引言
第38届AAAI人工智能年度会议将于2024年2月在加拿大温哥华举行。今天给大家分享十篇AAAI2024论文,主要涉及图神经网络,大模型幻觉、中文书法文字生成、表格数据分析、KGs错误检测、多模态Prompt、思维图生成等。
论文获取方式,回复:AAAI2024
AAAI是由国际人工智能促进协会主办的年会,是人工智能领域中历史最悠久、涵盖内容最广泛的国际顶级学术会议之一,也是中国计算机学会(CCF)推荐的A类国际学术会议。更多AAAI介绍可以参考这篇文章:一文了解AAAI国际会议--附: 各年论文列表连接
图神经网络微调
![]()
https://arxiv.org/pdf/2312.13583.pdf
本文研究解决预训练和微调图神经网络在图挖掘任务中的结构一致性问题。作者发现预训练图与微调图之间的结构差异主要源于生成模式的不一致。为此,本文作者提出了G-TUNING方法,通过调整预训练图神经网络,有效地保持了微调图的生成模式。
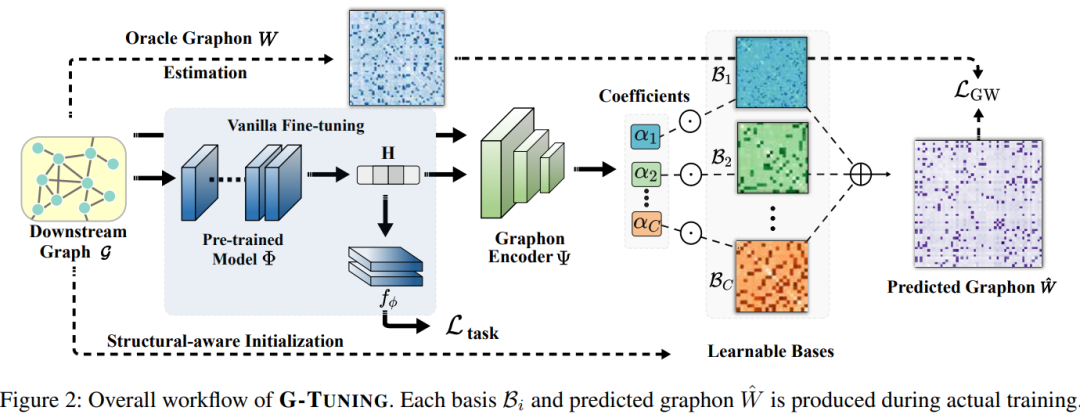
通过理论分析证明了存在一组替代图谱基,利用它们的线性组合可以高效地近似微调图的生成模式。在迁移学习实验中,与现有算法相比,G-TUNING在领域内和领域外分别提升了0.5%和2.6%
中文书法字体生成

https://arxiv.org/pdf/2312.10314.pdf
本文研究主要针对少样本中文书法字体生成的问题。本文提出了一种新颖的模型,DeepCalliFont,通过集成双模生成模型实现少样本中文书法字体合成。
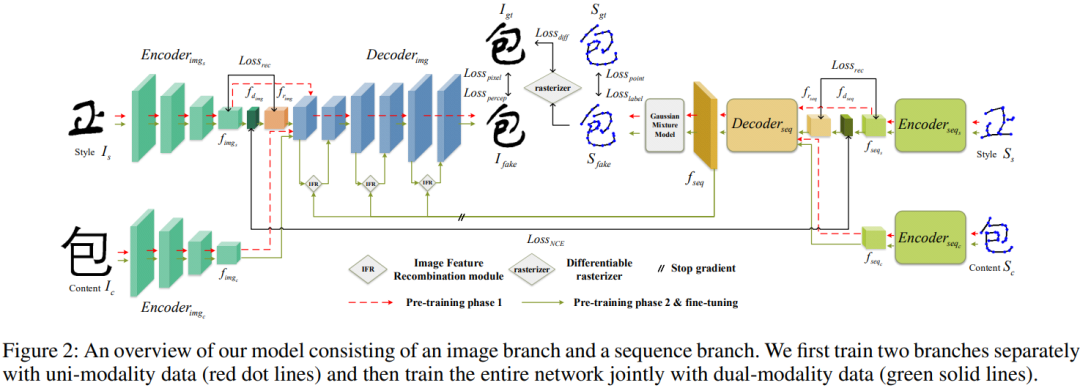
