一、克隆三台主机(hadoop102 hadoop103 hadoop104)
以master为样板机克隆三台出来,克隆前先把master关机
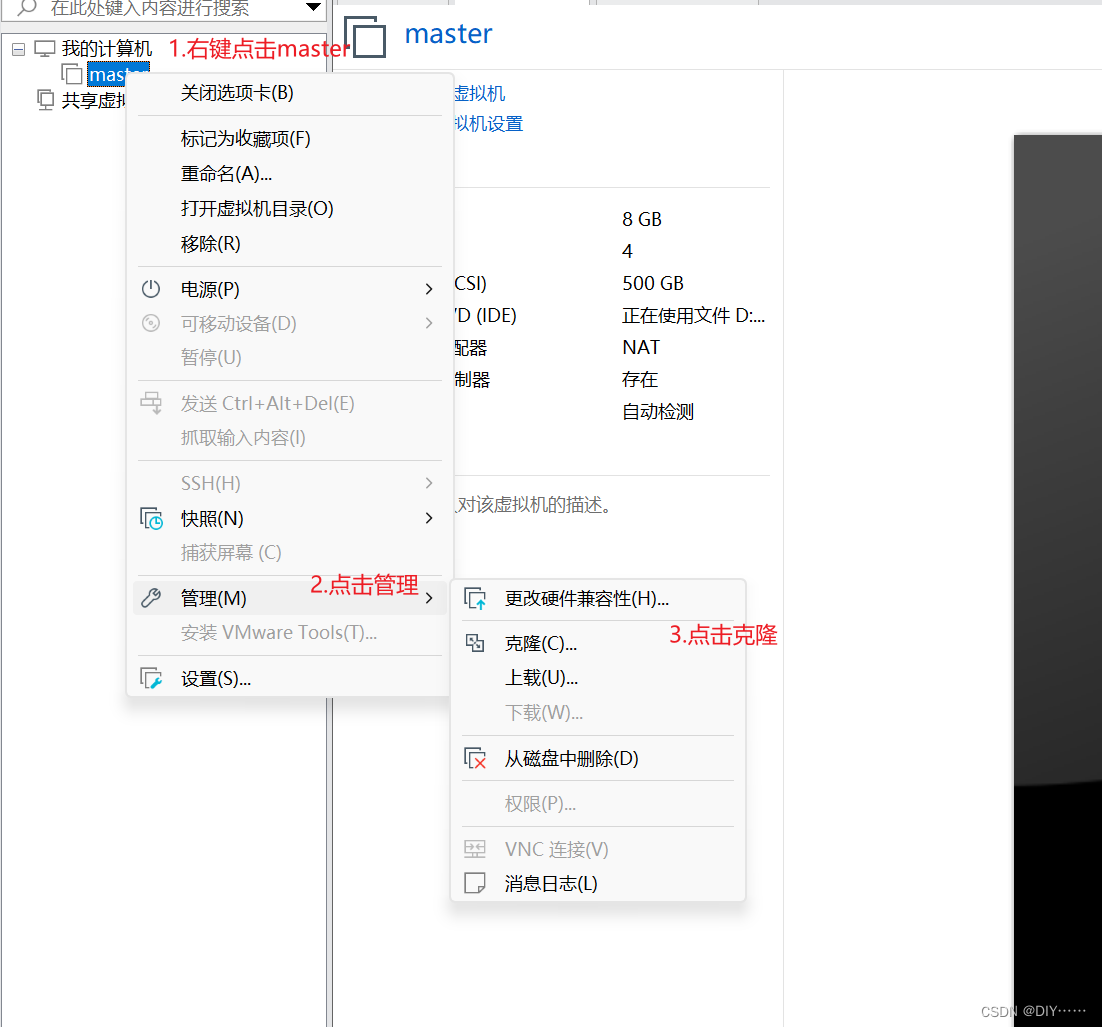
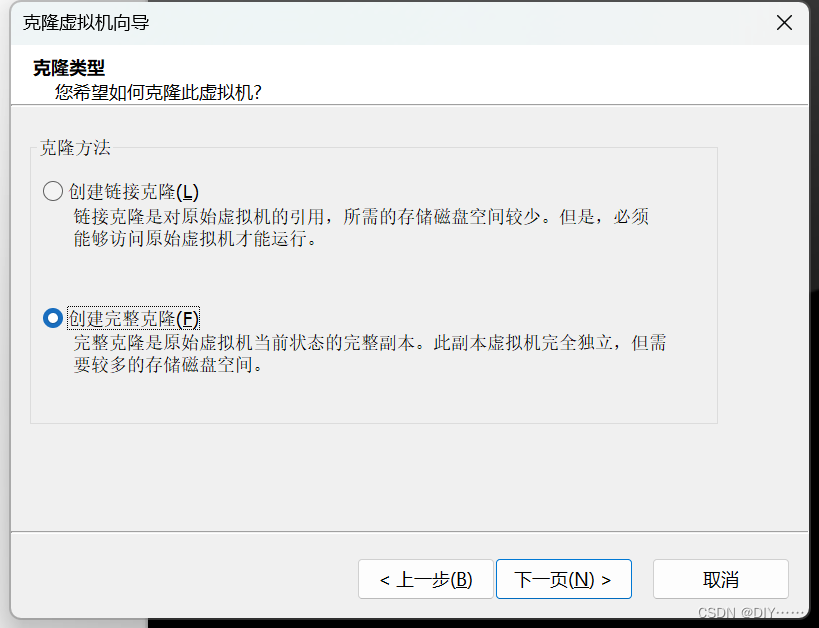
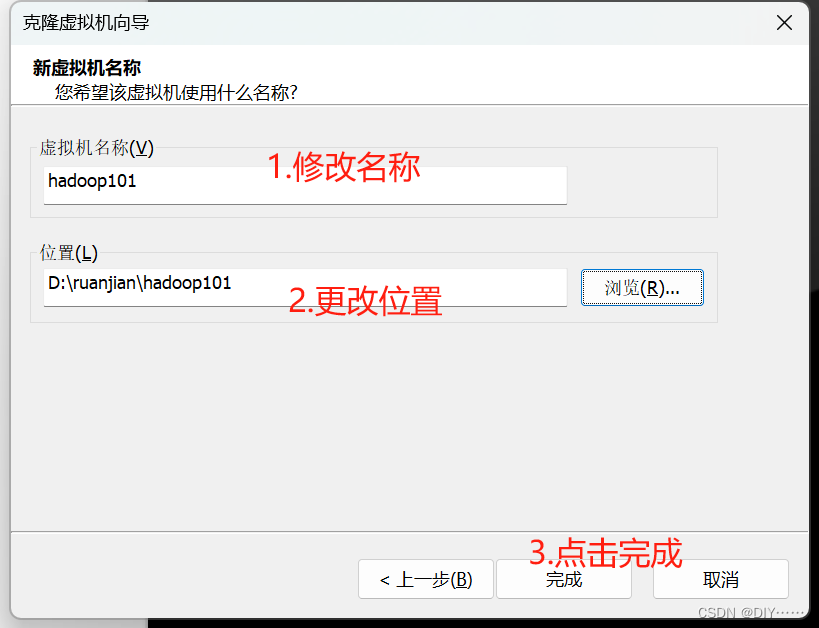
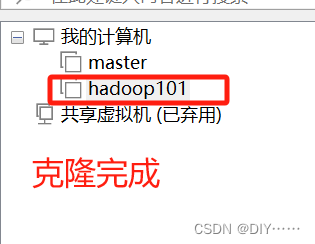
按照上面的步骤克隆其他两个就可以了,记得修改ip和hostname
二、编写集群同步脚本
- 在/home/attest/ 创建bin目录,在/home/attest/bin目录下创建集群同步脚本
#!/bin/bash#1. 判断参数个数
if [ $# -lt 1 ]
thenecho "Not Enough Arguement!"exit
fi#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done
- 给脚本添加执行权限

