
一、字符串操作---String类
1、String可以表示一个字符串,不能被继承(最终类)不可变
2、String类实际是使用字符数组存储的
String类的两种赋值方式:
(1)一种称为直接赋值、Java推荐使用第一种方式
String name="小白"
(2)通过关键字new调用String的构造方法赋值:new申请内存空间
String name = new String("小白")
String类的两种赋值分析:
1、字符串常量池
2、String name = new String("小白")在内存中分析
3、String name = "小白",在内存中分析
String 类编译期与运行期分析:
1、编译期和运行期
2、代码示例:4种情况分析:直接赋值字符串连接时,考虑编译期与运行期
如果在编译期值可以被确定,那么就使用已有的对象,否则会创建新对象
String a="a";String a+1;String a2="a1";System.out.println(a1==a2);String类字符与字符串操作方法:

String类字节与字符串操作方法:

String类判断是否以指定内容开头或结尾:

String类替换操作:

String字符串截取操作:

String字符串拆分操作:

String字符串查找操作:

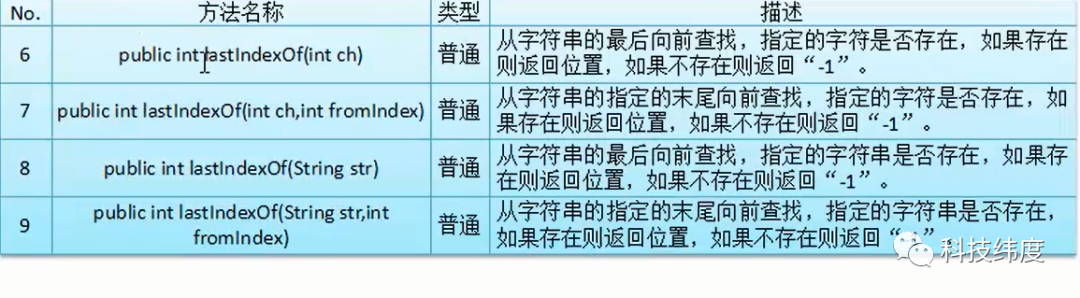
String类其它操作方法:

二、字符串操作-----StringBuffer类
在实际开发当中,我们经常会使用到字符串连接的操作,如果用String来操作,则使用“+”号来完成字符串的连接操作。
使用String连接字符串,代码性能会非常低,因为String的内容不可改变。解决这个问题的方法是使用StringBuffer.
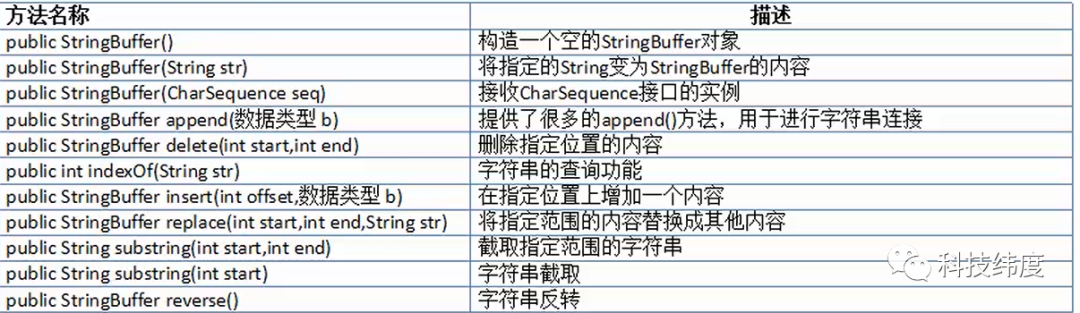
package com.vince.ex;public class StringDemo { public static void main(String[] args) { String a = "a"; String b = "b"; String c = a+b+1; System.out.println(c); String d="a"+1+2+3+4+"b";//a1234b //常量相加没有性能问题(编译期进行优化) //StringBuffer目的是为了解决字符串相加时带来的性能问题(常量与变量) //StringBuffer的内部实现采用字符数组、默认数组的长度为16,超过数组大小时,动态扩充的算法是原长度的*2+2 //所以当我们要预知添加的数据长度时,建议使用带初始化容量的构造方法,来避免动态扩张的次数,从而提高效率 //线程安全,会影响性能 StringBuffer sb = new StringBuffer(32);//带容量的构造 sb.append(a).append(b).append(1); System.out.println(sb.toString()); }}StringBuffer常用操作方法:
StringBuffer的兄弟StringBuilder:
一个可变的字符序列,此类提供一个与StringBuffer兼容的API,但不保证同步该类被设计用作StringBuffer的一个简易替换,用在字符串缓冲期被单个线程使用的时候(这种情况很普遍)如果可能,建议优先采用该类,因为在大多数实现中,它比StringBuffer更快。
JDK1.5后、字符串相加原理分析:
package com.vince.ex;public class StringBufferDemo { public static void main(String[] args) { //面试题:StringBuffer与StringBuilder的区别? //StringBuilder是线程不安全的,性能高,适合在单线程中使用,这种情况占大多数在JDK1.5后添加 //StringBuffer是线程安全的,性能低,适合在多线程中使用,JDK1.0 StringBuilder sb = new StringBuilder(); /** * 字符串相加操作 * 1、多个常量相加没有性能问题,在编译期优化 * 2、常量与常量相加、会产生多个垃圾对象 */ //String a = "a"+1; //String b = a+"b"; String c = null; for(int i=0;i<5;i++) { c+=i;//每个循环会产生一个StringBuilder对象实现拼接,性能低、最好是手动创建StringBuilder来拼接 } //1、字符串相加,在编译后,会使用StringBuilder来优化代码,实现拼接 }}三、程序国际化
1、对国际化程序的理解:
lnternationalization:国际化程序可以这样理解:
同一套程序代码,可以在各个语言环境下进行使用。只是语言显示不同,那么具体程序操作本身都是一样的,那么国际化程序完成的就是这样的一个功能。
2、Locale类:
Locale对象表示了特定的地理、政治和文化地区。需要Locale来执行其任务的操作称为语言环境敏感的操作,它使用Locale为用户量身定制信息,例如:显示一个数值就是语言环境敏感的操作,应该根据用户的国家、地区或文化风俗/传统来格式化数值。
使用此类中的构造方法来创建Locale:
Locale(String language)
Locale(String langusge,String country)
通过静态方法创建Locale:
getDefault()
package com.vince.ex;public class I18NDemo { public static void main(String[] args) { //创建一个环境语言对象,该对象会根据参数设置来自动选择与相关的语言环境 //参数:语言、地区 Locale locale_CN = new Locale("zh","CN"); Locale locale_US = new Locale("en","UD"); //获取当前系统默认的语言环境 Locale locale_default = Locale.getDefault(); }3、ResourceBundle类:
国际化的实现核心在于显示的语言上,通常的做法是将其定义成若干个属性文件(文件后缀是*。properties)属性中的格式采用“key=value”的格式进行操作。
ResourceBundle类表示的是一个资源文件的读取操作,所有的资源文件需要使用ResourceBundle进行读取,读取的时候不需要加上文件的后缀。
getBundle(String baseName)
getBundle(String baseName,Locale locale)
getString (String key)
properties文件:属性文件(配置文件)内容以键值对的形式存放(key-value)
ResourceBundle工具类:来绑定属性文件,并指定Locale对象,来自动选择使用哪个属性文件,默认讲使用与操作系统相同的语言环境
getString ()方法来从属性文件中使用key来获取value
注意:ResourceBundle工具类是只读的
4、处理动态文本:
前面的读取示例读取的内容都是固定的,如果现在假设要想打印这样的消息“欢迎你,xxx!”,具体的名字不是固定的,那么就要使用动态文本进行程序的处理。
