1.实验内容及原理
1. 在 Windows 系统中安装 VMWare 虚拟机,在 VMWare 中安装 Ubuntu 系统,并在
Ubuntu 中搭建 LAMP 实验环境。
2. 使用 MySQL 进行一些基本操作:
(1)登录 MySQL,在 MySQL 中创建用户,并对新建的用户赋予权限。
(2)创建并跳转到新的数据库,显示所有数据库和当前数据库。
(3)显示所有的表和查看表的属性。
(4)导入 emp loyees 和 sakila 两个样例数据库,对这两个数据库进行完整性检查,
对这两个数据库进行备份、导入与导出。
3. SQL DDL 使用
(1) 创建 DDL 脚本,包括创建、删除表,指定主键、候选键和外键;
(2)修改并展示表结构;
(3)创建、删除索引。
4. SQL DDL & DML 使用
(1)数据的增、删、查、改等操作
(2)掌握视图的创建、删除和更新
5. 简单查询
(1)使用 order by、group by、having 等子句;
(2)使用各种谓词;
(3)使用集合函数;
(4)在时间字段上查询。
6. 复杂查询
(1)嵌套子查询;
(2)多表连接查询,包括左连接、右连接、外连接、 自连接。
7. 创建存储过程、函数和触发器,调用创建的存储过程、函数,触动触发器。
8. 安装并使用 phpmyadmin。
2.实验步骤与分析
1. 自行在 Windows 系统中安装 VMWare 虚拟机,在 VMWare 中安装 Ubuntu 系统,在
Ubuntu 中安装 LAMP 步骤如下(也可使用安装菜单):
sudo apt-get install updatesudo apt-get install apache2sudo apt-get install mysq l-serversudo apt-get install php2. 熟悉 MySQL 的基本操作步骤如下:
(1)进入 MySQL:mysq l -u root -p
(2)创建新用户:CREATE USER 'newuser'@' localhost' IDENTIFIED BY 'password';
(3)赋予权限:GRANT ALL PRIVILEGES ON * . * TO 'newuser'@' localhost';
(4)创建新的数据库:CREATE DATABASE newdbname;
(5)跳转到新创建的数据库:USE newdbname;3
(6)显示所有数据库和当前数据库:SHOW DATABASES; SELECT DATABASE();
