文章目录
- 一、环境配置
- 二、准备数据
- 三、搭建网络结构
- 四、开始训练
- 五、查看训练结果
- 六、总结
- 6.1 不改变学习率的前提下,将训练epoch分别增加到50、60、70、80、90
- (1)epoch = 50 的训练情况如下:
- (2)epoch = 60 的训练情况如下:
- (3)epoch = 70 的训练情况如下:
- (4)epoch = 80 的训练情况如下:
- (5)epoch = 90 的训练情况如下:
- 6.2 在epoch=50、60、70、80、90的基础上修改固定学习率为动态学习率
- (1)epoch = 50 的训练情况如下:
- (2)epoch = 60 的训练情况如下:
- (3)epoch = 70 的训练情况如下:
- (4)epoch = 80 的训练情况如下:
- (5)epoch = 90 的训练情况如下:
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
🍺本文基础要求:
(1)本地读取并加载数据。
(2)测试集accuracy到达93%
🍻拔高:
(1)测试集accuracy到达95%
(2)调用模型识别一张本地图片
一、环境配置
# 1. 设置环境
import sys
from datetime import datetimeimport torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasetsimport os,PIL,pathlib,randomprint("---------------------1.配置环境------------------")
print("Start time: ", datetime.today())
print("Pytorch version: " + torch.__version__)
print("Python version: " + sys.version)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device

二、准备数据
导入数据分四步:
● 第一步:使用pathlib.Path()函数将字符串类型的文件夹路径转换为pathlib.Path对象。
● 第二步:使用glob()方法获取data_dir路径下的所有文件路径,并以列表形式存储在data_paths中。
● 第三步:通过split()函数对data_paths中的每个文件路径执行分割操作,获得各个文件所属的类别名称,并存储在classNames中
● 第四步:打印classNames列表,显示每个文件所属的类别名称。
'''
D:\jupyter notebook\DL-100-days\datasets\P3-天气识别\weather_photos\
'''
print("---------------------2.1 导入本地数据------------------")
data_dir = 'D:/jupyter notebook/DL-100-days/datasets/P3-天气识别/weather_photos/'
data_dir = pathlib.Path(data_dir)data_paths = list(data_dir.glob('*'))
classNames = [str(path).split("\\")[1] for path in data_paths]
classNamesprint("---------------------2.2 数据可视化------------------")
import matplotlib.pyplot as plt
from PIL import Image# 指定图像文件夹路径
image_folder = 'D:/jupyter notebook/DL-100-days/datasets/P3-天气识别/weather_photos/cloudy/'# 获取文件夹中的所有图像文件
image_files = [f for f in os.listdir(image_folder) if f.endswith((".jpg", ".png", ".jpeg"))]# 创建Matplotlib图像
fig, axes = plt.subplots(3, 8, figsize=(16, 6))# 使用列表推导式加载和显示图像
for ax, img_file in zip(axes.flat, image_files):img_path = os.path.join(image_folder, img_file)img = Image.open(img_path)ax.imshow(img)ax.axis('off')# 显示图像
plt.tight_layout()
plt.show()print("---------------------2.3 定义train_transforms函数,完成图片尺寸归一化------------------")
total_datadir = 'D:\jupyter notebook\DL-100-days\datasets\P3-天气识别\weather_photos'# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_dataprint("---------------------2.4 划分数据集------------------")
# 使用torch.utils.data.random_split()方法进行数据集划分。
# 该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,并将划分结果分别赋值给train_dataset和test_dataset两个变量。
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_datasetprint("---------------------2.4.1 检查训练集、测试集的size------------------")
# ● train_size表示训练集大小,通过将总体数据长度的80%转换为整数得到;
# ● test_size表示测试集大小,是总体数据长度减去训练集大小。
train_size,test_sizeprint("---------------------2.4.1 检查训练集、测试集的size------------------")
batch_size = 32
# ⭐torch.utils.data.DataLoader()参数详解
train_dl = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,batch_size=batch_size,shuffle=True,num_workers=1)for X, y in test_dl:print("Shape of X [N, C, H, W]: ", X.shape)print("Shape of y: ", y.shape, y.dtype)break