- 测试脚本
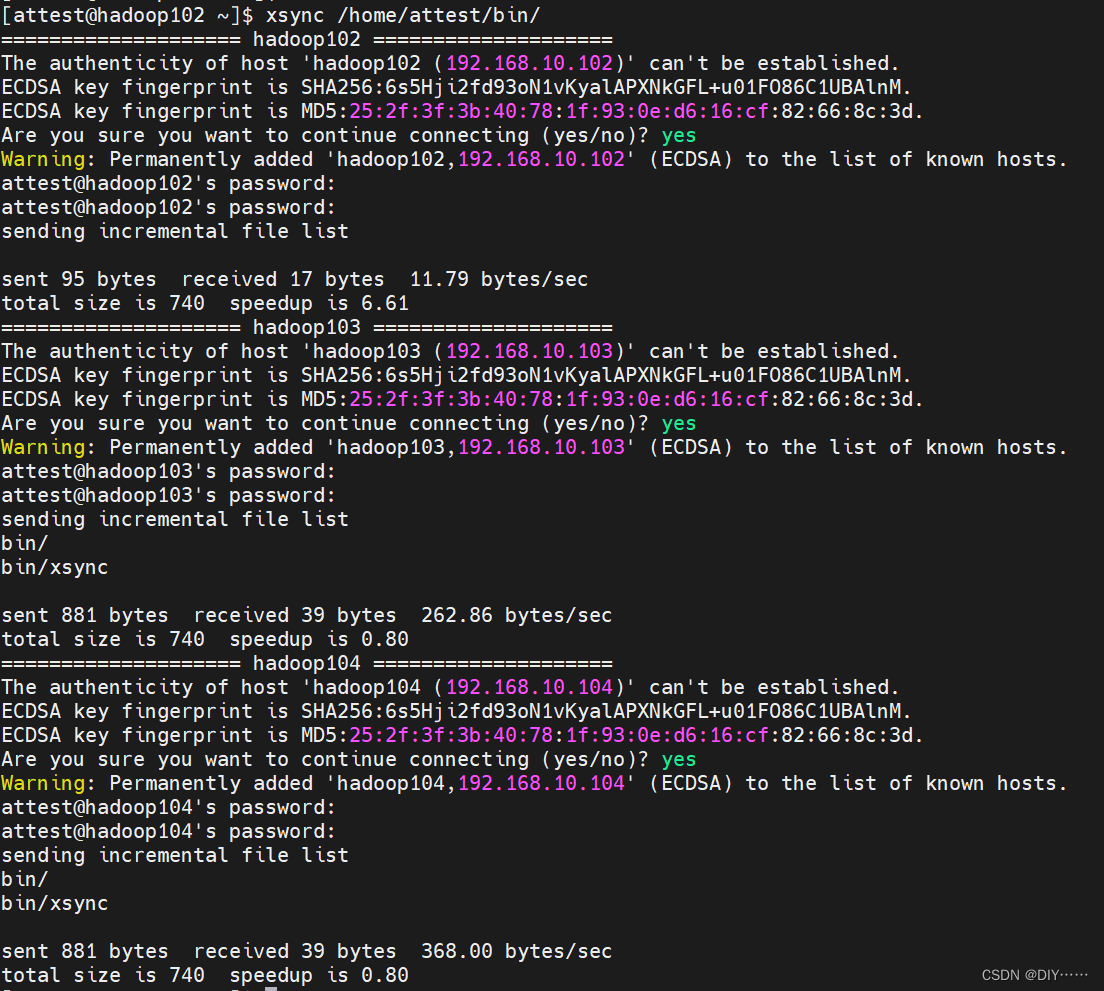
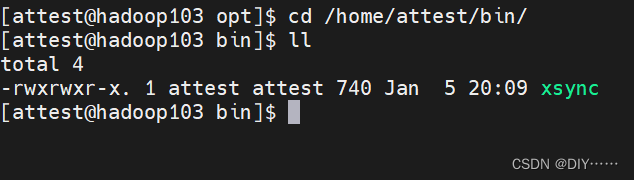