具体而言,该模型包括图像合成和序列生成两个分支,通过双模态表示学习策略生成一致的结果。两种模态(即字形图像和书写序列)通过特征重组模块和光栅化损失函数进行合理集成。此外,采用新的预训练策略,通过利用大量的单模态数据来提高性能。定性和定量实验证明了本文方法在少样本中文书法字体生成任务上优于其他最先进的方法。
RAG减少LLM幻觉研究
![]()
https://arxiv.org/pdf/2309.01431.pdf
本文研究主要针对检索增强生成(RAG)在缓解大型语言模型(LLMs)产生幻觉方面的问题。现有研究缺乏对检索增强生成对不同大型语言模型的影响进行严格评估,这使得难以确定RAG在不同LLMs能力中的潜在瓶颈。本文系统地调查了检索增强生成对大型语言模型的影响。
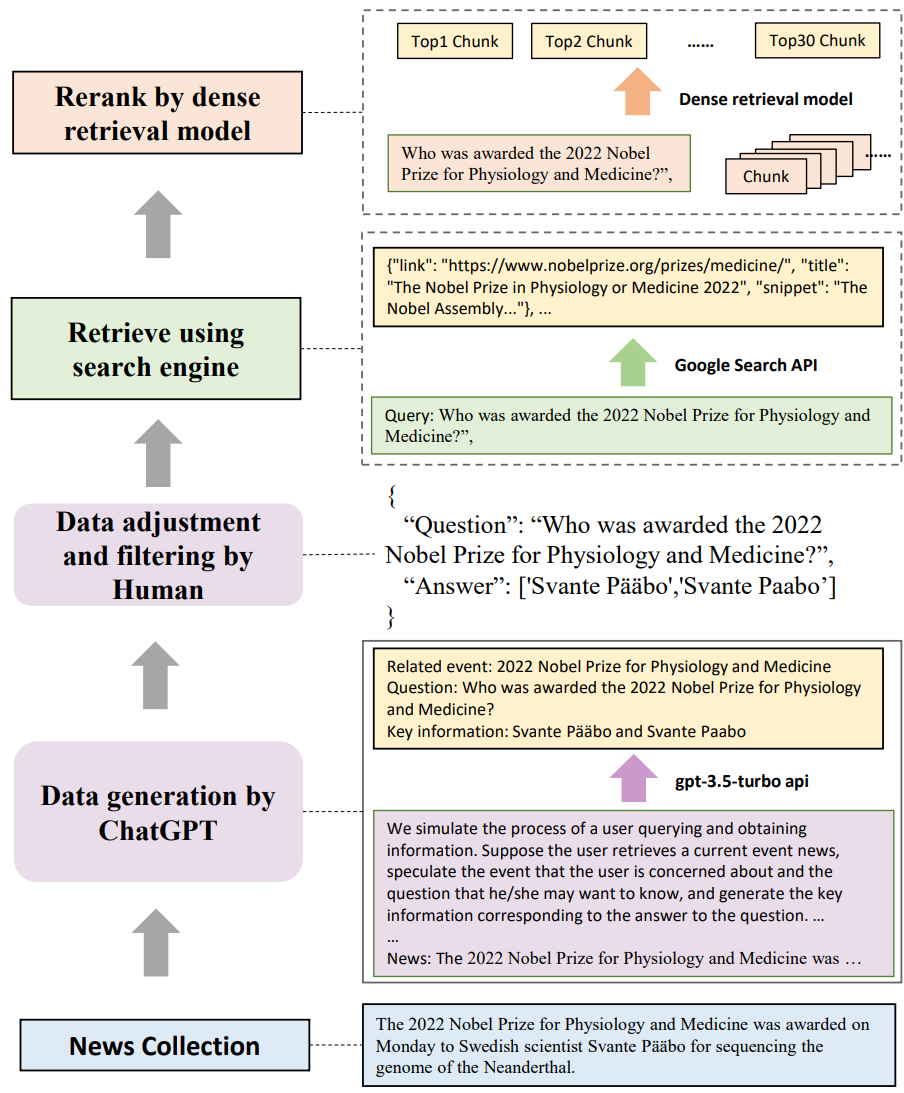
本文分析了不同大型语言模型在RAG所需的4个基本能力方面的性能,包括噪声鲁棒性、负例拒绝、信息整合和反事实鲁棒性。为此,本文建立了检索增强生成基准(RGB),这是一个用于在英语和中文中评估RAG的新语料库。RGB根据解决案例所需的上述基本能力将基准中的实例划分为4个独立的测试集。然后,我们在RGB上评估了6个代表性的LLMs,以诊断当前LLMs在应用RAG时的挑战。评估表明,虽然LLMs在一定程度上具有噪声鲁棒性,但在负例拒绝、信息整合和处理虚假信息方面仍然存在显著困难。结果表明,在将RAG有效应用于LLMs方面仍有相当的挑战。
表格数据分析

https://arxiv.org/pdf/2312.13671.pdf
本文研究主要针对表格数据分析领域存在的问题,当前研究主要集中在Text2SQL和TableQA等基础任务,忽略了像预测和图表生成这样的高级分析。
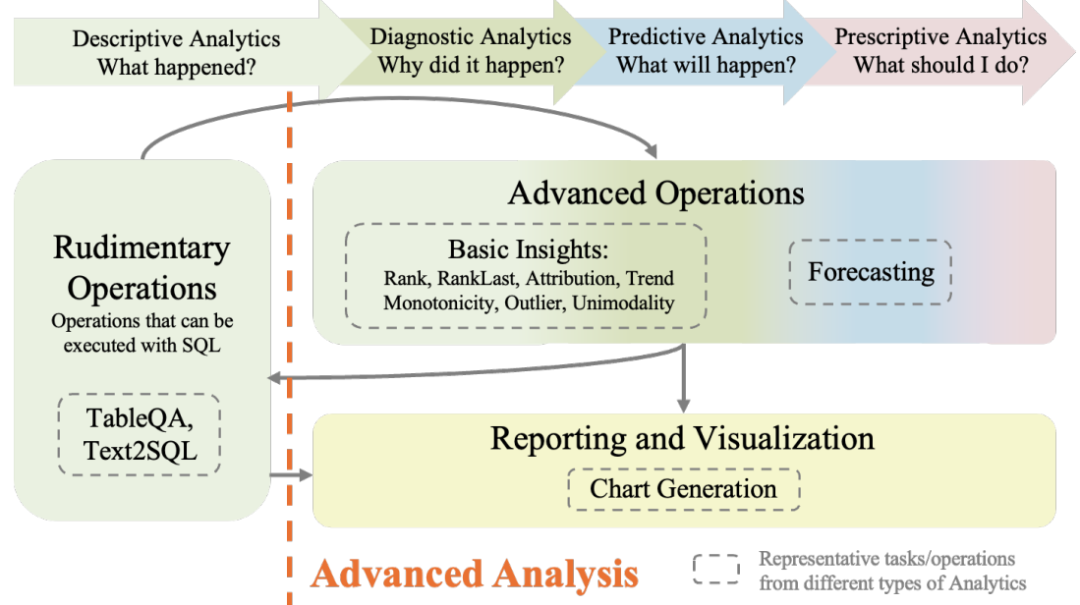
