上一篇文章我们记录了如何操作硬盘,并且编写了简单的硬盘驱动程序用于获取一些硬盘的参数。这篇文章就在上一篇文章的基础上记录文件系统,完善硬盘驱动程序。
文件系统
现在我们该仔细考虑如何构建一个文件系统了。这并不是我们第一次接触文件系统,我们在之前的时候就研究过FAT12。FAT12算是很简单的文件系统了,既然我们已经比较熟悉它了,就让我们结合它的结构来分析一下一个文件系统都需要哪些要素。

我们来参考一下FAT12的布局,图中分为四个部分,分别是引导区、FAT表、根目录区和数据区。其中引导扇区中不仅包含引导代码,而且包含BPB,它包含诸如根目录文件数最大值之类的信息,可算是文件系统的Metadata;FAT表记录的是整个磁盘扇区的使用情况,有哪些扇区未被使用,以及每个文件占用哪些扇区等;根目录区则是文件的索引了,那里记录了文件的名称、属性等内容。
这么看来,一个简单的文件系统大致需要这么几个要素:
- 要有地方存放Metadata;
- 要有地方记录扇区的使用情况;
- 要有地方来记录任一文件的信息,比如占用了哪些扇区等;
- 要有地方存放文件的索引。
这些要点不难理解,而且如果你分析其它文件系统的话,也基本是这些要素。与此同时,只要具备了这些要素,一个文件系统基本就可以用了——至于好坏,那不是我们这样的初学者要考虑的问题。
好了,根据这些要素,书上又同时参照了Minix的文件系统,我们就把我们的文件系统设计成如下图所示的样子。

可以看到,它几乎是把前面叙述的各要素一字排开:
- 要有地方存放Metadata——占用整整一个扇区的super block;
- 要有地方记录扇区的使用情况——sector map;
- 要有地方记录任一文件的信息,比如占用了哪些扇区等——inode map以及被称作inode_array的i-node真正存放地;
- 要有地方存放文件的索引——root数据区。
super block通常也叫做超级块,关于文件系统的Metadata我们统统记在这里。sector map是一个位图,它用来映射扇区的使用情况,用1表示扇区已被使用,0表示未被使用。i-node是UNIX世界各种文件系统的核心数据结构之一,我们把它借用过来。每个i-node对应一个文件,用于存放文件名、文件属性等内容,inode-array就是把所有i-node都放在这里,形成一个较大的数组。而inode map就是用来映射inode-array这个数组使用情况的一个位图用法跟sector map类似。root数据区类似于FAT12的根目录区,但本质上它也是个普通文件,由于它是所有文件的索引,所以我们把它单独看待。为了简单起见,我们的文件系统暂不支持文件夹,也就是说用来表示目录的特殊文件只有这么一个。这种不支持文件夹的文件系统,历史上曾经有过,而且这种文件系统还有个名字,叫做扁平文件系统(Flat File System)。
至于引导扇区,就让它纯粹用作引导吧,我们不打算学习FAT12把一些额外的数据结构塞进去——512字节已经够挤了,而如今的硬盘是如此的便宜。
轻轻松松,在前人的基础上,加上做的也简单,我们的文件系统就这样设计完成了。下面该是想想怎么将它放到硬盘上了。根据我们的经验,一个文件系统可以安装到硬盘上的一个分区上,而且一块硬盘之上可以有多个文件系统共存。那么,下面我们就来找个分区在它上面实现,可是不忙,我们还不知道硬盘是怎么分区的呢?下面就来研究一下。
硬盘分区表
你可能会有这样一个问题,就是为什么不把文件系统直接安装到整块硬盘上呢?这样做是完全可以的,而且简单易行。但是书上作者的想法是这样的,将来可以把我们辛苦实现的操作系统装到自己的计算机上,到时候稍微设置一下Grub,实现多引导,让我的操作系统跟Linux、Windows等并存,岂不美哉。所以在这里我们就多做一些,研究一下怎么来针对分区进行操作,要不然一下子用掉整块硬盘,显得过于浪费了。
硬盘分区表其实是一个结构体数组,数组的每个成员是一个16字节的结构体,它的构成如下表所示。
| 偏移 | 长度 | 描述 |
| 0 | 1 | 状态(80h=可引导,00h=不可引导,其它=不合法) |
| 1 | 1 | 起始磁头号 |
| 2 | 1 | 起始扇区号(仅用了低6位,高2位为起始柱面号的第8,9位) |
| 3 | 1 | 起始柱面号的低8位 |
| 4 | 1 | 分区类型(System ID) |
| 5 | 1 | 结束磁头号 |
| 6 | 1 | 结束扇区号(仅用了低6位,高2位为结束柱面号的第8,9位) |
| 7 | 1 | 结束柱面号的低8为 |
| 8 | 4 | 起始扇区的LBA |
| 12 | 4 | 扇区数目 |