测试成功
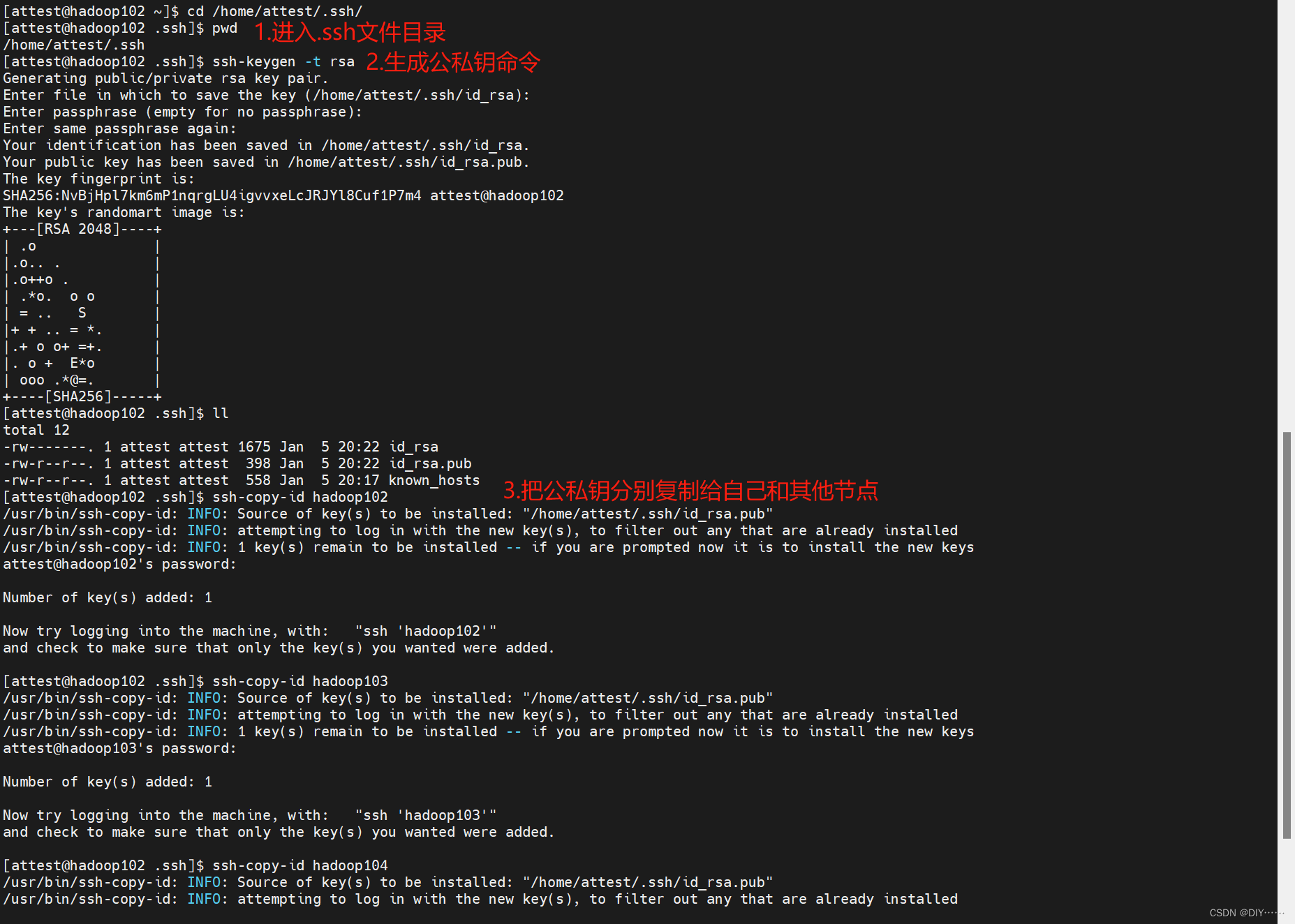
- SSH无密登录配置
二、集群配置
集群规划如下:

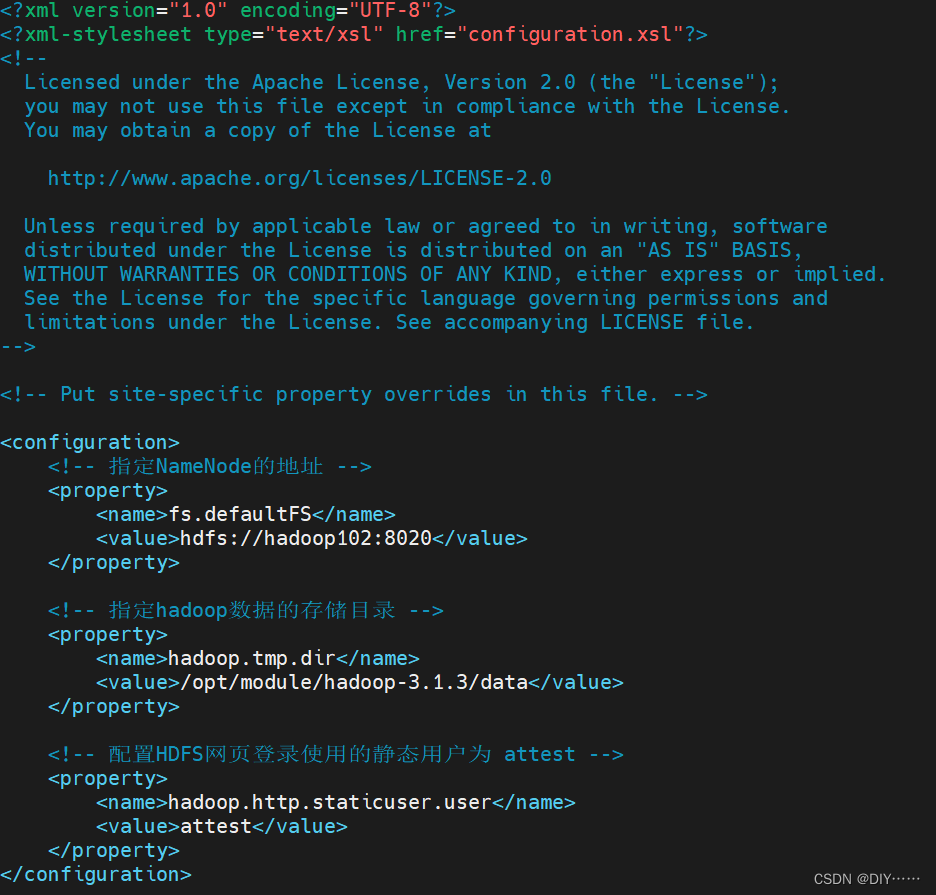
- 配置core-site.xml
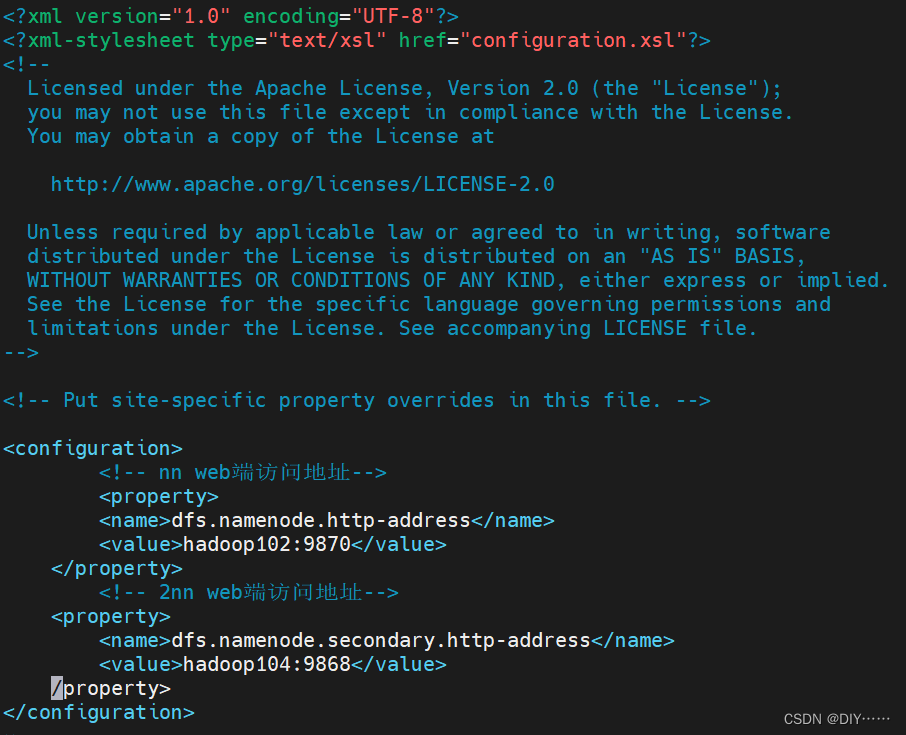
- 配置hdfs-site.xml(还是在原来的目录下)