为填补这一空白,本文提出了Text2Analysis基准,涵盖了超越SQL兼容操作的高级分析任务。本文还开发了五种创新有效的注释方法,充分利用大型语言模型的能力,提高数据的质量和数量。此外引入了类似真实用户问题的不确定查询,测试模型对此类挑战的理解和解决能力。
最终,本文收集了2249个查询-结果对和347个表格,使用三种不同的评估指标对五个最先进的模型进行评估,结果显示本文的基准在表格数据分析领域提出了相当大的挑战。
零样本认知诊断

https://arxiv.org/pdf/2312.13434.pdf
本文研究主要针对领域级零样本认知诊断(DZCD),该问题源于新启动领域中缺乏学生练习日志。近期的跨领域诊断模型被证明是解决DZCD的一种策略,但这些方法主要关注如何在领域之间转移学生状态。然而,它们可能会无意中将不可转移的信息纳入学生表示中,从而限制知识转移的效果。

为了解决这个问题,本文提出了Zero-1-to-3,通过早期学生实现领域共享认知信号传递和虚拟数据生成,有效处理新领域中缺乏学生练习日志的情况。共享的认知信号可以传递到目标领域,丰富新领域的认知先验,确保认知状态传播的目标。在六个真实世界数据集上的广泛实验证明了本文模型在DZCD及其在问题推荐中的实际应用方面的有效性。
动态网络方法
![]()
https://arxiv.org/pdf/2312.13068.pdf
本文研究主要针对动态网络方法在处理时间上连续变化的网络时存在的局限性。本文提出了一种基于生存函数的新型随机过程,用于建模链接在时间上的持续和缺失。这形成了一种通用的新似然规范,明确考虑了间歇性的边持续网络,即GRASP:Graph Representation with Sequential Survival Process。
