文章目录
- 前言
- 事故现场
- 问题分析
- 是否是整个域名解析服务当时都出问题了
- 是否是出问题的pods本身的域名解析有问题
- 异常发生的全部过程
- 域名的解析是什么时候发生的,怎么发生的
- 域名解析的详细流程
- 重试发生在什么地方
- 为什么重试会无效
- Bugfix
- 代码详解
- 关于StandardHostResolver和QualifiedHostResolver
- 关于InetAddress
- 关于InetSocketAddress
- 相关文章
前言
我们的HDFS客户端是来自一个Druid的一个分钟级的scheduled job,每分钟会并发提交10个左右的Application到Yarn集群,提交Job的Druid的客户端运行在一个K8S集群的不同的pods中。
我们发现,偶尔,提交Job的时候,HDFS客户端会出现UnknownHostException异常,这种异常发生在Job提交到Yarn集群以前,即发生在将用户的jar包上传到HDFS,还不到Application提交的阶段,所以这个异常跟Yarn集群没有任何关系。
整个异常持续达到20分钟异常,经过不断重试,最终这个Druid的task失败,我们收到报警。重试task,成功。
我们第一反应是联系DevOps,查看对应的pods上的域名解析服务是否出现问题。不过很显然,这种偶发的、不可重现的问题要想找到原因是很困难的。所以我们尝试从HDFS层面查找根本原因并解决问题。
我想,我们维护任何一个开源系统,要想它变得越来越稳定,都是通过一次又一次地定位并解决问题才能达到的,有时候这个问题的解决可能只需要几行代码,但是找到这几行代码,却可能花掉几天时间。可是当问题通过这几天的努力得到优雅的解决而不再出现,就是一个大数据基础设施工程师的价值。一个大型系统如果持续处于这样一种稳定的不断优化中,那就会越来越稳定。从我们多年的经验来看,通过盲目的系统升级,最多只能带给我们一些新的特性,但是往往无法给我们带来更好的稳定性。
之前看过一个纪录片,讲述最先进的空客A380的驾驶,空客A380相较于早起的客机更加智能,更多的工作交给了飞行电脑,驾驶舱从之前的空客A320的无数的机械按钮,在A380中全部变成了一个一个的显示屏,但是当记者问A380的驾驶员,驾驶A380是否比驾驶A320更轻松,驾驶员回答:并没有,这种技术的革新只是带来了驾驶方式的改变,并没有让驾驶更简单,也没有让飞机更安全。
我想,大数据系统的升级也是类似的道理。升级绝不是一劳永逸,也无法毕其功于一役,最终,我们依然要正视并解决每一个问题。
事故现场
Task失败的时候,是客户端在提交application以前会先尝试在HDFS上创建目录以存放application运行过程中的相关文件,但是抛出UnknownHostException异常,显然,这是因为客户端无法解析hdfs-site.xml中配置的NameNode的hostname:
---------------------------连接到Active NN时抛出的HostNotFoundException--------------------
2023-12-01T20:38:07,780 WARN [task-runner-0-priority-0] org.apache.hadoop.hdfs.DFSUtilClient - Namenode for druidhottier remains unresolved for ID namenode289. Check your hdfs-site.xml file to ensure namenodes are configured properly.
2023-12-01T20:38:08,166 INFO [task-runner-0-priority-0] org.apache.hadoop.io.retry.RetryInvocationHandler - Exception while invoking ClientNamenodeProtocolTranslatorPB.mkdirs over hadoop113-7c.dai3.prod.mycorp.com:8020 after 1 failover attempts. Trying to failover after sleeping for 1409ms.
java.net.UnknownHostException: Invalid host name: local host is: (unknown); destination host is: "rccp113-7c.dai3.prod.mycorp.com":8020; java.net.UnknownHostException; For more details see: http://wiki.apache.org/hadoop/UnknownHost..............at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:744) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.Client$Connection.<init>(Client.java:446) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.Client.getConnection(Client.java:1530) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.Client.call(Client.java:1381) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.Client.call(Client.java:1345) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116) ~[hadoop-common-2.8.5.jar:?]at com.sun.proxy.$Proxy214.mkdirs(Unknown Source) ~[?:?]at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.mkdirs(ClientNamenodeProtocolTranslatorPB.java:583) ~[hadoop-hdfs-client-2.8.5.jar:?]at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_332]at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_332]at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_332]at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_332]at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:409) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:346) ~[hadoop-common-2.8.5.jar:?]at com.sun.proxy.$Proxy215.mkdirs(Unknown Source) ~[?:?]at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:2472) ~[hadoop-hdfs-client-2.8.5.jar:?]..........at org.apache.druid.indexer.JobHelper.addJarToClassPath(JobHelper.java:209) ~[druid-indexing-hadoop-2022.01.9-lts-iap.jar:2022.01.9-lts-iap]
Caused by: java.net.UnknownHostException
然后,HDFS客户端开始尝试通过Failover连接到另外一台NameNode,但是显然,另外一台NameNode是Standby NameNode,尽管对Standby NameNode的域名解析成功,但是抛出了Operation category WRITE is not supported in state standby异常,这是预期之内的:
---------------------------------Failover重试失败的异常-----------------------------------
2023-12-01T20:38:09,583 INFO [task-runner-0-priority-0] org.apache.hadoop.io.retry.RetryInvocationHandler - Exception while invoking ClientNamenodeProtocolTranslatorPB.mkdirs over hadoop112-7c.dai3.prod.mycorp.com/12.7.2.184:8020 after 2 failover attempts. Trying to failover after sleeping for 2055ms.
