1 引言
Bert时代,我们常做预训练模型微调(Fine-tuning),即根据不同下游任务,引入各种辅助任务loss和垂直领域数据,将其添加到预训练模型中,以便让模型更加适配下游任务的方式。每个下游任务都存下整个预训练模型的副本,并且推理必须在单独的批次中执行。
那么能不能将所有自然语言处理的任务转换为语言模型任务?就是所有任务都可以被统一建模,任务描述与任务输入视为语言模型的历史上下文,而输出则为语言模型需要预测的未来信息。
因此,Prompt新范式被提出,无需要fine-tune,让预训练模型直接适应下游任务。Prompt方式更加依赖先验,而 fine-tuning 更加依赖后验。
2 P-tuning
P-tuning有两个版本:
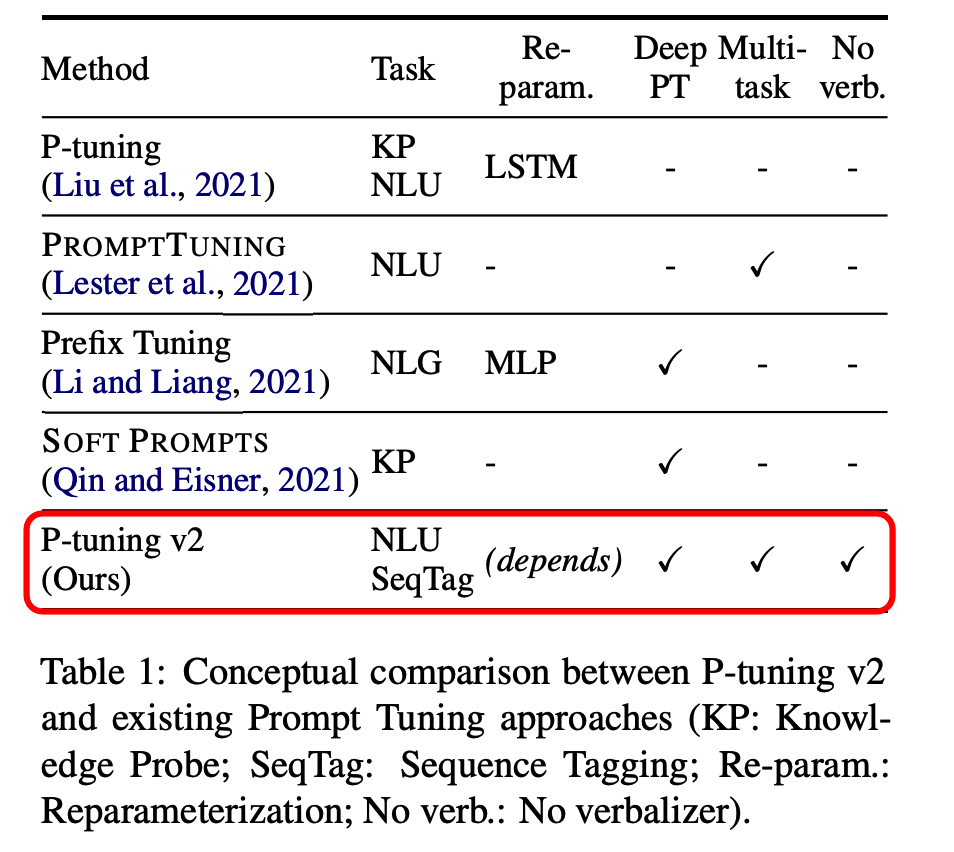
- 论文GPT Understands, Too[2]中的Prompt tuning,在本文行文过程中称为P-tuning v1。
GitHub 代码:https://github.com/THUDM/P-tuning
- P-Tuning v2在论文《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》中提出。
GitHub代码:https://github.com/THUDM/P-tuning-v2
2.1 prefix-tuning
如果分析 P-tuning,那不得不提到prefix-tuning技术,相对于fine-tuning,在调节模型的过程中只优化一小段可学习的continuous task-specific vector(prefix)而不是整个模型的参数。
对于不同的任务和模型结构需要不同的prefix:
-
在autoregressive LM 前添加prefix获得:
![]()
-
在encoder和decoder之前添加prefixs获得:
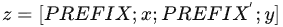

2.2 P-tuning v1
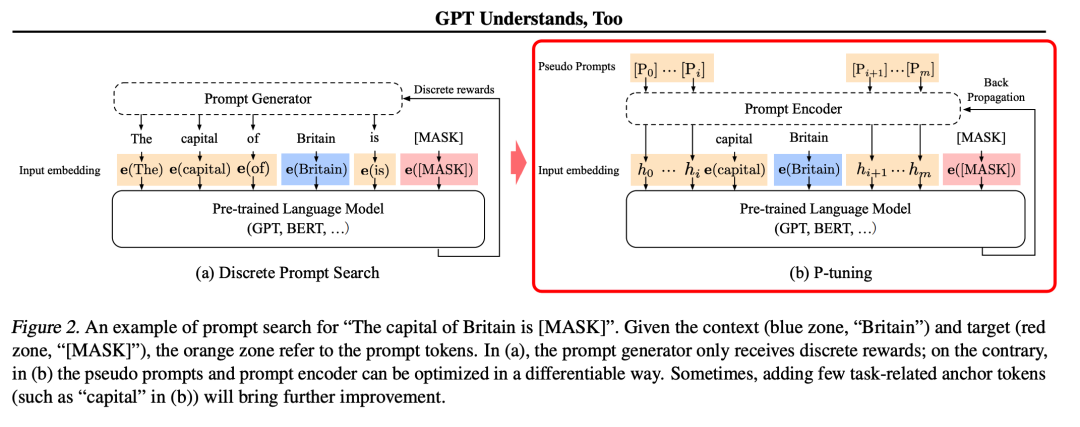
主要结构是利用了一个prompt encoder(BiLSTM+MLP),将一些pseudo prompt先encode(离散token)再与input embedding进行拼接,同时利用LSTM进行 Reparamerization 加速训练,并引入少量自然语言提示的锚字符(Anchor,例如Britain)进一步提升效果。然后结合(capital,Britain)生成得到结果,再优化生成的encoder部分。
P-tuning v1有两个显著缺点:任务不通用和规模不通用
在一些复杂的自然语言理解NLU任务上效果很差,比如序列标注等;预训练模型的参数量不能小,仅在10B规模表现良好,而在稍小规模的模型(330M和2B)上表现不佳。
2.3 P-tuning v2
V2版本主要是基于P-tuning和prefix-tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。
