题目:
我们有 n 种不同的贴纸。每个贴纸上都有一个小写的英文单词。
您想要拼写出给定的字符串 target ,方法是从收集的贴纸中切割单个字母并重新排列它们。如果你愿意,你可以多次使用每个贴纸,每个贴纸的数量是无限的。
返回你需要拼出 target 的最小贴纸数量。如果任务不可能,则返回 -1 。
注意:在所有的测试用例中,所有的单词都是从 1000 个最常见的美国英语单词中随机选择的,并且 target 被选择为两个随机单词的连接。
题解:
示例 1:
输入: stickers = ["with","example","science"], target = "thehat" 输出:3 解释: 我们可以使用 2 个 "with" 贴纸,和 1 个 "example" 贴纸。 把贴纸上的字母剪下来并重新排列后,就可以形成目标 “thehat“ 了。 此外,这是形成目标字符串所需的最小贴纸数量。
示例 2:
输入:stickers = ["notice","possible"], target = "basicbasic" 输出:-1 解释:我们不能通过剪切给定贴纸的字母来形成目标“basicbasic”。
分析:
1. 上面的两个式例正好都是前面两个符合条件的单词,如果符合条件的单词中间间隔比较大,该如何去处理?我个人觉得,肯定是需要遍历stickers数组的,否则无法判定那个是最优解。
2. 假设数组为 {abc, ab, bc, b, c} 而 target= abcabc. 那么遍历数组第一个元素拼出了abc, 此时target=abc; 第一个元素处理完以后,应该再次使用数组的第一个元素来拼词才更合理。题目也说了,张数无限。 否则的话至少需要3张才能拼出原始的target=abcabc. 而使用数组第一个元素abc只需要2张。此处,就要考虑使用递归了
3. 如果 假设1 和 假设2 都成立,那么也就是说根据abc拼了2次,存在重复消费abc的情况,是不是需要尝试添加缓存?
4. 因为贴纸是可以剪碎掉的,哪怕第一个元素是adqbec也是可以的。因为它还是包含abc子元素的。如何去统计abc子元素与target存在共同子序列,而且是不分先后顺序的。样本模型肯定是不可以的,它强调可以删减、但是不可以改变元素顺序。而此题是可以剪碎,完全打乱的。只能先去尝试写递归
5. 根据业务去分析,随便假设一个稍微简单的数组和target,满足条件即可。从简单到复杂,如果你随便假设测试数据都成立,那大概率就是成立的。
假设,数组为 {aa, b, bc}, target为aabc. 目测就是2张可以拼词完成 :

递归代码:
package code03.动态规划_07.lesson5;/*** 力扣691 : 贴纸拼词* https://leetcode.cn/problems/stickers-to-spell-word/description/**/
public class Stickers_01 {public int minStickers(String[] stickers, String target){//边界值if (stickers == null|| stickers.length == 0|| target == null|| target.isEmpty()) {return -1;}int ans = process (stickers, target);return ans == Integer.MAX_VALUE ? -1 : ans;}public int process (String[] stickers, String target){//如果target为空,说明在上一轮已经拼接完毕if (target.isEmpty()) {return 0;}//每一轮递归的最终返回值int ans = Integer.MAX_VALUE;//讨论每一个单词是否能够参与target的拼接for (String word : stickers) {//返回target拼词以后剩余字符串String res = splice(word, target);//如果res与target长度相等,说明word并没有参与进拼词过程if (res.length() != target.length()) {//最少贴纸数,每一轮递归都要取最小值ans = Math.min(ans, process (stickers, res));}}//如果ans不是无效值,说明此轮递归参与到拼词过程中。