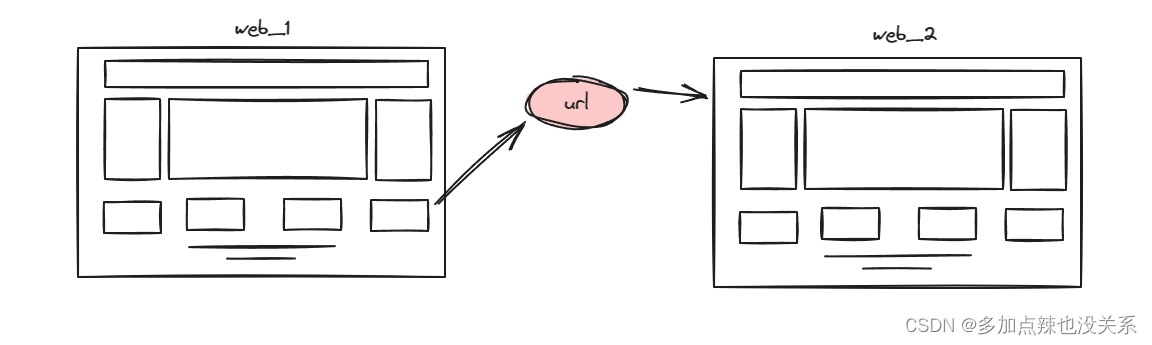
倘若出现了这么一种场景,在页面 web_1 中有跳转到页面 web_2 的 URL,而在网页 web_2 中也存在着跳转到网页 web_1 的 URL
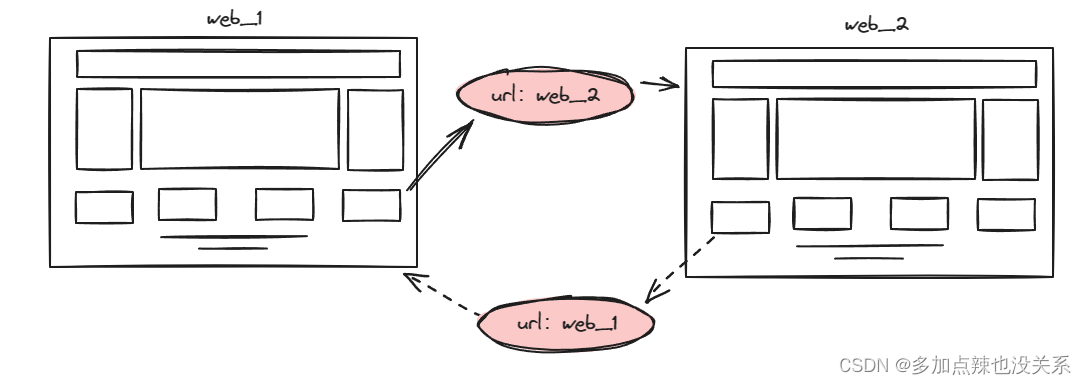
那么就会出现这样一种现象,就是 web_1 和 web_2 这两个页面会被无休止的重复解析,这显然是不合理的,所以我们需要记录下已被解析过的页面,让其不能重复解析,这就是页面的去重
对于页面的去重,可以采取很多种方式,这里我就列举三种常用的方法:
- HashSet 去重:使用 Java 中的 HashSet 不能重复的特点进行去重
- 优点:容易理解,使用方便
- 缺点:占用内存大,性能较低
- Redis 去重:使用 redis 的 set 进行去重
- 优点:速度快,而且去重不会占用爬虫服务器的资源,可以处理更大数据量的数据爬取
- 缺点:需要准备 redis 服务器,成本增加
- 布隆过滤器(BloomFilter):使用布隆过滤器的特性进行去重
- 优点:相比于 HashSet 去重更快,更加节省内存,也适用于大量数据的去重
- 缺点:有误判的可能,没有重复可能会被判断为重复,但是重复数据一定会判定重复
关于布隆过滤器的原理可参见博客:Java-布隆过滤器的实现
实际上 webbMagic 提供的 Scheduler 组件已经帮我们解决了上述问题,Scheduler 不仅会将待抓取的 URL 放到队列中进行管理,还会对比已抓取的 URL 进行去重
webMagic 内置了几个常用的 Scheduler,如果只是本地执行规模比较小的爬虫,基本无需定制 Scheduler
| 类 | 说明 | 备注 |
|---|---|---|
| DuplicateRemovedScheduler | 抽象基类,提供了一些模板方法 | 继承它可以实现自己的功能 |
| QueueScheduler | 使用内存队列保存待抓取的 URL | 如果数据量比较庞大的话,可能会造成内存溢出 |
| PriorityScheduler | 使用带有优先级的内存队列保存待抓取的 URL | 耗费内存较 QueueScheduler 更大,但是当设置了 request.priority 之后,只能使用 PriorityScheduler 才可使优先级生效 |