本文将该框架应用于最近的连续时间动态潜在距离模型,以节点在潜在空间中的分段线性移动序列来刻画网络动态。本文在诸如链接预测和网络完成等各种下游任务中进行了定量评估,结果表明本文的建模框架能够有效跟踪潜在空间中节点的内在轨迹,捕捉不断演变的网络结构的基本特征。
KGs错误检测
![]()
https://arxiv.org/pdf/2312.12108.pdf
本文研究主要针对知识图谱(KGs)中存在的各种错误问题。本文提出了一种KG错误检测模型CCA,通过三元组重建整合文本和图结构信息,更好地区分语义。
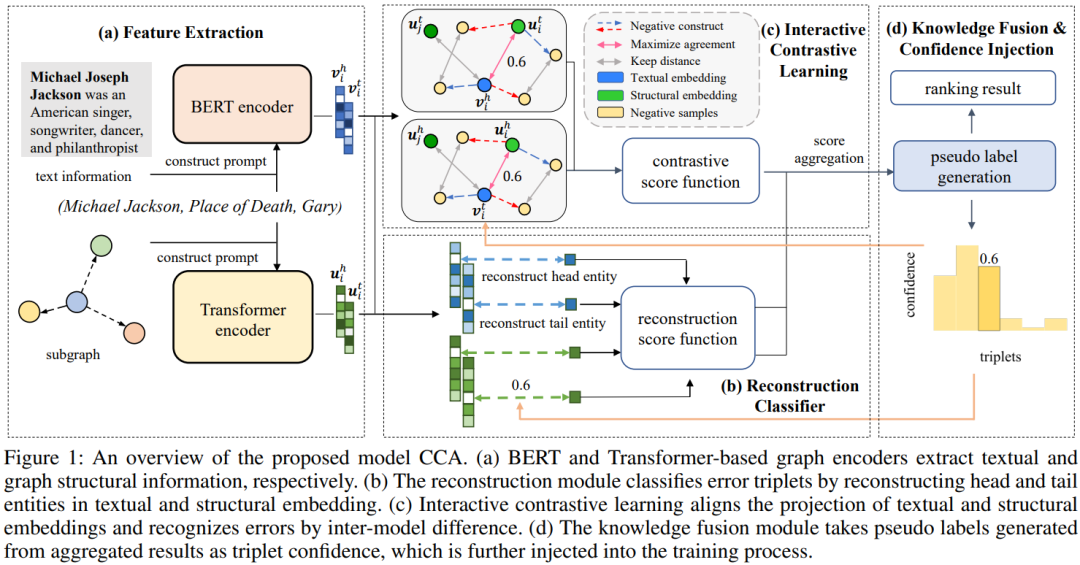
本文采用交互对比学习捕捉文本和结构模式之间的差异。此外,本文构建了包含语义相似噪声和对抗性噪声的真实数据集。实验结果表明,CCA在检测语义相似噪声和对抗性噪声方面优于最先进的基线方法。
思维图生成
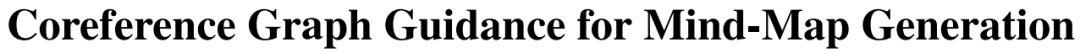
https://arxiv.org/pdf/2312.11997.pdf
本文研究主要针对思维图生成中存在的问题,即现有方法虽然能够并行生成思维图,但主要侧重于顺序特征,难以捕捉结构信息,尤其在建模长程语义关系方面存在困难。
本文提出了一种基于指代的思维图生成网络(CMGN),以引入外部结构知识。具体而言,本文基于指代语义关系构建指代图,引入图结构信息。然后,采用指代图编码器挖掘句子之间的潜在关系。
为了排除噪声并更好地利用指代图的信息,本文采用对比学习方式中的图增强模块。实验结果表明,本文模型优于所有现有方法。案例研究进一步证明,本文模型能够更准确、简洁地揭示文档的结构和语义。
多模态对齐Prompt
