Flink On Yarn 模式
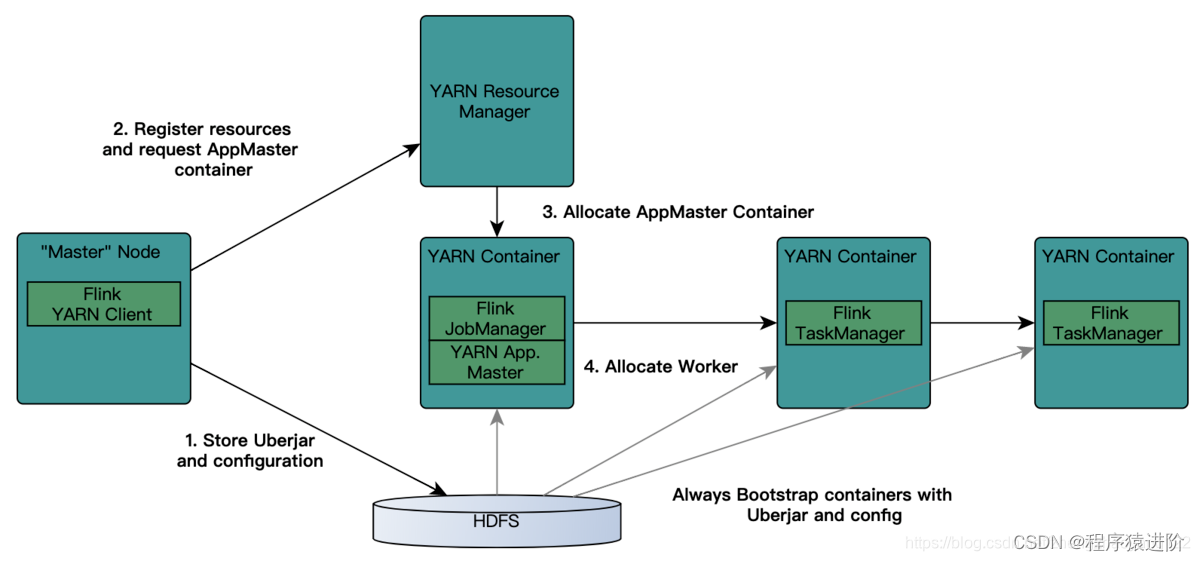
基于Yarn层面的架构类似 Spark on Yarn模式,都是由Client提交App到RM上面去运行,然后 RM分配第一个container去运行AM,然后由AM去负责资源的监督和管理。需要说明的是,Flink的Yarn模式更加类似Spark on Yarn的cluster模式,在cluster模式中,dirver将作为AM中的一个线程去运行。Flink on Yarn模式也是会将JobManager启动在container里面,去做个driver类似的任务调度和分配,Yarn AM与Flink JobManager在同一个Container中,这样AM可以知道Flink JobManager的地址,从而AM可以申请Container去启动Flink TaskManager。待Flink成功运行在Yarn集群上,Flink Yarn Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。
Fink on Yarn 的缺陷
【1】资源分配是静态的,一个作业需要在启动时获取所需的资源并且在它的生命周期里一直持有这些资源。这导致了作业不能随负载变化而动态调整,在负载下降时无法归还空闲的资源,在负载上升时也无法动态扩展。
【2】On-Yarn模式下,所有的container都是固定大小的,导致无法根据作业需求来调整container的结构。譬如CPU密集的作业或需要更多的核,但不需要太多内存,固定结构的container会导致内存被浪费。
【3】与容器管理基础设施的交互比较笨拙,需要两个步骤来启动Flink作业:1.启动Flink守护进程;2.提交作业。如果作业被容器化并且将作业部署作为容器部署的一部分,那么将不再需要步骤2。
【4】On-Yarn模式下,作业管理页面会在作业完成后消失不可访问。
【5】Flink推荐 per job clusters 的部署方式,但是又支持可以在一个集群上运行多个作业的session模式,令人疑惑。
在Flink版本1.5中引入了Dispatcher,Dispatcher是在新设计里引入的一个新概念。Dispatcher会从Client端接受作业提交请求并代表它在集群管理器上启动作业。引入Dispatcher的原因主要有两点:
【1】一些集群管理器需要一个中心化的作业生成和监控实例;
【2】能够实现Standalone模式下JobManager的角色,且等待作业提交。在一些案例中,Dispatcher是可选的Yarn或者不兼容的kubernetes。
资源调度模型重构下的 Flink On Yarn 模式
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/f2c2a368949e4477bc2bdf59255c1679.png)
客户端提交JobGraph以及依赖jar包到YarnResourceManager,接着Yarn ResourceManager分配第一个container以此来启动AppMaster,Application Master中会启动一个FlinkResourceManager以及JobManager,JobManager会根据JobGraph生成的ExecutionGraph以及物理执行计划向FlinkResourceManager申请slot,FlinkResoourceManager会管理这些slot以及请求,如果没有可用slot就向Yarn的ResourceManager申请container,container启动以后会注册到FlinkResourceManager,最后JobManager会将subTask deploy到对应container的 slot中去。
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/b2f178fff27b40bf842889897933f91b.png)
在有Dispatcher的模式下:会增加一个过程,就是Client会直接通过HTTP Server的方式,然后用Dispatcher将这个任务提交到Yarn ResourceManager中。
新框架具有四大优势,详情如下:
【1】client直接在Yarn上启动作业,而不需要先启动一个集群然后再提交作业到集群。因此client再提交作业后可以马上返回。
【2】所有的用户依赖库和配置文件都被直接放在应用的classpath,而不是用动态的用户代码classloader去加载。
【3】container在需要时才请求,不再使用时会被释放。
【4】“需要时申请”的container分配方式允许不同算子使用不同profile (CPU和内存结构)的container。
新的资源调度框架下 single cluster job on Yarn 流程介绍
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/dc4e94b0371f416bae31b31e81aec2fa.png)
single cluster job on Yarn模式涉及三个实例对象:
【1】clifrontend: Invoke App code;生成StreamGraph,然后转化为JobGraph;
【2】YarnJobClusterEntrypoint(Master): 依次启动YarnResourceManager、MinDispatcher、JobManagerRunner三者都服从分布式协同一致的策略;JobManagerRunner将JobGraph转化为ExecutionGraph,然后转化为物理执行任务Execution,然后进行deploy,deploy过程会向 YarnResourceManager请求slot,如果有直接deploy到对应的YarnTaskExecutiontor的slot里面,没有则向Yarn的ResourceManager申请,带container启动以后deploy。
【3】YarnTaskExecutorRunner (slave): 负责接收subTask,并运行。
整个任务运行代码调用流程如下图
![[点击并拖拽以移动] ](https://img-blog.csdnimg.cn/direct/6c806cbc7d26499cb6f9db9ae194c1f5.png)
subTask在执行时是怎么运行的?
调用StreamTask的invoke方法,执行步骤如下:
【1】initializeState()即operator的initializeState();
【2】openAllOperators()即operator的open()方法;
