1 引言
智能运维(AIOps-Algorithmic IT Operations基于算法的IT运维)是人工智能技术在IT运维领域的运用,引用Gartner 的报告的一段话“未来几年,将近50%的企业将会在他们的业务和IT运维方面采用AIOps,远远高于今天的10%“,最近2-3年智能运维的概念随处可见,各大互联网公司、传统IT公司、金融业等都在谈他们的智能运维设想,同时也有人谈AI色变,觉得人工智能只是一个愿景,要落地很难。其实AI已经不是一个新的概念了,百度、微软、谷歌等公司早就在10几年前开始自己的人工智能布局了,到现在均已成为人工智能行业的领跑者了
人工智能的时代已经来了!人工智能那么强大,应用场景十分的广泛,当然也包括运维领域,而且面向业务型的智能运维更是运维发展的热点趋势。
2 电信系统运维现状
目前,电信系统的IT运维绝大部分都停留在传统运维的层面,近两年才开始逐渐出现新的突破。
2.1 传统运维的痛点
传统的运维中,存在着诸多痛点:
(1)被动低效的运维难以保证业务连续性
(2)缺乏统一的运维监控体系和技术工具
(3)海量的运维数据的价值无法充分挖掘。
(4)缺乏全方位端到端的运维监控手段
2.2 AIOPS智能运维的切入点
针对上述这些传统运维中存在的痛点,智能化的运维出现必定具有划时代的意义,智能运维系统的设计可以从如下几方面进行展开思考:
(1)面向业务维度实现异常检测
(2)提供业务全局关系视图
(3)KPI可视化与下钻定位
(4)采用动态阈值思想的异常检测
(5)重视故障的全流程管理
(6)立体化监控体系的建设
3 AIOPS系统的架构
3.1 AIOPS体系构建要素
业务型智能运维体系架构的建设应该考虑如下因素
3.1.1数据
数据,搭建智能运维平台的关键就是数据驱动,具体表现如下。
海量数据存储:运维数据的量级是亿级、TB-PB级别的,所以存储系统一定要具备高容量和扩展性;
数据多样化:运维过程产生的数据具有多样特征,如应用性能数据,基础设施类数据,服务间调用链数据、业务/统计日志数据等,需要针对不同类型数据进行区别化的存储结构的设计,保证各类数据存储的扩展性,同时建立数据之间的关联支点;
数据加工:数据从首次获取到达可用可分析的过程需要数据加工,历经多个阶段,每个阶段数据具备对应的功用,如原始数据经过去脏排错后作为一阶段全量数据,应对历史详查场景;多维数据划分,应对局部场景化需求;不同时间粒度的统计数据,作为数据分析和建模的需求。各阶段数据通过API对外提供查询服务。
3.1.2分析能力
分析能力是智能运维平台的核心,应用大数据+机器学习的分析能力,结合成熟的开源分析算法实现基本的数据分析,再结合具体的应用场景,做出一些适应性改造或匹配来实现相对较好的分析效果。
运用起历史数据的价值,且可以有效识别出数据的各维度的规律,如周期性、趋势性、平稳性等,而且分析能力必须结合应用场景,判别相对适合的算法模型来训练数据,方能保证预期的设想。
分析能力可以随着时间的推移不断的演进,可以将新数据的特性带入到模型中来,以不断提高算法的准确度。
3.2 AIOPS体系架构
3.2.1通用的业务型智能运维的体系架构
一个比较通用的AIOPS系统体系架构可以归纳为如下架构:
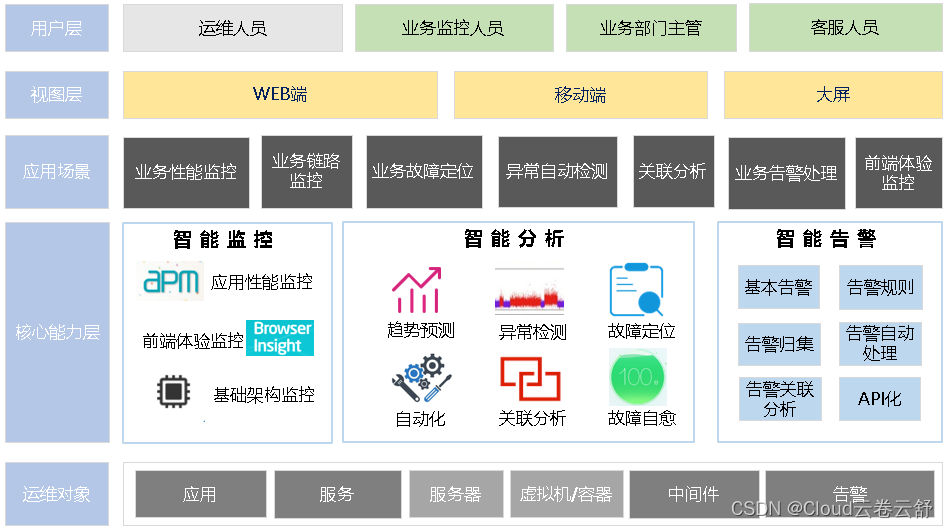
图1 业务性AIOPS智能运维系统架构设计图
在上述的架构设计中:
(1)用户层,业务型智能运维面向的用户,更偏重于业务监控人员,甚至业务部门主管、客服人员;
(2)视图层,提供WEB端丰富的可视化视图、大屏方式的业务状态视图、以及满足移动办公需求的手机端APP;
