参考
- 【Git学习笔记】逃不掉的merge和rebase-腾讯云开发者社区-腾讯云
- git merge 和 git rebase - 知乎
- git cherry-pick 教程 - 阮一峰的网络日志
简单理解各种合并的方法
- 线性合并,使用 rebase —— feature 分支开发,提交前拉取 master 最新改动进行合并
- 保留合并历史,使用 merge,会产生一个新的 commit —— master 分支合并 feature
- 挑选别的分支某几个 commit 进行合并,使用 cherry-pick
git rebase 使用场景 —— 线性合并
- 本地 feature 分支开发完成后,想要给远端 master 提交一个合并的 PR,此时发现远端 master 分支已经提交了很多 feature,就是本地 master 分支落后远端 master 分支多个 commit
# 1. 备份,将当前分支 feature 推到远端
git push origin feature# 2. 切换到本地 master 分支,并拉取远端最新 master
git checkout master
git pull origin master# 3. 切换到自己 feature 分支,采用 rebase 合并,不像 merge 会产生新分支
git checkout feature
git rebase master # 直接执行 esc :q 就行
# 若有冲突就进行解决,之后再执行 git rebase --continue
# 合并完成后,git log 会发现本地 feature 分支已合并了远端 master 分支新增的 commit,
# 本地 feature 开发提交的 commit 会在远端 master 新增 commit 之后,不会产生新的 commit,是线形的# 4. 推送到远端,覆盖
git push origin feature --force# 5. 提交 pr 到远程仓库的 master 分支# 注意
# git rebase ,想要合并到哪个分支,就先切换到那个分支,然后执行 git rebase {另一个分支名}
# 如,有两个分支 A 和 B,A 想要 B 分支的新增 commit
git checkout A
git rebase B
# git log 查看历史就是 A和B 共同的 commit --> B-commit --> A-commit(HEAD)
+---------------+ +---------------+
------->| master branch |------>| new commit-A |+---------------+ +---------------+| | v +---------------+ +---------------+
------->|featrue branch |------>| commit-B |+---------------+ +---------------+# git pull origin master
# git checkout feature
# git rebase master
# 通过 git log --graph 即可看到合并历史信息,如下是个线形的,但没有清楚记录从哪个分支合并的(merge 可以记录)+---------------+ +---------------+ +---------------+
------->|featrue branch |------>| new commit-A |------>| commit-B |+---------------+ +---------------+ +---------------+
git rebase 使用场景 —— 保留合并历史
- 假设 A,B 两个人,都是基于当前 master 分支进行开发,开发不同的功能,但是可能会对相同文件进行改动(也可能不会)
- A 首先完成,提交 pr 到 master 分支,master 分支维护者进行合并,这时候没有冲突,直接合并,但会产生一个新的 merge commit(该 commit 无文件更改,就是个说明)
- 这时候 B 也完成了,提交 pr 到 master 分支,master 分支维护者进行合并,这时候可能会有冲突,解决后,也会产生一个新的 merge commit(该 commit 可能文件更改,解决冲突)
- 可以看到下面
# git checkout master
# git merge A (合并 A 分支到 master 分支)
# 生成一个 merge commit A
# git merge B (合并 B 分支到 master 分支)
# 生成一个 merge commit B
# 可以看到下面记录了 合并的历史信息 ,通过 git log --graph 即可看到合并历史信息+---------------+ +---------------+ | A branch |------>| commit-A |--------+ +---------------+ +---------------+ | ^ | | v +---------------+ +---------------+ +---------------+
------->| master branch |----------------------->|merge-commit-A |---->|merge-commit-B |+---------------+ +---------------+ +---------------+| ^ v | +---------------+ +---------------+ | | B branch |----------->| commit-B |-------------------------+ +---------------+ +---------------+
git cherry-pick 使用场景 —— 挑选 commit 进行合并
- 上面 merge 和 rebase,都是将所有新增的 commit 进行合并
- 那么若只想挑选几个 commit 进行合并呢? —— cherry-pick 应运而生
- 若 A 分支新增了几个 commit,如 commit-a1、commit-a2、commit-a3、commit-a4
# 现 master 分支只想要 commit-a2
git checkout master
git cherry-pick commit-a2
git cherry-pick --continue# 现 master 分支想要 a2到a4 的commit
git checkout master
# 范围符号是两个点 ..
# 注意! 首个commit一定要有 ^ 符号,否则不包含 首个 commit
# 如 commit-a2..commit-a4 表示合并 commit-a3 、 commit-a4 到 master 分支
git cherry-pick commit-a2^..commit-a4
git cherry-pick --continue
rebase 和 merge 的基本原则
-
【Git学习笔记】逃不掉的merge和rebase-腾讯云开发者社区-腾讯云
-
git merge 和 git rebase - 知乎
-
下游分支更新上游分支内容的时候使用 rebase;
-
上游分支合并下游分支内容的时候使用 merge;
在 dev 上开发了一段时间后要把 master 分支提交的新内容更新到 dev 分支,此时切换到 dev 分支,使用 git rebase master,等 dev 分支开发完成了之后,要合并到上游分支 master 上的时候,切换到 master 分支,使用 git merge dev。
因为自己一直用的都是merge,以前完全没听过还有rebase这个命令
后来被问了,一脸懵逼,所以研究了一下,才发现rebase好像也有点东西
git merge
先构造一下环境
git init# mater初始化提交
touch master.txt
git add .
git commit -m "init master"# master第一次提交
# master.txt第一行加个1
git add .
git commit -m "commit 1"# 拉取feature分支
git branch feature# master第二次提交
# master.txt第二行加个2
git add .
git commit -m "commit 2"# master第三次提交
# master.txt第三行加个3
git add .
git commit -m "commit 3"# 到feature分支,进行提一次冲突提交
# master.txt第二行加个feature change1
git switch feature
git add .
git commit -m "confict1"# 进行提一次冲突提交
# master.txt第三行加个feature change2
git add .
git commit -m "confict2"
好了这个时候准备工作就完成了
现在master要merge feature分支的更新
git switch master
git merge feature# 解决完冲突后git add .
git commit -m "merged feature"
这是 git merge的流程
我们可以来看下此时的log:
git log --graph --pretty=oneline