org.apache.hadoop.ipc.RemoteException: Operation category WRITE is not supported in state standby. Visit https://s.apache.org/sbnn-errorat org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.checkOperation(StandbyState.java:88)at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.checkOperation(NameNode.java:1835)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkOperation(FSNamesystem.java:1483)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:4385)at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:4367)at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.mkdirs(NameNodeRpcServer.java:873)at org.apache.hadoop.hdfs.server.namenode.AuthorizationProviderProxyClientProtocol.mkdirs(AuthorizationProviderProxyClientProtocol.java:323)at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.mkdirs(ClientNamenodeProtocolServerSideTranslatorPB.java:618)at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:617)at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1073)at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2217)at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2213)at java.security.AccessController.doPrivileged(Native Method)at javax.security.auth.Subject.doAs(Subject.java:422)at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1917)at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2211)at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1489) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.Client.call(Client.java:1435) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.Client.call(Client.java:1345) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116) ~[hadoop-common-2.8.5.jar:?]at com.sun.proxy.$Proxy214.mkdirs(Unknown Source) ~[?:?]at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.mkdirs(ClientNamenodeProtocolTranslatorPB.java:583) ~[hadoop-hdfs-client-2.8.5.jar:?]at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[?:1.8.0_332]at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[?:1.8.0_332]at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_332]at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_332]at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:409) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:163) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:155) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95) ~[hadoop-common-2.8.5.jar:?]at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:346) ~[hadoop-common-2.8.5.jar:?]at com.sun.proxy.$Proxy215.mkdirs(Unknown Source) ~[?:?]at org.apache.hadoop.hdfs.DFSClient.primitiveMkdir(DFSClient.java:2472) ~[hadoop-hdfs-client-2.8.5.jar:?]
然后,HDFS的Failover重试了15次,到达了重试失败上线,错误抛给了Druid的客户端,然后Druid客户端总共会尝试4次,但是依然无法成功,因此总共进行了4 * 15 = 60次的Failover Retry Attempt,然后Druid task 失败。
关于HDFS客户端通过动态代理的方式的异常处理和重试过程,可以参考我的另外一篇文章《HDFS基于动态代理的客户端运行逻辑》。默认情况下,我们配置的Failover重试次数dfs.client.failover.max.attempts默认是15,普通重试次数 dfs.client.retry.max.attempts默认值是10。在我们的case中,是Failover的重试次数到达了15次,然后失败,然后在Druid层面再重试。最终域名解析始终不成功,并导致整个Druid task最终失败。
整个重试到最后失败的过程持续了30分钟。
问题分析
是否是整个域名解析服务当时都出问题了
不可能。
- 发生问题的时候,还有其他并行的task在正常提交和运行,因此,这说明整个域名解析服务没有出问题。问题似乎是这个pod的孤立问题。
是否是出问题的pods本身的域名解析有问题
有可能。
但是不清楚问题发生在哪一层,可能在HDFS的Java虚拟机层,也有可能出现在pods这一系统层。
但是有一点是非常确定的,虽然持续了30分钟的域名解析持续失败,但是,在这个客户端失败的过程中,居然有其他的task在这个pods上提交并运行成功。这说明,虽然task失败了30分钟,但是这个pod上的域名解析服务根本没有失效那么久,很可能只是闪断了很短的时间。
既然这样,为什么重试无法奏效?
异常发生的全部过程
所以,问题从“为什么这个pod会发生好几次短暂的域名解析失败”,变成“HDFS客户端为什么无法从短暂的域名解析失败中自动重试成功并恢复”?
从错误堆栈,我们确认了客户端的HDFS代码是社区版的HDFS 2.8.5。我们开始在代码层面查找原因。
从下面的异常堆栈可以看到,每次异常发生的时候,都是Client尝试构造一个Client.Connection对象,然后在构造Client.Connection的过程中抛出异常:
at org.apache.hadoop.ipc.Client$Connection.<init>(Client.java:446) ~[hadoop-common-2.8.5.jar:?]
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1530) ~[hadoop-common-2.8.5.jar:?]
at org.apache.hadoop.ipc.Client.call(Client.java:1381) ~[hadoop-common-2.8.5.jar:?]
at org.apache.hadoop.ipc.Client.call(Client.java:1345) ~[hadoop-common-2.8.5.jar:?]
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:227) ~[hadoop-common-2.8.5.jar:?]
----------------------------------Client.Connection---------------------------------
public Connection(ConnectionId remoteId, int serviceClass) throws IOException {.................this.server = remoteId.getAddress(); // this.server是一个InetSocketAddress对象if (server.isUnresolved()) {throw NetUtils.wrapException(server.getHostName(),server.getPort(),null,0,new UnknownHostException());}.............
从上面的Client.Connection的构造方法可以看到,是因为InetSocketAddress.isUnresolved()返回了True。
下文会讲到,InetSocketAddress保存了域名解析的结果,isUnresolved()返回True,说明域名解析失败。
那么,域名解析是什么时候发生的?重试难道不重新解析域名吗?