三、搭建网络结构
print("---------------------3. 定义简单CNN网络------------------")
import torch.nn.functional as Fclass Network_bn(nn.Module):def __init__(self):super(Network_bn, self).__init__()"""nn.Conv2d()函数:第一个参数(in_channels)是输入的channel数量第二个参数(out_channels)是输出的channel数量第三个参数(kernel_size)是卷积核大小第四个参数(stride)是步长,默认为1第五个参数(padding)是填充大小,默认为0"""self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn1 = nn.BatchNorm2d(12)self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)self.bn2 = nn.BatchNorm2d(12)self.pool = nn.MaxPool2d(2,2)self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn4 = nn.BatchNorm2d(24)self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)self.bn5 = nn.BatchNorm2d(24)self.fc1 = nn.Linear(24*50*50, len(classeNames))def forward(self, x):x = F.relu(self.bn1(self.conv1(x))) x = F.relu(self.bn2(self.conv2(x))) x = self.pool(x) x = F.relu(self.bn4(self.conv4(x))) x = F.relu(self.bn5(self.conv5(x))) x = self.pool(x) x = x.view(-1, 24*50*50)x = self.fc1(x)return xdevice = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))model = Network_bn().to(device)
model

四、开始训练
print("---------------------4. 训练模型------------------")
print("---------------------4.1 设置超参数------------------")
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)print("---------------------4.2 编写训练函数------------------")
# 训练循环
def train(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集的大小,一共60000张图片num_batches = len(dataloader) # 批次数目,1875(60000/32)train_loss, train_acc = 0, 0 # 初始化训练损失和正确率for X, y in dataloader: # 获取图片及其标签X, y = X.to(device), y.to(device)# 计算预测误差pred = model(X) # 网络输出loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失# 反向传播optimizer.zero_grad() # grad属性归零loss.backward() # 反向传播optimizer.step() # 每一步自动更新# 记录acc与losstrain_acc += (pred.argmax(1) == y).type(torch.float).sum().item()train_loss += loss.item()train_acc /= sizetrain_loss /= num_batchesreturn train_acc, train_lossprint("---------------------4.3 编写测试函数------------------")
def test (dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集的大小,一共10000张图片num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)test_loss, test_acc = 0, 0# 当不进行训练时,停止梯度更新,节省计算内存消耗with torch.no_grad():for imgs, target in dataloader:imgs, target = imgs.to(device), target.to(device)# 计算losstarget_pred = model(imgs)loss = loss_fn(target_pred, target)test_loss += loss.item()test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()test_acc /= sizetest_loss /= num_batchesreturn test_acc, test_lossprint("---------------------4.4 正式训练------------------")
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []for epoch in range(epochs):model.train()epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)model.eval()epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)train_acc.append(epoch_train_acc)train_loss.append(epoch_train_loss)test_acc.append(epoch_test_acc)test_loss.append(epoch_test_loss)template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')

五、查看训练结果
print("---------------------5. 训练结果可视化------------------")
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率epochs_range = range(epochs)plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

测试准确率Test_Accuracy = 89.8%。
六、总结
尝试提高test_accuracy的值。
【提高准确率方法总结】
6.1 不改变学习率的前提下,将训练epoch分别增加到50、60、70、80、90
不同epoch次数得到的test_accuracy的结果如下表:
| epoch | test_accuracy |
|---|---|
| epoch = 50 | 92.4% |
| epoch = 60 | 93.3% |
| epoch = 70 | 92.4% |
| epoch = 80 | 94.2% |
| epoch = 90 | 90.2% |
(1)epoch = 50 的训练情况如下:
得到训练情况如下:
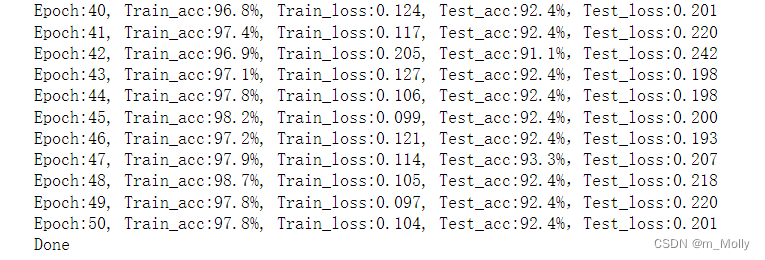

结论:50个epoch训练完,test_accuracy = 92.4%。在学习率不变的情况下,增加epoch次数是能够增加test_accuracy的值的。
(2)epoch = 60 的训练情况如下:
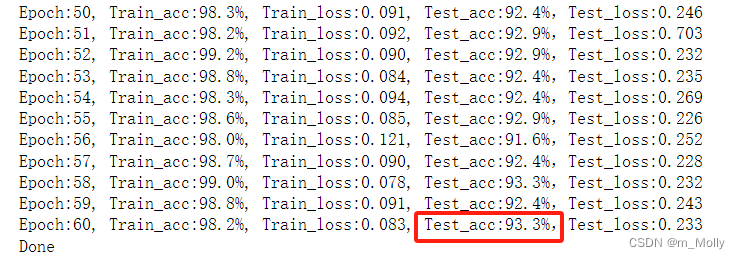