这个数组位于引导扇区的 1BEh 处,共有四个成员——因为IBM当时觉得一台PC最多会装四个操作系统。现在我们的计算机中每块硬盘经常划分成不止四个分区,这是因为每个主分区可以进一步分成多个逻辑分区。具体的做法,我们还是需要一个示例来对照。为了安全起见,我们操作映像而不是真的硬盘。现在我们把上一篇文章生成的硬盘分成几个区:


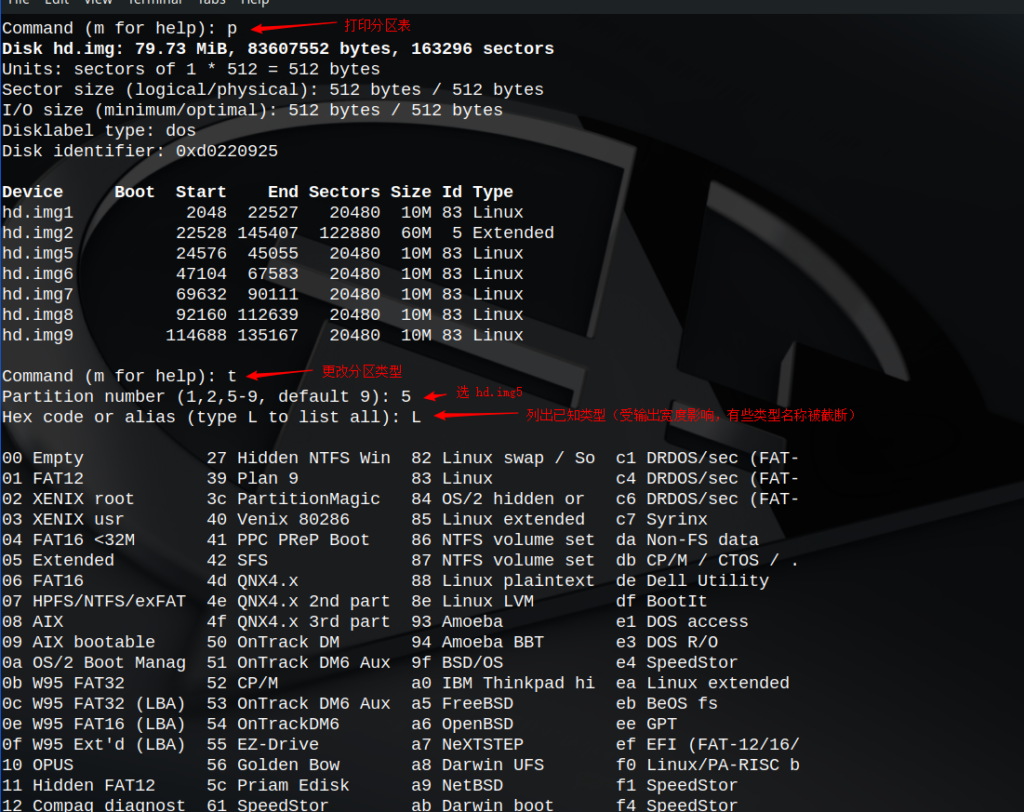

在这里我们把一个80MB的硬盘映像分成了一个主分区和一个扩展分区,扩展分区中又分成了五个逻辑分区(逻辑分区过程截图并未完全显示,也可以根据自己想法进行分区)。我们将来把Orange’s装在第一个逻辑分区上,也就是hd.img5的分区。我们先是把它的分区类型(System ID)改成99h,又为它设定了“可启动”标志。在设置分区类型时,我们先是列出了已知的类型,然后选定还未使用的99h作为我们文件系统的System ID。
现在我们就来实际看一下分区表是什么样子的,用二进制查看器来看一下引导扇区:

硬盘分区表位于1BEh 处,共有4个成员,每个成员是16字节,所以第1BEh到第1FDh字节便是分区表的内容了,按照硬盘分区表的说明,可知它们的意义如下表所示。
| 分区序号 | 状态 | 分区类型 | 起始扇区LBA | 扇区数目 |
| 0 | 00h(不可引导) | 83 | 800h | 5000h |
| 1 | 00h(不可引导) | 05 | 5800h | 1E000h |
从表中可知,第一个分区起始于800h扇区,共有5000h个扇区,第二个分区起始于5800h扇区,共有1E000h个扇区。然后这些信息是不够的,我们还有若干逻辑分区的信息没有得到呢。没关系,一步一步来,我们现在就来看一下第二个分区——也就是扩展分区的第一个扇区时什么样子。扩展分区的开始字节为B00000h(5800h*200h),它的内容如下:
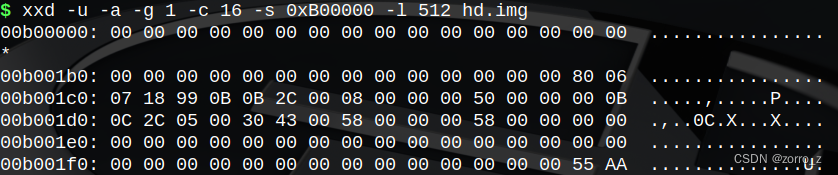
其主要项的意义如下表所示。
| 分区序号 | 状态 | 分区类型 | 起始扇区LBA | 扇区数目 |
| 0 | 80h(可引导) | 99h | 800h | 5000h |
| 1 | 00h(不可引导) | 05h | 5800h | 5800h |
前一个分区的起始扇区LBA是800h,这是个相对于扩展分区基地址的LBA,也就是说,它真正的LBA是5800h+800h=6000h。后一个分区,根据其分区类型05h可知,它又是个扩展分区,起始扇区LBA为5800h+5800h=B000h,字节偏移为B000h*200h=1600000h,我们继续看看其引导扇区:

其意义如表所示。
| 分区序号 | 状态 | 分区类型 | 起始扇区LBA | 扇区数目 |
| 0 | 00h(不可引导) | 83 | 800h | 5000h |
| 1 | 00h(不可引导) | 05 | B000h | 5800h |
从分区类型值(System ID)可以看出,在这个分区中,又包含了一个“普通的”分区和一个扩展分区,你现在可能有些明白了,多个逻辑分区是由嵌套来实现的。一个扩展分区里包含一个普通分区的同时,又可以嵌套一个扩展分区,一层一层的。其实这种层状结构,也可以看做是一个链表,链表的节点即为扩展分区的分区表,每个节点中有两个表项,前一个表项描述一个普通分区,后一个表项指向下一个节点。
需要留意的一点是,前一个表项中的起始扇区LBA是相对于当前扩展分区的,而后一个表项中的起始扇区——也就是下一个扩展分区的起始扇区——是相对于硬盘主引导扇区所指明的扩展分区的起始扇区的。这样说可能有点拗口,就本例来说,扇区5800h中的分区表有两个表项,前一项的起始扇区LBA为800h,它的实际LBA要将800h与5800h相加,即6000h;后一项的起始扇区LBA为5800h,它的实际地址要与5800h相加,即B000h。
明白了这些,遍历所有逻辑扇区的工作需要的就只剩下一些耐心和细心了。按照这样的方法,我们可以一步一步遍历所有的分区。
设备号
硬盘的每个分区都会有一个分区号,在我们的例子中,主引导扇区中有两个表项,对应一个主分区和一个扩展分区,即hd.img1和hd.img2,扩展分区中有5个逻辑分区,从hd.img5到hd.img9。Linux中的编号规则是1~4这四个数字为主引导扇区的分区表项所用,从5开始依次表示逻辑分区。
其实,1、2、5~9等这些数字有个名称,叫做次设备号。其作用是给每个设备(分区)起一个名字,这样驱动程序就能方便地管理它们。另外还有个我们没说过的主设备号,它的作用是给每一类设备一个名字,以方便管理。举个例子,假设我们的计算机内有三块硬盘和两个软盘。对用户而言,操作硬盘和软盘上的文件的区别可能仅在于路径不同,但对于操作系统,硬盘和软盘需要不同的驱动程序,所以不同类别的硬件需要区别对待,这就是主设备号存在的理由。同时,硬盘有多个,而且每个硬盘上可能有多个分区,对这些分区,又需要区别对待,于是又用到了次设备号。简单来说,主设备号告诉操作系统应该用哪个驱动程序来处理,次设备号告诉驱动程序这是具体哪个设备。