域名的解析是什么时候发生的,怎么发生的
在HA的场景下,为了构造HA层面的动态代理,是ConfiguredFailoverProxyProvider提供了基于Failover的、出错情况下可以进行不断切换的针对每一台NameNode的动态代理。
在客户端构造DFSClient的时候,会构造对应的ConfiguredFailoverProxyProvider,构造时将解析我们配置的多个NameNode的域名并封装成InetSocketAddress,然后将解析完成的每一个InetSocketAddress封装在AddressRpcProxyPair中,多个Proxy放在一个protected final List<AddressRpcProxyPair<T>> proxies中:
---------------------------------ConfiguredFailoverProxyProvider-------------------------------// ConfiguredFailoverProxyProvider的构造方法ConfiguredFailoverProxyProvider(Configuration conf, URI uri,Class<T> xface, ProxyFactory<T> factory) {.......Map<String, Map<String, InetSocketAddress>> map =DFSUtilClient.getHaNnRpcAddresses(conf); // 将配置文件中的NN的hostname解析成InetSocketAddress对象Map<String, InetSocketAddress> addressesInNN = map.get(uri.getHost());Collection<InetSocketAddress> addressesOfNns = addressesInNN.values();for (InetSocketAddress address : addressesOfNns) { // 为每一个Target NameNode构建Proxyproxies.add(new AddressRpcProxyPair<T>(address));}// 一个AddressRpcProxyPair对象封装了一个InetSocketAddress对象private static class AddressRpcProxyPair<T> {public final InetSocketAddress address;public T namenode;public AddressRpcProxyPair(InetSocketAddress address) {this.address = address;}}
所以,到这一步,域名解析已经完成,由于域名解析可能失败,这一步可能没有解析出来有效的IP地址。但是Hadoop的逻辑是,无论域名解析是否成功,在域名解析阶段都不会抛出异常,仅仅是打印一行warn日志,如下所示(在上文的堆栈中也贴出来了)。
注意,这里仅仅是在域名解析阶段不抛出异常,不代表后面的真正连接阶段也不抛出异常。
2023-12-01T20:38:07,780 WARN [task-runner-0-priority-0] org.apache.hadoop.hdfs.DFSUtilClient - Namenode for druidhottier remains unresolved for ID namenode289. Check your hdfs-site.xml file to ensure namenodes are configured properly.
然后,返回一个封装了无解析结果的特殊InetSocketAddress,客户端自己根据需要调用InetSocketAddress.isUnresolved()去判断这个域名解析是否成功:
------------------------------------------ NetUtils -------------------------------------------
public static InetSocketAddress createSocketAddrForHost(String host, int port) {......} catch (UnknownHostException e) { // 如果域名解析失败,创建一个特殊的InetSocketAddress,而不是抛出异常addr = InetSocketAddress.createUnresolved(host, port);}
下面的代码显式了构造一个没有解析IP地址的InetSocketAddress对象,其ip地址为空。
-----------------------------------InetSocketAddress--------------------------------------
public static InetSocketAddress createUnresolved(String host, int port) {return new InetSocketAddress(checkPort(port), checkHost(host));
}// private constructor for creating unresolved instances
private InetSocketAddress(int port, String hostname) {holder = new InetSocketAddressHolder(hostname, null, port); // addr即ip地址为空
}private boolean isUnresolved() {return addr == null;
}
所以,截止到这里,域名解析已经完成(尽管是失败的)。
我们在后面会讲到,尽管域名解析失败,但是在后续的重试中,却从来都没有尝试对域名重新解析,而是一直使用当前解析失败的InetSocketAddress进行重新连接。这就是为什么后来尽管环境中域名解析服务已经恢复,但是重试却无效。
域名解析的详细流程
上面已经讲到过域名解析(即构造InetSocketAddress对象)发生在客户端构造ConfiguredFailoverProxyProvider的时候,我们来看一下这个构造的具体逻辑。
我们查看DFSUtilClient.getHaNnRpcAddress()方法,可以看到最后的域名解析是在NetUtils.createSocketAddrForHost()中进行的:
---------------------------- org.apache.hadoop.net.NetUtils ----------------------------------------public static InetSocketAddress createSocketAddrForHost(String host, int port) {String staticHost = getStaticResolution(host); // 如果存在静态解析的配置,那么先将当前的host映射成我们配置的静态hostname,然后再解析域名String resolveHost = (staticHost != null) ? staticHost : host;InetSocketAddress addr;try {InetAddress iaddr = SecurityUtil.getByName(resolveHost); //将hostname解析成IP,封装在java.net.InetAddress// if there is a static entry for the host, make the returned// address look like the original given hostif (staticHost != null) {iaddr = InetAddress.getByAddress(host, iaddr.getAddress());}addr = new InetSocketAddress(iaddr, port);} catch (UnknownHostException e) { // 如果解析失败,会创建一个代表域名无法解析的InetAddress对象addr = InetSocketAddress.createUnresolved(host, port);}return addr;}
域名解析的过程,就是根据客户端配置的NameNode的域名(也有可能配置的是IP地址),通过域名解析,将解析后IP地址封装在InetSocketAddress中。InetSocketAddress封装了域名解析的结果InetAddress和对应的端口port。InetAddress是解析结果的封装,包括了域名本身(下面会讲到,根据不同的HostResolver实现,这里的域名可能已经不是我们传入的或者配置文件中配置的NameNode的初始域名)和解析以后的IP地址。
createSocketAddrForHost()解析域名的过程是:
- 如果用户配置了相关的静态域名映射,那么先获取这个域名host背后的真实域名,放在
resolveHost中; - 调用
SecurityUtil.getByName()获取解析以后的InetAddress。InetAddress封装了域名和解析得到的IP地址; - 如果刚刚进行了静态域名映射,那么通过
InetAddress.getByAddress()对InetAddress()进行重新封装,将host替换成映射以前用户传入的host; - 将
InetAddress和端口封装到InetSocketAddress中。
静态域名映射:
这个主要是为了在测试中定义多个实际上指向同一物理域名的多个虚假域名,比如在一些测试中,我们需要在一台机器上完成一个多NameNode、多DataNode的全分布式的HDFS的测试,需要在这一台机器上运行具有不同hostname的进程,就可以为这些进程分配不同的虚假域名,但是它们都指向localhost这个域名。
那么,SecurityUtil.getByName()是怎么解析域名的呢?主要是通过HostResolver接口的具体实现来完成的。
---------------------------------------SecurityUtil---------------------------------------@Privatepublic static InetAddress getByName(String hostname) throws UnknownHostException {....return hostResolver.getByName(hostname); //根据目前的hostResolver进行域名解析.....}// 这里的flag就是配置项hadoop.security.token.service.use_ip的值public static void setTokenServiceUseIp(boolean flag) {useIpForTokenService = flag;hostResolver = (HostResolver)(!useIpForTokenService ? new QualifiedHostResolver() : new StandardHostResolver());}
从上面的代码可以看到,SecurityUtil委托具体的HostResolver接口的实现类来进行域名解析。根据配置项hadoop.security.token.service.use_ip的值,决定了使用哪个实现类,StandardHostResolver或者QualifiedHostResolver。
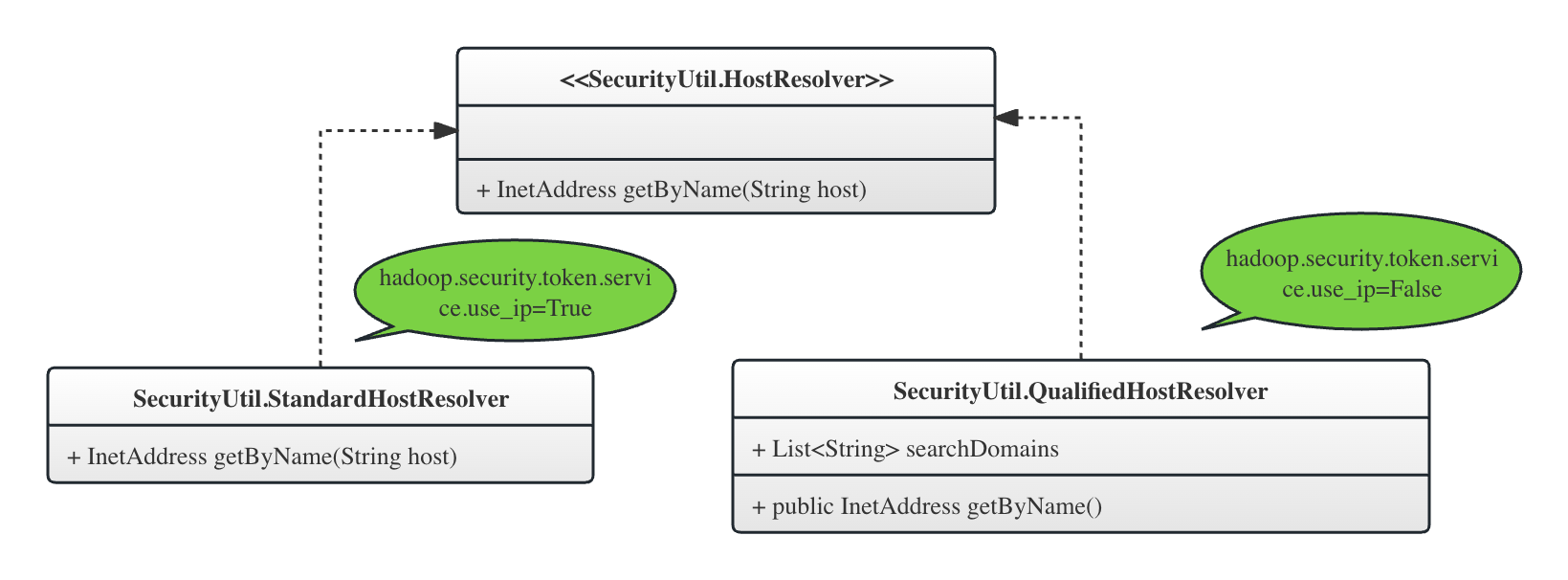
HostResolver接口就一个方法,getByName(),传入域名,获取解析结果InetAddress:
-------------------------------------HostResolver----------------------------------------static class StandardHostResolver implements HostResolver {// StandardHostResolver就是直接调用InetAddress.getByName方法,不做任何其他处理public InetAddress getByName(String host) throws UnknownHostException {return InetAddress.getByName(host);}}interface HostResolver {InetAddress getByName(String host) throws UnknownHostException; }
关于hadoop.security.token.service.use_ip,可以参考hadoop的官方文档关于它的解释:
hadoop.security.token.service.use_ip:
Controls whether tokens always use IP addresses. DNS changes will not be detected if this option is enabled. Existing client connections that break will always reconnect to the IP of the original host. New clients will connect to the host’s new IP but fail to locate a token. Disabling this option will allow existing and new clients to detect an IP change and continue to locate the new host’s token.