进行动态的文本处理,必须使用Java.text.MessageFormat类完成。这个类是Java.text,Format的子类
四、Math与Random类
1、Math类
Math类包含用于执行基本数学运算的方法、如初等指数、对数、平方根和三角函数。
使用Math类可以有以下两种方式:
(1)直接使用(Math所在的包Java.lang为默认引入的包)
(2)使用import.static java.lang.Math.abs;静态导入
| static double Pl | 对任何值都更接近pi的double值 |
| abs(double a) | 返回double值的绝对值 |
| random() | 返回带正号的double值,该值大于等于0.0且小于1.0 |
| round(double a) | 返回最近参数并等一整数的double值 |
| sqrt(double a) | 返回正确舍入的double值的平方根 |
2、Random类
Random:此类在实例用于生成随机数流
| nextLong() | 返回下一个伪随机数的long值 |
| nextBoolean() | 返回下一个伪随机数的boolean值 |
| nextDoble() | 返回下一个伪随机数,在0.0和1.0之间的double值 |
| nextFloat() | 返回下一个伪随机数,在0.0和1.0之间的float值 |
| nextInt() | 返回下一个伪随机数,int值 |
| nextInt(int n) | 返回一个伪随机数,在1(包括)和指定值分布的int值 |
五、日期操作类
1、Date类
类Date表示特定的瞬间,精确到毫秒,也就是程序运行时的当前时间
Date date = new Date();//实例化Date类,表示当前时间
2、Calender类
Calender、日历类、使用此类可以将时间精确到毫秒显示。两种实例化方式:
Calender c = Calender.getlnstance();
Calender c = new GregorianCalender();
3、DateFormat类及子类SimpleDateFormat
六、对象比较器
对两个或多个数据进行比较,以确定它们是否相等,或确定它们之间的大小关系及排列顺序称为比较。
Arrays.sort方法可实现对象的排列顺序操作:
(1)Comparable接口:
此接口强行对实现它的每个类的对象进行整体排序,这种排序被称为类的自然排序,类的compareTo方法被称为它的自然比较方法。
(2)Comparator接口:
Comparable接口是要求自定义类去实现,按照oo原则:对修改关闭,对扩展开发,那么如果这个类已经定义好了,不想再去修改它,那如何实现比较呢?Comparator接口:强行对一个对象collection进行整体排序的比较。
七、对象的克隆
将一个对象复制一份,称为对象的克隆技术。
在Object类中存在一个clone()方法:
protected Object clone()throws CloneNotSupportdException(如果一个类的对象要想克隆,则对象所在的类必须实现Cloneable接口。此接口没有定义任何方法,是一个标记接口)
对象需要具有可能功能:
1、实现Cloneable接口(标记接口)
2、重写Object类中的clone方法
八、System与Runtime类
System类代表系统,系统级的很多属性和控制方法都放置在该类的内部。该类位于java.lang包
1、成员变量
System类内部包含in、out和err三个成员变量,分别代表标准输入流(键盘输入),标准输入流(显示器)和标准错误输出流
2、成员方法
System类中提供了一些系统级的操作方法
参数(源数组、源数组的起始位置、目标数组的起始位置 、长度)
(1)public static void arraycopy(Object src、int srcPos、Object dest,int destPos,intlength)该方法的作用是数组拷贝,也就是将一个数组中的内容复制到另一个数组中的指定位置,由于该方法是native方法,所以性能上比使用循环高效
(2)public static long currentTimeMillis()该方法的作用是返回当前的计算机时间,时间的表达格式为当前计算机时间和GMT时间(格林威治时间)1970年1月1号0时0分0秒所差的毫秒数
(3)public static void exit(int status)该方法的作用是退出程序。其中status的值为0代表正常退出,非零代表异常退出,使用该方法可以在图形界面编程中实现程序的退出功能等。
(4)public static void gc()该方法的作用是请求系统进行垃圾回收,至于系统是否立即回收,则取决于系统中的垃圾回收算法实现以及系统执行时的情况
(5)public static String getProperty(String key)该方法的作用是获得系统中属性名为key的属性对应的值
java.version java 运行时环境版本
Java.home Java安装目录
os.name 操作系统的名称
os.version 操作系统的版本
user.name 操作系统账号名称
user.heme 用户的主目录
user.dir 用户的当前工作目录
Runtime类:每个Java应用程序都有一个Runtime类实例、使应用程序能够与其运行的环境相连接。
Runtime rt = Runtime.getRuntime();
System.out.println("处理器数量:"+rt.availableProcessors()+"个");
System.out.println("JVM总内存数:"+rt.totaIMemory()+"byte")
System.out.println("JVM空闲内存数:"rt.freeMemory()+"byte");
System.out.println("JVM可用最大内存数:"rt.maxMemory()+"byte);
在单独的进程中执行指定的字符串命令
rt.exec("notepad")