在我们的系统中,我们也需要有主次设备号,但对硬盘而言,我们采用与Linux不同的编号规则,具体如下图所示。
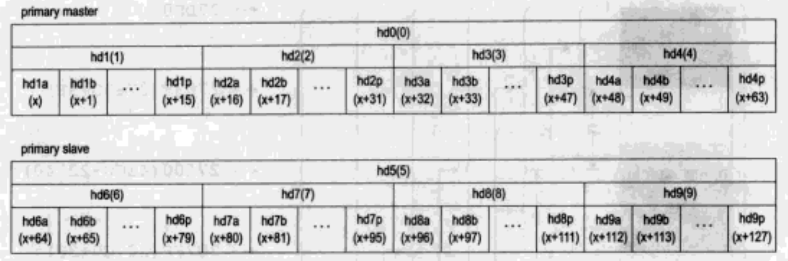
在这里我们还是只看主IDE通道上连接两块硬盘的情况。图中括号内的便是次设备号。主盘是hd0,其次设备号为0,它的主引导扇区分区表对应四个分区分别是hd1、hd2、hd3、hd4。每个扩展分区中最多有16个逻辑分区,以字母a~p表示,逻辑分区的次设备号是以hd1a为基准递增的。这种编号规则的好处是,给定一个次设备号,可以很容易地计算出它是主分区还是扩展分区,或者是哪个扩展分区的哪个逻辑分区。同时,给定一个分区的名称,我们也很容易计算出其次设备号。
配置这套规则,我们定义了一些宏。
代码 include/const.h,硬盘设备号相关的宏。
#define MAX_DRIVES 2
#define NR_PART_PER_DRIVE 4
#define NR_SUB_PER_PART 16
#define NR_SUB_PER_DRIVE (NR_SUB_PER_PART * NR_PART_PER_DRIVE)
#define NR_PRIM_PER_DRIVE (NR_PART_PER_DRIVE + 1)/*** @def MAX_PRIM* Defines the max minor number of the primary partitions.* If there are 2 disks, prim_dev ranges in hd[0-9], this macro will* equal 9.*/
#define MAX_PRIM (MAX_DRIVES * NR_PRIM_PER_DRIVE - 1)
#define MAX_SUBPARTITIONS (NR_SUB_PER_DRIVE * MAX_DRIVES)在这本书中,只考虑硬盘接在主IDE通道的情况,所以最多支持两块硬盘,因此MAX_DRIVES定义为2。NR_SUB_PER_PART定义的是每个扩展分区最多有多少个逻辑分区。根据NR_PART_PER_DRIVE的值容易算出NR_PRIM_PER_DRIVE为5,它其实表示的是hd[0~4]这5个分区,因为有些代码中我们把整块硬盘(hd0)和主分区(hd[1~4])放在一起看待。MAX_PRIM定义的是主分区的最大值,比如有两块硬盘,那第一块硬盘的主分区为hd[1~4],第二块硬盘的主分区为hd[6~9],所以MAX_PRIM为9,我们定义的hd1a的设备号应大于它,这样通过与MAX_PRIM比较,我们就可以知道一个设备是主分区还是逻辑分区。
主设备号的情况要简单一些,因为它的作用在于找到相应的驱动程序,所以我们只要建立一个以主设备号为下标、以驱动器号(PID)为值的数组,就可以了。具体如下面代码所示。
代码 kernel/global.c,dd_map。
/*** For dd_map[k], * 'k' is the device nr.\ dd_map[k].driver_nr is the driver nr.* * Remeber to modify include/const.h if the order is changed.*/
struct dev_drv_map dd_map[] = {/* driver nr. major device nr. *//* ---------- ---------------- */{INVALID_DRIVER}, /**< 0 : Unused */{INVALID_DRIVER}, /**< 1 : Reserved for floppy driver */{INVALID_DRIVER}, /**< 2 : Reserved for cdrom driver */{TASK_HD}, /**< 3 : Hard disk */{TASK_TTY}, /**< 4 : TTY */{INVALID_DRIVER} /**< 5 : Reserved for scsi disk driver */
};主设备号的定义如下,代码 include/const.h。
/* major device numbers (corresponding to kernel/global.c::dd_map[]) */
#define NO_DEV 0
#define DEV_FLOPPY 1
#define DEV_CDROM 2
#define DEV_HD 3
#define DEV_CHAR_TTY 4