-
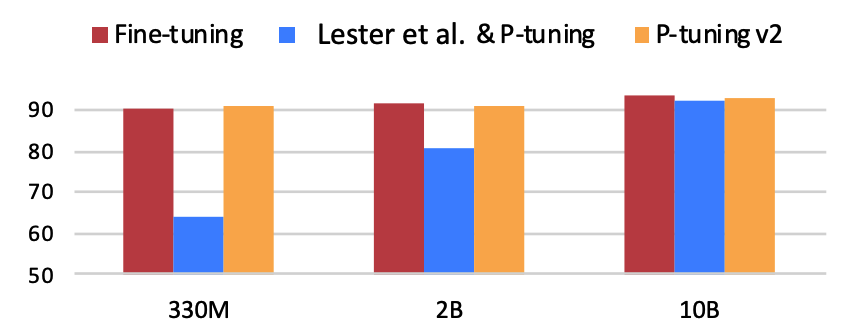
仅精调0.1%参数量,在330M到10B不同参数规模LM模型上,均取得和Fine-tuning相比肩的性能:
-
将Prompt tuning技术首次拓展至序列标注等复杂的NLU任务上,而P-tuning(v1)在此任务上无法运作:
2.4 v1和v2框架对比:
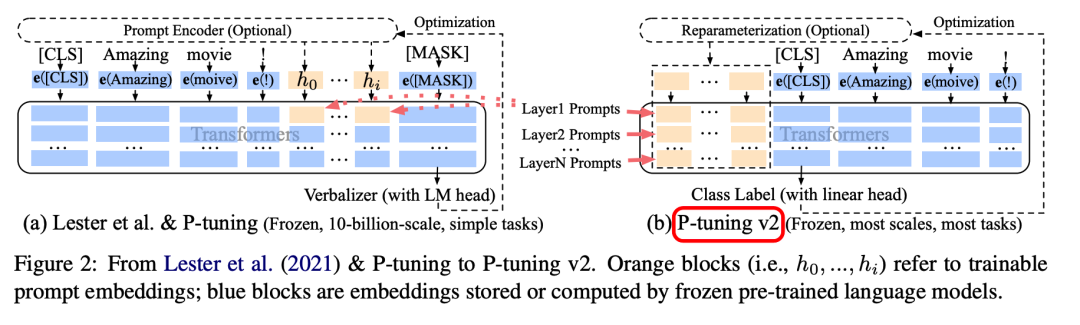
可以看到右侧的p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。在左图v1模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。
v2变化:
移除了Reparameterization,舍弃了词汇Mapping的Verbalizer的使用,重新利用CLS和字符标签,来增强通用性,这样可以适配到序列标注任务。此外,作者还引入了两项技术:
-
Deep Prompt Encoding:
采用 Prefix-tuning 的做法,在输入前面的每层加入可微调的参数。使用无重参数化编码器对pseudo token,不再使用重参数化进行表征(如用于 prefix-tunning 的 MLP 和用于 P-tuning 的 LSTM),且不再替换pre-trained word embedding,取而代之的是直接对pseudo token对应的深层模型的参数进行微调。
-
Multi-task learning:
基于多任务数据集的Prompt进行预训练,然后再适配到下游任务。对于pseudo token的continous prompt,随机初始化比较难以优化,因此采用multi-task方法同时训练多个数据集,共享continuous prompts去进行多任务预训练,可以让prompt有比较好的初始化。
3 大模型 p-tuning
ptuning v2论文已经证明在不同规模大小模型和不同NLP任务上的有效性,结合最近大模型涌现后的微调热,清华相关实验室对 ChatGLM-6B 模型做了基于 P-Tuning v2的微调。
需要微调的参数量减少到原来的 0.1%,结合模型量化和Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行了。
这里使用了两层MLP对Prefix做 Encode:
class PrefixEncoder(torch.nn.Module):"""The torch.nn model to encode the prefixInput shape: (batch-size, prefix-length)Output shape: (batch-size, prefix-length, 2*layers*hidden)"""def __init__(self, config):super().