张数对应的要增加一次return ans != Integer.MAX_VALUE ? ans + 1 : ans;}public String splice(String s, String target){char[] ss = s.toCharArray();char[] tt = target.toCharArray();//26个小写字母,题目给定的int[] count = new int[26];//target字符串词频统计for (char tChar : tt) {count[tChar - 'a']++;}//根据当前单词到target中去减少对应的字符出现次数for(char sChar : ss) {count[sChar - 'a']--;}StringBuffer sb = new StringBuffer();//统计target还剩下哪些字符,并且把这些字符拼成字符串for (int i = 0; i < 26; i++) {//count[i]对应出现的次数,而 i 才是对应的字符if (count[i] > 0) {for (int times = 0; times < count[i]; times++) {sb.append((char)(i + 'a'));}}}return sb.toString();}public static void main(String[] args) {Stickers_01 s = new Stickers_01();String[] ss = {"aa", "b", "bc"};String target = "aabc";System.out.println(s.minStickers(ss, target));}
}
本地测试是ok的,但是到力扣上测试,发现直接超时了:
好消息是测试了30多个例子没有报错。既然超时,说明执行时间满,代码的时间复杂度有问题。那就进尝试优化,还是看图:
1. 最后一列,aa不参与返回max出现了很多次。而aa参与拼词的情况下也出现了很多次,说明存在重复消费的代码。
2. 遍历aa的时候,可以找到 bc。 这是最优解; 而遍历到bc的时候,可以找到aa, 这也是最优解。
因此,加缓存(记忆化搜索),势在必行。
递归 + 记忆化搜索:
package code03.动态规划_07.lesson5;import java.util.HashMap;/*** 力扣691 : 贴纸拼词* https://leetcode.cn/problems/stickers-to-spell-word/description/**/
public class Stickers_01_opt {public int minStickers(String[] stickers, String target){//边界值if (stickers == null|| stickers.length == 0|| target == null|| target.isEmpty()) {return -1;}HashMap<String, Integer> map = new HashMap<>();//优化之前,target为空直接返回0. 因此,此处必须保持逻辑一直map.put("",0);int ans = process (stickers, target, map);return ans == Integer.MAX_VALUE ? -1 : ans;}public int process (String[] stickers, String target, HashMap<String, Integer> map ){if (map.get(target) != null) {return map.get(target);}//如果target为空,说明在上一轮已经拼接完毕if (target.isEmpty()) {return 0;}//每一轮递归的最终返回值int ans = Integer.MAX_VALUE;//讨论每一个单词是否能够参与target的拼接for (String word : stickers) {//返回target拼词以后剩余字符串String res = splice(word, target);//如果res与target长度相等,说明word并没有参与进拼词过程if (res.length() != target.length()) {//最少贴纸数,每一轮递归都要取最小值ans = Math.min(ans, process (stickers, res, map));}}//如果ans不是无效值,说明此轮递归参与到拼词过程中。张数对应的要增加一次ans = ans != Integer.MAX_VALUE ? ans + 1 : ans;map.put(target, ans);return ans;}public String splice(String s, String target){char[] ss = s.toCharArray();char[] tt = target.toCharArray();//26个小写字母,题目给定的int[] count = new int[26];//target字符串词频统计for (char tChar : tt) {count[tChar - 'a']++;}//根据当前单词到target中去减少对应的字符出现次数for(char sChar : ss) {count[sChar - 'a']--;}StringBuffer sb = new StringBuffer();//统计target还剩下哪些字符,并且把这些字符拼成字符串for (int i = 0; i < 26; i++) {//count[i]对应出现的次数,而 i 才是对应的字符if (count[i] > 0) {for (int times = 0; times < count[i]; times++) {sb.append((char)(i + 'a'));}}}return sb.toString();}public static void main(String[] args) {Stickers_01_opt s = new Stickers_01_opt();String[] ss = {"aa", "b", "bc"};String target = "aabc";System.out.println(s.minStickers(ss, target));}