(3)服务层,业务型智能运维系统应该提供给用户业务视图服务、拓扑服务、性能KPI服务、运维分析服务、告警服务、报表服务以及系统服务等,另外需要支持快速构建新服务的能力。
(4)核心能力层,业务型智能运维系统的最核心部分,可以分为 “智能监控”、“智能分析”和“智能告警”三大模块。
(5)运维对象:运维对象涵盖应用、服务、服务器、网络设备、虚拟化/容器、中间件/数据库、应用日志以及告警等。
3.2.1智能三板斧
构建一个AIOPS智能运维系统,往往应该实现监控采集、分析计算、告警通知三个方面的智能化配备,所以整体架构也应该包含如下三个模块:
(1)智能监控:
实现针对各个层面的监控覆盖,包括用户体验的监控、应用性能的监控、中间件监控、基础设施的监控,收集了全面的数据,从数据中寻找关联,从关联中发现规律,丰富运维知识库。
(2)智能分析:
该部分应该涵盖离线算法的训练模块和在线实时分析模块。离线算法训练模块根据历史数据来以离线的方式训练和修正算法模型,然后生成的算法模型可以实时的应用到线上,如趋势预测、异常检测、故障定位等。
在线实时分析模块要实现实时的算法分析,并不依赖于历史数据所训练出的离线模型,而是依托大数据技术进行实时的分析。
(3)智能告警:
智能告警需要将告警最及时、最准确、最小化的通知给运维人员,这里面则涉及了“实时计算”、“告警抑制”、“告警净化”等关键技术点。
智能告警还可以动态调整告警短信/邮件发送的频率和周期,还有告警通知对象的智能配置,保证运维人员处理告警的专注性,不会被突如其来的海量告警所淹没。
4 AIOPS系统构建的关键要素和技术
4.1异常检测
异常检测,是业务智能运维领域中的一个最常见的场景,异常检测的方法一般可分为如下几个类别:
(1)传统的异常检测方法
传统模式下完全基于人的主观经验,也即基于固定阈值的异常判断,如 CPU usage高于80%就告警,这种方式适配性是很差的,需要针对不同的场景设定不同的阈值,甚至同一个业务不同时间段的阈值都是不一样的,大量个性化的配置要求,对于运维人员来说是十分费时费力的。
后来也出现了一定的改进,如3-sigma算法,是根据正态分布的概率,自动的调整告警阈值,此时告警阈值的配置不用人工进行,一定程度上提高了运维效率。但是,该类的算法机器容易忽略指标的周期性和趋势性,非常容易造成误判和漏判。
(2)基于统计学和机器学习的异常检测方法
总结前面的异常检测方法,可以概括为两点:人工运维工作量大、算法适配性低下,其实本质问题归结为一句话,就是动态阈值怎么评定的问题。
这个时候就比较适合引入一些高级的统计学算法了,比如基于指数的三次平滑算法、基于分解的傅里叶/小波分解算法等,可以有效的识别出指标的周期性、趋势性,可以快速识别出一些尖峰(spike)异常
另外自回归移动平均模型(ARIMA算法),对于稳定的时序数据的异常检测是非常有效的,该算法也非常适合用作时序数据的预测场景。
另外机器学习算法也是比较适合在此处应用的, 比如逻辑回归、KNN、k-means、隔离森林等算法。
还有基于深度学习的循环神经网络 RNN算法和长短期记忆网络LSTM算法,比较适合处理和预测时间序列中间隔和延迟相对较长的重要事件。
基于机器学习的众多算法,都可以大大的提高运维的效率,发现人工难以发现的问题,提高预警的及时性和准确度。
(3)异常检测模型优化
上一小节提到的各类机器学习算法,虽然功能强大,但是往往都有一定的局限性,那么我们在对具体的一个场景指标(如响应时间)做异常检测的时候,我们到底选哪个算法呢?