| FileCacheQueueScheduler | webMagic-extension 提供,使用文件保存抓取 URL,可以在关闭程序并下次启动时,从之前抓取到的 URL 继续抓取 | 需要指定文件存放路径,会建立 urls.txt 和 cursor.txt 两个文件 |
| RedisScheduler | webMagic-extension 提供,使用 redis 保存抓取队列,可进行多台机器同时合作抓取 | 需要安装并启动 redis |
| RedisPriorityScheduler | webMagic-extension 提供,使用 redis 保存抓取队列,可设置优先级 | 需要安装并启动 redis |
去重部分被单独抽象成了一个接口 — DuplicateRemover
public interface DuplicateRemover {boolean isDuplicate(Request var1, Task var2);void resetDuplicateCheck(Task var1);int getTotalRequestsCount(Task var1);
}
从而可以为同一个 Scheduler 选择不同的去重方式,以适配不同的需要,目前提供了两种去重方式:
| 类 | 说明 |
|---|---|
| HashSetDuplicateRemover | 使用 HashSet 来进行去重,占用内存较大 |
| BloomFilterDuplicateRemover | webMagic-extension 提供,使用 BloomFilter 来进行去重,占用内存较小,但是可能漏抓页面 |
除了 RedisScheduler 和 RedisPriorityScheduler 是使用 redis 的 set 进行去重,其它的 Scheduler 默认使用 HashSetDuplicateRemover 进行去重的
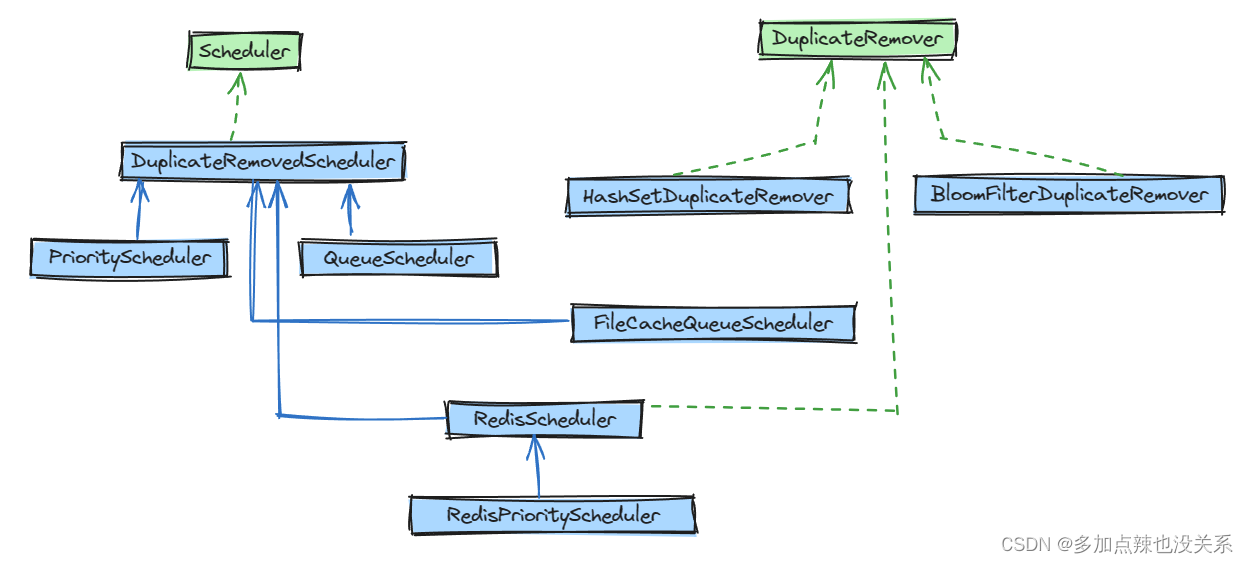