网络上没有太多对这个参数的更深入的解释,我们结合代码去理解这个配置项:
------------------------------------SecurityUtil--------------------------------------@InterfaceAudience.Private@VisibleForTestingpublic static void setTokenServiceUseIp(boolean flag) {useIpForTokenService = flag;hostResolver = !useIpForTokenService? new QualifiedHostResolver() // 用户设置useIpForTokenService为false,使用QualifiedHostResolver: new StandardHostResolver(); // useIpForTokenService默认为True,使用StandardHostResolver}public static Text buildTokenService(InetSocketAddress addr) {String host = null;if (useIpForTokenService) {host = addr.getAddress().getHostAddress();// 获取对应的IP地址,注意当useIpForTokenService=true,使用的是StandardHostResolver,获取ip地址是需要进行域名解析的} else {host = addr.getHostName().toLowerCase();// 获取对应的hostname, 注意当useIpForTokenService=false,使用的是QualifiedHostResolver,它的Host已经是FQDN}return new Text(host + ":" + addr.getPort());}
从上面的SecurityUtil的代码可以看到,hadoop.security.token.service.use_ip的值在两个方面对系统产生影响,1)决定了 HostResolver的具体实现类,2)决定了DelegationToken的名字的构造。
即:
- 当
hadoop.security.token.service.use_ip是True(这是默认设置),将会使用StandardHostResolver作为HostResolver的具体实现。StandardHostResolver返回的InetAddress封装了传入的原始的host和解析以后的ip地址。大多数用户不会修改这个默认值。我们的系统也是使用的默认配置。- 这时候,DNS的映射改变(比如NameNode机器发生故障,我们进行了机器的替换,新的机器有新的IP地址,但是域名不变),通过
SecurityUtil.buildTokenService()方法可以看到,客户端使用InetAddress提供的IP地址作为DelegationToken的名字。因此如果IP地址改变,已有的客户端还是使用原有的IP地址连接,并且token由于使用原来的IP地址,因此也不再正确。
- 这时候,DNS的映射改变(比如NameNode机器发生故障,我们进行了机器的替换,新的机器有新的IP地址,但是域名不变),通过
- 当
hadoop.security.token.service.use_ip被显式配置为False,将会使用QualifiedHostResolver作为HostResolver的具体实现。- 这时候使用如果发生了DNS映射的改变,通过
SecurityUtil.buildTokenService()方法可以看到,客户端使用InetAddress提供的hostname作为DelegationToken的名字。并且由于使用的是QualifiedHostResolver,因此这个hostname其实是FQDN。这时候如果DNS映射发生变化,比如域名背后的机器发生了替换,由于FQDN不变,因此连接不受影响,IP地址会被InetAddress解析的时候自动update。 - 下文会详细讲解两种
HostResolver的具体实现
- 这时候使用如果发生了DNS映射的改变,通过
重试发生在什么地方
现在,客户端已经进行了域名解析,但是很可惜,解释失败,拿到了一个没有解析成功的InetSocketAddress
从上文的异常堆栈可以看到,当客户端进行了相关操作的调用,比如,在本文中的mkdirs()操作的时候,基于Protobuf的连接在在连接层是通过org.apache.hadoop.ipc.Client(以下简称Client)来管理Client.Connection的。
Client会通过调用Client.getConnection()方法获取一个Client.Connection对象,这个对象应该是封装好的到某一个NameNode的连接。
在HA的环境下有多个NameNode,所以Client将每一个连接维护在一个private ConcurrentMap<ConnectionId, Connection> connections中,这个map的key是一个Client.ConnectionId,对应了一个远程的NameNode,value是一个Client.Connection对象,代表了和这个NameNode建立好的RPC连接。
当调用getConnection()对象的时候,通过ConnectionId remoteId查找对应的Client.Connection,如果不存在,就创建这个remoteId对应的Connection并保存在connections中,以后,这个客户端对这个remoteId就使用这个Client.Connection。所以,连接的建立是lazy的,即在构造的时候只是进行域名的解析,并不建立连接,连接建立发生在真正进行RPC调用的时候。
----------------------------------------Client--------------------------------------------
// 如果抛出异常,上层的重试机制会不断重新调用getConnection()
private Connection getConnection(ConnectionId remoteId,Call call, int serviceClass, AtomicBoolean fallbackToSimpleAuth)throws IOException {.....Connection connection;........while (true) {// These lines below can be shorten with computeIfAbsent in Java8connection = connections.get(remoteId);if (connection == null) {connection = new Connection(remoteId, serviceClass);Connection existing = connections.putIfAbsent(remoteId, connection);if (existing != null) {connection = existing;}}异常的抛出发生在Client.Connection的构造方法中:
-----------------------------------Client.Connection----------------------------------public Connection(ConnectionId remoteId, int serviceClass) throws IOException {this.remoteId = remoteId;this.server = remoteId.getAddress(); // getAddress()返回的是InetSocketAddress对象if (server.isUnresolved()) { // 在这里抛出异常throw NetUtils.wrapException(server.getHostName(),server.getPort(),null,0,new UnknownHostException());}