方法一:这个问题可以通过“自动模型选取”方式来解决,即采用多个算法同时运行,然后通过投票的方式抉择产生最终的结果。
举个例子,针对“响应时间”指标进行异常检测,采用同比、环比、ARIMA、LSTM、KNN、高斯共5个算法同时进行异常检测,当其中的一半(即>=3)的算法判定为异常时,方认为该时刻的指标是异常的。
方法二:在方法一的基础上为每个算法加入权重值,5种算法初始值均为20(总合为100),当一次异常的判断后,比如算法1/2/3都判定是异常,算法4/5都判定为非异常,那么最终结果为判定为异常,系统向运维人员发出告警,当运维人员在平台上通过指标横向对比、请求下钻、事件挖掘之后发现该时刻的指标确实为异常,那么运维人员会将这个告警处理掉,那么此时后台就会默认向投票正确的算法的权重倾斜,为其权重加1,同时为投票错误的算法权重扣分(但总分仍保持100分);而如果运维人员发现该告警是误报,则会在平台上反馈“误报”,则后台会向投票为非异常的算法权重倾斜,为每个算法权重加1,同时为投票为异常的算法权重扣分(但总分仍保持100分)。如此经过长时间的不断调整,算法组合就越来越接近于准确。
4.2 故障定位
在异常检测技术针对故障做出迅速预警之后,就需要进一步的去定位故障的根因,这也是AIOPS中一个比较核心的领域,一般的故障定位方法包括如下几种:
- 传统方法:通过查看日志实现,此方法下定时故障的时间一般较长;
- 通过APM软件:为应用部署APM探针,实现代码级别的错误下钻查看;
- 告警关联分析:通过告警之间的关联,推测出导致故障的根因告警。
以上方法(1)是传统的方法,不可取;方法(2)需要应用部署探针方可,当故障发生之后再部署探针,显然无济于事;而方法(3)下,告警之间的关联方法只是找出了一个相对可能性较大的根因告警,但是这个告警是怎么发生的仍然无法知悉,另外该告警体现的也只是一个瞬时的值,可能针对该告警指标已经上报了多条告警,那么也无法判断。
基于上述方法中的问题,本文中将提出“基于数据跨层关联的故障传播链”的故障定位方法,实现针对故障根因的准确定位。
本方法通过“数据分层”以及“基于变化的跨层关联分析”作为核心点。该方法的简单流程图/协作数据流图如下(以一个大数据平台为例子介绍):
图2 基于数据跨层关联的故障传播链故障定位设计图
4.2.1数据分层
将整个应用运行的环境分为三个层面,如下
(1)app层:应用层,运行在平台上的各类应用,例如用户提交的批处理程序“定时计算有推广商业短信价值的用户名单”Job,或图处理程序“计算潜在用户画像”Job,亦或是实时流处理程序“实时发现钓鱼短信”Job等;
(2)platform层:平台层,app层的各类程序,包括批处理、图处理、流处理、深度学习等多种类型程序都运行在platform层提供的运行组件环境中,如storm、spark、hadoop、zookeeper、tensorflow、hbase、kafka等组件;
(3)device层:设备层,即Iaas层,例如服务器、虚拟机、容器等软硬计算设备的运行时环境,也包括如防火墙、路由器、交换机等网络控制面设备运行时环境等。
4.2.2故障定位原理
(1)针对app层、platform层、device等的各项指标进行采集;
(2)设定故障原因的方向为device层àplatform层àapp层,即app层的故障一般都来自于platform层,同样platform层的指标的异常可能由于下一层device层指标异常引起;
