? 工欲善其事,必先利其器。
栈和队列 - Stack And Queue
栈
如何理解栈呢?
后进者先出,先进者后出,这就是典型的 "栈" 结构。
从栈的操作特性上来看,栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
事实上,从功能上来说,数组或者链表确实都可以替代栈,但你要知道,特定的数据结构是对特定场景的抽象,而且,数组或链表暴漏了太多的操作接口,操作上的确灵活运用,但同时使用时就变的不可控,自然也就更容易出错。
当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,就应该首选“栈”这种数据结构。
实现栈
既然数组或者链表可以替代栈,那么同样的,使用数组和链表可以实现栈。用数组实现的栈叫做顺序栈,用链表实现的栈叫做链式栈。
// 基于数组实现的顺序栈
public class ArrayStack {
private String[] items; // 数组
private int count; // 栈中元素个数
private int n; //栈的大小
// 初始化数组,申请一个大小为n的数组空间
public ArrayStack(int n) {
this.items = new String[n];
this.n = n;
this.count = 0;
}
// 入栈操作
public boolean push(String item) {
// 数组空间不够了,直接返回false,入栈失败。
if (count == n) return false;
// 将item放到下标为count的位置,并且count加一
items[count] = item;
++count;
return true;
}
// 出栈操作
public String pop() {
// 栈为空,则直接返回null
if (count == 0) return null;
// 返回下标为count-1的数组元素,并且栈中元素个数count减一
String tmp = items[count-1];
--count;
return tmp;
}
}
上面代码是拷贝网上的,使用java的数组实现栈。
了解了定义和基本操作,那它的操作的时间、空间复杂度是多少呢?
不管是顺序栈还是链式栈,存储数据只需要一个大小为 n 的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是 O(1)。
注意,这里存储数据需要一个大小为 n 的数组,并不是说空间复杂度就是 O(n)。因为,这 n 个空间是必须的,无法省掉。所以我们说空间复杂度的时候,是指除了原本的数据存储空间外,算法运行还需要额外的存储空间。
不管是顺序栈还是链式栈,入栈、出栈只涉及栈顶个别数据的操作,所以时间复杂度都是 O(1)。
栈的应用 - 四则运算
四则运算是编译器利用栈来实现的表达式求值。
对于四则运算来说,我们大脑可以很快的计算出来,但是对于计算机而言,理解四则运算本来就难。
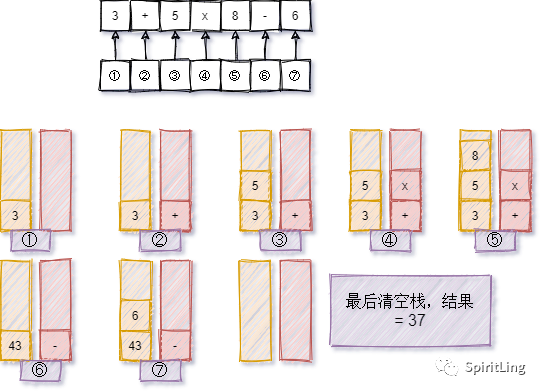
那么编译器如何通过栈来解决四则运算,首先我们需要两个栈,一个保存操作数,一个保存运算符。从左向右遍历表达式,当遇到数字,我们就直接压入操作数栈;当遇到运算符,就与运算符栈的栈顶元素进行比较。
如果比运算符栈顶元素的优先级高,就将当前运算符压入栈;如果比运算符栈顶元素的优先级低或者相同,从运算符栈中取栈顶运算符,从操作数栈的栈顶取 2 个操作数,然后进行计算,再把计算完的结果压入操作数栈,继续比较。
队列
栈是后进先出,那有没有先进先出的呢?当然有,就是队列。
先进先出,这就是典型的“队列”
栈只支持两个基本操作:入栈 push()和出栈 pop()。队列跟栈非常相似,支持的操作也很有限,最基本的操作也是两个:入队 enqueue(),放一个数据到队列尾部;出队 dequeue(),从队列头部取一个元素。
所以,队列跟栈一样,也是一种操作受限的线性表数据结构。
队列的概念很好理解,基本操作也很容易掌握。作为一种非常基础的数据结构,队列的应用也非常广泛,特别是一些具有某些额外特性的队列,比如循环队列、阻塞队列、并发队列。它们在很多偏底层系统、框架、中间件的开发中,起着关键性的作用。比如高性能队列 Disruptor、Linux 环形缓存,都用到了循环并发队列;Java concurrent 并发包利用 ArrayBlockingQueue 来实现公平锁等。
实现队列
跟栈一样,队列可以用数组来实现,也可以用链表来实现。用数组实现的栈叫作顺序栈,用链表实现的栈叫作链式栈。同样,用数组实现的队列叫作顺序队列,用链表实现的队列叫作链式队列。
// 用数组实现的队列
public class ArrayQueue {
// 数组:items,数组大小:n
private String[] items;
private int n = 0;