#define DEV_SCSI 5/* make device number from major and minor numbers */
#define MAJOR_SHIFT 8
#define MAKE_DEV(a,b) ((a << MAJOR_SHIFT) | b)/* separate major and minor numbers from device number */
#define MAJOR(x) ((x >> MAJOR_SHIFT) & 0xFF)
#define MINOR(x) (x & 0xFF)#define INVALID_DRIVER -20结构体 dev_drv_map 的定义在 include/fs.h 中,这是新增加的一个头文件。
struct dev_drv_map {int driver_nr; /**< The proc nr.\ of the device driver. */
};一定要注意,主设备号的宏定义的值为dd_map[]的下标,两者是相呼应的,若要改变的话要同时改变。将来我们每个设备号都有主设备号和次设备号组成,通过简单的位运算即可得到主设备号及次设备号。
刚才我们在给磁盘映像hd.img分区时,指定hd.img5为Orange’s分区,我们将来会把文件系统建立在这个分区上。根据我们的命名规则,它的名字应该是hd2a。它的次设备号应该等于hd1a加上16。
用代码遍历所有分区
好了,分区表的原理已经清楚了,下面我们就来添加代码,在硬盘驱动程序中找出所有分区并且将它们打印出来。
代码 kernel/hd.c,读取分区表。
PRIVATE struct hd_info hd_info[1];#define DRV_OF_DEV(dev) (dev <= MAX_PRIM ? dev / NR_PRIM_PER_DRIVE : (dev - MINOR_hd1a) / NR_SUB_PER_DRIVE)/* task_hd */
/* Main loop of HD driver */
PUBLIC void task_hd()
{
...switch (msg.type) {case DEV_OPEN:hd_open(msg.DEVICE);break;
...}...
}/*** <Ring 1> Check hard drive, set IRQ handler, enable IRQ and initialize data structures.*/
PRIVATE void init_hd()
{
...int i;for (i = 0; i < sizeof(hd_info) / sizeof(hd_info[0]); i++) {memset(&hd_info[i], 0, sizeof(hd_info[0]));}hd_info[0].open_cnt = 0;
}/*** <Ring 1> This routine handles DEV_OPEN message. It identify the drive * of the given device and read the partition table of the drive if it * has not been read.* * @param device The device to be opend.*/
PRIVATE void hd_open(int device)
{int drive = DRV_OF_DEV(device);assert(drive == 0); /* only one drive */hd_identify(drive);if (hd_info[drive].open_cnt++ == 0) {partition(drive * (NR_PART_PER_DRIVE + 1), P_PRIMARY);print_hdinfo(&hd_info[drive]);}
}/*** <Ring 1> Get a partition table of a drive.* * @param drive Drive nr (0 for the 1st disk, 1 for the 2nd, ...)n* @param sect_nr The sector at which the partition table is located.* @param entry Ptr to part_ent struct.*/
PRIVATE void get_part_table(int drive, int sect_nr, struct part_ent * entry)