- 配置yarn-site.xml(还是在原来的目录下)
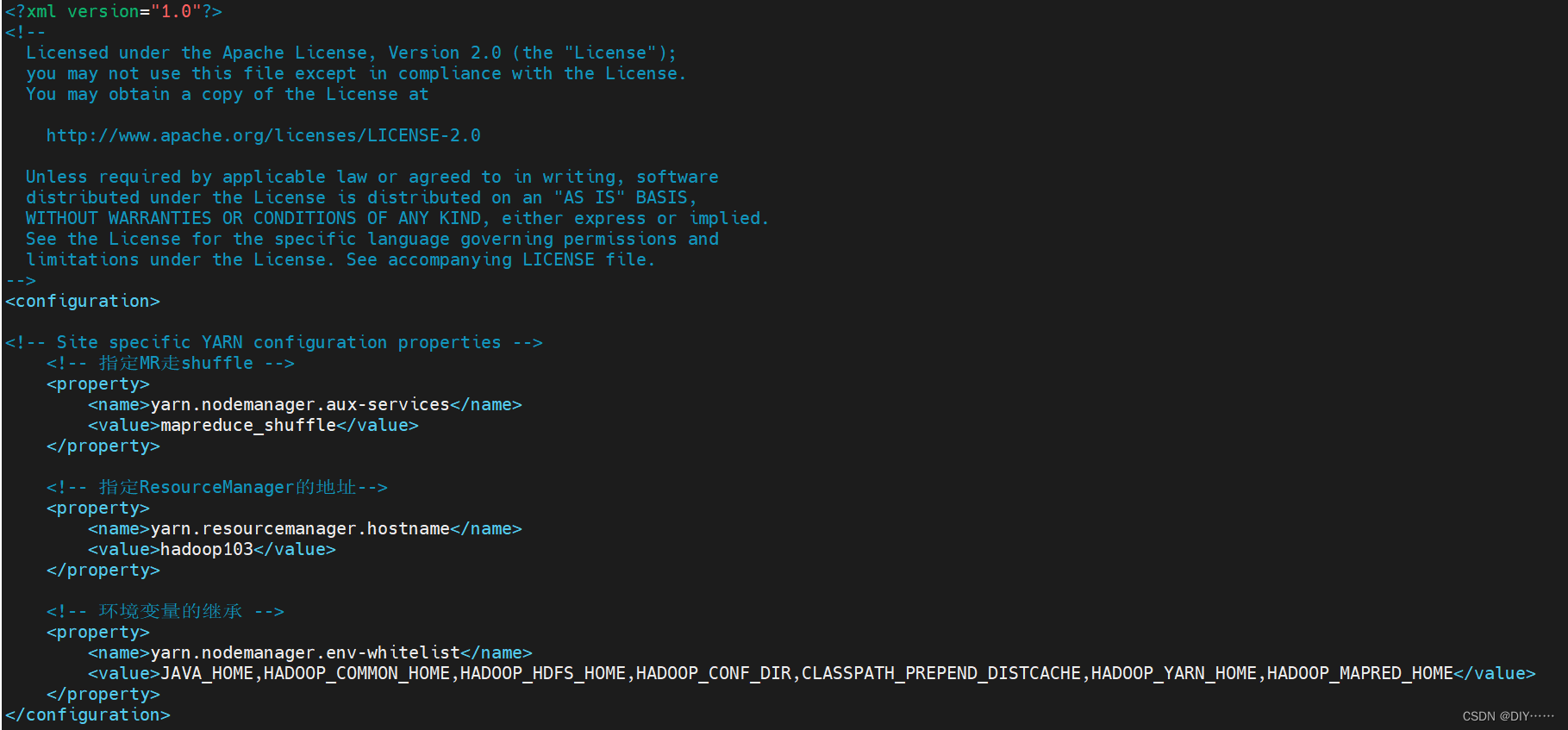
- 配置mapred-site.xml(还是在原来的目录下)

