simOTA是YOLOX中提出的
正负样本分配策略(OTA, SimOTA,TAS)
OTA源于2021年cvpr的论文,使训练和验证的标签有着更好的对应关系。
yolov5没有用到,只有一种loss:
from utils.loss import ComputeLoss
compute_loss = ComputeLoss(model) # init loss class
yolov7用到了,对应的loss:
from utils.loss import ComputeLoss, ComputeLossOTA
这里说yolov5改成simota以后可以提高6个百分点。https://www.iotword.com/4182.html
一、YOLOX整体介绍可看文章:
https://zhuanlan.zhihu.com/p/392221567
改进点:
1、Decoupled head(预测分支解耦)。
作者实验发现耦合检测头可能会损害性能。共有两点改进:
①将预测分支解耦极大的改善收敛速度。
②相比较于非解耦的端到端方式,解耦能带来4.2%AP提升。
图2:yolov3 head与decoupled head结构图
模型结构:
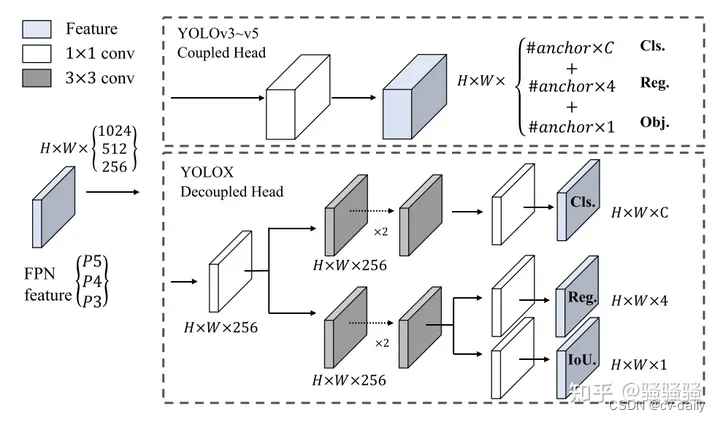
yolov3中,针对coco80类的检测任务,每一个anchor会对应产生hw85维度的预测结果,其中obj(区分是前景背景)占用1个通道,reg(坐标)占用4个通道,cls(预测是80类中的哪一个类)占用80个通道。
而YOLOX首先使用11卷积将原本不同channel数的特征图先统一到256(主要目的是降维),然后使用两个平行分支,两个分别两个使用33卷积,同时regression分支里还添加了IoU分支。
2、强大的数据增强。
添加Mosaic和MixUp,但在最后15epochs时关闭(笔者认为最后15轮关闭的原因可能是怕数据增强过度)
Mosaic最先在U版的yolov3中使用,现在已经广泛用于各大目标检测器。U版yolov3代码网址:https://github.com/ultralytics/yolov3
MixUp用在目标检测中大概的方式是:两张图以一定的比例对rgb值进行混合,同时需要模型预测出原本两张图中所有的目标。目前MixUp在各大竞赛、各类目标检测中属于稳定提点的策略。
作者颠覆性发现:使用强大的数据增强后,ImageNet预训练模型无益,所有后续模型都是随机初始化权重。
同时论文最后提到,在训练比较小的模型时候,例如YOLOX-S, YOLOX-Tiny,YOLOX-Nano网络,剔除mixup,弱化mosaic效果,表现要比使用好。
3、Anchor-free
anchor的问题:
①使用anchor时,为了调优模型,需要对数据聚类分析,确定最优锚点,缺乏泛化性。
②anchor机制增加了检测头复杂度,增加了每幅图像预测数量(针对coco数据集,yolov3使用416416图像推理, 会产生3(1313+2626+52*52)85=10647个预测结果)。
使用ancho-freer可以减少调整参数数量,减少涉及的使用技巧
从原有一个特征图预测3组anchor减少成只预测1组,直接预测4个值(左上角xy坐标和box高宽)。减少了参数量和GFLOPs,使速度更快,且表现更好。
作者在正样本选择方式做过以下几个尝试:
①只将物体中心点所在的位置认为是正样本,一个gt最多只会有一个正样本。AP达到42.9%。
②Multi positives。(笔者感觉这就是暴力美学,策略简单直接)将中心33区域都认为是正样本,即从上述策略每个gt有1个正样本增长到9个正样本。且AP提升到45%,已经超越U版yolov3的44.3%AP。
③SimOTA
这里不得不提到OTA(Optimal Transport Assignment,Paper: https://arxiv.org/abs/2103.14259),这里简单解释一下,后续计划出个专栏来解释OTA。在目标检测中,有时候经常会出现一些模棱两可的anchor,如图3,即某一个anchor,按照正样本匹配规则,会匹配到两个gt,而retinanet这样基于IoU分配是会把anchor分配给IoU最大的gt,而OTA作者认为,将模糊的anchor分配给任何gt或背景都会对其他gt的梯度造成不利影响,因此,对模糊anchor样本的分配是特殊的,除了局部视图之外还需要其他信息。因此,更好的分配策略应该摆脱对每个gt对象进行最优分配的惯例,而转向全局最优的思想,换句话说,为图像中的所有gt对象找到全局的高置信度分配。(和DeTR中使用使用匈牙利算法一对一分配有点类似)
二、详解SimOTA
参考:https://zhuanlan.zhihu.com/p/394392992
https://zhuanlan.zhihu.com/p/549382358
巧妙之处:
1、simOTA能够做到自动的分析每个gt要拥有多少个正样本。
2、能自动决定每个gt要从哪个特征图来检测。
3、相比较OTA,simOTA运算速度更快。
4、相比较OTA,避免额外超参数。
代码结构:
核心代码位于yolox/models/yolo_head.py中。
整体代码逻辑:
1、确定正样本候选区域。
2、计算anchor与gt的iou。
3、在候选区域内计算cost。
4、使用iou确定每个gt的dynamic_k。
5、为每个gt取cost排名最小的前dynamic_k个anchor作为正样本,其余为负样本。
6、使用正负样本计算loss。
 OTA虽然实现了很好的性能涨点,但其训练成本很高. YOLOX发现OTA中的Sinkhorn-Knopp算法在训练300epoch的情况下会增加25%的训练时间,为此YOLOX提出了SimOTA,使用手工设定的规则替代Sinkhorn-Knopp算法,缩短了因此增加的训练时间.
OTA虽然实现了很好的性能涨点,但其训练成本很高. YOLOX发现OTA中的Sinkhorn-Knopp算法在训练300epoch的情况下会增加25%的训练时间,为此YOLOX提出了SimOTA,使用手工设定的规则替代Sinkhorn-Knopp算法,缩短了因此增加的训练时间.
如上所述,SimOTA和OTA的区别主要在于最后一步,即使用Sinkhorn-Knopp算法求得最小cost的传输计划
. 对此,SimOTA使用下述方法替代Sinkhorn-Knopp算法求得传输计划
在已求得cost矩阵和每个GT所需的Anchor数量k的情况下,针对每个GT,根据cost挑选出k个cost最小的Anchor. (参考下图,下图为示例,只为了表达大概意思. IoU数量也和10对不上)


)





)
)









