gRPC 为什么这么快?
本文转自 公众号 ByteByteGo,如有侵权,请联系,立即删除
RPC(Remote Procedural Call, 远程过程调用)之所以被称为 remote,因为在微服务架构下,RPC 可以实现远程服务之间的通信。从服务调用者的角度来看,它就像一个本地函数调用。
下图说明了 gRPC 的数据流。
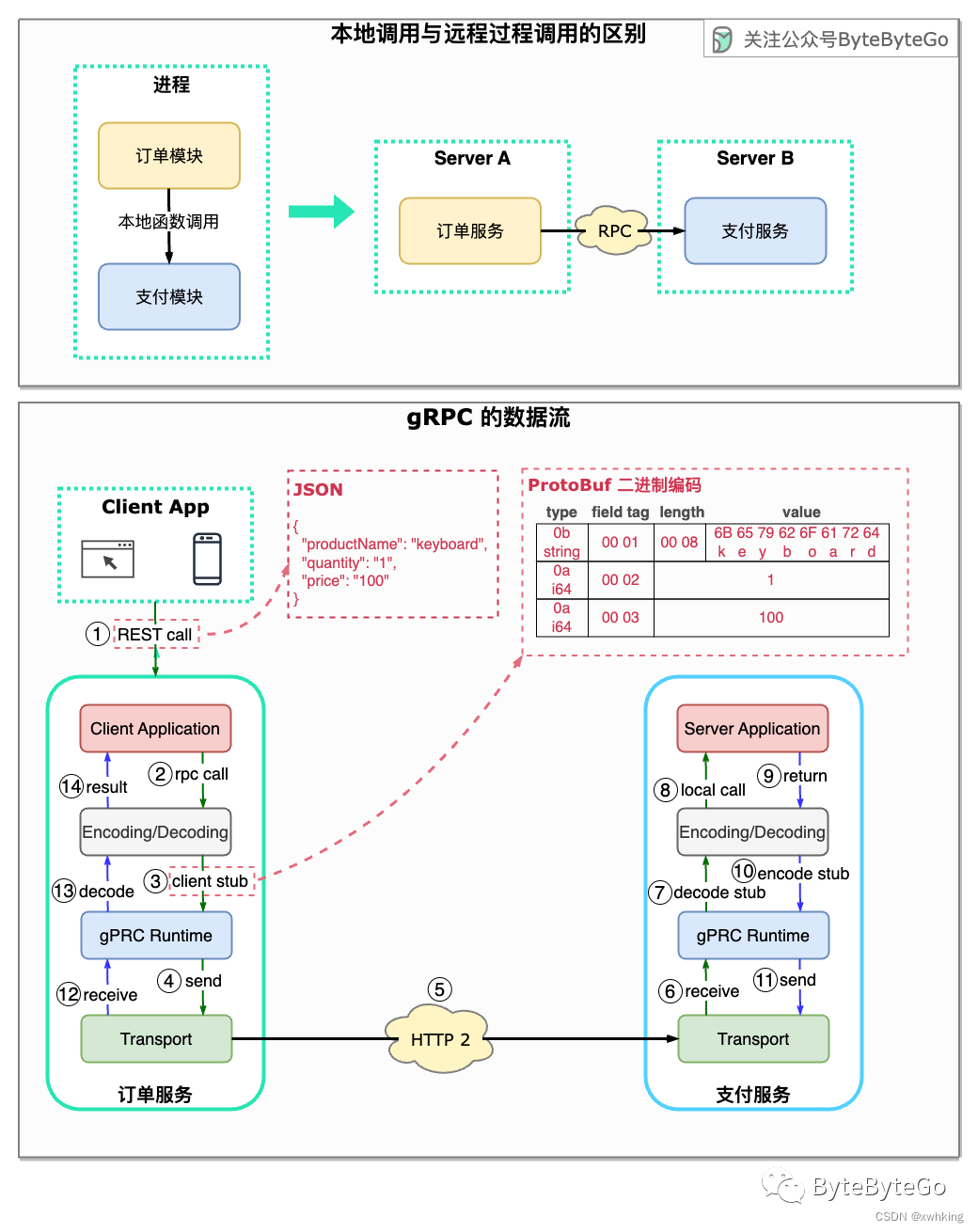
- 步骤 1:客户前端发出 REST 调用。请求体通常为 JSON 格式。
- 步骤 2-4:订单服务(gRPC 客户端)接收 REST 调用,对其进行转换,然后向支付服务发出 RPC 调用。gPRC 将 client stub 编码为二进制格式,并将其发送到底层传输层。
- 步骤 5:gRPC 通过 HTTP2 在网络上发送数据包。由于采用了二进制编码和网络优化,gRPC 据说比 JSON 快 5 倍。
- 步骤 6 - 8:支付服务(gRPC 服务器)接收来自网络的数据包,解码后调用服务器应用程序。
- 步骤 9 - 11:结果从服务器应用程序返回,经过编码后发送到传输层。
- 步骤 12 - 14:订单服务接收数据包、解码并将结果发送给客户端应用程序。
和广泛用于前后端通信的 REST 相比,gRPC 普遍用于服务间通信。并且,REST 不是一个协议,它只是一个基于 HTTP 协议的设计范式。gRPC 针对传输层和数据编解码都进行了优化,使得它的效率更高。
虽然 RPC 调用在微服务中被广泛采用,神书 DDIA (Designing Data-Intensive Applications) 中列举了一些 RPC 的局限性:
- 本地函数调用的结果是可预测的,而 RPC 需要经过网络传输,数据在中途可能因为各种原因丢失。
- RPC 调用有可能超时,编写程序时需要考虑该情况。
- 重试一个失败的 RPC 调用有可能造成数据重复,需要考虑幂等。
- 由于传输数据时需要序列化和反序列化,RPC 在传输复杂对象时会不太方便。
正是因为这些原因,让远程调用看上去像是一个本地调用的编程思想值得商榷。开发者在使用 RPC 时需要有针对性地进行容错处理。
















)

)