![]()
https://arxiv.org/pdf/2312.08636.pdf
本文研究主要针对多任务学习中解码器随任务增加而复杂的问题。本文提出了一种集成无解码器的视觉-语言模型CLIP的方法,该模型表现出强大的零样本泛化能力。
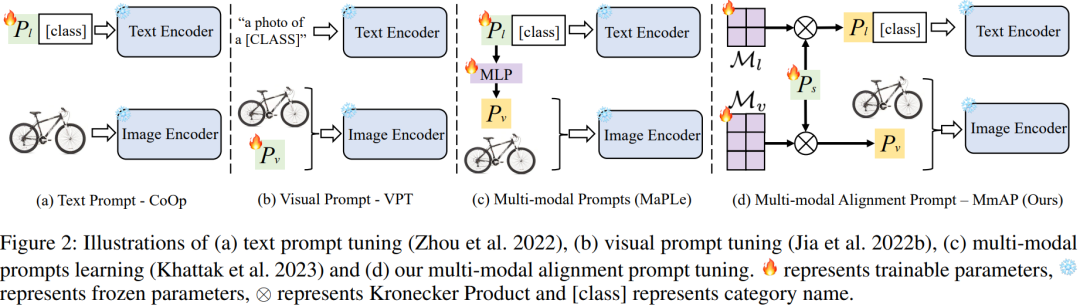
本文首先提出了多模态对齐提示(MmAP)方法,用于在微调过程中对齐文本和视觉模态。在MmAP的基础上,本文开发了一种创新的多任务提示学习框架。一方面,为了最大化相似任务的互补性;另一方面,为了保留每个任务的独特特征,为每个任务分配一个特定的MmAP。
在两个大型多任务学习数据集上的综合实验证明,本文方法相较于完全微调实现了显著的性能提升,同时仅利用约0.09%的可训练参数。
多模型标签对齐
https://arxiv.org/pdf/2312.08212.pdf
本文研究主要针对在视觉-语言(VL)领域中,将预训练模型成功迁移到下游任务的问题。先前的方法主要集中于构建文本和视觉输入的提示模板,忽略了VL模型和下游任务之间类别标签表示的差距。
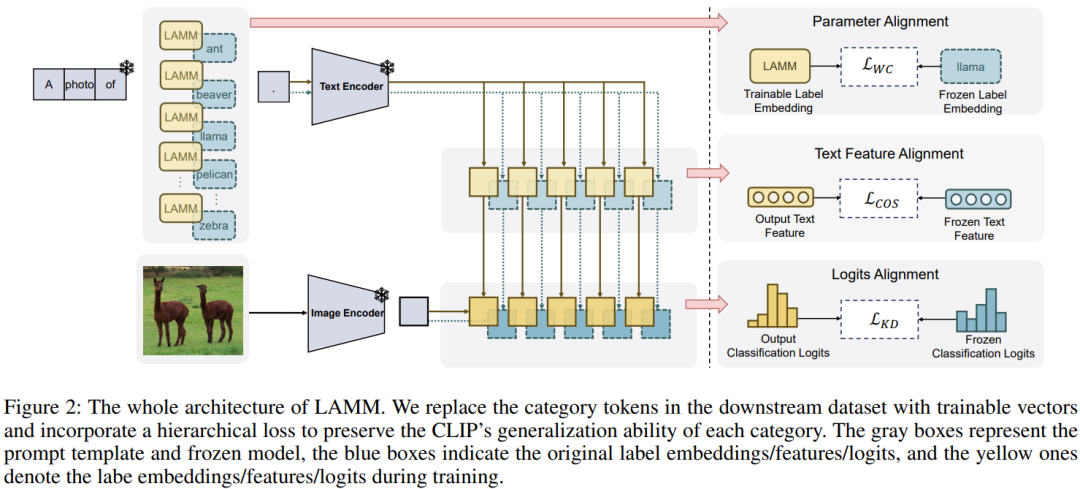
为解决这一挑战,本文引入了一种名为LAMM的创新标签对齐方法,通过端到端训练动态调整下游数据集的类别嵌入。此外,为了获得更合适的标签分布,本文提出了一个分层损失,包括参数空间、特征空间和logits空间的对齐。我们在11个下游视觉数据集上进行了实验证明,本文方法在少样本场景中显著提高了现有多模态提示学习模型的性能,相较于16张图像的最先进方法,平均准确率提升了2.31%。

)



)






IO 多路复用实验之poll实验)


【Linux】)



