上一篇已经讲解了如何构建自己的私人GPT,这一篇主要讲如何让GPT支持中文。
privateGPT 本地部署目前只支持基于llama.cpp 的 gguf格式模型,GGUF 是 llama.cpp 团队于 2023 年 8 月 21 日推出的一种新格式。它是 GGML 的替代品,llama.cpp 不再支持 GGML。
本文主要采用国产YI-34B-CHAT模型。
1.模型下载
yi模型下载:TheBloke/Yi-34B-Chat-GGUF · Hugging Face
下载后放置在 models 文件夹下
embedding模型下载:BAAI/bge-small-en-v1.5 · Hugging Face
下载后放置在models/cache文件夹下,bge is short for BAAI general embedding,FlagEmbedding 可以将任何文本映射到低维密集向量,该向量可用于检索、分类、聚类或语义搜索等任务。它还可以用于法学硕士的矢量数据库
2.settings.yaml 文件修改:
主要修改local部分,使用YI模型使用prompt_style: "tag"类型的提示词模板
llm_hf_model_file: yi-34b-chat.Q4_K_M.gguf
prompt_style: "tag"3.代码修改
使用YI-34B-CHAT模型,源码要简单修改下,修改如下
文件路径 privateGPT/private_gpt/components/llm/llm_component.py
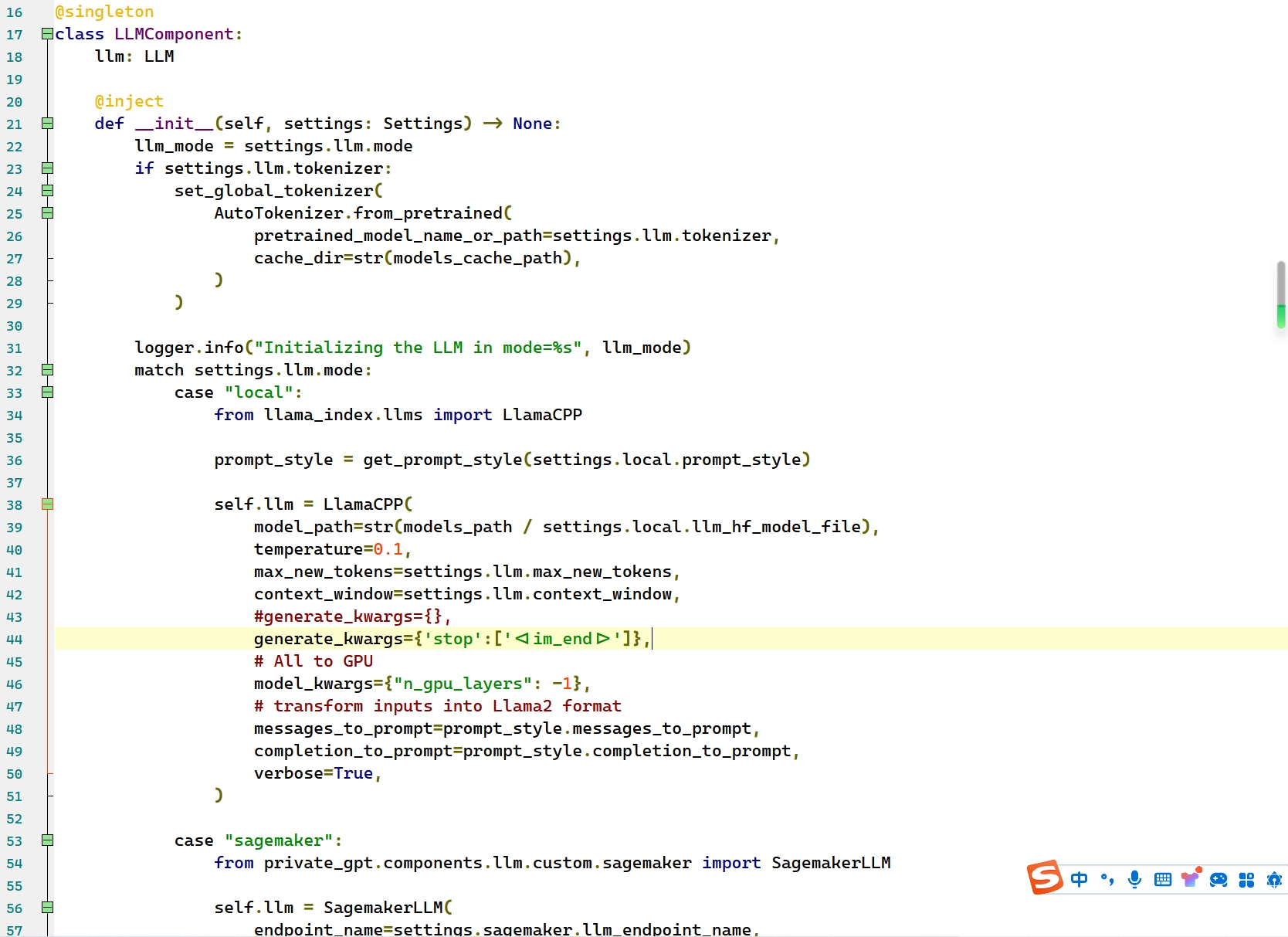
第44行,添加如下内容:
generate_kwargs={'stop':['<|im_end|>']},如图:
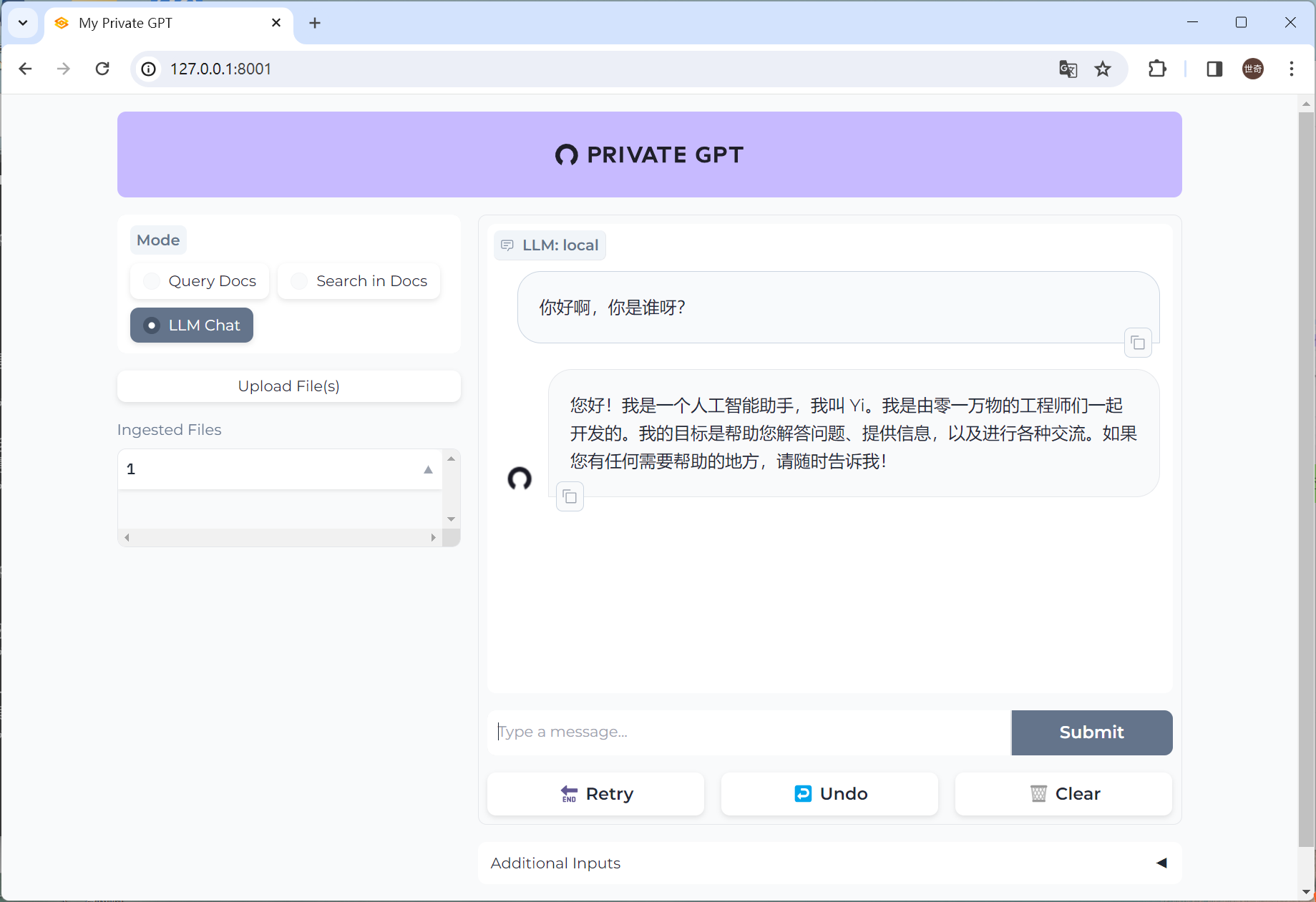
导航到 UI:在浏览器中打开 http://localhost:8001/。
原理解析
