目录
- 概述
- 架构
- HDFS
- 副本
- HDFS数据写入流程
- NN 工作原理
- DN 工作原理
- 结束
概述
官方文档快递
环境:hadoop 版本 3.3.6
相关文章速递
架构
HDFS

HDFS 架构总结如下:
- a master/slave architecture 一主多从架构
- a file is split into one or more blocks and these blocks are stored in a set of DataNodes 一个文件会被拆分成1或者多个 block (块),然后存储在 DN 上
- NameNode:NN
- file system namespace 文件系统命名空间
- 执行文件系统的命名空间操作:打开、关闭、重命名文件或者文件目录
- 记录数据 block (块) 对应的 DN
- DataNode:DN
HDFS 组件职责
- NN
- 维护和管理文件系统的命名空间
- 副本策略
- Block 的映射信息
- 处理客户端读写请求
- DN
- 存储 Block
- 真正执行数据块的读写操作
- Client
- 与 NN 交互,获取到文件的元数据信息
- 与 DN 交互,执行数据块的读写操作
- 管理 HDFS
- SNN:Secondary NameNode
- 不是 NN 的热备
- 分担一些 NN 工作量:定期合并 FsImage Edits 完成后推送到 NN
- Block
- hadoop3.x 默认大小 128M
副本
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode in the same rack as that of the writer, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack.
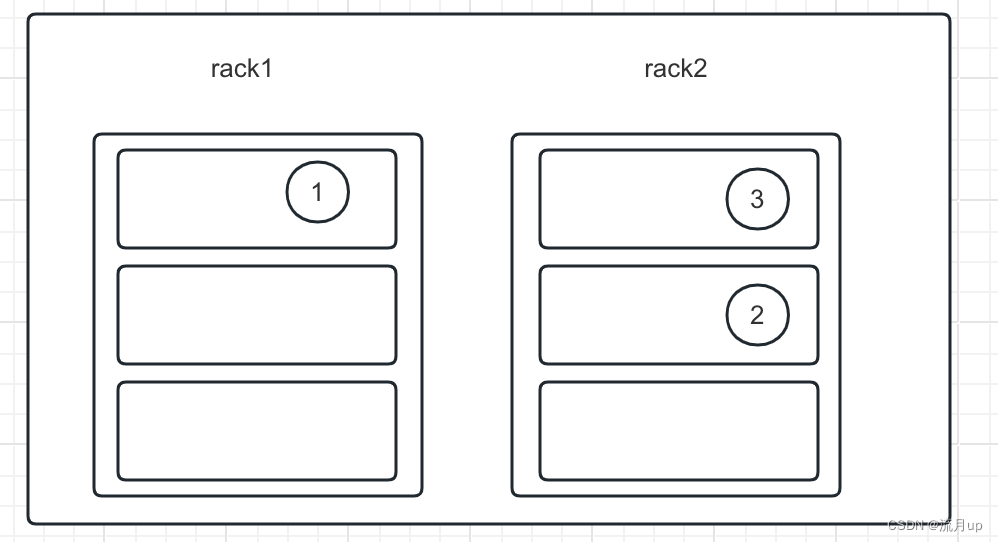
上述两个机架,一个机架三台机器。
通常情况下,副本因子为3
- 第一个副本:client 所处的节点上,如果 client 在集群外,在相同机架上(rack)随机选择一个
- 第二个副本:在另外一个机架上随机选择一个节点
- 第三个副本:在第二个副本所在机架上随机选择一个节点(与二个副本不在一个节点)
HDFS数据写入流程
先来张图,如下
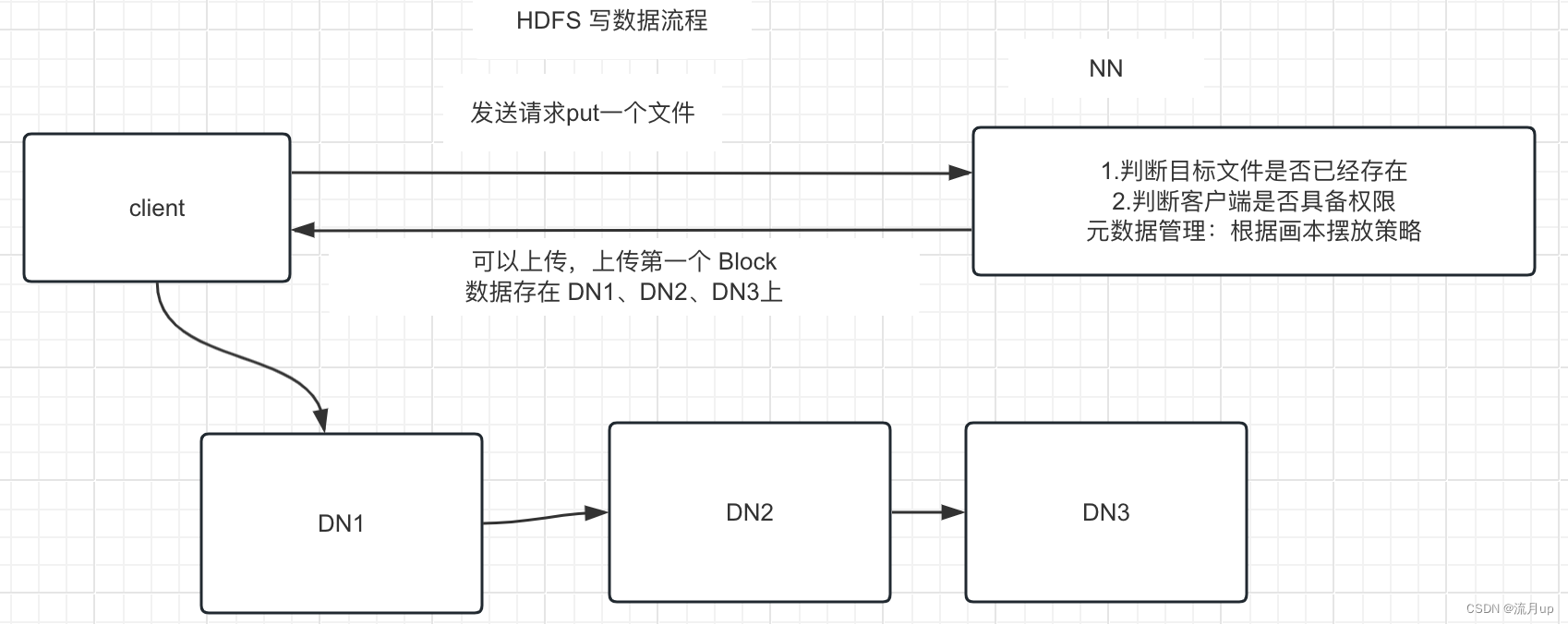
- 客户端发送请求 put 一个文件,由 NN 根据元数据判断文件是否存在,是否具备权限,根据副本摆放策略,返回响应数据给 client 端
- client 根据响应数据,将第一个 block 写入 DN1 , DN1、DN2、DN3 之间会同步数据,而不是由 client 执行
NN 工作原理