【3】最后调用run方法来进行真正的任务处理;
我们来看下flatMap对应的OneInputStreamTask的run方法具体是怎么处理的。
@Override
protected void run() throws Exception {// 在堆栈上缓存处理器引用,使代码更易于JITfinal StreamInputProcessor<IN> inputProcessor = this.inputProcessor;while (running && inputProcessor.processInput()) {// 所有的工作都发生在“processInput”方法中}
}
最终是调用StreamInputProcessor的processInput()做数据的处理,这里面包含用户的处理逻辑。
public boolean processInput() throws Exception {if (isFinished) {return false;}if (numRecordsIn == null) {try {numRecordsIn = ((OperatorMetricGroup) streamOperator.getMetricGroup()).getIOMetricGroup().getNumRecordsInCounter();} catch (Exception e) {LOG.warn("An exception occurred during the metrics setup.", e);numRecordsIn = new SimpleCounter();}}while (true) {if (currentRecordDeserializer != null) {DeserializationResult result = currentRecordDeserializer.getNextRecord(deserializationDelegate);if (result.isBufferConsumed()) {currentRecordDeserializer.getCurrentBuffer().recycleBuffer();currentRecordDeserializer = null;}if (result.isFullRecord()) {StreamElement recordOrMark = deserializationDelegate.getInstance();//处理watermarkif (recordOrMark.isWatermark()) {// handle watermark//watermark处理逻辑,这里可能引起timer的triggerstatusWatermarkValve.inputWatermark(recordOrMark.asWatermark(), currentChannel);continue;} else if (recordOrMark.isStreamStatus()) {// handle stream statusstatusWatermarkValve.inputStreamStatus(recordOrMark.asStreamStatus(), currentChannel);continue;//处理latency watermark} else if (recordOrMark.isLatencyMarker()) {// handle latency markersynchronized (lock) {streamOperator.processLatencyMarker(recordOrMark.asLatencyMarker());}continue;} else {//用户的真正的代码逻辑// now we can do the actual processingStreamRecord<IN> record = recordOrMark.asRecord();synchronized (lock) {numRecordsIn.inc();streamOperator.setKeyContextElement1(record);//处理数据streamOperator.processElement(record);}return true;}}}//这里会进行checkpoint barrier的判断和对齐,以及不同partition 里面checkpoint barrier不一致时候的,数据buffer,final BufferOrEvent bufferOrEvent = barrierHandler.getNextNonBlocked();if (bufferOrEvent != null) {if (bufferOrEvent.isBuffer()) {currentChannel = bufferOrEvent.getChannelIndex();currentRecordDeserializer = recordDeserializers[currentChannel];currentRecordDeserializer.setNextBuffer(bufferOrEvent.getBuffer());}else {// Event receivedfinal AbstractEvent event = bufferOrEvent.getEvent();if (event.getClass() != EndOfPartitionEvent.class) {throw new IOException("Unexpected event: " + event);}}}else {isFinished = true;if (!barrierHandler.isEmpty()) {throw new IllegalStateException("Trailing data in checkpoint barrier handler.");}return false;}}
}
streamOperator.processElement(record)最终会调用用户的代码处理逻辑,假如operator是StreamFlatMap的话。
@Override
public void processElement(StreamRecord<IN> element) throws Exception {collector.setTimestamp(element);userFunction.flatMap(element.getValue(), collector);//用户代码
}











——STP协议判断)

)

)