我们可以通过类图类验证,DuplicateRemovedScheduler 是其它的 Scheduler 的基类,在 DuplicateRemovedScheduler 中使用的就是 HashSetDuplicateRemover,所以其它的 Scheduler 也继承了这一点

但是 RedisScheduler 实现了 DuplicateRemover 接口,重写了其中的去重逻辑,使用 set 来存储 url,而 RedisPriorityScheduler 又继承了 RedisScheduler,所以这两个是使用了 redis 的 set 进行去重的
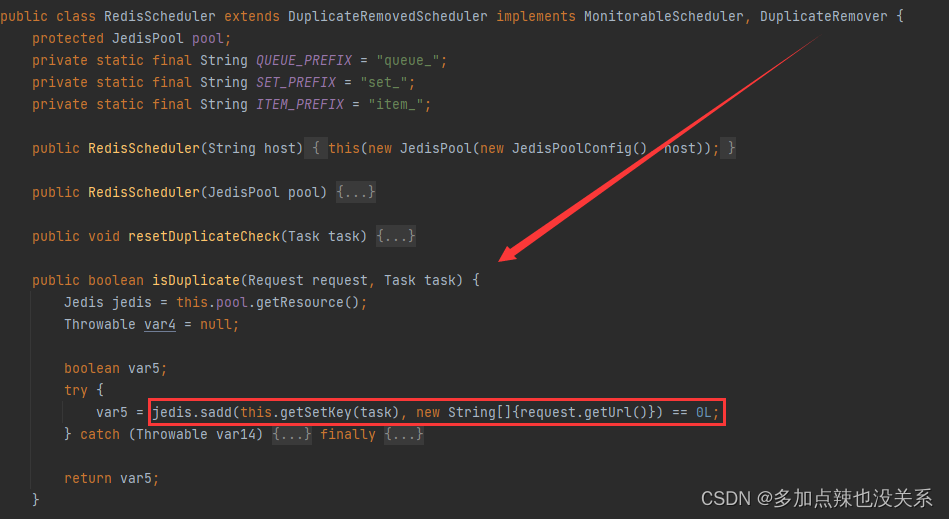
如果需要使用到布隆过滤器进行去重,则需要进行设置
在设置之前还需要先添加 guava 依赖,因为 webMagic-extension 中使用的布隆过滤器是 guava 中的 BloomFilter
maven 导入 guava 依赖
<!-- guava -->
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>33.0.0-jre</version>
</dependency>
代码设置 Scheduler 使用布隆过滤器
// 创建 schedulerQueueScheduler scheduler = new QueueScheduler();// 设置 scheduler 使用布隆过滤器,预计存放一百万条数据scheduler.setDuplicateRemover(new BloomFilterDuplicateRemover(1000000));// Spider 设置 schedulerspider.setScheduler(scheduler);
四、综合案例
1. 案例三
下载食品营养成分查询平台的所有页面持久化到本地磁盘中
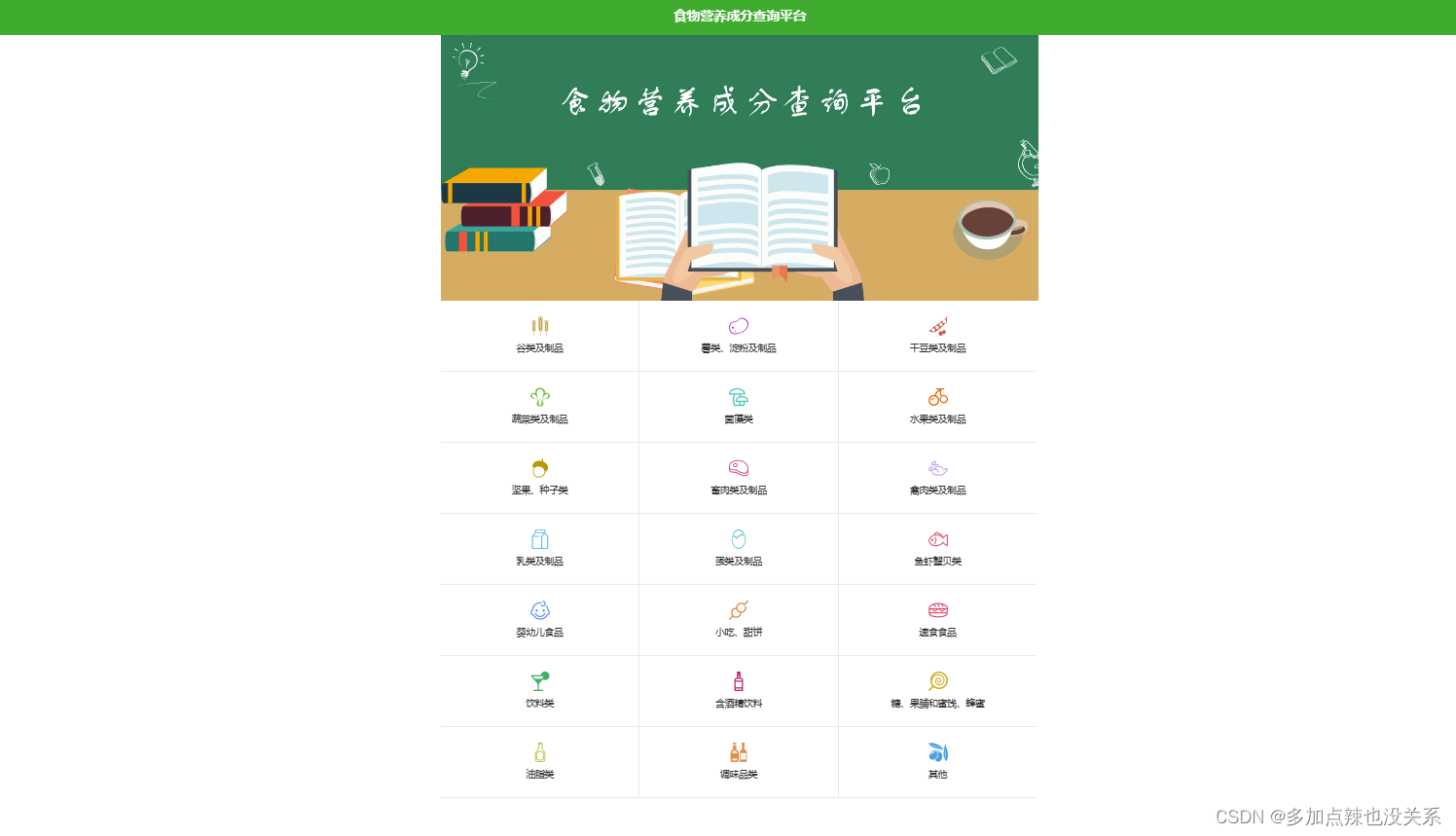
分析:
- ① 如果需要爬到该网站的所有页面,就需要将每个页面的超链接放入待处理
URL中 - ② 对网页进行去重处理,可以使用布隆过滤器
- ③ 要将网页内容持久化到本地磁盘可以使用
FilePipeline
代码如下:
import com.google.common.base.Charsets;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.BloomFilterDuplicateRemover;
