文章目录
- 前言
- 一、pako 介绍
- 一些特点和功能:
- 简单示例
- 二、vue3 实战示例
- 1.安装后引入库
- 安装:
- 引用
- 用自定义hooks 抽取共用逻辑
- 部署小插曲
前言
外部接口返回一个图片数据是经过zip压缩的,前端需要把这个数据处理成可以显示的图片。大概思路:zip解压-> 转换为base64数据 -> img标签显示。
一、pako 介绍
pako详细描述🚀 npm 直达
pako 是一个流行的 JavaScript 库,用于在浏览器中进行数据压缩和解压缩操作。它提供了对常见的压缩算法(如 Deflate 和 Gzip)的实现,使开发者能够在客户端上轻松进行数据压缩和解压缩,以减少数据传输大小和网络带宽消耗。
一些特点和功能:
支持多种压缩算法:pako 实现了 Deflate 和 Gzip 等常见压缩算法的压缩和解压缩功能。这些算法在网络传输中被广泛使用,能够显著减小数据的大小。
跨平台兼容性:pako 可以在多个平台和环境中使用,包括浏览器、Node.js 和 Web Workers 等。
简单易用的 API:pako 提供了简单的 API,使得压缩和解压缩操作变得简单和直观。你可以通过提供原始数据和选项来执行压缩和解压缩,并获得压缩后的数据或原始数据。
高性能:pako 的实现经过优化,具有较高的性能。它使用原生的 JavaScript 数组和类型化数组操作来处理数据,以提高压缩和解压缩的速度和效率。
简单示例
// 压缩数据
const dataToCompress = "Hello, world!";
const compressedData = pako.deflate(dataToCompress);// 解压缩数据
const decompressedData = pako.inflate(compressedData);
const originalData = pako.inflateRaw(compressedData);// 将压缩数据转换为 Base64 字符串
const compressedBase64 = btoa(String.fromCharCode.apply(null, compressedData));
二、vue3 实战示例
1.安装后引入库
安装:
npm install pako
引用
import pako from 'pako'
用自定义hooks 抽取共用逻辑
import pako from 'pako'export function useHandleZipData() {const toBase64String = (byteArray: any) => {let binaryString = ''for (let i = 0; i < byteArray.length; i++) {binaryString += String.fromCharCode(byteArray[i])}const base64String = btoa(binaryString)return base64String}const fromBase64String = (base64String: any) => {const binaryString = atob(base64String)const byteArray = new Uint8Array(binaryString.length)for (let i = 0; i < binaryString.length; i++) {byteArray[i] = binaryString.charCodeAt(i)}return byteArray}const decompressGzip = (compressedBytes:any) => {const input = new Uint8Array(compressedBytes);const output = new Uint8Array(input.length * 10); // Allocate initial output buffer sizeconst inflater = new pako.Inflate();inflater.push(input, true);if (inflater.err) {throw new Error(`Gzip decompression error: ${inflater.msg}`);}const decompressedBytes = inflater.result;const