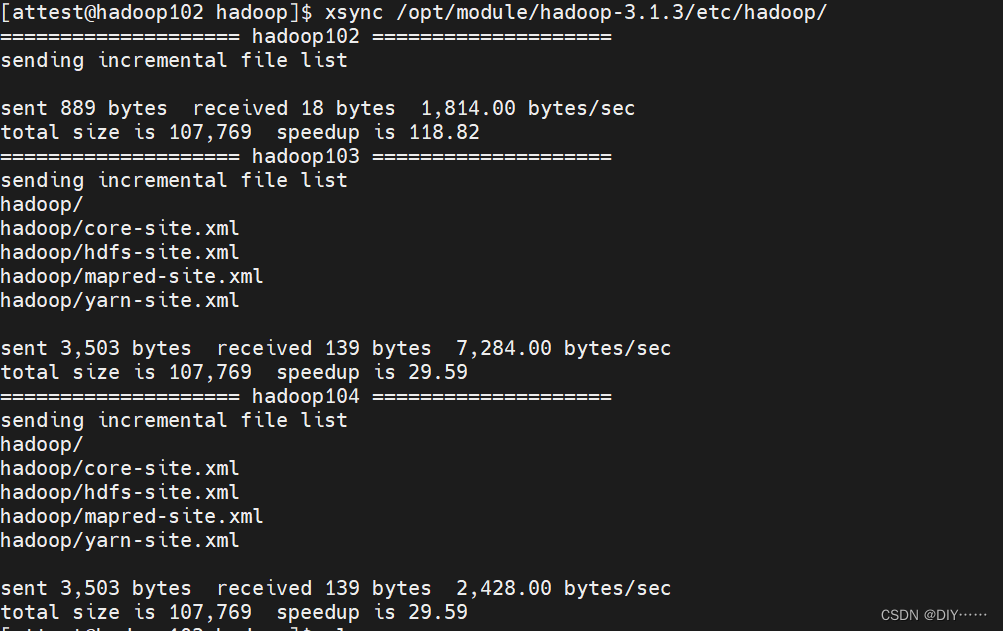
- 分发文件
- 配置workers

分发文件

三、启动集群
- 启动HDFS
第一启动需要初始化NN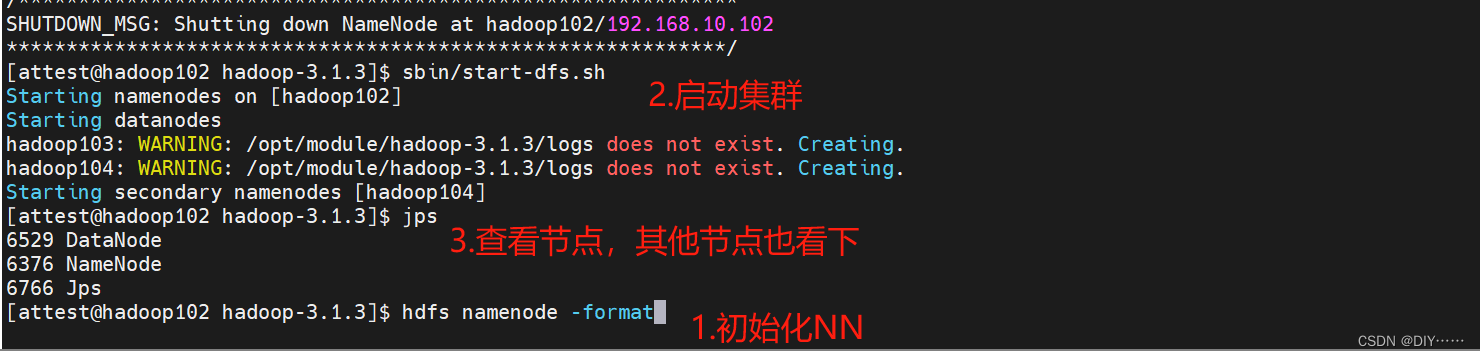
- 启动yarn
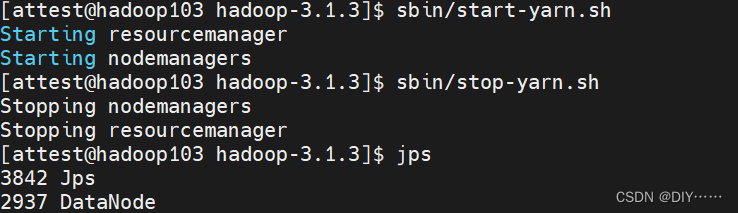
四、配置历史服务器
- 配置mapred-site.xml
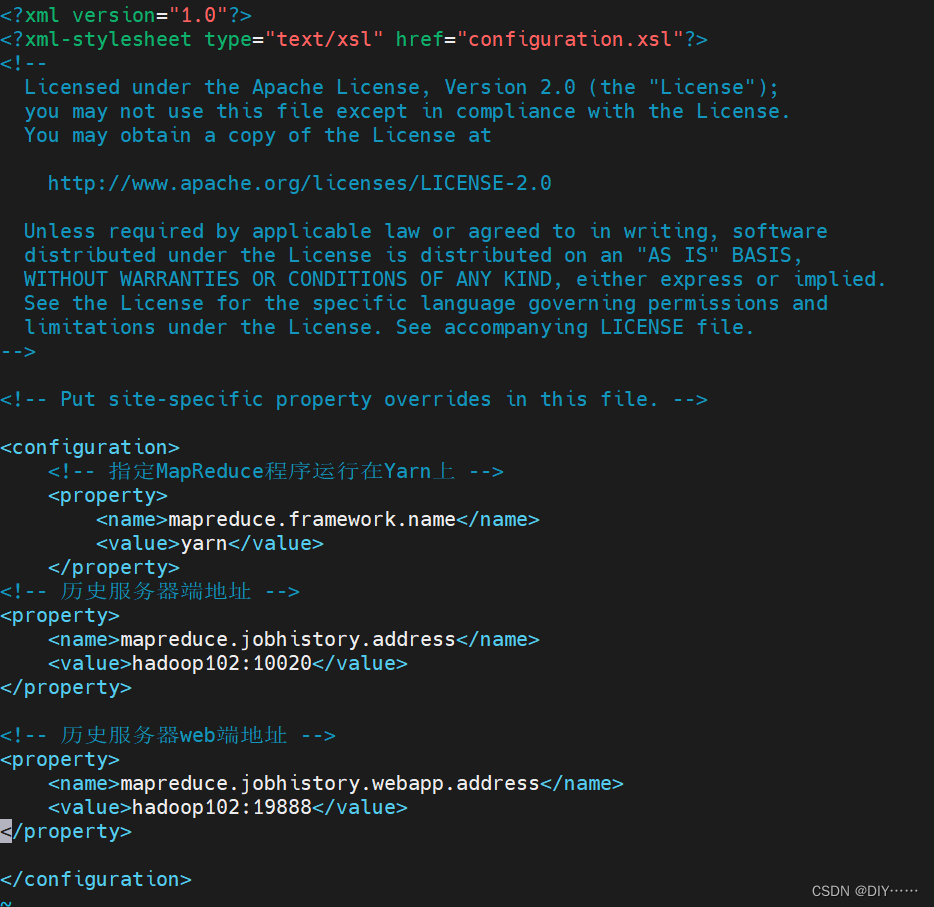
- 在hadoop102启动历史服务器