(7)显示所有的表并查看表的属性:SHOW TABLES; DESCRIBE tabname;
(8)导入两个样例数据库
① 解压数据包:unzip test_db_master.zip
② 进入数据包目录:cd test_db_master
③ 导入 emp loyee 数据库:sudo sudo mysql -t < emp loyees.sql
④ 解压数据包:unzip sakila-db.zip
⑤ 进入数据包目录:cd sakila-db
⑥ 进入 MySQL,导入 sakila schema 数据:SOURCE /path/to/sakila-schema.sq l
⑦ 导入 sakila 数据:SOURCE /path/to/sakila-data.sq l
(9)对导入的两个数据库进行完整性检查
① 查看外键检查状态:show variables like ‘%foreign_key_checks% ’;
② 查看主键检查状态:show variables like ‘%unique_checks% ’;
③ 查看外键检查结果:select @@foreign_key_checks;
④ 查看主键检查结果:select @@unique_checks;
(10)数据库备份(以 employee 为例)
① 不导出任何数据,只导出数据库表结构:
mysqldump -u test_02 -p --no-data emp loyees> employees_bak1.sq l
② 只导出数据,而不添加 CREATE TABLE 语句:
mysqldump -u test_02 -p --no-create-info employees> emp loyees_bak2.sq l
③ 导出全部数据库:
mysqldump -u test_02 -p emp loyees> emp loyees_bak3.sq l
(11)导出和导入(以 sakila 为例)
① 导出为 TXT 文件:
select * from country into outfile '/your/file/path/country';
② 导入 TXT 文件:
load data infile '/your/file/path/country' into table country;
③ 导出为 CSV 文件:4
select * from country into outfile '/your/file/path/country.csv';