显然,server.isUnresolved()永远返回True,这里的server是一个InetSocketAddress对象。
为什么重试会无效
上文其实已经说过,重试失败的原因是,域名解析失败,后续的重试只是在重新建立连接,但是却从来没有重新进行域名解析并构造新的InetSocketAddress。
在执行mkdirs()方法的时候,客户端会将在构造ConfiguredFailoverProxyProvider的时候解析好的InetSocketAddress等信息封装成一个Client.ConnectionId对象。一个Client.ConnectionId封装了域名解析结果InetSocketAddress对象、当前的协议信息、当前的UGI信息、timeout配置、重试配置RetryPolicy以及整个配置项Configuration。这样封装的意图是,上面任何一项信息发生变化,比如,发现RetryPolicy有了变化,或者Configuration中的任何信息发生变化,我们都认为客户端的连接上下文发生了变化,我们都必须重新构造Client.Connection对象:
封装和构造Client.ConnectionId的过程发生在底层RPC层的动态代理的代理主题角色的构造方法中:
------------------------------ProtobufRpcEngine.Invoker--------------------------------private Invoker(Class<?> protocol, InetSocketAddress addr,UserGroupInformation ticket, Configuration conf, SocketFactory factory,int rpcTimeout, RetryPolicy connectionRetryPolicy,AtomicBoolean fallbackToSimpleAuth) throws IOException {this(protocol, Client.ConnectionId.getConnectionId(addr, protocol, ticket, rpcTimeout, connectionRetryPolicy, conf),conf, factory // 将相关的连接信息封装成Client.ConnectionId对象);.......}
构造细节如下所示。我们必须详细看一下Client.ConnectionId.equals()方法,因为这涉及到判断两个ConnectionId是否是相同的ConnectionId的判断逻辑,即客户端在调用Client.getConnections()方法的时候,怎么判断对应的Connection是存在因此不需要新创建的。
下面的方法显示了根据当前的InetSocketAddress等连接信息封装成一个ConnectionId信息:
-------------------------------Client.ConnectionId-----------------------------// 构造一个ConnectionId对象,封装了对应的InetSocketAddress,static ConnectionId getConnectionId(InetSocketAddress addr,Class<?> protocol, UserGroupInformation ticket, int rpcTimeout,RetryPolicy connectionRetryPolicy, Configuration conf) throws IOException {return new ConnectionId(addr, protocol, ticket, rpcTimeout,connectionRetryPolicy, conf);}@Overridepublic boolean equals(Object obj) {if (obj == this) {return true;}if (obj instanceof ConnectionId) {ConnectionId that = (ConnectionId) obj;return isEqual(this.address, that.address)&& this.doPing == that.doPing&& this.maxIdleTime == that.maxIdleTime&& isEqual(this.connectionRetryPolicy, that.connectionRetryPolicy)&& this.pingInterval == that.pingInterval&& isEqual(this.protocol, that.protocol)&& this.rpcTimeout == that.rpcTimeout&& this.tcpNoDelay == that.tcpNoDelay&& isEqual(this.ticket, that.ticket);}return false;}
从上面的equals()方法可以看到,基本上对Client.ConnectionId的各个成员进行了比较,只有所有信息都相同,才会认为是一个Client.ConnectionId:
Client在在以一个Client.ConnectionId为key来调用Client.getConnection()的时候,会先尝试从private Hashtable<ConnectionId, Connection> connections中去获取,如果获取成功,就返回Connection对象,失败,则需要重新构造Client.Connection对象:
private Connection getConnection(ConnectionId remoteId,Call call, int serviceClass, AtomicBoolean fallbackToSimpleAuth)throws IOException {........Connection connection;do {synchronized (connections) {connection = connections.get(remoteId);// 以ConnectionId为key,获取对应的Connectionif (connection == null) {connection = new Connection(remoteId, serviceClass);connections.put(remoteId, connection);}}} while (!connection.addCall(call));
在构造Connection的时候,对InetSocketAddress中的域名是否已经resolve进行了检查,如果失败了,则抛出UnknownHostException异常,异常抛出到Failover层面的带有Failover重试机制,尝试另外一个NameNode,另外一个NameNode则由于是Standby也抛出异常,然后再重试当前的Active NameNode。但是,对于当前的ActiveNameNode,始终没有重新进行域名解析,使用的依然是以前的InetSocketAddress,显然会永远失败:
public Connection(ConnectionId remoteId, int serviceClass) throws IOException {this.remoteId = remoteId;this.server = remoteId.getAddress(); //获取ConnectionId中封装的InetSocketAddressif (server.isUnresolved()) { //查看这个InetSocketAddress是否已经成功解析throw NetUtils.wrapException(server.getHostName(),server.getPort(),null,0,new UnknownHostException());}
Bugfix
所以,问题的关键是,当发生域名解析失败的时候,我们需要重新构造InetSocketAddress,即重新进行域名解析,这样,Client.Connection()就不会再抛出异常。