import us.codecraft.webmagic.scheduler.QueueScheduler;
import us.codecraft.webmagic.selector.Html;
import java.util.Collections;
import java.util.List;public class WebMagicDemo01 implements PageProcessor {@Overridepublic void process(Page page) {// 获取当前页面的 Html 对象Html html = page.getHtml();// 获取页面上所有的链接List<String> links = html.links().all();// 放入待处理 url 中page.addTargetRequests(links);// 将 html 内容放置 resultItems 中page.putField("html", html.get());}@Overridepublic Site getSite() {// 返回自定义 Sitereturn Site.me()// 设置字符集.setCharset(Charsets.UTF_8.name())// 设置超时时间:5000(单位毫秒).setTimeOut(5000)// 设置重试间隔时间:3000(单位毫秒).setRetrySleepTime(3000)// 设置重试次数:5.setRetryTimes(5);}public static void main(String[] args) {// 创建 spiderSpider spider = Spider.create(new WebMagicDemo01());// 创建 schedulerQueueScheduler scheduler = new QueueScheduler();// 设置 scheduler 使用布隆过滤器,预计存放一百万条数据scheduler.setDuplicateRemover(new BloomFilterDuplicateRemover(1000000));// Spider 设置 schedulerspider.setScheduler(scheduler);// 创建 filePipelineFilePipeline filePipeline = new FilePipeline();// 设置存放路径filePipeline.setPath("D:\\web-magic\\download-page");// Spider 设置 pipelinespider.setPipelines(Collections.singletonList(filePipeline));// 设置初始 URLspider.addUrl("http://yycx.yybq.net/");// 开启 2 个线程spider.thread(2);// 异步爬取spider.runAsync();}
}可以看到指定文件夹下就开始下载这个网站的页面文件了
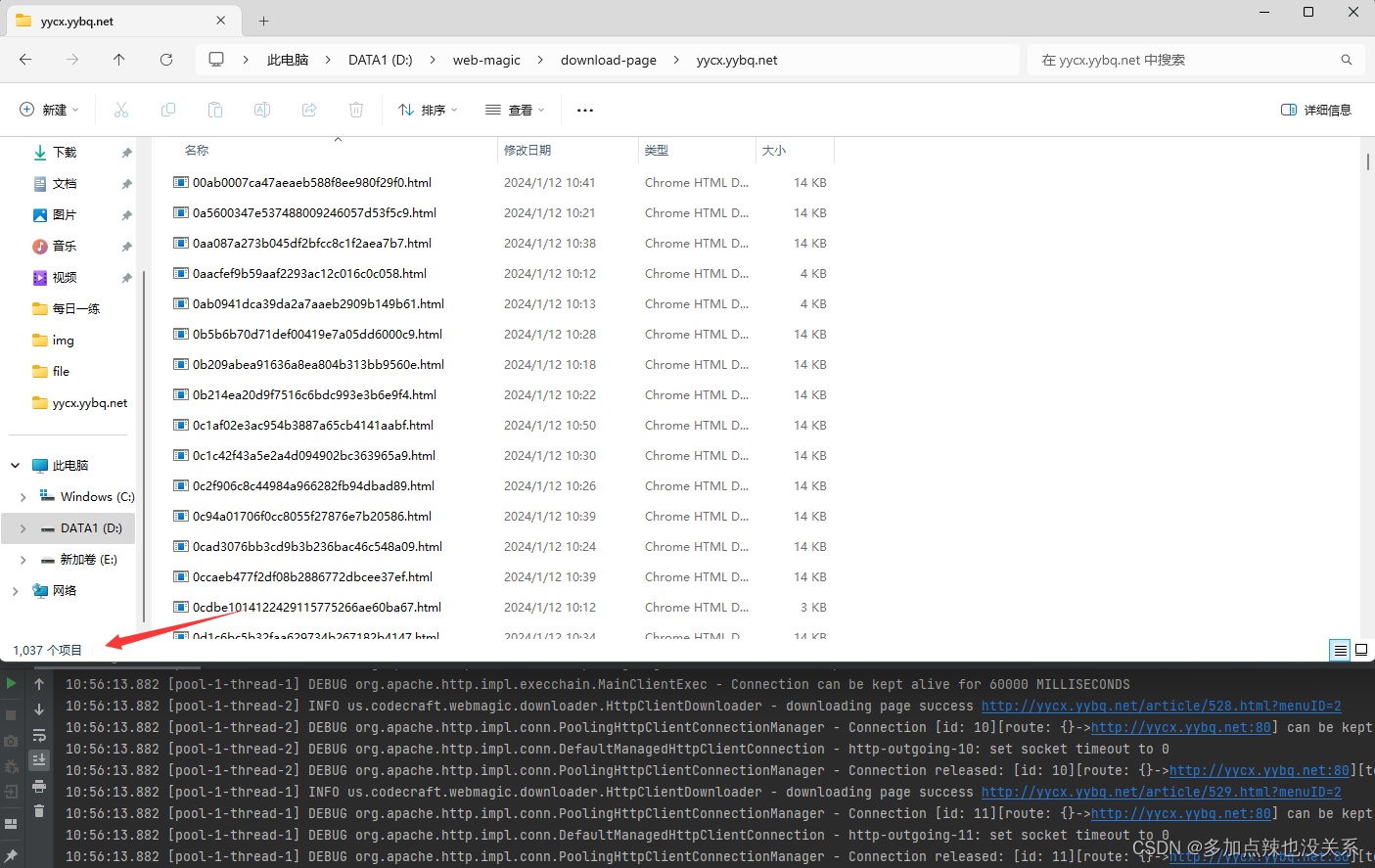
将下载的 html 文件内容和网页源码对比,可以看见基本上是一致的,不过多了一点内容
在游览器上打开下载的 html 文件
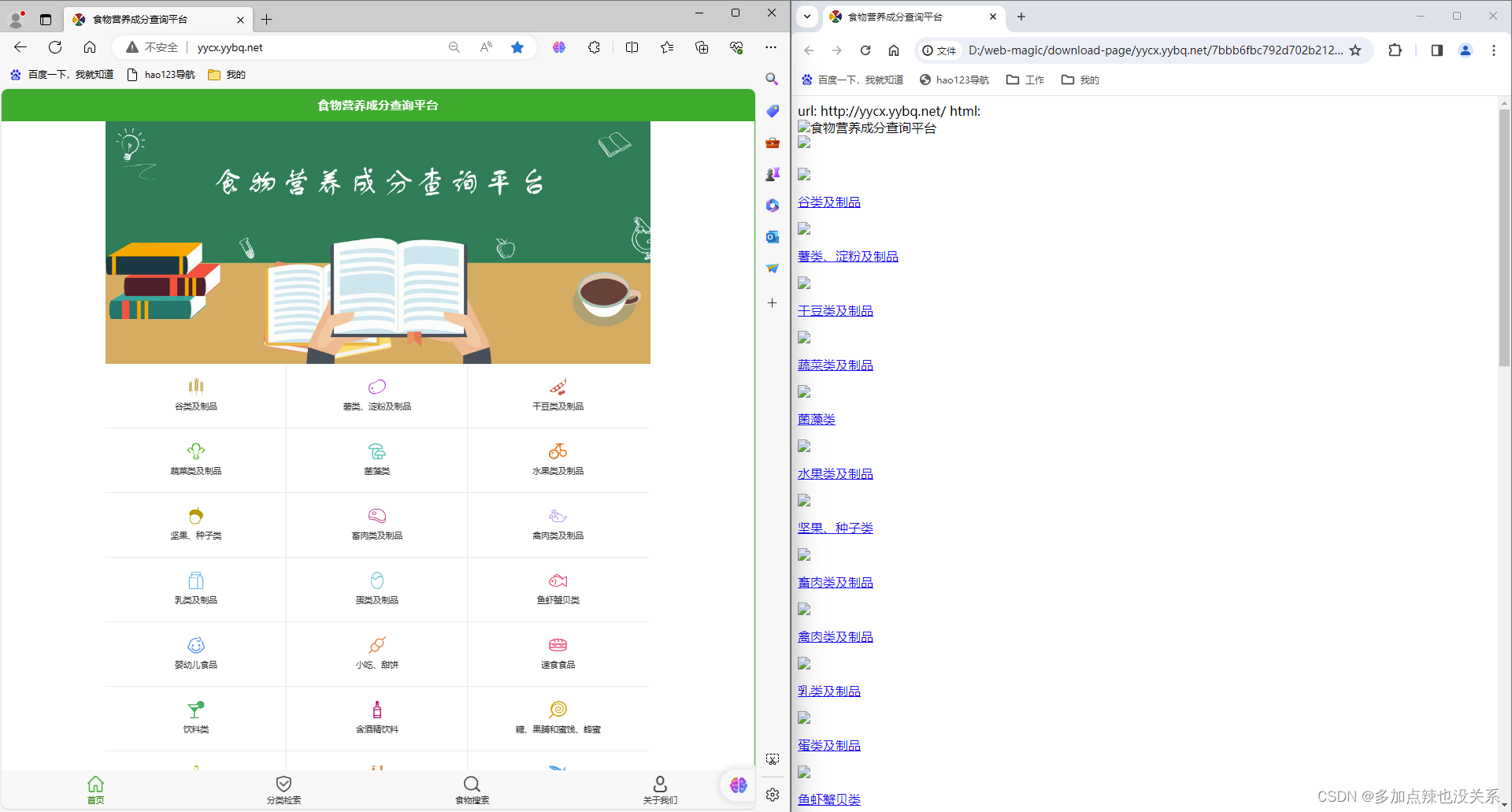
可以看到虽然下载的 html 文件中的内容和网页源代码几乎一样,但是却没有样式,图片也显示不了,链接跳转过去也是 404,原因是在源码中有关资源的路径使用的都是相对路径,而本地没有这些资源当然访问不了
如果想要解决上述问题:
- ① 去除多余的内容
- ② 游览器打开下载的
html文件,资源部分未能加载
解决方案:
- 问题 ①:重写
FilePipeline去除打印多余部分的代码 - 问题 ②:将有关资源的路径前全部加上起始网页地址
改进后代码:
import com.google.common.base.Charsets;
import org.apache.commons.codec.digest.DigestUtils;
import org.apache.commons.lang3.StringUtils;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import us.codecraft.webmagic.*;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.scheduler.BloomFilterDuplicateRemover;