举例说明,如上图中,假设app层的“spark time cost”指标发现了数值上的异常,并且通过平台发出了告警,同时通过阈值也发现了platform层的“zookeeper timeout avg”指标(即zookeeper平均超时时间)发生指标告警,以及device层也发出了多条告警,如“netflow size”(即网路流量)指标异常告警等。通过本平台的智能关联算法,判断得出“故障传播链”为“netflow size”异常à“zookeeper timeout avg” 异常à“spark time cost” 异常,那么导致最上层“spark time cost”故障的原因来自device层的“netflow size”异常。
(3)基于2的判断结果,可以向平台用户发送最终故障原因内容,即device设备层的网络流量过大导致了app业务层的spark任务运行时间过大,波及业务。
4.2.3故障传播链
4.2.2章节中的(2)中描述的“故障传播链”实现方法如下:
(1)为三层的各项数据序列进行变化模型的构建,即构建出的新模型new-model体现的是原始指标模型origin-model变化的规律;
(2)为三层所有指标设定三层阈值,且阈值设定为矢量方式,即包含变化率change-rate(简称CR)和变化方向change-direction(简称CD):
一层阈值设定原则:5%<CR<20%,CD任意,代表指标微变;
二层阈值设定原则:20%<=CR<50%,CD任意,代表指标中变;
二层阈值设定原则:50%<=CR,CD任意,代表指标巨变。
(3)针对任何指标的变化,通过2中的设定原则,定义指标的变化等级(微变、中变、巨变)和方向,分别记录为异常警示,在此规则下,新的异常模型定义则类似为“platfom:zookeeper timeout avg:巨变:变大” 、“platfom:hbase iops:中变:变大” 、“device:netflow size:微变:变大”;
(4)经过长时间的积累,当平台报告除了app层的故障时,则根据如下规则寻找故障下层传播源节点,举例:app层的“spark time cost”故障产生时,选取该故障发生时刻前后各5分钟内的其他层指标异常列表,通过频繁项集算法FP-GROWTH计算得出最佳置信度(最可靠)的频繁项组合(例如“device:netflow size:微变:变大”à“platfom:zookeeper timeout avg:巨变:变大”à“spark time cost”故障),则故障传播链则可以确定。
(5)经过长时间积累,FP-GROWTH算法得出了多条可靠故障传播链条,涵盖了所有app层故障的故障传播链,前面的众多描述中,故障传播链都是单线条链路,即AàBàC,其实也可以是树形结构的,即A+BàCàD,代表着A和B同时发生时,会导致C发生,进一步导致app层的D故障发生,针对所有最佳故障传播链路进行存储;
(6)那么反向推理克制,当下次底层某特定的故障发生时,则可以推导出上层故障即将发生(例如A和B发生了,那么C故障就会发生了,在C发生前就可以预警,进行故障干预,避免C故障的发生),实现了预警,降低业务影响和损失的目的。
5 结论及未来工作
本文针对构建AIOPS系统需要的研究路径、通用架构、关键技术点做了阐述,并且针对AIOPS中最关键的“异常检测”和“故障定位”两个话题展开了比较详细的分析和设想,让AIOPS的落地更加可行、更加切合业务实际,同时让运维人员以更低的成本运用人工智能技术来服务于电信运维工作。
下一步的工作重点将是进一步提高异常检测和故障定位的准确度,同时针对故障自愈进行探索,并在更合适的运维场景寻求最切合的方法来实现AIOPS的逐渐落地。
参考文章:
https://blog.csdn.net/bishenghua/article/details/135185321
https://blog.csdn.net/bishenghua/article/details/135217477


)

)