- 配置日志的聚集,配置yarn-site.xml
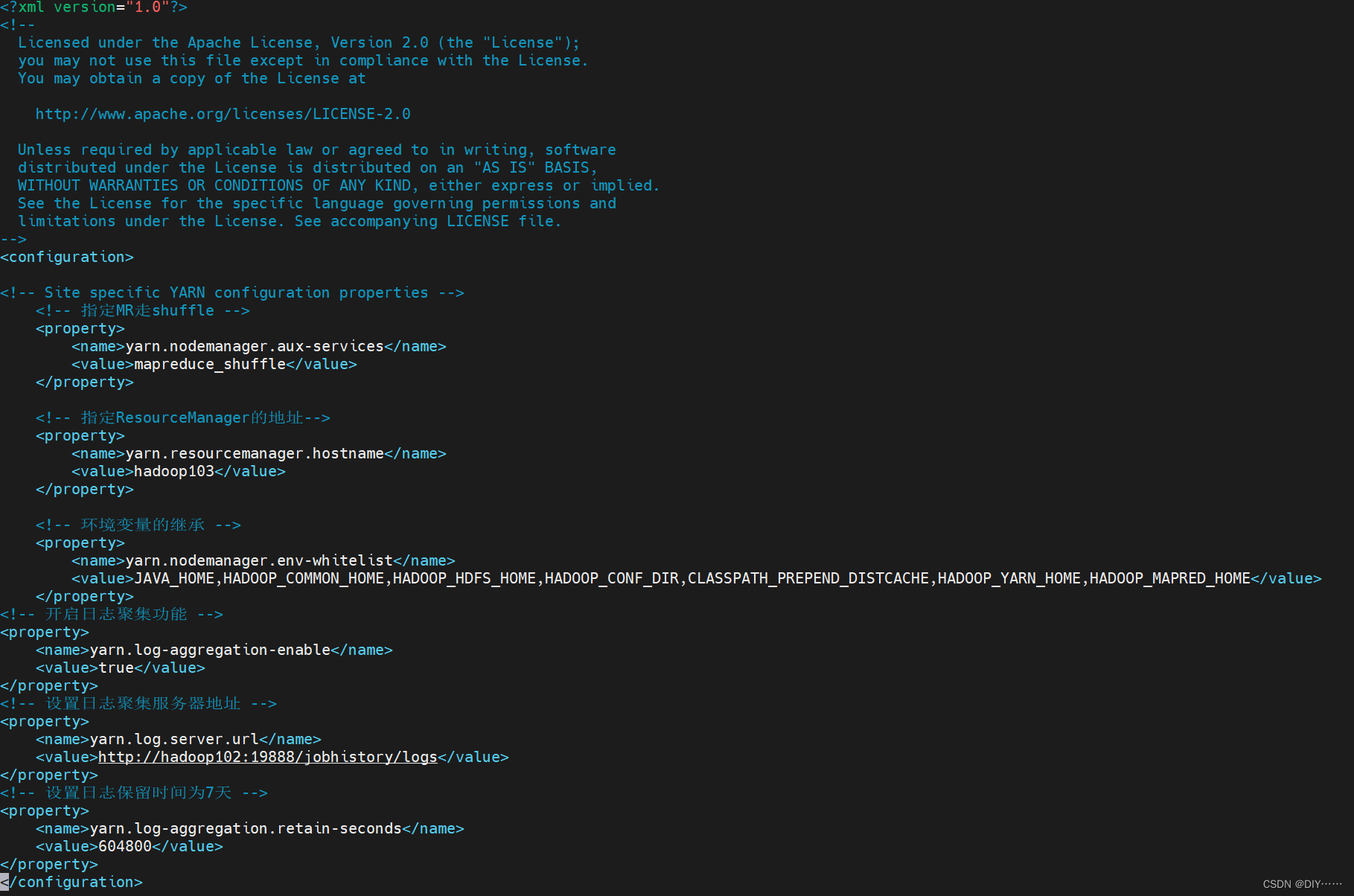
- 关闭HistoryServer