老规矩上个图易理解
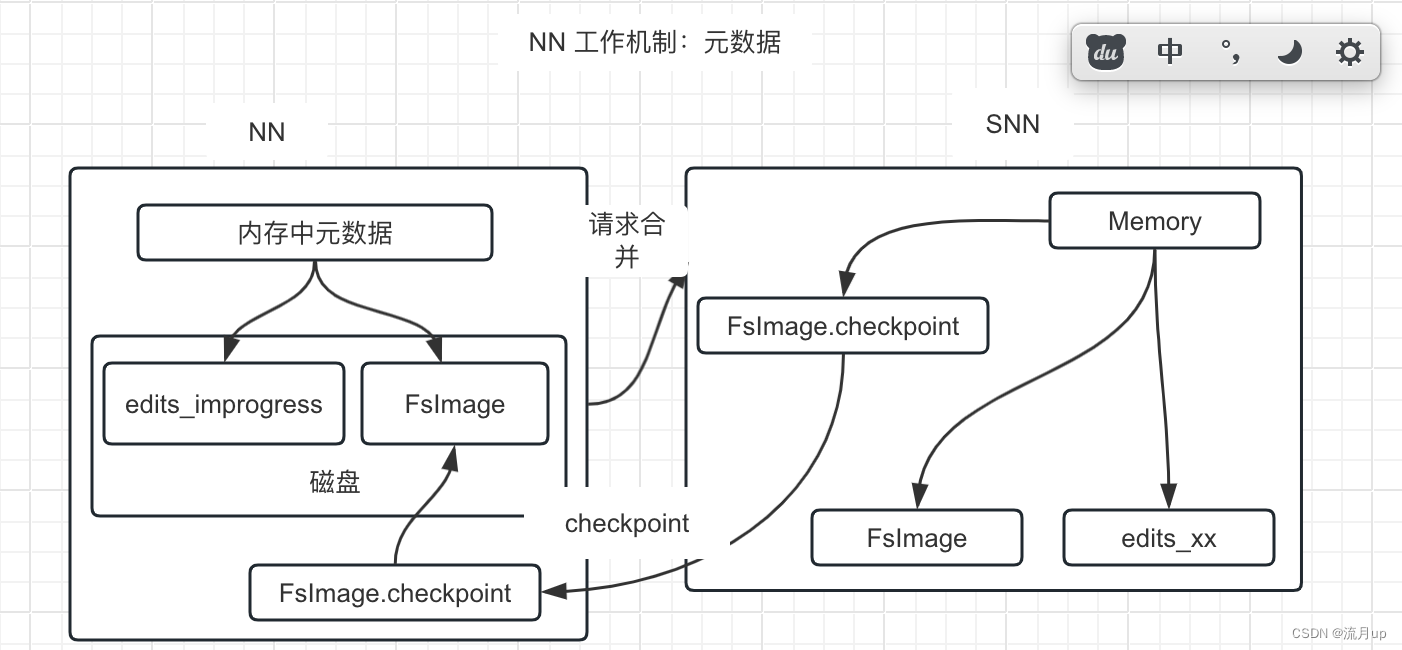
重点总结如下:
- NN 元数据采取的是 内存+磁盘的方式管理
- FsImage
- Edits 每次操作都以追加的方式写入日志
- 完整的元数据信息 = FsImage + Edits
- 相关配置
- dfs.namenode.checkpoint.txns
- dfs.namenode.checkpoint.period
DN 工作原理
老规矩上图
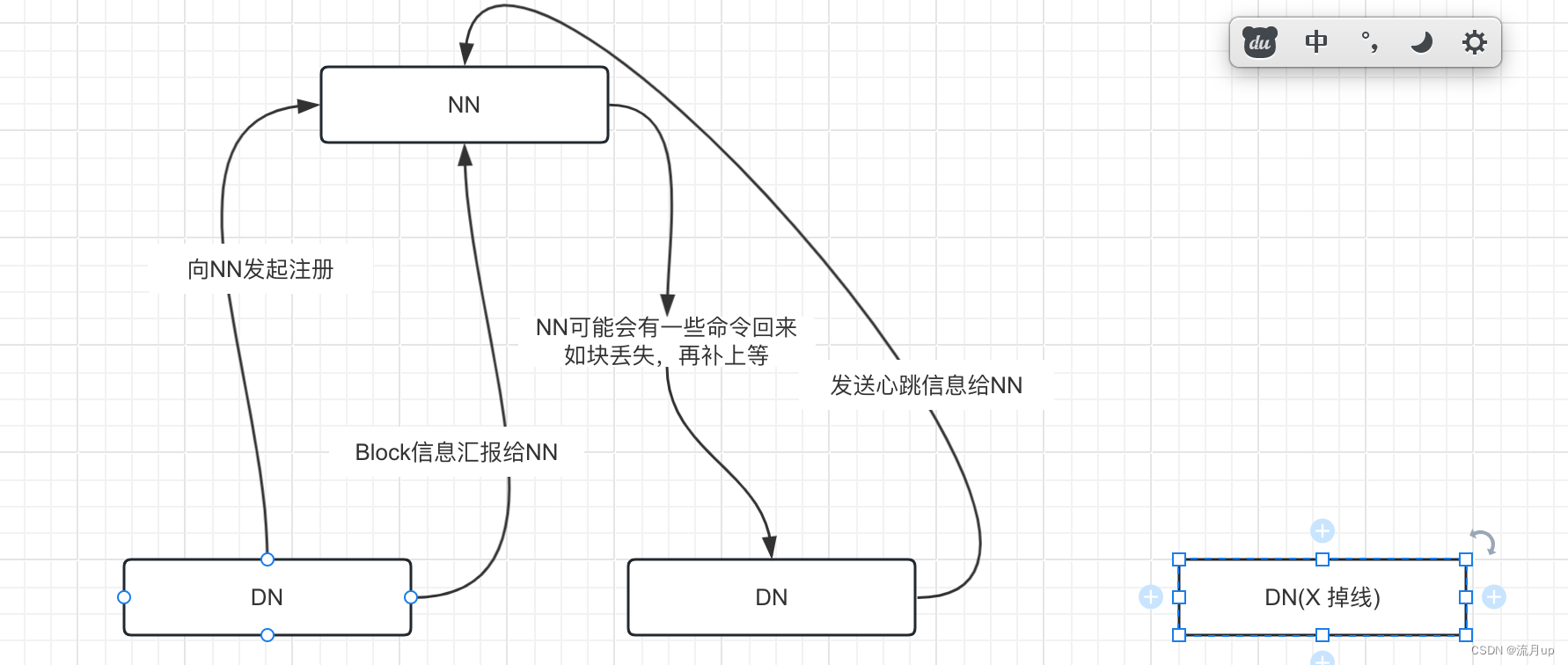
- 向 NN 发起注册
- Block 信息汇报
- dfs.blockreport.intervalMsec
- DN 发起心跳
- dfs.heartbeat.interval (默认 3秒)
- dfs.namenode.heartbeat.recheck-interval (再次 recheck 默认 5分钟)
- 超时掉线 10分钟30秒 检测不到心跳,直接掉线
- timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
结束
至此,HDFS 架构 就结束了,如有疑问,欢迎评论区留言。





el-popover鼠标移入提示效果)




)



 车载用)

:数据导出的其他导出案例参考)
)

)