}

虽然力扣是通过了,但是 5.****%的胜率,实在是有些牵强了。
再次看图分析:
1. 遍历数组的时候,不管能不能参与到target的拼词过程中去,所有数组都会遍历一遍,这有点说不过去了。因为每遍历一个数组元素,都要进入递归的,这样反反复复,浪费性能。
解决:不去遍历全部数组,而是根据target字符串中的第一个字符(或者其他位置的字符)去过滤。把过滤出来的数组进行遍历,这样可以快很多。
2. 词频统计是放在递归里面生成的,每遍历数组元素一次,就递归调用一次,相当麻烦。而且我们需要对数组元素进行过滤,目前的词频统计位置就不合理了。
解决:把词频统计提前批量完成,这样才方便过滤
优化版本:
package code03.动态规划_07.lesson5;/*** 力扣691 : 贴纸拼词* https://leetcode.cn/problems/stickers-to-spell-word/description/**/
public class Stickers_02 {public int minStickers(String[] stickers, String target){//边界值if (stickers == null|| stickers.length == 0|| target == null|| target.isEmpty()) {return -1;}int[][] dp = new int[stickers.length][26];//词频统计,去除掉第一版同一个单词反反复复的词频统计for (int i = 0; i < stickers.length; i++) {char[] chars = stickers[i].toCharArray();for (char sChar : chars) {dp[i][sChar - 'a']++;}}int ans = process (dp, target);return ans == Integer.MAX_VALUE ? -1 : ans;}public int process (int[][] arr, String target){//如果target为空,说明在上一轮已经拼接完毕if (target.isEmpty()) {return 0;}int[] count = new int[26];char[] tt = target.toCharArray();//每一轮递归target都不一样,因此每一轮都需用统计targetfor (char tChar : tt) {count[tChar - 'a']++;}int result = Integer.MAX_VALUE;for (int i = 0; i < arr.length; i++) {int[] sticker = arr[i];/**** tt是原target字符数组, 那么tt[0]就是target第一个字符* tt[0] - 'a' 就是第一个字符对应的下标。比如字符 'b' 下标就为1,'a' 对应0. 'c'对应2** count[0] 对应的是 a 字符。 target可以以26个字母任意一个开头,此处不可以使用count[0]** sticker[tt[0] - 'a'] 对应的是字符出现的次数。如果当前字符串含有target首字符,就考虑;* 否则,放弃。 剪枝:去除了不包含的情况*/if (sticker[tt[0] - 'a'] > 0) {StringBuilder sb = new StringBuilder();for (int j = 0; j < 26; j++) {//target词频需要根据当前数组单词全部剪掉。如果大于0,//则代表target在数组的当前单词参与拼词以后,还存在没有//拼接完的部分,需要记录下来用数组中别的单词再来拼for (int m = 0; m <count[j] - sticker[j]; m++) {//j代表字符的下标, count[j] 代表单签字符出现的次数sb.append((char) (j + 'a'));}}//递归,把剩余的target部分继续交个arr[][]去拼词result = Math.min(result, process(arr, sb.toString()));}}return result != Integer.MAX_VALUE ? result + 1 : result;}public static void main(String[] args) {Stickers_02 s = new Stickers_02();String[] ss = {"aa", "b", "bc"};String target = "aabc";System.out.println(s.minStickers(ss, target));}