(3)epoch = 70 的训练情况如下:


(4)epoch = 80 的训练情况如下:


(5)epoch = 90 的训练情况如下:

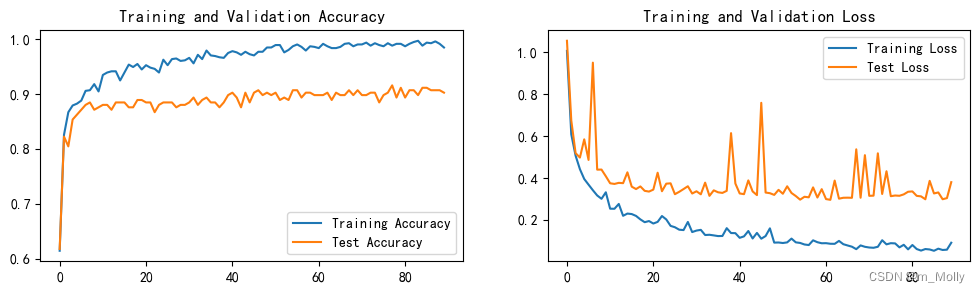
6.2 在epoch=50、60、70、80、90的基础上修改固定学习率为动态学习率
【参考这里】
使用pytorch提供的学习率,在
torch.optim.lr_scheduler内部,基于当前epoch的数值,封装了几种相应的动态学习率调整方法,该部分的官方手册传送门——optim.lr_scheduler官方文档。需要注意的是学习率的调整需要应用在优化器参数更新之后,也就是说:
optimizer = torch.optim.XXXXXXX()#具体optimizer的初始化
scheduler = torch.optim.lr_scheduler.XXXXXXXXXX()#具体学习率变更策略的初始化
for i in range(epoch):for data,label in dataloader:out = net(data)output_loss = loss(out,label)optimizer.zero_grad()loss.backward()optimizer.step()scheduler.step()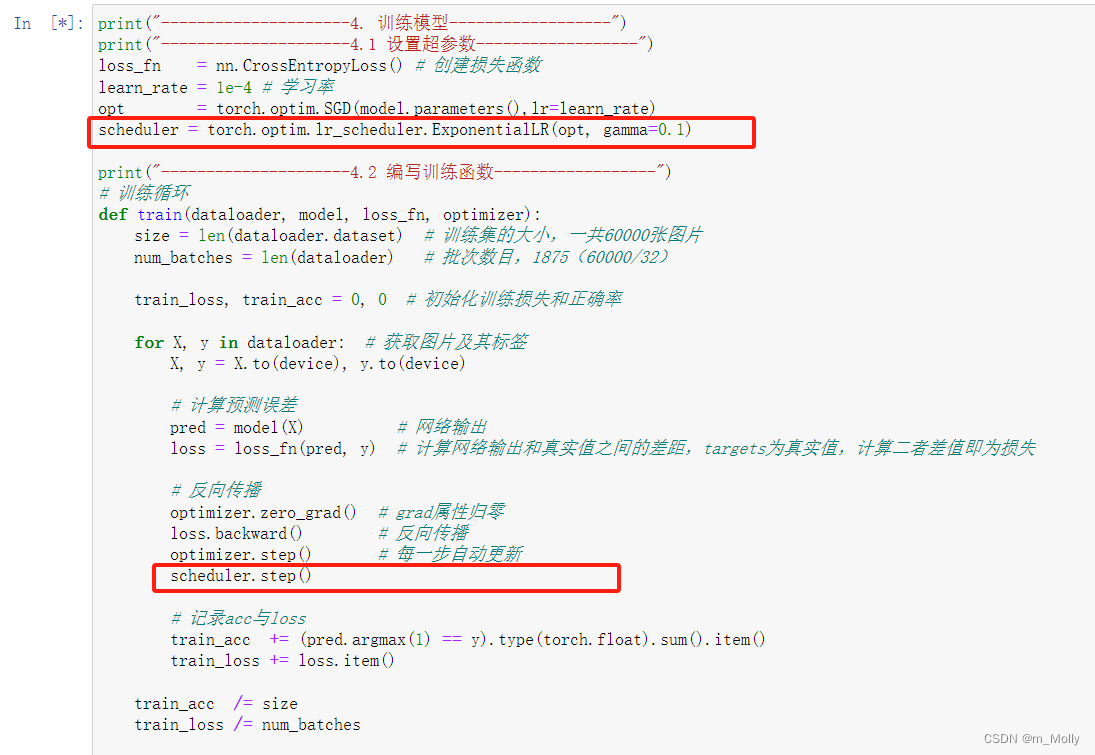
设置动态学习率,不同epoch次数的test_accuracy值如下表所示:
| epoch | test_accuracy |
|---|---|
| epoch = 50 | 92.0% |
| epoch = 60 | 93.3% |
| epoch = 70 | 92.4% |
| epoch = 80 | 93.3% |
| epoch = 90 | 87.6% |
(1)epoch = 50 的训练情况如下:
训练情况如下:test_accuracy最高能达到92.9%,然后又降下来,等50个epoch都训练完,最终的test_accuracy = 92.0%。