master上的日志分支出现了feature分支的提交
也就是说,merge的流程是,将分支的改动合并到当前分支后,再形成一个新的commit
这只是一条分支,一旦分支多了,merge多了,可以想象master的提交记录将会是多么可怕…
这个时候,如果单纯只是为了保持master分支的纯净,使其的日志以一条线性的方式存在,看起来就会比较清晰。
git rebase
顾名思义 —— 变基
我的理解就是将当前所在的分支作为目标分支的新基线
还是先来跑一下,新找个目录:
git init# mater初始化提交
touch master.txt
git add .
git commit -m "init master"# master第一次提交
# master.txt第一行加个1
git add .
git commit -m "commit 1"# 拉取feature分支
git branch feature# master第二次提交
# master.txt第二行加个2
git add .
git commit -m "commit 2"# master第三次提交
# master.txt第三行加个3
git add .
git commit -m "commit 3"# 到feature分支,进行提一次冲突提交
# master.txt第二行加个feature change1
git switch feature
git add .
git commit -m "confict1"# 进行提一次冲突提交
# master.txt第三行加个feature change2
git add .
git commit -m "confict2"
这个时候,用一下rebase:
# 切回master分支
git switch master# 使用rebase
git rebase -i feature# 解决冲突
这样rebase之后,我们用相同的方式来看下master的日志:

