Kafka 除了用作消息队列还能干吗?
本文转自 公众号 ByteByteGo,如有侵权,请联系,立即删除
Kafka 最初是为大规模处理日志而构建的。它可以保留消息直到过期,并让各个消费者按照自己的节奏提取消息。
与其之前的竞品不同,Kafka 不仅仅是一个消息队列,它还是一个适用于各种情况的开源事件流平台。
让我们回顾一下流行的 Kafka 用例。
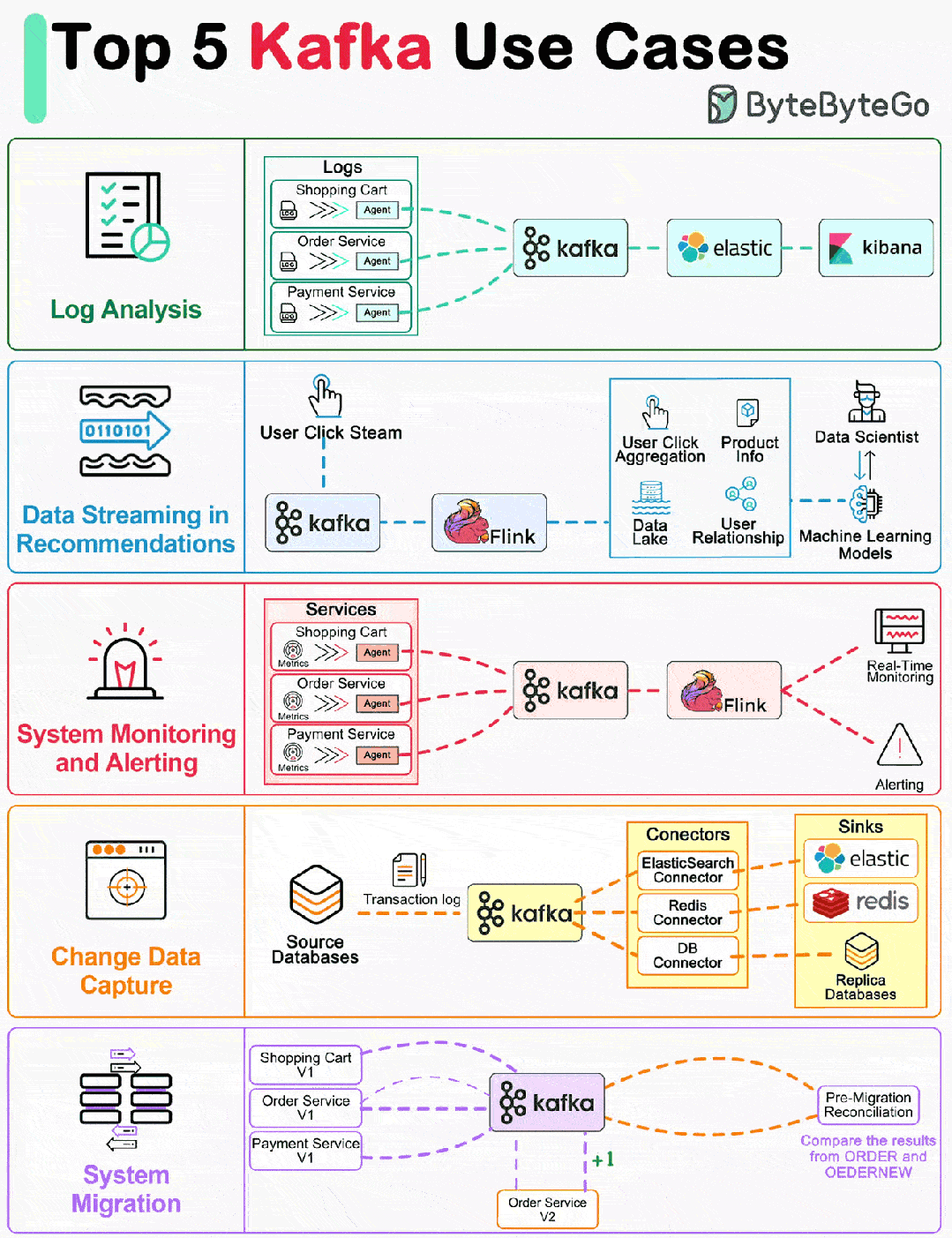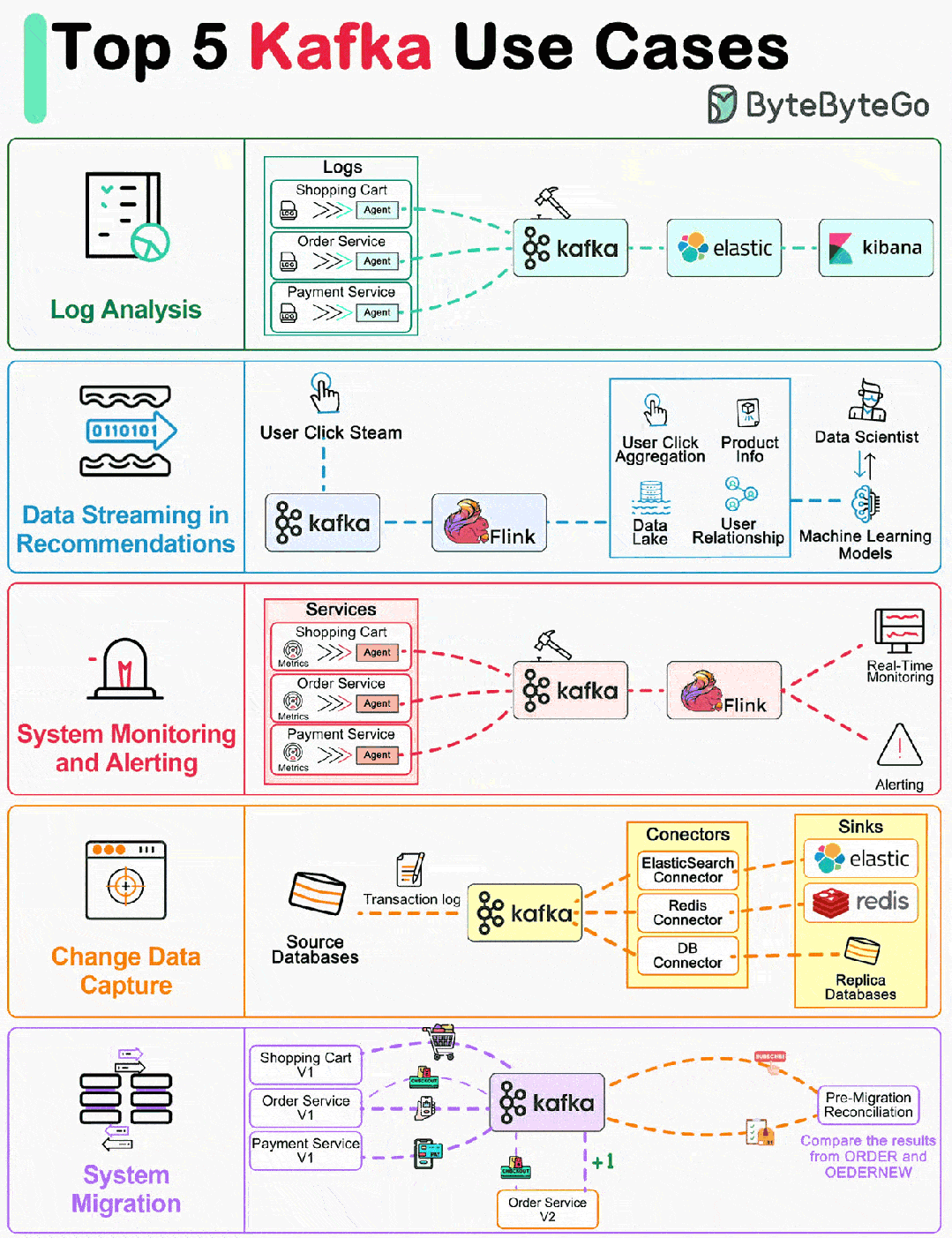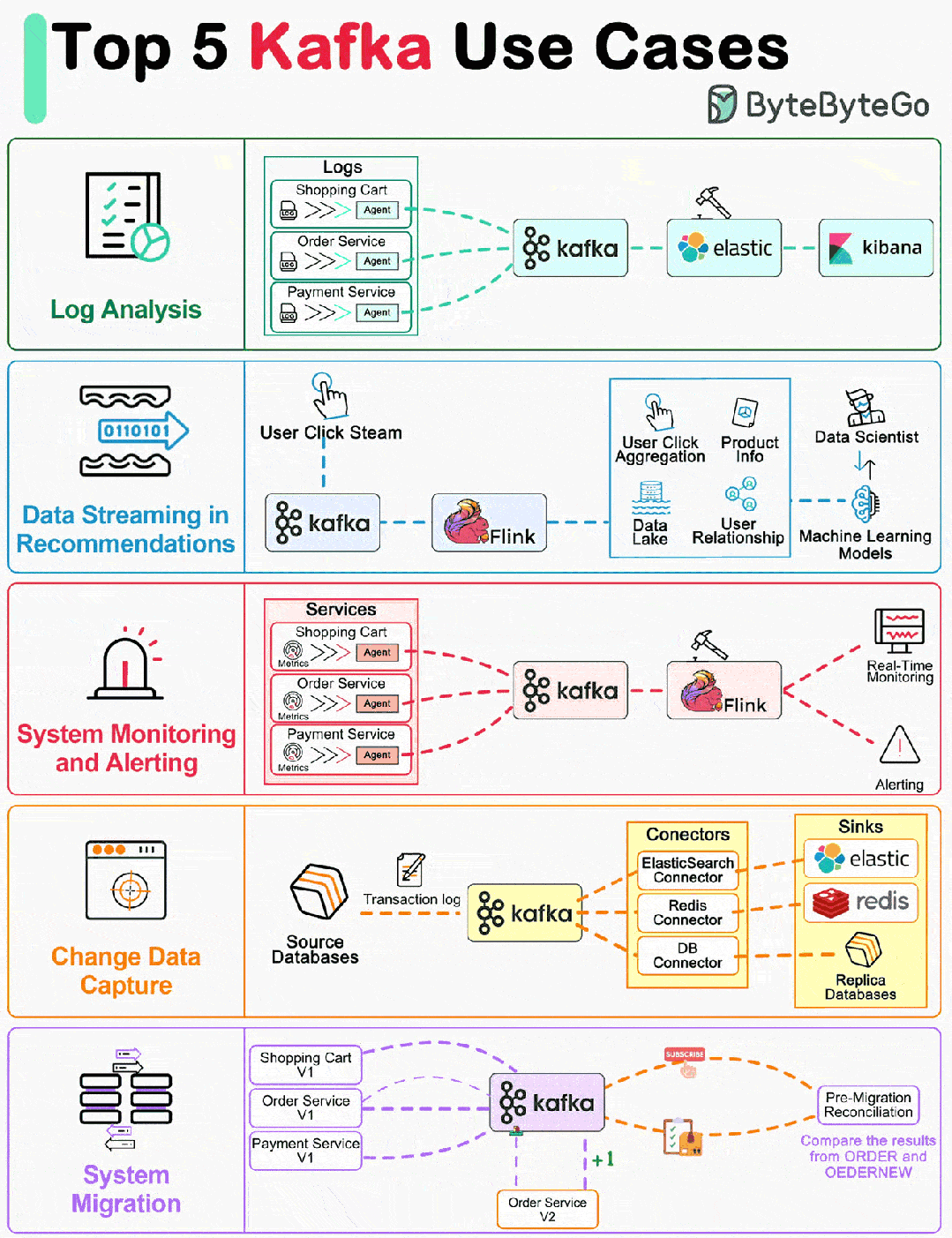