{struct hd_cmd cmd;cmd.features = 0;cmd.count = 1;cmd.lba_low = sect_nr & 0xFF;cmd.lba_mid = (sect_nr >> 8) & 0xFF;cmd.lba_high = (sect_nr >> 16) & 0xFF;cmd.device = MAKE_DEVICE_REG(1, /* LBA mode */drive, (sect_nr >> 24) & 0xF);cmd.command = ATA_READ;hd_cmd_out(&cmd);interrupt_wait();port_read(REG_DATA, hdbuf, SECTOR_SIZE);memcpy(entry, hdbuf + PARTITION_TABLE_OFFSET, sizeof(struct part_ent) * NR_PART_PER_DRIVE);
}/*** <Ring 1> This routine is called when a device is opened. It reads the * partition table(s) and fills the hd_info struct.* * @param device Device nr.* @param style P_PRIMARY or P_EXTENDED.*/
PRIVATE void partition(int device, int style)
{int i;int drive = DRV_OF_DEV(device);struct hd_info * hdi = &hd_info[drive];struct part_ent part_tbl[NR_SUB_PER_DRIVE];if (style == P_PRIMARY) {get_part_table(drive, drive, part_tbl);int nr_prim_parts = 0;for (i = 0; i < NR_PART_PER_DRIVE; i++) { /* 0~3 */if (part_tbl[i].sys_id == NO_PART) {continue;}nr_prim_parts++;int dev_nr = i + 1; /* 1~4 */hdi->primary[dev_nr].base = part_tbl[i].start_sect;hdi->primary[dev_nr].size = part_tbl[i].nr_sects;if (part_tbl[i].sys_id == EXT_PART) { /* extended */partition(device + dev_nr, P_EXTENDED);}}assert(nr_prim_parts != 0);} else if (style == P_EXTENDED) {int j = device % NR_PRIM_PER_DRIVE; /* 1~4 */int ext_start_sect = hdi->primary[j].base;int s = ext_start_sect;int nr_1st_sub = (j - 1) * NR_SUB_PER_PART; /* 0/16/32/48 */for (i = 0; i < NR_SUB_PER_PART; i++) {int dev_nr = nr_1st_sub + i; /* 0~15/16~31/32~47/48~63 */get_part_table(drive, s, part_tbl);hdi->logical[dev_nr].base = s + part_tbl[0].start_sect;hdi->logical[dev_nr].size = part_tbl[0].nr_sects;s = ext_start_sect + part_tbl[1].start_sect;/* no more logical partitions in this extended partition */if (part_tbl[1].sys_id == NO_PART) {break;}}} else {assert(0);}
}/*** <Ring 1> Print disk info.* * @param hdi Ptr to struct hd_info.*/
PRIVATE void print_hdinfo(struct hd_info * hdi)
