这里以谷歌浏览器为例,需要安装一下chromedriver,其他浏览器也有相对应的driver,chromedriver下载地址:https://googlechromelabs.github.io/chrome-for-testing/
然后是打开python环境安装一下依赖pip install selenium,验证一下控制浏览器是否成功
# -*- coding: utf-8 -*-
from selenium import webdriverdriverPath = r'D:\chromedriver-win64\chromedriver.exe'
driver = webdriver.Chrome(executable_path=driverPath)
url = 'http://www.baidu.com'
driver.get(url)
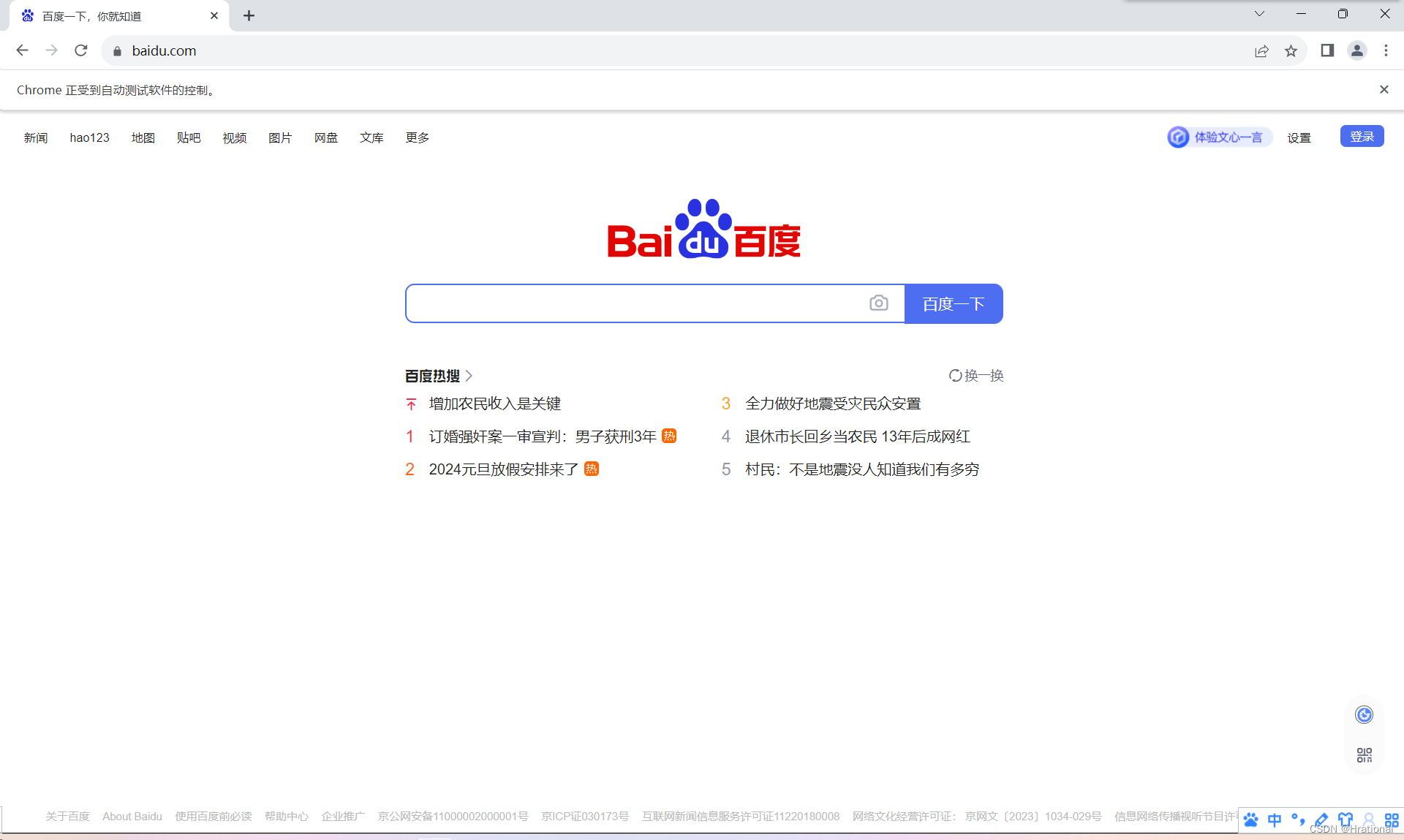
点击运行脚本可以看到以下页面就成功了。
爬虫的话需要使用到以下相关函数:
driver.find_element_by_class_name("class") # 通过class属性值定位
driver.find_element_by_id("id") # 通过id值定位
driver.find_element_by_name("name") # 通过属性名称定位
driver.find_element_by_css_selector("selector") # 通过css选择器定位,格式是(‘标签名[属性名=”属性值”]’)
driver.find_element_by_link_text("text") # 通过超链接文本定位
driver.find_element_by_tag_name("tag") # 通过标签定位
driver.find_element_by_xpath("path") # 通过xpath路径定位
还有其他的输入操作send_keys和点击操作click()等等这些基本上满足浏览器的大部分操作需求


仓库内容更新,使用TortoiseGit同步本地仓库和远程仓库)



)

(Leetcode) C++递归实现(超详细))