- 集群时间同步
查看hadoop102服务状态和开机自启动状态(如果开着就关掉)


修改hadoop102的ntp.conf配置文件
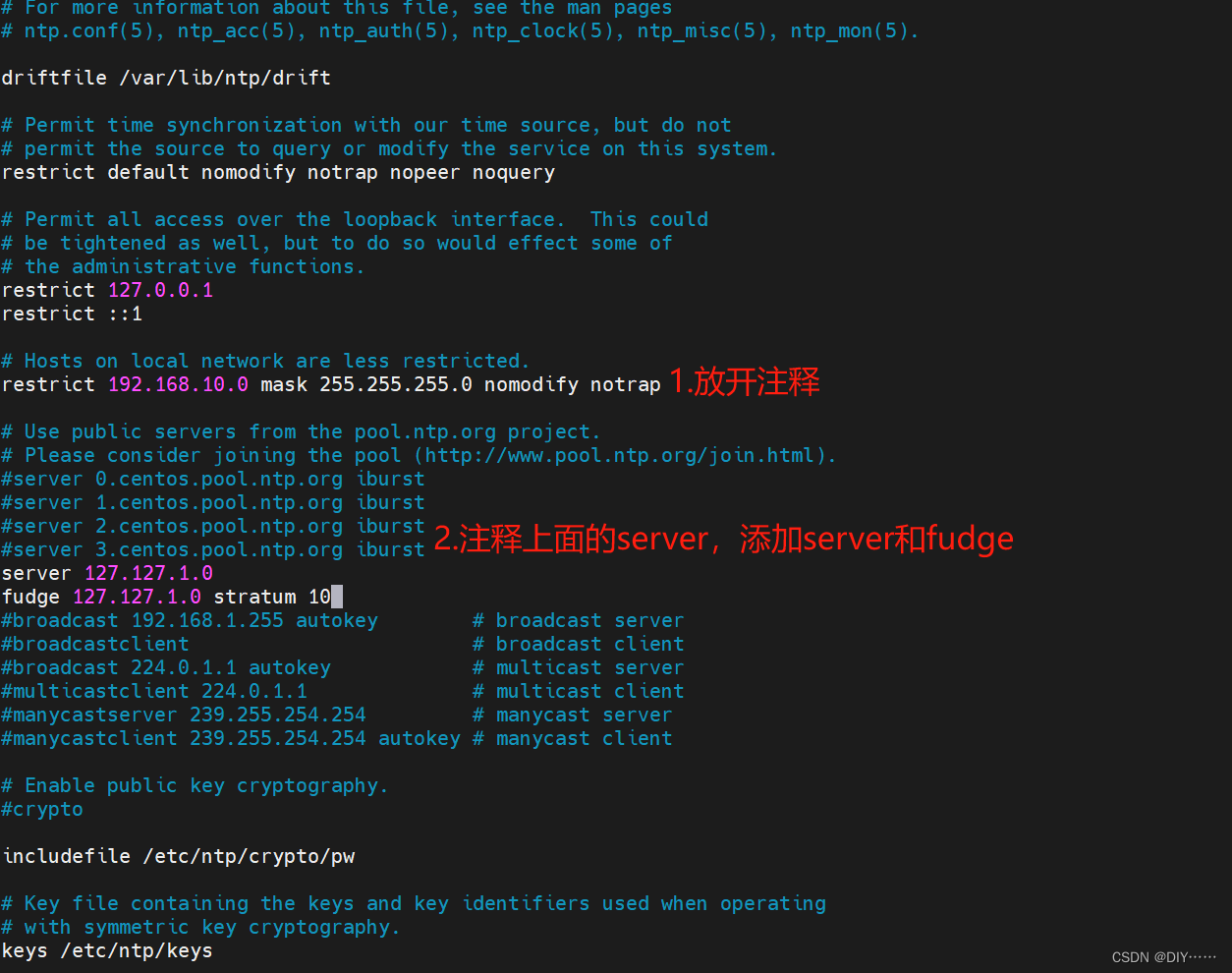
修改hadoop102的/etc/sysconfig/ntpd 文件

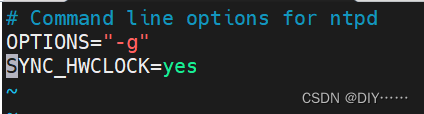
重新启动ntpd服务

关闭其他节点上ntp服务和自启动(使用root用户)


在其他机器配置1分钟与时间服务器同步一次



——硬件外设操作)



——redis、Lettuce、Redisson使用)






)





