声明:
- 背景:本人为24届双非硕校招生,已经完整经历了一次秋招,拿到了三个offer。
- 本专题旨在分享自己的一些Java开发岗面试经验(主要是校招),包括我自己总结的八股文、算法、项目介绍、HR面和面试技巧等等,如有建议,可以友好指出,感谢,我也会不断完善。
- 想了解我个人情况的,可以关注我的B站账号:东瓜Lee
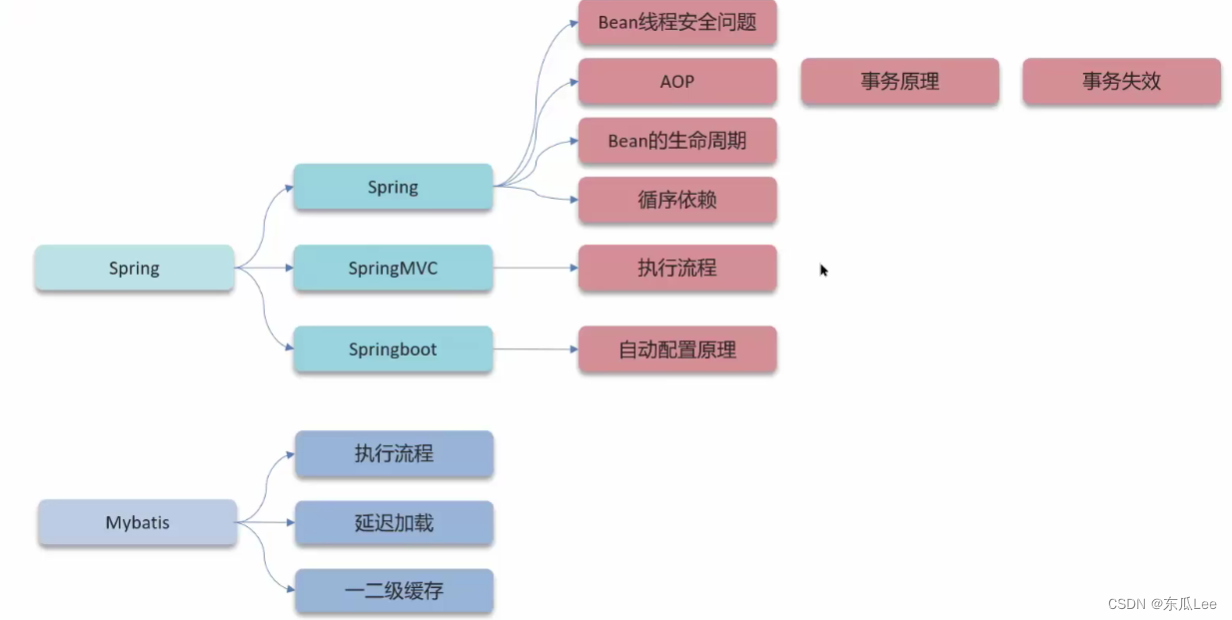
面试题:
-
Spring框架中的bean是单例的吗?
- 是单例的,IOC容器里面的bean对象默认就是单例singleton的
- 也可以使用@Scope注解设置为prototype原型的
- @Scope可以设置五种类型
-
Spring框架中的bean是线程安全的吗?
- 如果使用默认的单例作用域Singleton:不一定是线程安全的,要分两种情况考虑
- 如果bean没有可变的状态(此如Controller、Service、DAO类),在某种程度上来说,这种bean是线程安全的。
- 如果在bean中定义了可修改的成员变量,同时被多个线程访问就会导致数据的不一致性,就不是线程安全的(可以使用多例或者加锁来解决)
- 如果使用原型作用域Prototype:线程不会共享同一个bean,就不会有线程安全问题
- 如果使用默认的单例作用域Singleton:不一定是线程安全的,要分两种情况考虑
-
定义bean的方式(怎么把对象交给IOC容器管理)
- XML配置文件
- 注解
- JavaConfig(很少用)
-
什么是IOC?
- IOC就是控制反转,不同于正转(手动new对象,自己去处理对象之间的依赖关系),IOC就相当于是一个容器,可以管理的所有的java对象,也就是bean,然后也可以让它去处理对象依赖关系,它的目的就是为了降低代码耦合度,而且可以使得对象被统一管理。
- DI就是依赖注入,它是实现了控制反转,建立了bean对象之间的依赖关系
-
什么是AOP?