__init__()self.prefix_projection = config.prefix_projectionif self.prefix_projection:# 这里!!self.embedding = torch.nn.Embedding(config.pre_seq_len, config.hidden_size)self.trans = torch.nn.Sequential(torch.nn.Linear(config.hidden_size, config.hidden_size),torch.nn.Tanh(),torch.nn.Linear(config.hidden_size, config.num_layers * config.hidden_size * 2))else:self.embedding = torch.nn.Embedding(config.pre_seq_len, config.num_layers * config.hidden_size * 2)def forward(self, prefix: torch.Tensor):if self.prefix_projection:prefix_tokens = self.embedding(prefix)past_key_values = self.trans(prefix_tokens)else:past_key_values = self.embedding(prefix)return past_key_values并在 ChatGLMModel class 中的 prompt 处调用:

并且传入到每一层中:
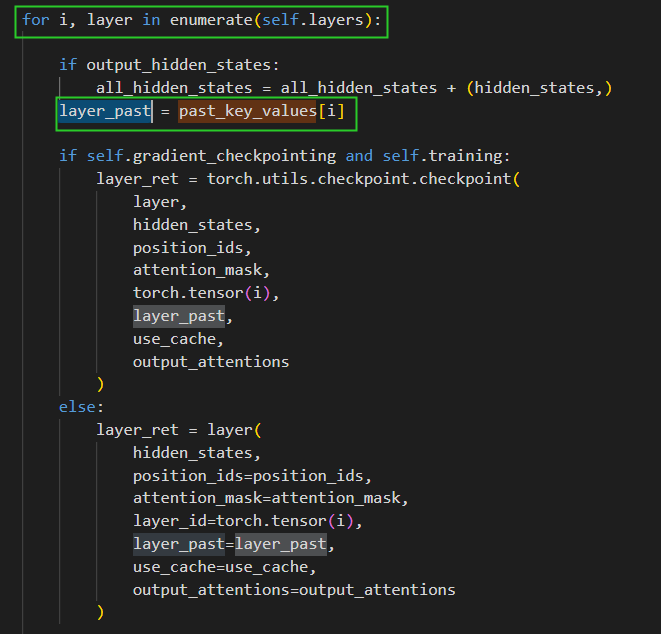
这时候,我们对照论文中的v2模型结构就更好理解了:
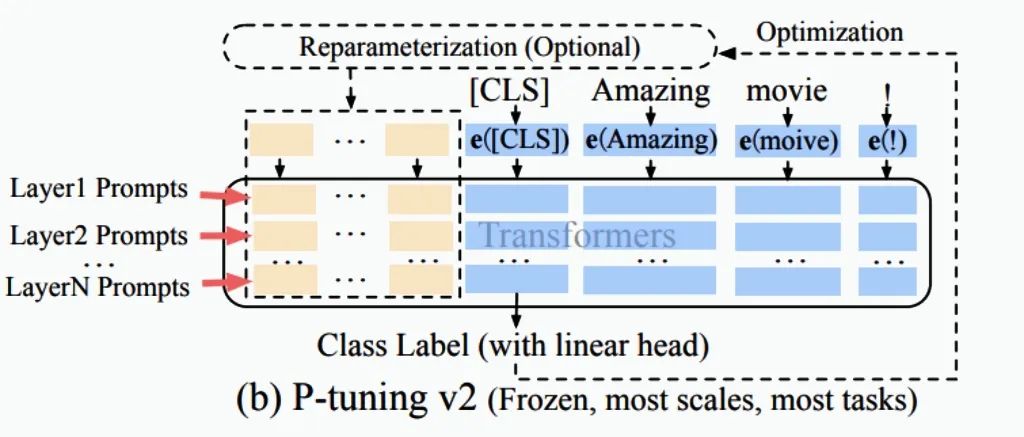
使用两层MLP对prompt做encode,添加到模型每一层,这部分的参数是可训练的,右侧蓝色部分是预训练模型的权重不做更新。
4 参考资料
[1]Prompt综述: https://dl.acm.org/doi/pdf/10.1145/3560815
[2]P-Tuning v1 论文: https://arxiv.org/pdf/2103.10385.pdf
[3]P-Tuning v2论文: https://arxiv.org/abs/2110.07602
[4]Prefix-Tuning: Optimizing Continuous Prompts for Generation: https://arxiv.org/abs/2101.00190
[5]PrefixTuning Code: https://github.com/XiangLi1999/PrefixTuning
[6]ChatGLM-6B: https://github.com/THUDM/ChatGLM-6B
[7]ChatGLM-6B PTuning: https://github.com/THUDM/ChatGLM-6B/tree/main/ptuning

)
)














、nextLine()、nextInt()、nextDouble()))