import us.codecraft.webmagic.scheduler.QueueScheduler;
import us.codecraft.webmagic.selector.Html;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
import java.util.Map;public class WebMagicDemo01 implements PageProcessor {@Overridepublic void process(Page page) {// 获取当前页面的 Html 对象Html html = page.getHtml();// 获取页面上所有的链接List<String> links = html.links().all();// 放入待处理 url 中page.addTargetRequests(links);// 获取所有的 src 属性Document document = html.getDocument();Elements srcElements = document.select("script,img");for (Element element : srcElements) {if (StringUtils.isNotBlank(element.baseUri())) {String src = element.attr("abs:src");// 重新设置属性element.attr("src", src);}}// 获取所有的标签属性Elements aElements = document.select("a,link");for (Element element : aElements) {if (StringUtils.isNotBlank(element.baseUri())) {String href = element.attr("abs:href");// 重新设置属性element.attr("href", href);}}// 将 html 内容放置 resultItems 中page.putField("html", html.get());}@Overridepublic Site getSite() {// 返回自定义 Sitereturn Site.me()// 设置字符集.setCharset(Charsets.UTF_8.name())// 设置超时时间:5000(单位毫秒).setTimeOut(5000)// 设置重试间隔时间:3000(单位毫秒).setRetrySleepTime(3000)// 设置重试次数:5.setRetryTimes(5);}public static void main(String[] args) {// 创建 spiderSpider spider = Spider.create(new WebMagicDemo01());// 创建 schedulerQueueScheduler scheduler = new QueueScheduler();// 设置 scheduler 使用布隆过滤器,预计存放一百万条数据scheduler.setDuplicateRemover(new BloomFilterDuplicateRemover(1000000));// Spider 设置 schedulerspider.setScheduler(scheduler);// 创建 filePipelineFilePipeline filePipeline = new MyFilePipeline();// 设置存放路径filePipeline.setPath("D:\\web-magic\\download-page");// Spider 设置 pipelinespider.setPipelines(Collections.singletonList(filePipeline));// 设置初始 URLspider.addUrl("http://yycx.yybq.net/");// 开启 2 个线程spider.thread(2);// 异步爬取spider.runAsync();}
}/*** 继承 FilePipeline*/