九、数字处理工具类
Biglnteger:可以让超过lnteger范围内的数据进行运算
构造方法:public Biglnteger(String val)
常用方法:
public Biglnteger add(Biglnteger val)
public Biglnteger subtact(Biglnteger val)
public Biglnteger nultiply(Biglnteger val)
public Biglnteger divide(Biglnteger val)
public Biglnteger[] divideAndRemainder(Biglnteger val)
BigDecimal:由于在运算的时候,float类型和double很容易丢失精度,为了能精确的表示,计算浮点数,Java提供了BigDecimal,不可变的,任意精度的有符号十进制。
构造方法:public BigDecimal (String val)
常用方法:
public BigDecimal add(BigDecimal augend)
public BigDecimal subtact(BigDecimal subtrahend)
public BigDecimal multiply(BigDecimal multitlplicand)
public BigDecimal divide(BigDecimal divisor)
DecimalFormat:java提供DecimalFormat类,帮你用最块的速度将数字格式化为你需要的样子.
十、MD5工具类
MD5的全称是Message-Digest Algorithm5(信息摘要算法)
确定信息算法
MessageDigest md5=MessageDigest.getlnstance("MD5");
JDK1.8新增Base64
String newstr = Base64.getEncoder().encodeToString(md5.digestBytes("utf-8")));
1.8之前使用sun.misc.BASE64Encoder(此类没有访问权限,在rt.jar中添加访问权限:sun/misc/*)
BASE64Encoder base64Encoder();
base64.encode(md5.digest(str.getBytes("uft-8)));
package com.common.tools;import java.security.MessageDigest;public abstract class MD5Tools{ public final static String MD5(String pwd) { //用于加密的字符 char md5String[] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F' }; try { //使用平台的默认字符集将此 String 编码为 byte序列,并将结果存储到一个新的 byte数组中 byte[] btInput = pwd.getBytes(); //信息摘要是安全的单向哈希函数,它接收任意大小的数据,并输出固定长度的哈希值。 MessageDigest mdInst = MessageDigest.getInstance("MD5"); //MessageDigest对象通过使用 update方法处理数据, 使用指定的byte数组更新摘要 mdInst.update(btInput); // 摘要更新之后,通过调用digest()执行哈希计算,获得密文 byte[] md = mdInst.digest(); // 把密文转换成十六进制的字符串形式 int j = md.length; char str[] = new char[j * 2]; int k = 0; for (int i = 0; i < j; i++) { // i = 0 byte byte0 = md[i]; //95 str[k++] = md5String[byte0 >>> 4 & 0xf]; // 5 str[k++] = md5String[byte0 & 0xf]; // F } //返回经过加密后的字符串 return new String(str); } catch (Exception e) { return null; } }}package com.common.tools;import java.security.MessageDigest;/** * MD5加密工具类 * */public abstract class MD5Tools{ public final static String MD5(String pwd) { //用于加密的字符 char md5String[] = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F' }; try { //使用平台的默认字符集将此 String 编码为 byte序列,并将结果存储到一个新的 byte数组中 byte[] btInput = pwd.getBytes(); //信息摘要是安全的单向哈希函数,它接收任意大小的数据,并输出固定长度的哈希值。 MessageDigest mdInst = MessageDigest.getInstance("MD5"); //MessageDigest对象通过使用 update方法处理数据, 使用指定的byte数组更新摘要 mdInst.update(btInput); // 摘要更新之后,通过调用digest()执行哈希计算,获得密文 byte[] md = mdInst.digest(); // 把密文转换成十六进制的字符串形式 int j = md.length; char str[] = new char[j * 2]; int k = 0; for (int i = 0; i < j; i++) { // i = 0 byte byte0 = md[i]; //95 str[k++] = md5String[byte0 >>> 4 & 0xf]; // 5 str[k++] = md5String[byte0 & 0xf]; // F } //返回经过加密后的字符串 return new String(str); } catch (Exception e) { return null; } }}十一、数据结构之二叉树实现