{int i;for (i = 0; i < NR_PART_PER_DRIVE + 1; i++) {printl("%sPART_%d: base %d(0x%x), size %d(0x%x) (in sector)\n",i == 0 ? " " : " ",i,hdi->primary[i].base,hdi->primary[i].base,hdi->primary[i].size,hdi->primary[i].size);}for (i = 0; i < NR_SUB_PER_DRIVE; i++) {if (hdi->logical[i].size == 0) {continue;}printl(" %d: base %d(0x%x), size %d(0x%x), (in sector)\n",i,hdi->logical[i].base,hdi->logical[i].base,hdi->logical[i].size,hdi->logical[i].size);}
}/*** <Ring 1> Get the disk information.* * @param drive Drive Nr. */
PRIVATE void hd_identify(int drive)
{struct hd_cmd cmd;cmd.device = MAKE_DEVICE_REG(0, drive, 0);cmd.command = ATA_IDENTIFY;hd_cmd_out(&cmd);interrupt_wait();port_read(REG_DATA, hdbuf, SECTOR_SIZE);print_identify_info((u16*)hdbuf);u16* hdinfo = (u16*)hdbuf;hd_info[drive].primary[0].base = 0;/* Total Nr of User Addressable Sectors */hd_info[drive].primary[0].size = ((int)hdinfo[61] << 16) + hdinfo[60];
}在之前的代码中,驱动程序收到DEV_OPEN消息之后调用函数hd_identify(),在这里我们改成了调用函数hd_open(),这是新加的一个函数,它接受的参数即为设备的次设备号。在hd_open()中,我们首先由设备次设备号得到驱动器号,由于我们的Bochs只定义了一个硬盘,所以这里的驱动器号一定是0。接下来便是调用hd_identify()了。再往下是一个if语句,其中涉及我们新定义的一个结构体:hd_info。它的定义如下代码所示。
struct part_ent {u8 boot_ind; /*** boot indicator* Bit 7 is the active partition flag,* bits 6-0 are zero (when not zero this* byte is also the drive number of the* drive to boot so the active partition* is always found on drive 80H, the first* hard disk).*/u8 start_head; /*** Starting Head*/u8 start_sector; /*** Starting Sector.* Only bits 0-5 are used. Bits 6-7 are* the upper two bits for the Starting* Cylinder field.*/u8 start_cyl; /*** Starting Cylinder.* This field contains the lower 8 bits* of the cylinder value. Starting cylinder* is thus a 10-bit number, with a maximum* value of 1023.*/u8 sys_id; /*** System ID* e.g.* 01: FAT12* 81: MINIX* 83: Linux*/u8 end_head; /*** Ending Head*/u8 end_sector; /*** Ending Sector.* Only bits 0-5 are used. Bits 6-7 are* the upper two bits for the Ending* Cylinder field.*/u8 end_cyl; /*** Ending Cylinder.* This field contains the lower 8 bits* of the cylinder value. Ending cylinder* is thus a 10-bit number, with a maximum* value of 1023.*/u32 start_sect; /*** starting sector counting from* 0 / Relative Sector. / start in LBA*/u32 nr_sects; /*** nr of sectors in partition*/};struct part_info {u32 base; /* # of start sector (NOT byte offset, but SECTOR) */u32 size; /* how many sectors in this partition */