④ 导入 CSV 文件:
load data infile '/your/file/path/country.csv' into table country;
⑤ 导出为 xml 文件:
mysql -u test_02 -p --xml -e 'select * from sakila.country' >
/your/file/path/country.xml
3. SQL DDL 使用
(1)使用 create 语句创建项目所有的表;
(2)使用 alter 命令修改表结构,删除某个表中的“xxx ”字段;修改某个表中
的“xxx ”字段的类型为 char(2),该字段不能为空,默认值为“m”;
(3)添加类型为 char(2)的‘xxx ’字段数据,添加是否成功,如果失败分析
失败的原因并进行必要的操作使字段添加成功;
(4)修改某个表,添加类型为 varchar2(18)的字段,并添加 check 约束,要求该
字段的长度为 18,并且只能由数字组成,并且指定该字段为候选键;
(5)设置某个表中某个字段的 check 约束为大于 0;设置某个字段默认值为“未
审核 ”,设置某个 ”字段的 check 约束为“未审核 ”、“ 审核已通过 ”、“ 审核不通
过”;
(6)在某个表中创建索引;
(7)使用 describe 命令展示表结构。
4. SQL DDL & DML 使用
(1) 使用 insert 语句将数据插入到相应的表中;
(2) 使用 delete 语句删除表中有关联表外建对应的记录,能否成功删除,如
果不能请分析原因;
(3) 使用 update 语句更新外键数据,能否成功修改,如果不能请分析原因。;
(4) 创建视图;
(5) 对视图进行查询操作;
(6) 对表进行联合查询操作;
(7) 更新视图,分析更新操作可以执行成功或失败的原因。5
5. 简单查询
(1) 查询性别为“ 男 ”的所有学生的学号、姓名和班级号;(单表简单查询)
(2) 查询 xxx 表,获得性别为“女 ”的记录,结果按照班级 ID 降序排列;(order
by)
(3) 查询 xxx 表,按照年龄从小到大排序;(获取子串函数、order by)
(4) 查询学号以“2002 ”开头的学生信息,字段包括学号、姓名、班级号;(使用子
串函数)
(5) 查询学号中包含“01 ”的学生信息,字段包括学号、姓名、班级号;(like)