树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为节点)按分支关系组织起来的结构。二叉树(Binary Tree)是每个节点最多有两个子树的有序树。通常子树被称作“左子树”和“右子树”。
二叉树的分类及特点:
(1)完全二叉树
完全二叉树是二叉树的-一个分类,它的特点是每个节点的孩子节点的数量可以是0,1, 2个,除此之外它要求每层节点添加,必须是从左到右,不允许跳着添加。
(2)满二叉树(Full Binary tree)
满二叉树它的特点是每个节点的孩子节点要么没有,要么就是两个,不允许出现单个孩子的情况。
(3)二叉搜索树(Ordered Binary Tree )
也称二叉排序树,这个是我们接触的最多的一种结构, 它要求节点的左子树小于该节点本身,右子树大于该节点,每个节点都符合这样的规则,对二叉搜索树进行中序遍(左中右)历就得到一个有序的序列
(4)均衡二叉树( Balanced Binary Tree)
均衡二叉树指的是-一个节点的左右子树的高度差值不能大于1,均衡二叉树一般都是在二叉搜索树的基础之上添加自动维持平衡的性质,这种树的插入,搜索,删除的综合效率比较高。
(5)完美二叉树(Perfect binary Tree)
完美二叉树是理想中的一种二叉树,这种树的特点就是非常完美,每个节点都有两个孩子节点,并且每层都被完全填充,完美二叉树的叶子节点的高度都是一样。
二叉搜索树算法的排序规则:
1、选择第一个元素作为根节点
2、之后如果元素大于根节点放在右子树,如果元素小于根节点,则放在左子树
3、最好按照中序遍历的方式进行输出,则可以得到排序的结果(左→根→右)
先序遍历:根左右
后序遍历:左右根
如:1、2、3、4、5、6、7、8、9、10
主类:
package com.booy1;public class BinaryTreeTest { public static void main(String[] args) { BinaryTree bt = new BinaryTree(); bt.add(6); bt.add(5); bt.add(9); bt.add(8); bt.add(1); bt.add(7); bt.add(2); bt.print(); }}BinaryTree 类:
package com.booy1;public class BinaryTree { private Node root; //添加节点 public void add(int data){ if(root==null) { root = new Node(data); }else { root.addNode(data); } } //遍历节点 public void print(){ root.printNode(); } private class Node{ private int data; private Node left; private Node right; public Node(int data ){ this.data = data; } //添加节点 public void addNode(int data){ if(this.data>data) { if(this.left==null) { this.left = new Node(data); }else { this.left.addNode(data); } }else{ if(this.right==null) { this.right = new Node(data); }else { this.right.addNode(data); } } } //遍历节点 public void printNode(){ if(this.left != null) { this.left.printNode(); } System.out.print(this.data+">"); if(this.right != null) { this.right.printNode(); } } } }/**运行结果:1>2>5>6>7>8>9>*/十二、JDK1.8新特性-Lambda表达式
1、Lambda表达式(也称为闭包)是整个Java8发行版中最受期待的Java语言层面上的改变,Lambda允许把函数作为一个方法的参数(函数作为参数传递进方法中)或者把代码看成数据。Lambda表达式用于简化Java中接口式的匿名内部类。被称为函数式接口的概念。函数式接口就是一个具有一个方法的普通接口,像这样的接口可以被隐式转换为Lambda表达式。
语法:
(参数1,参数2....)->{......}
(1)没有参数时使用Lambda表达式
(2)带参数时使用Lambda表达式
(3)代码块中只有一句代码时使用Lambda表达式
(4)代码块中有多句代码时使用Lambda表达式
(5)有返回值的代码块
(6)参数中使用final关键字