- AOP称为面向切面编程,可以将那些与业务无关,但却对多个对象产生影响的公共行为,抽取并封装为一个可重用的模块,这个模块就是为切面(Aspect) , 简单来说AOP就是,在不惊动原始设计的基础上 ,为代码进行功能增强。
- 作用:减少系统中的重复代码、降低了模块间的耦合度、提高了系统的可维护性。
- AOP的底层用的就是动态代理模式
使用场景:
- 记录操作日志
- Spring事务处理的底层实现就是用的AOP
-
Spring AOP底层是代理模式实现的,具体是怎么实现的?
用到了两种代理机制:
- JDK的动态代理,针对实现接口的类的产生代理
- Cglib的动态代理,针对没有实现接口的类的产生代理
-
AOP的实现中涉及到哪些注解?项目中怎么使用的AOP【待完善】
- @Aspect:定义当前类为 切面
- @Pointcut:定义当前方法为 切入点
- @Before:标注当前方法为 前置通知
- @After:标注当前方法为 后置通知
- @Around:标注当前方法为 环绕通知
-
Spring中的事务是如何实现的?
事务这个概念其实是数据库层面的,Spring框架只是基于数据库中的事务进行了扩展,而且方便程序操作事务。
Spring支持编程式事务管理和声明式事务管理两种方式:
- 编程式事务:需使用TransactionTemplate来进行实现,对业务代码有侵入性(也就是要手动写代码来实现开启、提交、回滚事务),项目中很少使用。
- 声明式事务:声明式事务管理是建立在AOP之上的,本质是通过AOP功能,对方法前后进行拦截,在目标方法开始之前加入一个事务,在执行完目标方法之后,根据执行情况提交或者回滚事务。(在方法上加个@Transactional注解)
为什么有的公司禁止使用声明式事务@Transactional注解,反而使用编程式事务:
- 如果方法存在嵌套调用,而被嵌套调用的方法也声明了事务,就会出现事物的嵌套调用,也就是事务传播行为来决定事务如何执行,这样容易引起事物的混乱。
- 声明式事务是将事物控制逻辑放在注解中,如果项目的复杂度增加,事务的控制可能会变得更加复杂,导致代码可读性和维护性下降。
-
Spring中事务的隔离级别?
Spring事务的隔离级别其实也就是数据库的隔离级别:
- ru:读未提交
- rc:读已提交
- rr:可重复读
- serializable:串行化
mysql默认的隔离级别是可重复读rr,oracle是读已提交rc,如果Spring中配置的隔离级别和数据库不一样,以Spring配置的为准
-
Spring中事务失效的场景有哪些?
指的是声明式事务,在方法(操作多张表)上加上@Transactional注解
- 异常捕获处理
如果的正常的话,出现了异常(运行时异常),那么事务就会进行回滚,那么事务就是正常的,如果代码主动对异常进行了try catch捕获处理,就会导致事务失效。
如果非要自己处理异常,还要保证事务不会失效,可以在catch块添加
throw new RuntimeException(e),再把运行时异常主动抛出去。- 抛出编译时(检查)异常
因为Spring的声明式事务 默认只会在出现运行时异常的时候进行回滚,编译时异常是不会回滚的。
可以在@Transactional注解中加上一个rollbackFor属性,指定所有的异常都可以进行回滚
- 非public的方法
因为 Spring 为方法添加事务通知的前提条件是 该方法是 public的,所以只有public的方法才能使用声明式事务
-
Spring 中事务的传播行为有哪些?
它解决的核心问题是,多个声明了事务的方法 在相互调用的时候 会存在事务的嵌套问题,那么这个事务的行为应该如何进行传递呢?