// head表示队头下标,tail表示队尾下标
private int head = 0;
private int tail = 0;
// 申请一个大小为capacity的数组
public ArrayQueue(int capacity) {
items = new String[capacity];
n = capacity;
}
// 入队
public boolean enqueue(String item) {
// 如果tail == n 表示队列已经满了
if (tail == n) return false;
items[tail] = item;
++tail;
return true;
}
// 出队
public String dequeue() {
// 如果head == tail 表示队列为空
if (head == tail) return null;
// 为了让其他语言的同学看的更加明确,把--操作放到单独一行来写了
String ret = items[head];
++head;
return ret;
}
}
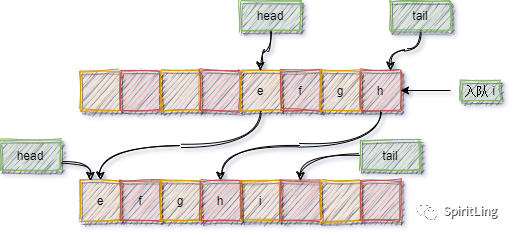
对于栈来说,我们只需要一个栈顶指针就可以了。但是队列需要两个指针:一个是 head 指针,指向队头;一个是 tail 指针,指向队尾。
当 a、b、c、d 依次入队之后,队列中的 head 指针指向下标为 0 的位置,tail 指针指向下标为 4 的位置。
当我们调用两次出队操作之后,队列中 head 指针指向下标为 2 的位置,tail 指针仍然指向下标为 4 的位置。
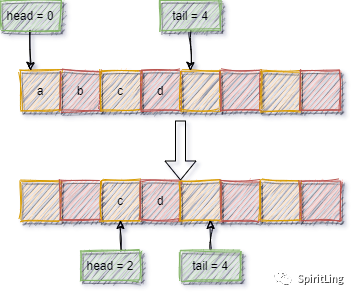
随着不停地进行入队、出队操作,head 和 tail 都会持续往后移动。当 tail 移动到最右边,即使数组中还有空闲空间,也无法继续往队列中添加数据了。
在数组那一节,我们也遇到过类似的问题,就是数组的删除操作会导致数组中的数据不连续。你还记得我们当时是怎么解决的吗?对,用数据搬移!
每次进行出队操作都相当于删除数组下标为 0 的数据,要搬移整个队列中的数据,这样出队操作的时间复杂度就会从原来的 O(1) 变为 O(n)。实际上,我们在出队时可以不用搬移数据。如果没有空闲空间了,我们只需要在入队时,再集中触发一次数据的搬移操作。
所以改造下上面的代码后:
// 入队操作,将item放入队尾
public boolean enqueue(String item) {
// tail == n表示队列末尾没有空间了
if (tail == n) {
// tail ==n && head==0,表示整个队列都占满了
if (head == 0) return false;
// 数据搬移
for (int i = head; i items[i-head] = items[i];
}
// 搬移完之后重新更新head和tail
tail -= head;
head = 0;
}
items[tail] = item;
++tail;
return true;
}
从代码中我们看到,当队列的 tail 指针移动到数组的最右边后,如果有新的数据入队,我们可以将 head 到 tail 之间的数据,整体搬移到数组中 0 到 tail-head 的位置。
出队操作的时间复杂度仍然是 O(1),但是入队操作时需要使用前面提到的时间复杂度中的摊还分析,时间复杂度仍是 O(1) 。
循环队列
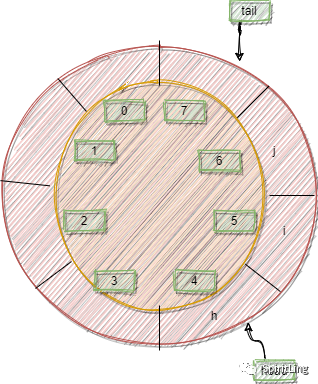
刚才用数组来实现队列的时候,在 tail==n 时,会有数据搬移操作,这样入队操作性能就会受到影响。那有没有办法能够避免数据搬移呢?我们来看看循环队列的解决思路。
循环队列,顾名思义,它长得像一个环。原本数组是有头有尾的,是一条直线。现在我们把首尾相连,扳成了一个环。如下图所示
队列应用
队列这种数据结构很基础,平时的业务开发不大可能从零实现一个队列,甚至都不会直接用到。而一些具有特殊特性的队列应用却比较广泛,比如阻塞队列和并发队列。
阻塞队列其实就是在队列基础上增加了阻塞操作。简单来说,就是在队列为空的时候,从队头取数据会被阻塞。因为此时还没有数据可取,直到队列中有了数据才能返回;如果队列已经满了,那么插入数据的操作就会被阻塞,直到队列中有空闲位置后再插入数据,然后再返回。
线程安全的队列我们叫作并发队列。最简单直接的实现方式是直接在 enqueue()、dequeue() 方法上加锁,但是锁粒度大并发度会比较低,同一时刻仅允许一个存或者取操作。实际上,基于数组的循环队列,利用 CAS 原子操作,可以实现非常高效的并发队列。这也是循环队列比链式队列应用更加广泛的原因。
历史系列文章
算法与数据结构(四)- 链表
算法与数据结构(三)- 数组
算法与数据结构(二)- 算法分析
算法与数据结构(一)- 概述








)
)


从官网下载安装包)



——容器)