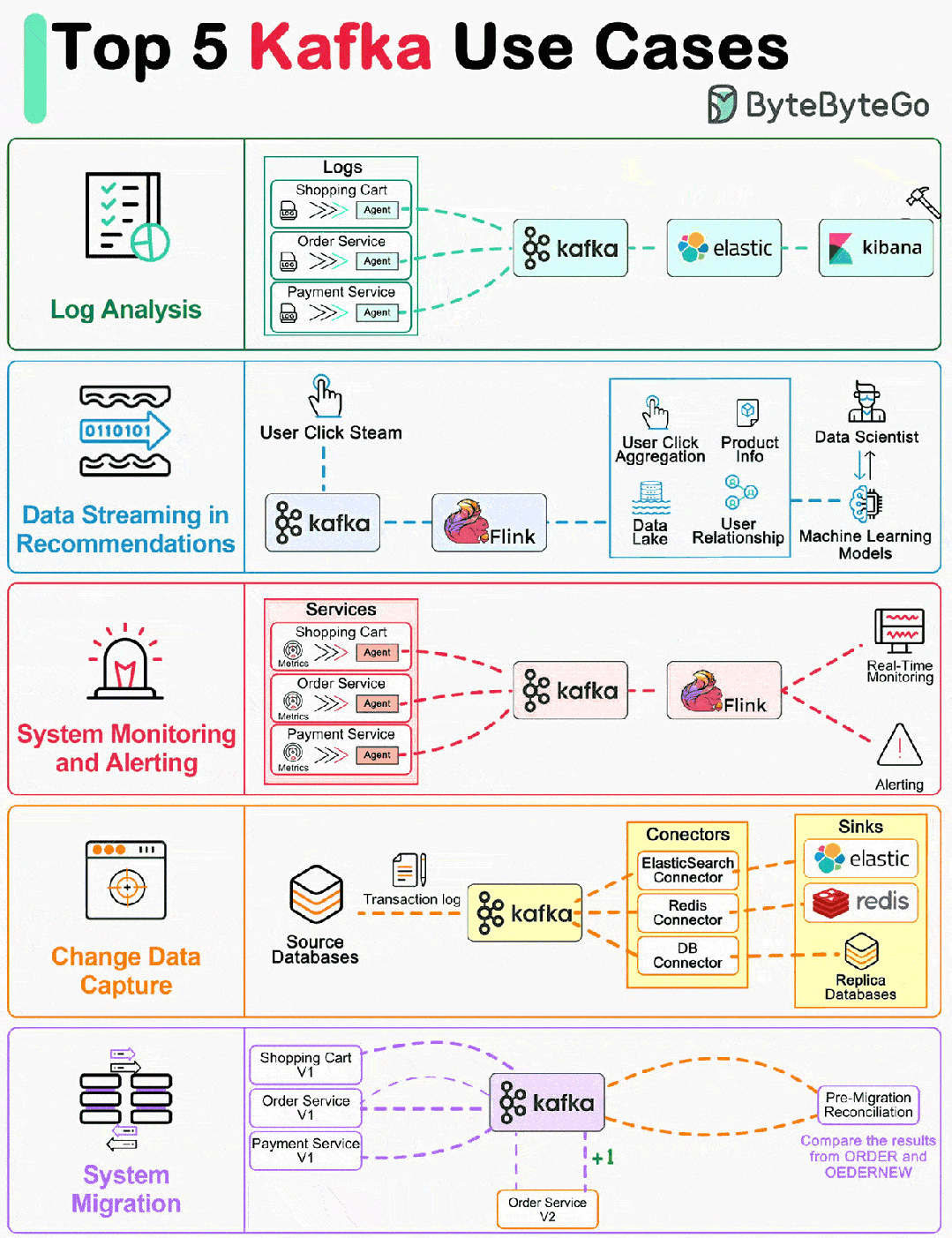
01 日志处理和分析
上图显示了一个典型的 ELK(Elastic-Logstash-Kibana)栈。Kafka 从每个服务实例高效地收集日志流。ElasticSearch 从 Kafka 中获取日志并编制索引。Kibana 在 ElasticSearch 的基础上提供搜索和可视化用户界面。
02 推荐系统中的数据流
亚马逊等电子商务网站利用用户过去的行为和相似用户分析来计算产品推荐。Kafka 传输原始点击流数据,Flink 对其进行处理,而模型训练则消耗数据湖中的汇总数据。这样就能不断改进针对每个用户的推荐相关性。
03 系统监控和警报
与日志分析系统类似,我们需要收集系统指标来进行监控和故障排除。不同的是,指标是结构化数据,而日志是非结构化文本。指标数据被发送到 Kafka 并在 Flink 中聚合。实时监控仪表板和警报系统(如 PagerDuty)将使用汇总的数据。
04 CDC(Change Data Capture)
CDC 将数据库的变更传输到其他系统,以便复制或更新缓存/索引。例如,在下图中,事务日志被发送到 Kafka,并被 ElasticSearch、Redis 和二级数据库摄取。
05 系统迁移
升级旧服务是一项具有挑战性的任务,比如编程语言陈旧、逻辑复杂、缺乏测试等等。我们可以利用消息中间件来降低风险。如上图所示,为了升级订单服务,我们更新了旧订单服务,以便从 Kafka 中消费输入,并将结果写入 ORDER Topic。新订单服务消耗相同的输入,并将结果写入 ORDERNEW Topic。对账服务会比较 ORDER 和 ORDERNEW 下收到的内容。如果它们完全相同,新服务就会通过测试。











——Native层函数)


)

_09_Telent协议【13道题】)
C++泛型编程与标准模板库简介)

)