这套方法使用了 LangChain, GPT4All, LlamaCpp, Chroma and SentenceTransformers.
LangChain 用来生成文本向量,Chroma 存储向量。GPT4All、LlamaCpp用来理解问题,匹配答案。基本原理是:问题到来,向量化。检索语料中的向量,给到最相似的原始语料。语料塞给大语言模型,模型回答问题。基本原理和chatpdf没大差别。
创建自己的模型
Llama2 模型使用16位浮点数作为权重进行训练。我们可以将其缩小到4位整数以进行推理,而不会失去太多的功率,但会节省大量的计算资源(特别是昂贵的 GPU RAM)。这是已经被证实的。这个过程叫做量化。
GGUF格式专为 LLM 推理设计。它支持 LLM 任务,如语言编码和解码,使其比 PyTorch 更快、更容易使用。
使用 convert.py 实用程序将一个 PyTorch 模型转换为 GGUF 。你只需给出包含 PyTorch 文件的目录。这里的 GGUF 模型文件是完整的16位浮点模型
Llama2 模型,可以使用 llama.cpp 将其转换并量化为 GGUF,使用 convert.py 实用程序将一个 PyTorch 模型转换为 GGUF,quantize 命令行工具量化 FP16 GGUF 文件。下面的命令使用5位 k-量化创建一个新的 GGUF 模型文件。你可以在自己的应用程序中使用 GGUF 模型文件,或者在 Huggingface 上与全世界分享你的模型
构建自己的私人GPT
privateGPT中如何使用国产YI-34B-CHAT模型
如何创建 GGUF 模型文件?
全面了解 PrivateGPT:中文技巧和功能实测


)
:如何将一台电脑上的Elasticsearch服务迁移到另一台电脑上)





方法,报错Error: EPERM: operation not permitted)








,父调子方法(defineExpose))