(6) 查询状态为“未审核 ”,且申请时间在 2013 年 9 月 4 日之后的请假申请
单的信息,包含申请时间为 9 月 4 日的申请单;(单表多条件查询)
(7) 查询审核状态为“未审核 ”和“ 审批已通过 ”两种类型的申请单 ID;(in)
(8) 查询时间在 2013 年 8 月 31 日和 2013 年 9 月 2 日之间所提交的申请单 ID,
请假原因; (between、时间)
(9) 查询 XXX 老师所教课程的的选课人次(一人选两门课程,算两人次);
(10) 查询 XXX 老师所教课程的的选课人数(一人选两门课程,算一人);(distinct)
(11) 查询 XX 老师对请假单审核不通过的请假原因与学生姓名;
(12) 统计每门课的学生的个数(集合函数);
(13) 查询选课人数超 过 3 人 的课程 号 , 并按课程 号 降序排列( group by,
having,order by …desc)。
6. 复杂查询
(1)查询审批通过人数最多的课程名称和教师姓名;
(2)查询选课人数最多和第二多的课程名称和任课老师姓名; (选做)
(3)查询只选了课程《算法设计》的学生姓名;
(4)查询选修了全部课程的学生姓名;
(5)查询选修了课程 3 的学生学号、姓名、身份证号;
(6)据学生学号将 xxx 表与 xxx 表做自然连接查询;
(7)据学号将 xxx 表与 xxx 表进行左连接查询,并解释这样做所具有的业务含 6
义;
(8)据学号将 xxx 表与 xxx 表进行右连接查询,并解释这样做所具有的业务含
义;
(9)总结自然连接、左连接、右连接查询在产生的结果上面有什么区别。
7. 创建并调用存储过程、函数和触发器
(1)创建并调用存储查询过程(以 emp loyee 为例)
① 创建一个查询存储过程:
> delimiter##> create procedure select_manager(in fname varchar(20), in lname varchar(20))-> begin->select * from dept_manager natural join emp loyees where first_name = fnameandlast_name = lname;->end> ##② 调用这个存储查询过程:call select_manager('Xiaobin','Spinelli');
(2)创建并调用函数(以 emp loyee 为例)
① 创建函数:
> delimiter ##> create function title_num(title_name varchar(50)) returns int> begin> declare num int;> select count(title) from titles where to_date > curdate() and title =title_name groupby title into num;> return num;> end> ##set g lobal log_bin_trust_function_creators=1;② 调用函数:select title_num("manager");7
(3)创建并调用触发器(以 emp loyee 为例)
① 查看表 dept_manager:select * from dept_manager;
② 创建新表 quit:create table quit (emp_no int, depr_no char(4), quit_date
date);
③ 创建触发器:
mysql> delimiter ##mysql> create trigger after_ insert_ quit after insert on quit for each row-> begin-> update dept_ manager set to_ date = curdate( ) where emp_ no = 110039;-> end-> ##④ 触发触发器: insert into quit values (110039, 'd001', curdate());
⑤ 查看新表 quit:select * from quit;
⑥ 再次查看表 dept_manager:select * from dept_manager;
8. 安装 phpmyadmin 步骤如下:
(1)安装 phpmyadmin:sudo apt-get install phpmyadmin
(2)安装 php-mbstring:sudo apt-get install php-mbstring
(3)安装 php-gettext:sudo apt-get install php-gettext
(4)编辑 php.ini: vim /path/to/php. ini 修改;extension=php-mbstring.so
(5)重启 Apache2:sudo /path/to/apache2 restart