}
明明代码已经优化了,为啥还超时呢?超时,说明代码应该没有逻辑错误,那就是时间复杂度的问题了。而时间复杂度是和计算有关的,加上缓存,俗称记忆化搜索试试:
public int minStickers(String[] stickers, String target){//边界值if (stickers == null|| stickers.length == 0|| target == null|| target.isEmpty()) {return -1;}int[][] dp = new int[stickers.length][26];//词频统计,去除掉第一版同一个单词反反复复的词频统计for (int i = 0; i < stickers.length; i++) {char[] chars = stickers[i].toCharArray();for (char sChar : chars) {dp[i][sChar - 'a']++;}}HashMap<String, Integer> map = new HashMap<>();//优化之前,target为空直接返回0. 因此,此处必须保持逻辑一直map.put("",0);int ans = process (dp, target, map);return ans == Integer.MAX_VALUE ? -1 : ans;}public int process (int[][] arr, String target, HashMap<String, Integer> map){if (map.get(target) != null) {return map.get(target);}//如果target为空,说明在上一轮已经拼接完毕if (target.isEmpty()) {return 0;}int[] count = new int[26];char[] tt = target.toCharArray();//每一轮递归target都不一样,因此每一轮都需用统计targetfor (char tChar : tt) {count[tChar - 'a']++;}int result = Integer.MAX_VALUE;for (int i = 0; i < arr.length; i++) {int[] sticker = arr[i];/**** tt是原target字符数组, 那么tt[0]就是target第一个字符* tt[0] - 'a' 就是第一个字符对应的下标。比如字符 'b' 下标就为1,'a' 对应0. 'c'对应2** count[0] 对应的是 a 字符。 target可以以26个字母任意一个开头,此处不可以使用count[0]** sticker[tt[0] - 'a'] 对应的是字符出现的次数。如果当前字符串含有target首字符,就考虑;* 否则,放弃。 剪枝:去除了不包含的情况*/if (sticker[tt[0] - 'a'] > 0) {StringBuilder sb = new StringBuilder();for (int j = 0; j < 26; j++) {//target词频需要根据当前数组单词全部剪掉。如果大于0,//则代表target在数组的当前单词参与拼词以后,还存在没有//拼接完的部分,需要记录下来用数组中别的单词再来拼for (int m = 0; m <count[j] - sticker[j]; m++) {//j代表字符的下标, count[j] 代表单签字符出现的次数sb.append((char) (j + 'a'));}}//递归,把剩余的target部分继续交个arr[][]去拼词result = Math.min(result, process(arr, sb.toString(), map));}}result = result != Integer.MAX_VALUE ? result + 1 : result;map.put(target, result);return result;}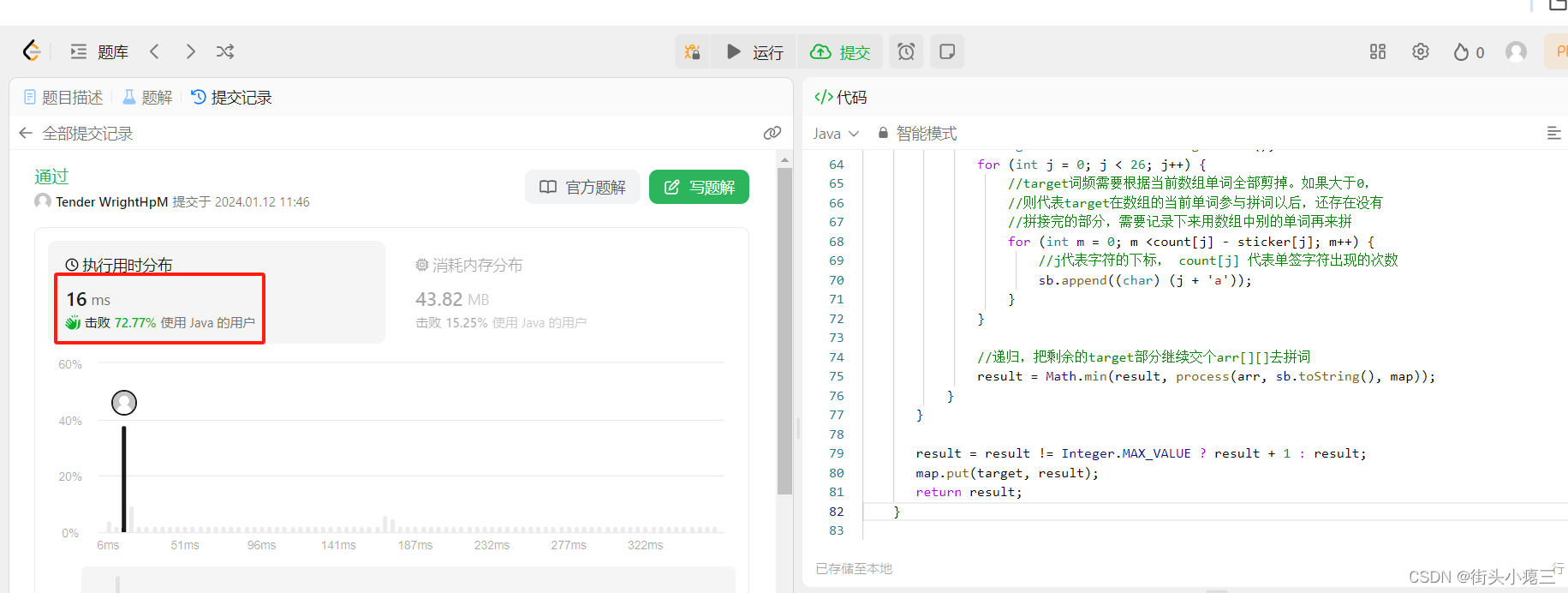
加上缓存以后,果然快了很多!
我们之前说递归、递归+记忆化搜索、动态规划。 对于非严格依赖表结构,递归+记忆化搜索有时候也是等价于动态规划的。
严格依赖表结构的动态规划,则优化的空间更大。以后,还会基于动态规划,进行更为复杂的算法优化。




)






![[深度学习]Open Vocabulary Object Detection 部署开放域目标检测模型使用感受](http://pic.xiahunao.cn/[深度学习]Open Vocabulary Object Detection 部署开放域目标检测模型使用感受)