decompressedArray = new Uint8Array(decompressedBytes.buffer, 0, decompressedBytes.length);return decompressedArray;}//解决数据过大和中文乱码function Utf8ArrayToStr(array: any) {let out, i, len, c;let char2, char3;out = '';len = array.length;i = 0;while (i < len) {c = array[i++];switch (c >> 4) {case 0:case 1:case 2:case 3:case 4:case 5:case 6:case 7:// 0xxxxxxxout += String.fromCharCode(c);break;case 12:case 13:// 110x xxxx 10xx xxxxchar2 = array[i++];out += String.fromCharCode(((c & 0x1f) << 6) | (char2 & 0x3f),);break;case 14:// 1110 xxxx 10xx xxxx 10xx xxxxchar2 = array[i++];char3 = array[i++];out += String.fromCharCode(((c & 0x0f) << 12) |((char2 & 0x3f) << 6) |((char3 & 0x3f) << 0),);break;}}return out;}const gzipstringDecompress = (b64Data: any) => {let strData = atob(b64Data);const charData = strData.split('').map(function (x) {return x.charCodeAt(0);});const binData = new Uint8Array(charData);const data = pako.inflate(binData);return Utf8ArrayToStr(data);}return {toBase64String,fromBase64String,decompressGzip,gzipstringDecompress}
}
看到 toBase64String,fromBase64String 写法有点类似.net ,是的以上是使用chatgpt 把.net 中convert.toBase64String convert.fromBase64String 等价转换的
使用:返回base64 图片字符串,再根据情况添加 data:image/png;base64,
if (labelRawData?.startsWith('H4sI') ||labelRawData?.startsWith('Cl5YQQ') ||labelRawData?.startsWith('XkZVIF')) {const tempStr = gzipstringDecompress(labelRawData)if (tempStr?.substring(0, 5).includes('PNG') ||tempStr?.substring(0, 5).includes('png')) {const compressedBytes = fromBase64String(labelRawData)const bytes = decompressGzip(compressedBytes)const base64String = toBase64String(bytes)if (String(base64String ).substring(0, 22) != 'data:image/png;base64,') {base64String = `data:image/png;base64,` + base64String }}
部署小插曲
目前还不知道为啥会这样?Jenkins构建的时候报错了。下面方法解决了
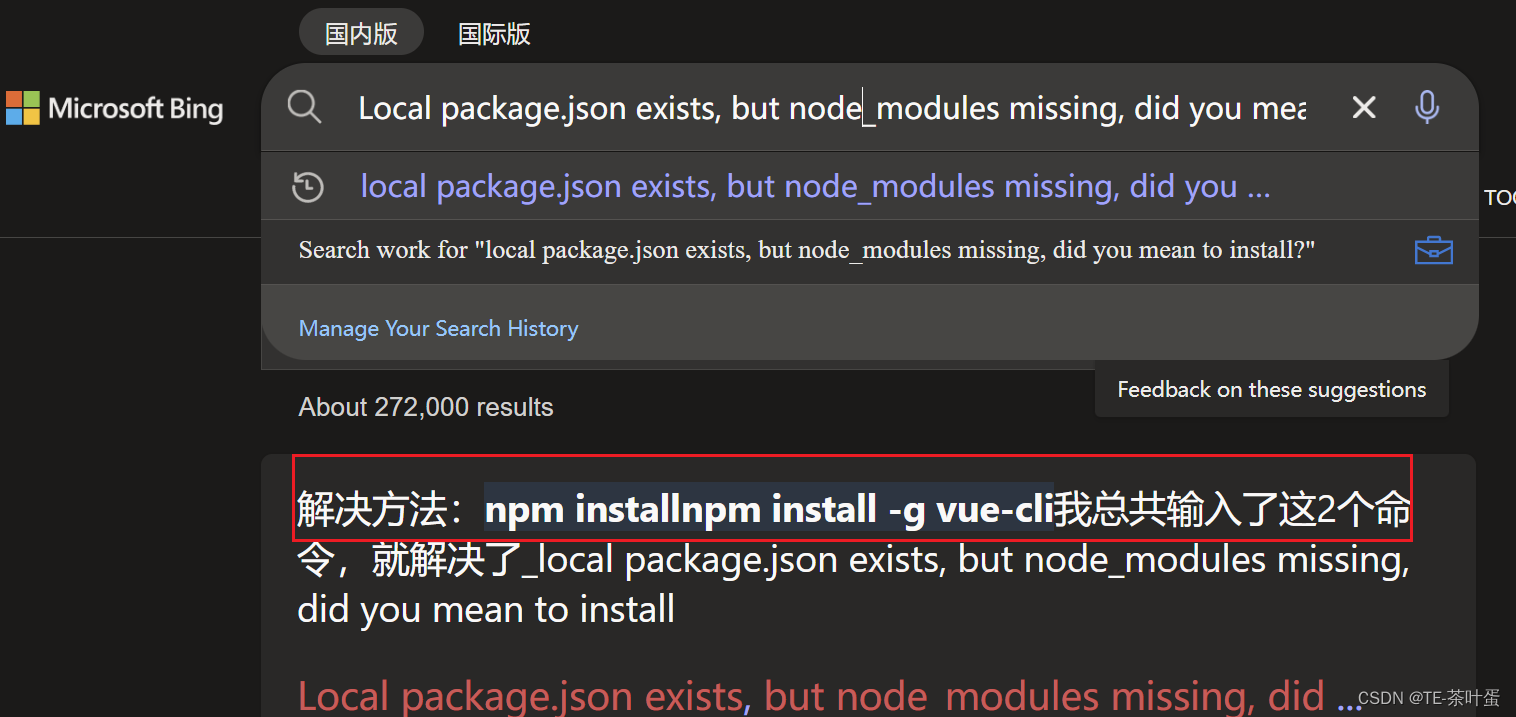
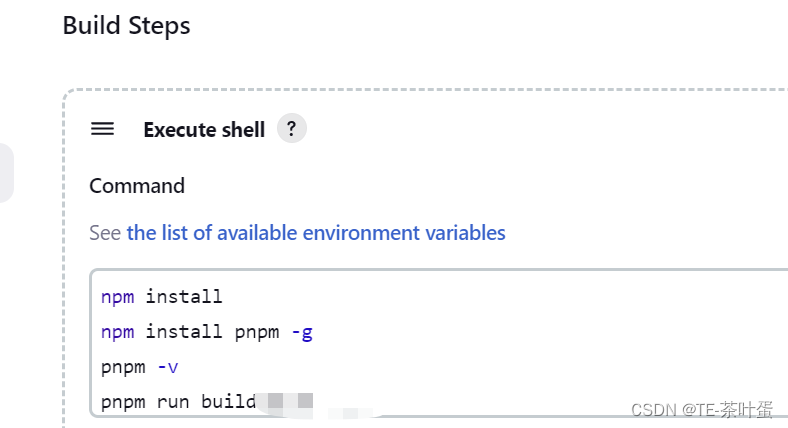
2023年 最后一个工作日 。修了一天bug,下班

中网络(Network)不显示请求接口(一闪而过))


)






)


)