(6)查看 IP 地址: ifconfig
(7)登录 phpmyadmin:从浏览器地址 your. ip.4.address/phpmyadmin
3.实验结果与总结
5. 简单查询
在进行简单查询和复杂查询实验前,我新建了一个名为 school 的数据库。内含 4 个表,
各表内容如图所示:
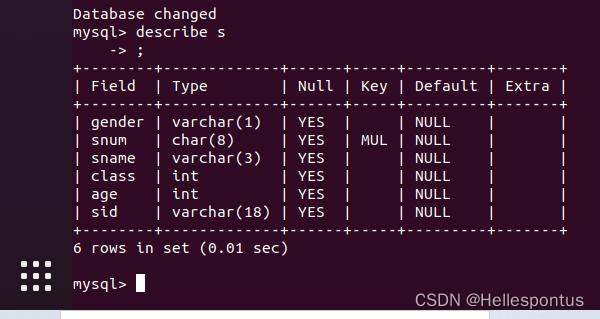
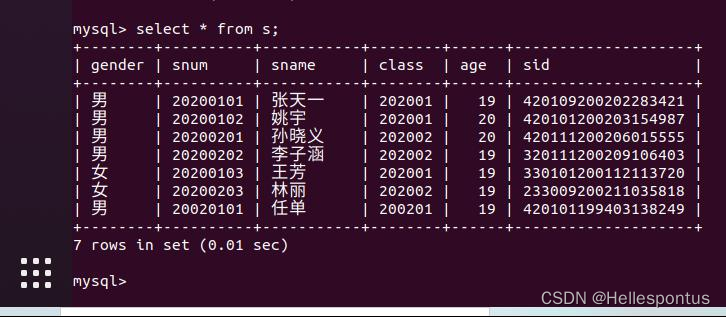
s 表, 内容为学生的个人信息
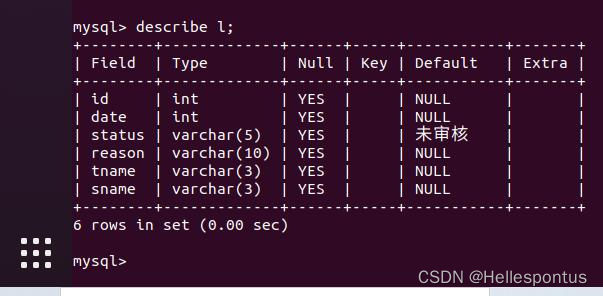

l 表, 内容为学生的请假申请和审批状态

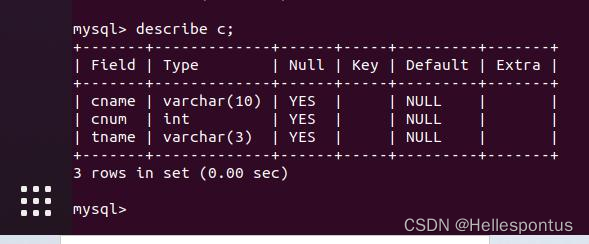
c 表, 内容为开设课程与授课老师信息
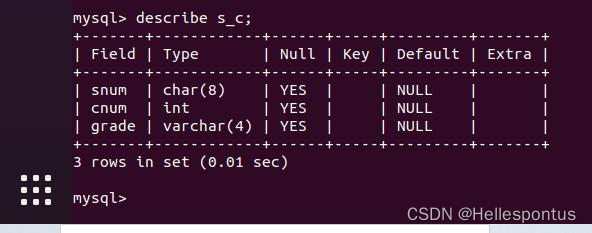
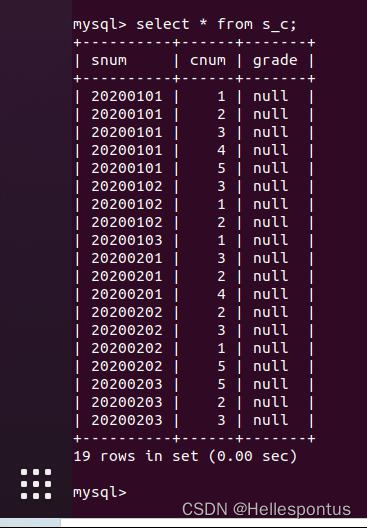
s_c 表, 内容为学生选课与成绩信息
基于以上四个表,我进行了下面两个部分的实验。首先是简单查询的实验:
(1) 查询性别为“ 男 ”的所有学生的学号、姓名和班级号;(单表简单查询)
(2) 查询 xxx 表,获得性别为“女 ”的记录,结果按照班级 ID 降序排列;(order by)
(3) 查询 xxx 表,按照年龄从小到大排序;(获取子串函数、order by)

(前三题查询结果)
(4) 查询学号以“2002 ”开头的学生信息,字段包括学号、姓名、班级号;(使用子串函数)
(5) 查询学号中包含“01 ”的学生信息,字段包括学号、姓名、班级号;(like)

(第四题与第五题均与字串相关,查询结果如上)
(6) 查询状态为“未审核 ”,且申请时间在 2013 年 9 月 4 日之后的请假申请单的信息,包含申请时间为 9 月 4 日的申请单;(单表多条件查询)
(7)查询审核状态为“未审核 ”和“ 审批已通过”两种类型的申请单 ID;(in)

(8) 查询时间在 2013 年 8 月 31 日和 2013 年 9 月 2 日之间所提交的申请单 ID,请假原因; (between、时间)
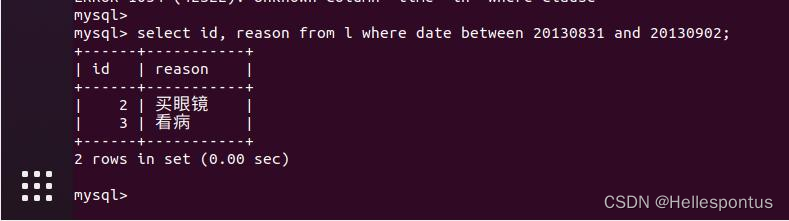
(9) 查询 XXX 老师所教课程的的选课人次(一人选两门课程,算两人次);
(10) 查询 XXX 老师所教课程的的选课人数(一人选两门课程,算一人);(distinct)