};/* main drive struct, one entry per drive */
struct hd_info
{int open_cnt;struct part_info primary[NR_PRIM_PER_DRIVE];struct part_info logical[NR_SUB_PER_DRIVE];
};与此同时我们声明了一个数组:hd_info[1],鉴于目前我们的虚拟机只装了一块硬盘,我们只给了它一个成员。hd_info的主要作用是记录硬盘的分区信息,每个硬盘应有一个hd_info结构。其中primary成员用来记录所有主分区的起始扇区和扇区数目,它们占用primary[1-4],logical用来记录所有逻辑分区的起始扇区和扇区数目。注意这里整个硬盘的起始扇区和扇区数目记在了primary[0]中。
我们接着来看hd_open,其中的if语句判断hd_info的open_cnt成员是否为0,并将其自加。由于在init_hd()中我们将结构体清零了,所以第一次执行到这里时if判断为真,于是调用partition()和print_hdinfo()。
函数partition()所做的便是获取硬盘分区表了,这个过程我们已经清楚了,这里只不过是用C语言代码写出来而已。注意其中的读硬盘扇区的工作封装在了函数get_part_table()中,和执行IDENTIFY命令类似,执行READ命令时我们同样是先填充hd_cmd结构,然后交给hd_cmd_out()来写寄存器。
函数print_hdinfo()就比较简单了,将获取的分区信息打印出来而已。
这里有一点需要说明一下,上一篇文档的代码FS发送DEV_OPEN消息时没有任何附加参数,现在hd_open()是带参数的了,所以FS的代码也要修改一下。
代码 fs/main.c,修改后的文件系统进程。
/*** <Ring 1> The main loop of TASK FS.*/
PUBLIC void task_fs()
{printl("Task FS begins.\n");/* open the device: hard disk */MESSAGE dirver_msg;dirver_msg.type = DEV_OPEN;dirver_msg.DEVICE = MINOR(ROOT_DEV);assert(dd_map[MAJOR(ROOT_DEV)].driver_nr != INVALID_DRIVER);send_recv(BOTH, dd_map[MAJOR(ROOT_DEV)].driver_nr, &dirver_msg);spin("FS");
}这里我们不仅将ROOT_DEV的次设备号通过消息发送给了驱动程序,而且使用哪个驱动程序也变成由dd_map来选择,这样一来,只要将ROOT_DEV定义好了,正确的消息便能发送给正确的驱动程序。ROOT_DEV的定义如下所示。
代码 include/const.h,ROOT_DEV。
/* device numbers of hard disk */
#define MINOR_hd1a 0x10
#define MINOR_hd2a (MINOR_hd1a + NR_SUB_PER_PART)#define ROOT_DEV MAKE_DEV(DEV_HD, MINOR_BOOT)其中MINOR_BOOT被定义成MINOR_hd2a,放在一个新的头文件config.h中,将来一些硬盘配置的宏定义将放在这个文件中。
代码 include/config.h。
#define MINOR_BOOT MINOR_hd2a好了,现在FS会把hd2a的次设备号发给dd_map[DEV_HD].driver_nr,即TASK_HD——我们的硬盘驱动,然后驱动程序将执行hd_open,从而获取硬盘的分区信息。现在我们可以make并执行看一下效果了。提醒一下,由于我们新增加了头文件,所以不要忘记更改Makefile。运行效果如下图所示。

好了,做了这么多准备工作,硬盘的分区信息总算是打印出来了。
欢迎关注我的公众号






)









)

![C语言中的指针变量p,特殊表达式p[0] ,(*p)[0],(px+3)[2] ,(*px)[3]化简方法](http://pic.xiahunao.cn/C语言中的指针变量p,特殊表达式p[0] ,(*p)[0],(px+3)[2] ,(*px)[3]化简方法)
)