比如说,A B两个方法都开启了事务,方法A 调用 方法B,那么 方法B 是开启一个新的事务,还是继续在 方法A 的事务中执行?就取决于事务的传播行为。
一共有7种事务传播行为:
1. REQUIRED:默认的事物传播级别,如果当前存在事务,则加入这个事务,如果不存在事务,就新建一个事务。 2. REQUIRE_NEW:不管是否存在事务,都会新开一个事务,新老事务相互独立。外部事务抛出异常回滚不会影响内部事务的正常提交。 3. NESTED:如果当前存在事务,则嵌套在当前事务中执行。如果当前没有事务,则新建一个事务,类似于 REQUIRE_NEW 4. SUPPORTS:表示支持当前事务,如果当前不存在事务,以非事务的方式执行。 5. NOT_SUPPORTED:表示以非事务的方式来运行,如果当前存在事务,则把当前事务挂起。 6. MANDATORY:强制事务执行,若当前不存在事务,则抛出异常。 7. NEVER:以非事务的方式执行,如果当前存在事务,则抛出异常。
-
Spring的bean的生命周期
- 通过BeanDefinition获取bean的定义信息(xml里面定义的bean or 注解)
- 调用构造方法 实例化bean
- 对bean进行依赖注入(set注入)
- 实现几个Aware接口(BeanNameAware、BeanFactoryAware),重写里面的方法
- Bean的(前置)后置处理器BeanPostProcessor-before
- 初始化方法(InitializingBean、init- method)
- Bean的后置处理器BeanPostProcessor-after
- 关闭ioc容器,销毁bean对象
-
Spring中的循环引用(依赖)
比如的几种情况:
-
在创建A对象的时候要用到B对象,在创建B的时候又要用到A
-
A依赖于B,B依赖于C,C又依赖于A
-
A依赖于自己
Spring解决循环依赖是通过三级缓存 -
一级缓存(单例池):缓存的是 已经初始化完成的bean对象(已经经历了完整的生命周期的bean)
-
二级缓存:缓存的是 早期的还没初始化完成的bean对象(生命周期还在进行中的bean对象)
-
三级缓存:缓存的是ObjectFactory对象工厂,对象工厂就是用来创建某个对象的
-
使用一级缓存和二级缓存可以解决一般的循环依赖问题,但是如果有代理对象的话,就要使用三级缓存了,三级缓存可以解决大部分的循环依赖问题
-
-
谈谈你对SpringMVC的理解?
SpringMVC是一种基于Spring的 Web框架,采用了 MVC 的架构模式。
把复杂的 Web 应用分成逻辑清晰的几个组件,在 Spring MVC 中有 9 大重要的组件。
1. HandlerMapping 处理器映射器:在 SpringMVC 中会有很多请求,每个请求都需要一个 Handler 来处理,HandlerMapping 的作用就是找到 每个请求 对应的处理器 Handler。 2. HandlerAdapter 处理器适配器:它就是一个适配器,它主要就是如何让固定的 Servlet 处理方法 灵活的调用 Handler 来进行处理 3. ViewResolvers 视图解析器:将 String 类型的 视图名 和 Locale 解析为 View 类型的视图。 4. RequestToViewNameTranslator 视图名称翻译器:有的 Handler 处理完后并没有设置 View 也没有设置 ViewName,这时就需要从request 中获取,而 RequestToViewNameTranslator 就是为 request 提供获取 ViewName 的实现。 5. HandlerExceptionResolver 异常处理器:用于处理其他组件产生的异常情况 6. MultipartResolver 文件处理器:用于处理上传请求 7. ThemeResolver 主题处理器:用于解析主题 8. LocaleResolver 当前环境处理器:在 ViewResolver 进行视图解析的时候会用到 9. FlashMapManager 参数传递管理器:用于请求重定向场景中的参数传递
-
SpringMVC的执行流程知道吗?