(第九题与第十题的区别为计算重复与否。第十题需排除重复项,所以需要使用 distinct)
(11) 查询 XX 老师对请假单审核不通过的请假原因与学生姓名;

(12) 统计每门课的学生的个数(集合函数);

(使用 group by 语句即可)
(13) 查询选课人数超过 3 人 的课程号 , 并按课程号降序排列( group by, having,order by …desc)。
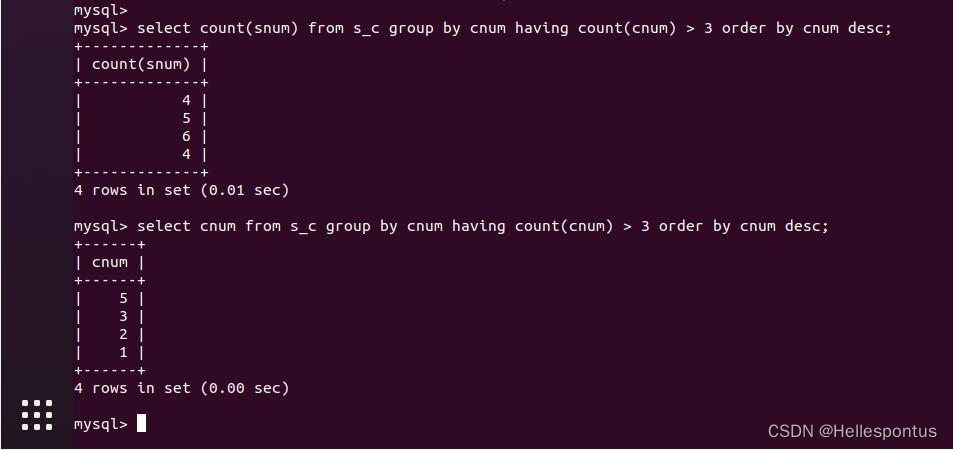
6. 复杂查询
进行该复杂查询实验时,使用的数据库也为以上创建的 school 数据库
(1)查询审批通过人数最多的课程名称和教师姓名:需要涉及计数、子查询等

(2)查询选课人数最多和第二多的课程名称和任课老师姓名; (选做)
(3)查询只选了课程《算法设计》的学生姓名;
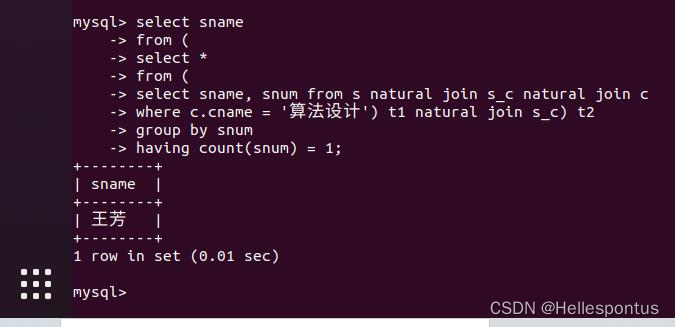
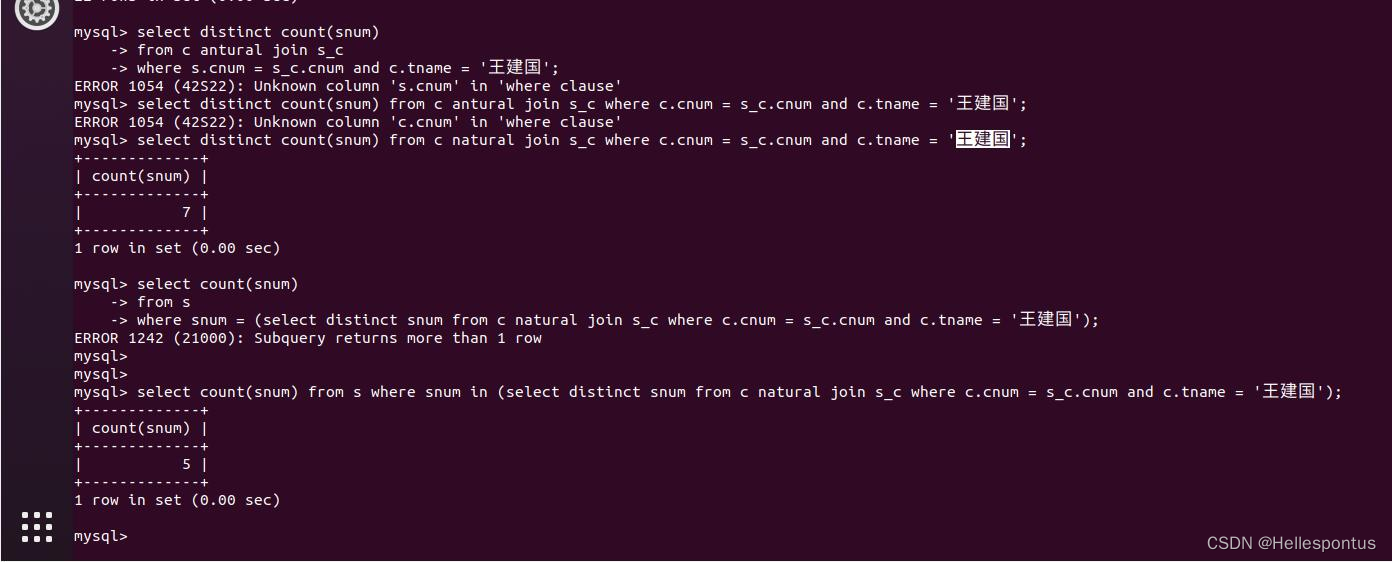
(4) 查询选修了全部课程的学生姓名;
此处若知道课程数量,可以直接使用分组计数的方式。若一名学生选课数量等于课程数(无重复),则可以认为其选修了全部课程。如下图所示:

(5) 查询选修了课程 3 的学生学号、姓名、身份证号;
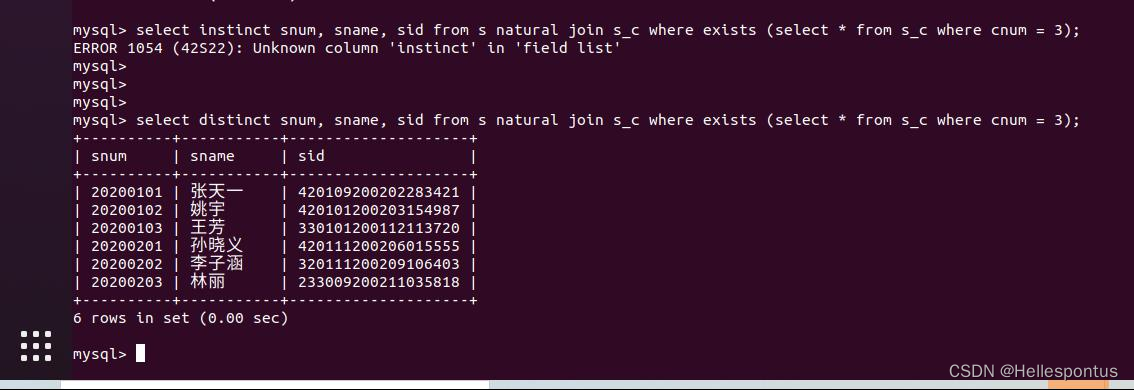
(6) 据学生学号将 xxx 表与 xxx 表做自然连接查询;
将学生信息表(s)与选课信息表(s_c)做连接查询
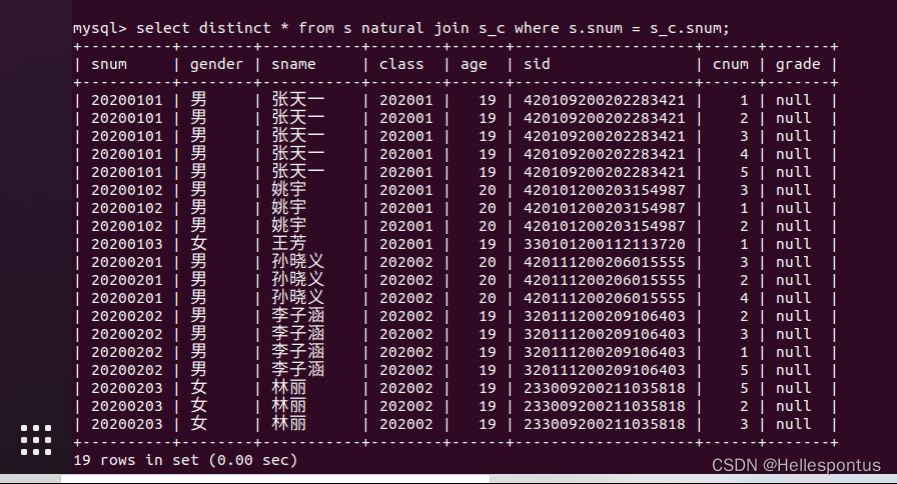
(7) 据学号将 xxx 表与 xxx 表进行左连接查询,并解释这样做所具有的业务含义;
将学生信息表(s)与选课信息表(s_c)做连接查询

含义:根据课程名单查询完全确定的选课信息
(8) 据学号将 xxx 表与 xxx 表进行右连接查询,并解释这样做所具有的业务含义;
将学生信息表(s)与选课信息表(s_c)做连接查询
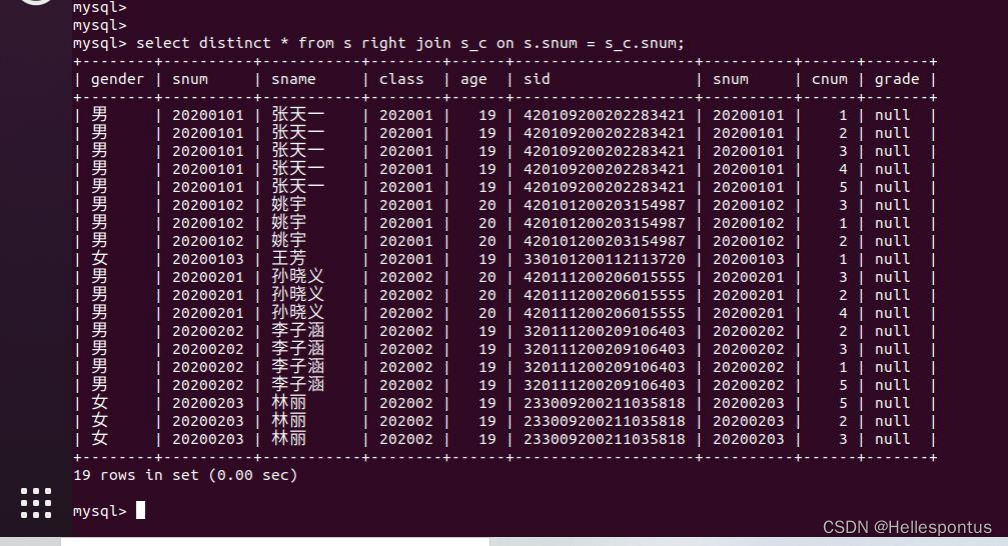
含义:根据学生信息查询所有的选课信息
(9) 总结自然连接、左连接、右连接查询在产生的结果上面有什么区别。
三种连接查询的区别在于:自然连接查询的信息完全确定,左连接与右连接查询得到的信息分别在左侧与右侧的表上完全确定,在另一侧的表上的信息无法完全确定。















)