import java.sql.SQLOutput;import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;import java.util.List; //让代码更加简洁,不会单独生成class文件public class LambdaTest { /** * lambda呈现入口 */ public void exeEntry(String message,HandlerArg handlerArg){ handlerArg.handleEntry(message); } /** * 声明一个接口(只能有一个抽象方法接口),以lambda的语法来表达该接口的方法调用 */ public interface HandlerArg{ public void handleEntry(String message); } /** * 声明一个接口,以lambda的语法来表达该接口的方法调用 */ public interface HandlerArgs{ public int handleEntry(String message1,String message2); } /** * lambda呈现入口 * */ public int exeEntry(String message1,String message2,HandlerArgs handlerArgs){ return handlerArgs.handleEntry(message1, message2); } public static void main(String[] args) { LambdaTest lambdaTest = new LambdaTest(); //一、 //1."msg"为传入HandlerArg接口的handleEntry方法所需参数,在"->前面";而后面 直接执行方法所要做的事; //2.参数可不声明参数类型; //3.单个参数不需要被"()"包围起来; //lambdaTest.exeEntry("the hardest thing is to feel good everyday",msg -> System.out.println(msg)); //二、 //也可以预先实现接口,再将接口作为参数传递 //HandlerArg handlerArg = msg -> System.out.println(msg); //lambdaTest.exeEntry("the hardest thing is to feel good everyday",handlerArg); //三、 //多条语句,则直接作为一个函数来使用,其实这里就类似于javaScript的方法传递了 //lambdaTest.exeEntry("the hardest thing is to feel good everyday",msg -> { // String strPrefix = "chengxp said:"; // System.out.println(strPrefix + msg); //}); //四、 //多个参数,并处理后返回结果// int strsLength = lambdaTest.exeEntry("sdf5745","fgdg", (msg1,msg2) -> {return msg1.length() + msg2.length();});// System.out.println("两个字符串长度之和为:" + strsLength); //五、 //例如集合框架中用的比较多的排序,可以这么写 List strs = new ArrayList<>(); strs.add("bb"); strs.add("cc"); strs.add("dd"); strs.add("aa"); //以前是这么写的 Collections.sort(strs, new Comparator() { public int compare(String o1, String o2) { return o1.compareTo(o2); } }); //这里也是1.8的遍历语法。不过试了一下,效率没有普通的for循环效率高。 strs.forEach(str -> System.out.println(str)); //用lambda写 Collections.sort(strs,(s1,s2) -> s1.compareTo(s2)); strs.forEach(str -> System.out.println(str)); }}Java 8 新增了接口的静态方法和默认方法。即接口可以有实现方法,而且不需要实现类去实现其方法,通过static和default关键字实现
静态方法和默认方法的引进,解决了接口一旦发生修改将与现有的实现不兼容的问题
默认方法与静态方法并不影响函数接口的契约,可以任意使用
二、示例
1、接口
package com.xl.infc; public interface Employee { /** * 抽象方法 实现类必须重写,必须通过实现类的实例来调用 */ public void say(); /** * 静态方法 只能通过接口的接口名来调用,实现类可以互不冲突的定义相同的方法并通过实现类的类名来调用 */ public static void work() { System.out.println("干活"); } /** * 默认方法 必须通过实现类的实例来调用,可以重写,但不能再加default关键字,且将覆盖接口中的实现 */ public default void role() { System.out.println("员工"); }}2、实现
package com.xl.infc; public class Programmer implements Employee { @Override public void say() { System.out.println("上班"); } /** * 实现类可以定义的和接口相同的静态方法,通过类名来调用 */ public static void work() { System.out.println("撸代码"); } /** * 重写接口的默认方法,不能再用default关键字修饰,且将覆盖接口中的实现,且必须通过实例来调用 */ @Override public void role() { System.out.println("程序员"); } public static void main(String[] args) { Employee.work(); Programmer.work(); Programmer p = new Programmer(); p.say(); p.role(); } }

:对列和行的操作)

函数)



-性能银弹:缓存...)








)