我们找到了对应的bugfix,在Hadoop-15129中,对应的patch文件是Hadoo-15129.002.patch。
它的基本思路是,如果发生比如连接异常或者HostNotFoundException异常,ipc.Client会捕获异常并在catch block中通过调用ipc.Client.updateAddress()方法重构并更新InetSocketAddress,然后进行后续的重试。
但是由于代码逻辑问题,构造Connection对象抛出HostNoutFoundException不在这部分的代码块中,无法触发ipc.Client.updateAddress()。
下面的代码显式了这部分逻辑。ipc.Client.updateAddress()的调用发生在connection.setupIOstreams -> connection.setupConnection(),因此在setupIOstreams()调用以前发生的HostNotFoundException没有被正确处理。
------------------------------------------Client---------------------------------------------/** Get a connection from the pool, or create a new one and add it to the* pool. Connections to a given ConnectionId are reused. */private Connection getConnection(ConnectionId remoteId,Call call, int serviceClass, AtomicBoolean fallbackToSimpleAuth)throws IOException {.........while (true) {// These lines below can be shorten with computeIfAbsent in Java8connection = connections.get(remoteId);if (connection == null) {connection = new Connection(remoteId, serviceClass);Connection existing = connections.putIfAbsent(remoteId, connection);.............connection.setupIOstreams(fallbackToSimpleAuth); // 原有的代码在这个方法里会捕获异常并通过updateAddress()方法重新构造InetSocketAddress,因此前面new Connection()抛出的异常无法触发InetSocketAddress的更新return connection;}
Bugfix的方式就是把抛出异常的位置挪到了setupIOstreams() -> setupConnection()中,这样,发生HostNotFoundException的异常能够被捕获并调用updateAddress()进行InetSocketAddress的重新构造和更新。
代码详解
关于StandardHostResolver和QualifiedHostResolver
StandardHostResolver和QualifiedHostResolver都是域名解析HostResolver的具体实现,而且都定义在文件HostResolver.java中。两个实现类都要具体实现getByName()的接口方法,该方法输入域名,返回一个 InetAddress对象,封装了域名和IP地址。上面讲解InetSocketAddress的时候讲过,InetSocketAddress是解析后的InetAddress和对应的端口的封装。
默认情况下,hadoop.security.token.service.use_ip=true,使用StandardHostResolver,即直接调用java.net.InetAddress进行域名解析:
interface HostResolver {InetAddress getByName(String host) throws UnknownHostException; }/*** Uses standard java host resolution*/static class StandardHostResolver implements HostResolver {@Overridepublic InetAddress getByName(String host) throws UnknownHostException {return InetAddress.getByName(host);}}
而QualifiedHostResolver则对StandardHostResolver进行了优化,它实现的getByName()方法不再直接使用InetAddress.getByName(),而是先尝试将host转换成FQDN,然后进行域名解析,返回的InetAddress对象中的host是分析以后的FQDN,而不一定是原始的host。
从下面的代码可以看到,QualifiedHostResolver在初始化的时候,会先加载出系统中的searchDomains,具体就是读取/etc/resolv.conf文件,获取所有的domain,存放在一个list中。在实现接口方法getByName()的时候,会利用searchDomains,在逐个Domain中去当前的Host封装成FQDN,然后尝试解析这个host,一旦解析成功,则返回封装了FQDN和解析的IP地址的InetAddress给调用方。
protected static class QualifiedHostResolver implements HostResolver {@SuppressWarnings("unchecked")private List<String> searchDomains =ResolverConfiguration.open().searchlist(); // 类加载的时候,会加载系统中所有的domain@Overridepublic InetAddress getByName(String host) throws UnknownHostException {InetAddress addr = null;......} else if (host.endsWith(".")) { //已经是一个fqdn了// a rooted host ends with a dot, ex. "host."// rooted hosts never use the search path, so only try an exact lookupaddr = getByExactName(host);} else if (host.contains(".")) { //中间含有点儿// the host contains a dot (domain), ex. "host.domain"// try an exact host lookup, then fallback to search listaddr = getByExactName(host); // 这有可能是一个fqdn,按照fqdn,看看能否解析成功if (addr == null) { //没有解析成功,则通过当前的domain进行逐个searchaddr = getByNameWithSearch(host); //返回的InetAddress是fqdn和ip地址}} else { //这是不带任何点号的一个简单的hostname,比如:myhost InetAddress loopback = InetAddress.getByName(null);.......addr = getByNameWithSearch(host); //在Search List中搜索,最终封装成一个FQDN+IP地址if (addr == null) { //搜索不成功,回退到exactName的addr = getByExactName(host); //}}........return addr;}