前后端不分离阶段(视图阶段,直接说这个版本的,前后端分离阶段的就是少了个视图的解析)
- 用户发出请求 到前端控制器DispatcherServlet(调度中心)
- DispatcherServlet收到请求 调用处理器映射器HandlerMapping,HandlerMapping找到具体的处理器,生成 含有处理器对象和处理器拦截器 的执行链,再重新返回给DispatcherServlet
- DispatcherServlet再去 调用处理器适配器HandlerAdapter,HandlerAdapter经过适配 调用具体的处理器(controller中的方法),执行完成后返回一个ModelAndView对象,HandlerAdapter再将ModelAndView返回给DispatcherServlet
- DispatcherServlet将ModelAndView 传给视图解析器ViewReslover,视图解析器ViewReslover返回 具体的试图View给DispatcherServlet
- DispatcherServlet根据View进行试图的渲染,最后将试图响应给用户
用户发送请求给前端控制器,前端控制器去找控制器映射器,控制器映射器返回给前端控制器一个执行链,前端控制器请求处理器适配器,处理器适配器去找执行器执行处理,处理器执行完处理返回给处理器适配器一个ModelAndView,处理器适配器再将ModelAndView返回给前端控制器,前端控制器请求视图解析器,视图解析器返回给前端控制器View对象,前端控制器再对视图进行渲染,最后响应给用户。
-
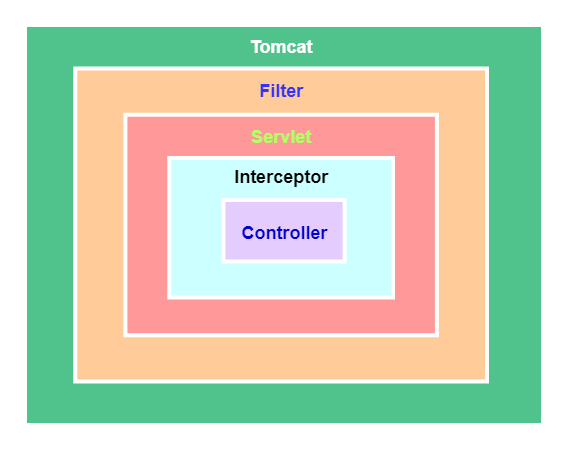
SpringMVC拦截器、Servlet过滤器的区别?
-
归属不同:过滤器属于Servlet、拦截器属于SpringMVC、
-
拦截内容不同:过滤器对所有访问进行增强、拦截器仅针对SpringMVC的访问(对Controller的请求)进行增强,
-
实现原理不同:过滤器是基于函数的回调、拦截器是基于Java的反射(动态代理)
-
实现方式不同:
- 过滤器Filter:主要重写三个方法,init()、destory()、doFilter()
- 拦截器Interceptor:主要重写三个方法,preHandle()、postHandle()、aftetCompletion()
-
使用范围不同:
- 过滤器Filter:依赖于Tomcat等容器,只能在web程序中使用
- 拦截器Interceptor:本质上属于Spring的组件,不依赖于Tomcat等容器,可以在web程序、Application等等程序中使用。
-
执行顺序不同:先执行过滤器,再执行拦截器
-
-
SpringBoot自动配置(装配)原理
-
主要依赖于@SpringBootApplication注解,包含了三个注解
- @SpringBootConfiguration:该注解与@Configuration注解作用相同,用来声明当前也是一个配置类。
- @ComponentScan:组件扫描,默认扫描当前引导类所在包及其子包。
- @EnableAutoConfiguration: SpringBoot实现自动化配置的核心注解。
-
其中@EnableAutoConfiguration是实现自动化配置的核心注解。
该注解通过@Import注解导入对应的配置选择器,内部读取了spring.factories文件中的所有配置类,在这些配置类中Bean会根据条件注解,来决定是否需要将其导入到Spring容器中,会判断是否有对应的class文件,如果有,则加载该类。
-
-
SpringBoot框架的好处是什么?