class MyFilePipeline extends FilePipeline {/*** 重写 FilePipeline 中的 process 方法* 去除打印多余部分的代码*/@SuppressWarnings("all")public void process(ResultItems resultItems, Task task) {String path = this.path + PATH_SEPERATOR + task.getUUID() + PATH_SEPERATOR;try {PrintWriter printWriter = new PrintWriter(new OutputStreamWriter(new FileOutputStream(this.getFile(path + DigestUtils.md5Hex(resultItems.getRequest().getUrl()) + ".html")), "UTF-8"));Iterator var5 = resultItems.getAll().entrySet().iterator();while(true) {while(var5.hasNext()) {Map.Entry<String, Object> entry = (Map.Entry)var5.next();if (entry.getValue() instanceof Iterable) {Iterable value = (Iterable)entry.getValue();Iterator var8 = value.iterator();while(var8.hasNext()) {Object o = var8.next();printWriter.println(o);}} else {printWriter.println((String)entry.getValue());}}printWriter.close();break;}} catch (IOException var10) {var10.printStackTrace();}}
}
再使用游览器打开新下载好的 html 文件就会能看到,其样式也官方网站的效果一样了
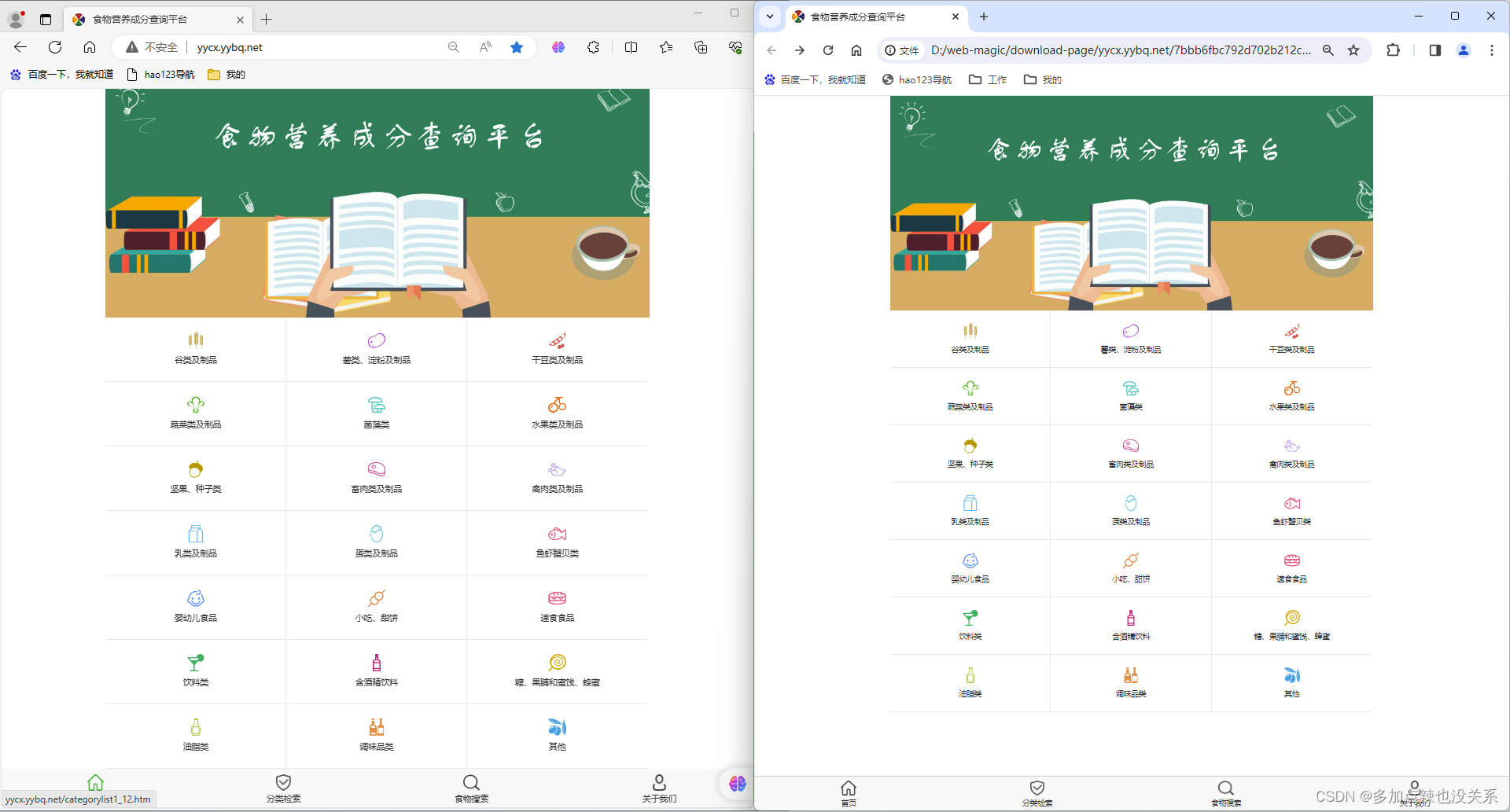
PS:以上案例只做学习爬虫使用,切勿恶意攻击他人网站
上篇:Java-网络爬虫(二)


)
















——Linux下Qt15.5.2配置Android)