关于InetAddress
InetAddress是java.net package中重要类。
真个InetAddress、InetSocketAddress和相关类的类图如下图所示:
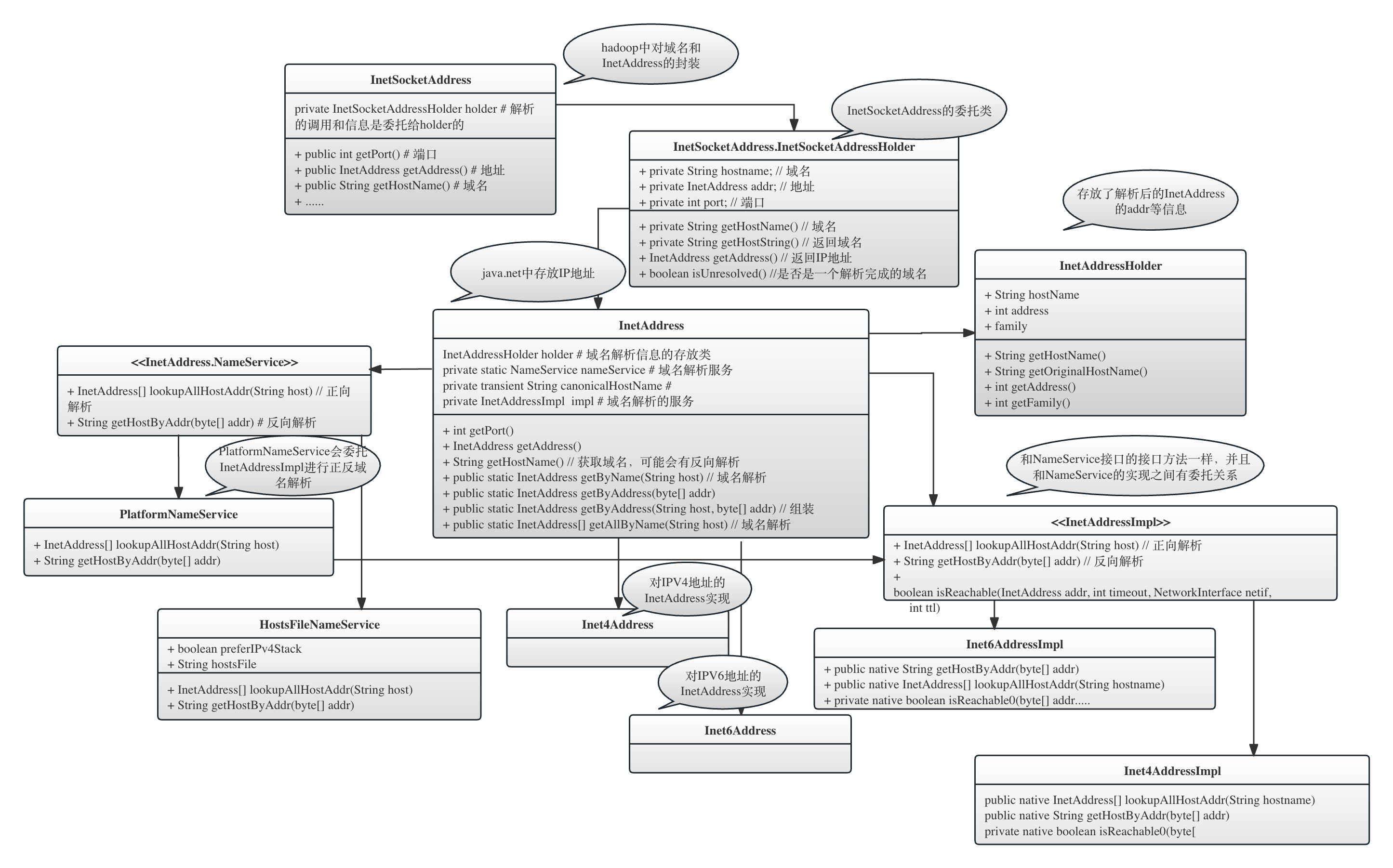
我们需要理解,在Java中,address其实是IP Address的简称,而不是DNS Address或者Hostname Address的代称。所以,InetAddress存放的是解析以后的地址信息,同时,它也承担了域名解析的功能,这是通过它的静态方法getByName()实现的:
public static InetAddress getByName(String host)throws UnknownHostException {return InetAddress.getAllByName(host)[0];
}
InetAddress本身不保存address信息,解析完成的address信息其实保存在它具体的实现类中,比如Inet4Address和Inet6Address中。
InetAddress提供的方法都有存放对应的hostname和解析以后的address的信息,当然这些信息有可能没有值。因此我们用方法getByName(),通过域名解析获取域名对应的包含了address的InetAddress,也可以通过getHostName()从当前的InetAddress的address信息中通过反向域名解析,解析出对应的Hostname。
其他具体细节本文不做讲解。
关于InetAddress中的两个ttl的设置:
InetAddressg关于域名解析的缓存,设置了两个参数:
networkaddress.cache.ttl: 表示从名称服务中成功查找名称的缓存策略。 该值指定为整数,指示缓存成功查找的秒数。 默认设置是缓存一段特定于实现的时间。
networkaddress.cache.negative.ttl: 表示从名称服务中查找不成功的名称的缓存策略。 该值指定为整数,指示缓存不成功查找失败的秒数。
我们可以查看jre/lib/security/java.security文件已获取当前这些配置项的值。一般情况下,在有SecurityManager的情况下,networkaddress.cache.ttl为-1,即域名解析成功以后永久缓存。而没有SecurityManager的情况下,默认缓存过期时间为30s。而networkaddress.cache.negative.ttl的缓存时间则默认为10s
关于InetSocketAddress
InetSocketAddress是Hadoop中域名解析过程中最重要的类,因为它封装了域名解析的结果,即域名和解析以后的IP地址InetAddress。
-----------------------------------InetSocketAddress----------------------------------
public class InetSocketAddressextends SocketAddress
{// InetSocketAddress 的构造方法public InetSocketAddress(InetAddress addr, int port) {holder = new InetSocketAddressHolder(null,addr == null ? InetAddress.anyLocalAddress() : addr,checkPort(port));}private final transient InetSocketAddressHolder holder;// Private implementation class pointed to by all public methods.private static class InetSocketAddressHolder { //内部类InetSocketAddressHolder// The hostname of the Socket Addressprivate String hostname; // 待解析的hostnameprivate InetAddress addr; // 解析以后的ip地址private int port; //端口private InetSocketAddressHolder(String hostname, InetAddress addr, int port) {this.hostname = hostname;this.addr = addr;this.port = port;}}}
InetSocketAddress的hostname,解析以后的InetAddress信息、端口信息其实是封装在InetSocketAddressHolder中。InetSocketAddress的get*()方法都是通过调用InetSocketAddressHolder对应的方法获取的。
从NetUtils.createSocketAddrForHost()代码可以看到InetSocketAddress 构造过程,即调用者先使用InetAddress的静态方法解析域名,将解析结果封装成InetAddress对象,最后和端口一起封装在InetSocketAddress中。
---------------------------- org.apache.hadoop.net.NetUtils ----------------------------------------public static InetSocketAddress createSocketAddrForHost(String host, int port) {String staticHost = getStaticResolution(host); // 如果存在静态解析的配置,那么先将当前的host映射成我们配置的静态hostname,然后再解析域名String resolveHost = (staticHost != null) ? staticHost : host;InetSocketAddress addr;try {InetAddress iaddr = SecurityUtil.getByName(resolveHost); //将hostname解析成IP,封装在java.net.InetAddress,其实是使用 InetAddress的静态方法来解析域名,返回返回一个InetAddress对象// if there is a static entry for the host, make the returned// address look like the original given hostif (staticHost != null) {iaddr = InetAddress.getByAddress(host, iaddr.getAddress());}addr = new InetSocketAddress(iaddr, port);} catch (UnknownHostException e) { // 如果解析失败,会创建一个代表域名无法解析的InetAddress对象addr = InetSocketAddress.createUnresolved(host, port);}return addr;}
--------------------------------InetSocketAddress--------------------------------public InetSocketAddress(InetAddress addr, int port) {holder = new InetSocketAddressHolder(null,addr == null ? InetAddress.anyLocalAddress() : addr,checkPort(port));}
相关文章
- QualifiedHostResolver和StandardHostResolver
- FQDN是什么
)


(还原截图锐捷))
 操作)







4.4-Autosar_BSW的Memory功能)