我们以前可能使用的比较常见的后端框架是SSH,后来又是SSM,再到现在主要使用的就是SpringBoot,SpringBoot的核心就是采用了 约定大于配置 这样的思想,省去了一些繁琐的配置项,使得我们可以专注于业务代码的编写。
具体来说,使用传统的Spring框架来开发web应用,需要做很多和业务无关的配置,比如:一些.xml文件的维护、管理依赖jar包、将应用手动部署到服务器。
而在SpringBoot种,不需要再去做这些繁琐的配置,Spring Boot 已经自动帮我们完成了,这就是约定大于配置思想 的体现,它配置了很多东西,比如说:
- SpringBoot Starter,也就是启动依赖,它能帮我们管理所有的 jar 包
- 在SpringBoot 自动装配机制的实现中,通过扫描约定路径下的 spring.factories 文件来识别配置类,实现 Bean 的自动装配。
- SpringBoot还内嵌了几种服务器,比如Tomcat、Jetty,不再需要手动部署应用到服务器
总的来说,SpringBoot正因为有约定大于配置 的思想,使得它可以更高效 也更便捷的 实现软件系统的开发和维护。
-
Spring框架常见注解
-
@Configuration:指定当前类是一个Spring配置类
-
@Component:放在类上 用于实例化bean对象的(对应的还有@Controller、@Service、@Mapper)
-
@ComponentScan:用于指定Spring在初始化容器时要扫描的包
-
@Autowired:使用在字段上 用于根据类型依赖注入
-
@Scope:用于标注bean的作用范围(单例、原型bean)
-
-
SpringMVC常见的注解
- @RequestMapping:用于映射请求路径,可以定义在类上和方法上,用于类上,则表示类中的所有的方法都是以该地址作为父路径
- @RequestBody:实现前台传过来的的是json字符串,将json转换为Java对象
- @RequestParam:指定请求参数的名称
- @PathViriable:从请求路径下中获取请求参数(/user/id),传递给方法的形式参数
- @ResponseBody:实现将controller方法返回的Java对象 转化为json字符串响应给前台
-
Springboot常见注解
- @SpringBootApplication:启动类上的注解,包含了三个注解
- @SpringBootConfiguration:用来声明当前也是一个配置类。
- @ComponentScan:组件扫描,默认扫描当前引导类所在包及其子包。
- @EnableAutoConfiguration:SpringBoot实现自动化配置的核心注解。
- @SpringBootApplication:启动类上的注解,包含了三个注解
-
MyBatis执行流程
- 读取MyBatis的配置文件mybatis-config.xml,里面有数据库的连接信息、映射文件和代理方式等等信息
- 构造会话工厂SqlSessionFactory,再通过会话工厂创建SqISession对象(包含了执行所有sql语句的方法)
- SqISession有个操作数据库的接口 Executor执行器,同时它还负责了查询缓存的维护
- Executor的执行方法中 有一个MappedStatement类型的参数,封装了映射信息
- 输入参数映射,就可以执行数据库的操作了
- 执行完后数据库操作后,就可以输出结果映射
MyBatis-Plus selectOne的时候查询出多条数据怎么办?
查询出多条数据会报异常,临时解决方案可以加个limit 1,但是可能得不到想要的数据
正确的话可以通过AOP来解决,设置切面
-
MyBatis延迟加载
MyBatis默认是立即加载,延迟记载需要配置一下
延迟加载的意思:
- 需要用到数据的时候就进行加载(到数据库中去查找),暂时还没有用到的话,就不提前加载
- 比如有两个表,用户表和订单表,一个用户可以对应多个订单,在用户属性里面就有一个字段叫做订单项,使用mybatis执行对用户的查询的时候,默认也会去查找订单信息,这就是立即加载,所谓延迟加载就是,如果只查询用户的信息,底层就不执行查询订单的逻辑,需要用到订单项的时候,再去查询,要实现延迟加载,需要配置一下
- 延迟加载也可以叫做懒加载,类似于单例模式成的懒汉式单例
-
MyBatis的一级、二级缓存
MyBatis中的一级二级缓存都是基于本地缓存,本质上就是一个hashmap的结构,给一个key,在缓存中得到一个value
一级二级缓存其实就是作用域不同,默认开启的就是一级缓存
-
一级缓存:作用域是session级别的
比如使用sqlSessionFactory(也就是会话工厂),来创建一个session会话,使用这个session来get到两个mapper对象来操作数据库,两个mapper对象执行同一条sql查询数据,那其实就只会去数据库查询一次,查询一次后就把数据放到了一级缓存中,第二次查询直接从缓存中命中。
-
二级缓存:作用域是namespace和mapper的作用域,不依赖于session
就比如当前使用的是默认的一级缓存,如果sqlSessionFactory创建了两个session,使用这两个session来分别get到两个mapper对象,去执行同一条sql查询语句,那么其实就会去查询两次数据库,因为是用的两个session。
然后可以去配置文件中开启一下二级缓存,开启之后,使用不同的session对象得到的mapper,再去执行同一条查询操作,第一次查询就会将数据保存到二级缓存中,第二次查询就不会查询数据库了。
-
-
Mybatis 动态SQL是什么?有哪些动态SQL?