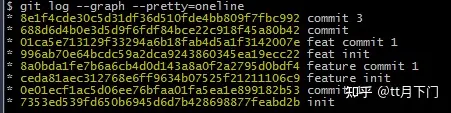
你看,就是完全线性的了
rebase的过程实际就是以当git 前最新的master的版本,再"拉"出一条分支作为当前最新的分支上,原先该分支上的改动就变成现在分支上的新的commit 了
单从master的提交记录来看,rebase之后的日志记录是线性的,肯定是舒适很多
那么问题来了:那不是都用rebase就好了吗,用啥merge操作呢?
使用场景是纯个人看法:
1、个人开发分支管理使用rebase
比如我们现在在feature分支上开发我们新功能,master正常迭代
feature开发到一半,master迭代的很多了,再不更新你的feature就会导致和master的偏移越来越大
这个时候获取最新的master代码,merge的话刚刚看了,别的分支的commit记录乱的一批全混到你的分支来了
重新拉一条分支,本地的改动备份还原又不方便
看来看去,rebase算是最好的选择了,可以线性化个人分支的commit
版本追溯起来更清晰,roll back 也更方便
2、master(公共分支)使用merge
这个我觉得应该没毛病,公共分支上的commit历史还是不能去篡改的,所以老老实实git merge --no-ff 好了
git cherry-pick
- git cherry-pick 教程 - 阮一峰的网络日志
一、基本用法
git cherry-pick命令的作用,就是将指定的提交(commit)应用于其他分支。
$ git cherry-pick <commitHash>
上面命令就会将指定的提交commitHash,应用于当前分支。这会在当前分支产生一个新的提交,当然它们的哈希值会不一样。
举例来说,代码仓库有master和feature两个分支。
a - b - c - d Master\e - f - g Feature
现在将提交f应用到master分支。
# 切换到 master 分支 $ git checkout master# Cherry pick 操作 $ git cherry-pick f
上面的操作完成以后,代码库就变成了下面的样子。
a - b - c - d - f Master\e - f - g Feature
从上面可以看到,master分支的末尾增加了一个提交f。
git cherry-pick命令的参数,不一定是提交的哈希值,分支名也是可以的,表示转移该分支的最新提交。
$ git cherry-pick feature
上面代码表示将feature分支的最近一次提交,转移到当前分支。
二、转移多个提交
Cherry pick 支持一次转移多个提交。
$ git cherry-pick <HashA> <HashB>
上面的命令将 A 和 B 两个提交应用到当前分支。这会在当前分支生成两个对应的新提交。
如果想要转移一系列的连续提交,可以使用下面的简便语法。
$ git cherry-pick A..B
上面的命令可以转移从 A 到 B 的所有提交。它们必须按照正确的顺序放置:提交 A 必须早于提交 B,否则命令将失败,但不会报错。
注意,使用上面的命令,提交 A 将不会包含在 Cherry pick 中。如果要包含提交 A,可以使用下面的语法。
$ git cherry-pick A^..B
三、配置项
git cherry-pick命令的常用配置项如下。
(1)-e,--edit
打开外部编辑器,编辑提交信息。
(2)-n,--no-commit
只更新工作区和暂存区,不产生新的提交。
(3)-x
在提交信息的末尾追加一行(cherry picked from commit ...),方便以后查到这个提交是如何产生的。
(4)-s,--signoff
在提交信息的末尾追加一行操作者的签名,表示是谁进行了这个操作。
(5)-m parent-number,--mainline parent-number
如果原始提交是一个合并节点,来自于两个分支的合并,那么 Cherry pick 默认将失败,因为它不知道应该采用哪个分支的代码变动。
-m配置项告诉 Git,应该采用哪个分支的变动。它的参数parent-number是一个从1开始的整数,代表原始提交的父分支编号。
$ git cherry-pick -m 1 <commitHash>
上面命令表示,Cherry pick 采用提交commitHash来自编号1的父分支的变动。
一般来说,1号父分支是接受变动的分支(the branch being merged into),2号父分支是作为变动来源的分支(the branch being merged from)。
四、代码冲突
如果操作过程中发生代码冲突,Cherry pick 会停下来,让用户决定如何继续操作。
(1)--continue
用户解决代码冲突后,第一步将修改的文件重新加入暂存区(git add .),第二步使用下面的命令,让 Cherry pick 过程继续执行。
$ git cherry-pick --continue
(2)--abort
发生代码冲突后,放弃合并,回到操作前的样子。
(3)--quit
发生代码冲突后,退出 Cherry pick,但是不回到操作前的样子。
五、转移到另一个代码库
Cherry pick 也支持转移另一个代码库的提交,方法是先将该库加为远程仓库。
$ git remote add target git://gitUrl
上面命令添加了一个远程仓库target。
然后,将远程代码抓取到本地。
$ git fetch target
上面命令将远程代码仓库抓取到本地。
接着,检查一下要从远程仓库转移的提交,获取它的哈希值。
$ git log target/master
最后,使用git cherry-pick命令转移提交。
$ git cherry-pick <commitHash>
(完)


——指令集-汇编基础)




)



-K8S源代码走读之Kube-Scheduler)
Sentinel简介)

)



Buffer的创建和销毁、扩容、写入数据)
)