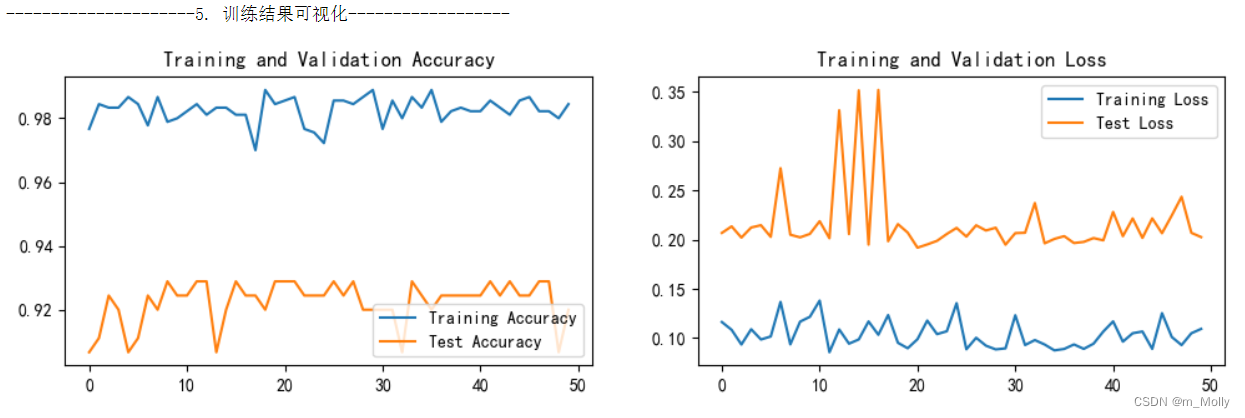
(2)epoch = 60 的训练情况如下:


(3)epoch = 70 的训练情况如下:


(4)epoch = 80 的训练情况如下:
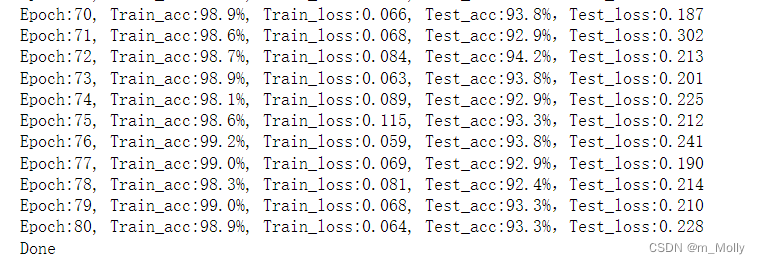

(5)epoch = 90 的训练情况如下:

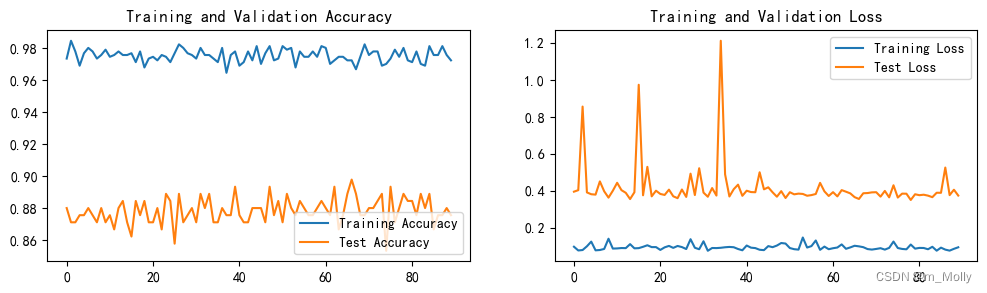
)











:停止执行当前表达式并执行错误操作。)


)

ArkUI--循环foreachList组件自定义组件)