- 动态SQL是一种可以根据不同条件生成不同SQL语句的技术,可以在xml映射文件中编写灵活的SQL语句,能根据设定参数的不同情况来动态生成SQL语句。
- Mybatis 常用的动态 SQL 标签:
- where:生成动态的WHERE子句,只有满足条件时才包含WHERE子句,避免不必要的WHERE关键字。
- set:生成动态的SET子句,只有满足条件时才包含SET子句,用于动态更新表中的字段。
- choose:根据不同的条件选择执行不同的SQL片段,实现类似于switch-case语句的功能。
- foreach:对集合进行循环,并在SQL语句中使用循环的结果
- trim:对SQL语句进行修剪和重组,去掉多余的AND或OR等,以便根据不同的条件,动态生成合适的SQL语句。
-
MyBatis和Hibernate的区别?
- 在国内MyBatis是主流的持久层框架,但是其实在欧美国家Hibernate用的更多,主要的原因就是欧美国家对于java的态度,更加把它当成一门面向对象的语言。
- 因为Hibernate是全自动ORM框架,ORM也就是对象关系映射,它将java中的对象和数据库中的表直接关联起来,通过对象就可以实现对数据库的操作,而MyBatis是半自动ORM框架,它的重点在于java对象和SQL语句之间的映射关系,操作数据表还是要通过SQL语句。
-
SpringBoot除了集成了Tomcat,它还集成了哪些容器,Servlet容器?
- Tomcat是SpringBoot默认使用的web容器,除此之外还有:
- Jetty、Undertow、Netty容器
- 因为默认是使用Tomcat,所以如果要使用其他的容器就需要先排除(exclusion)Tomcat容器,再导入其他容器。
-
SpringBoot有bootstrap.yml和application.yml两个配置文件,这两个文件有什么区别?
SpringBoot项目一般具有两个配置文件,bootstrap.yml、application.yml
(也可以用.properties,properties > yml > yaml)
具体区别:
- 加载顺序不同,bootstrap比application配置文件先加载,因为bootstrap是由spring父上下文加载,而application是由子上下文加载。
- 优先级不同,bootstrap加载的配置信息是不能被application的相同配置覆盖的,也就是说如果两个配置文件同时存在,以bootstrap为主。
- 应用场景不同,bootstrap常用于配置一些固定的、系统级别的参数,application常用于配置一些springboot项目的自动化配置。
大部分情况下都是使用application.yml
-
Spring的BeanFactory和ApplicationContext是什么?有什么区别?
- BeanFactory就是一个bean工厂,用到了工厂设计模式,负责读取bean的配置文件、管理bean的加载、实例化,还能维护bean之间的依赖关系,也就是依赖注入DI,它负责了bean的整个生命周期。
- ApplicationContext其实是属于BeanFactory的子接口,除了实现了BeanFactory接口的功能之外,还做了功能增强,比如:国际化访问、资源访问、事件传递之类的。
- 还一个区别就是他俩加载bean的时机不同:
- BeanFactory不会在初始化的时候就加载所有的bean,执行getBean的时候才会加载,也就是采用的惰性加载(类似于懒汉式单例),好处就是节省了资源而且初始化速度比较快,因为有的bean不一定会被使用,坏处就是要用的时候要等一个加载的时间
- ApplicationContext会在初始化的时候加载所有的bean,也就是饿汉式加载(类似于饿汉式单例),好处就是要用的时候可以直接用,坏处就是可能会浪费资源而且初始化速度慢。
-
Spring的 BeanFactory和FactoryBean的区别是什么?
- BeanFactory就是一个bean工厂,用到了工厂设计模式,负责读取bean的配置文件、管理bean的加载、实例化,还能维护bean之间的依赖关系,也就是依赖注入DI,它负责了bean的整个生命周期。
- FactoryBean 是一个工厂 Bean,它是一个接口,主要的功能是 动态地生成某一个类型 的Bean 的实例,也就是说,我们可以自定义一个 Bean ,然后加载到 IOC 容器里面,它里面有一个重要的方法叫 getObject(),这个方法里面就是用来实现动态构建 Bean的过程。
【后续继续补充,敬请期待】
——提取接口响应内容JSON Extractor)










)
![scanf函数返回值占位符详解,%*,%[]的应用](http://pic.xiahunao.cn/scanf函数返回值占位符详解,%*,%[]的应用)


和有名管道(FIFO)的区别)



