今天我们在学习朴素贝叶斯分类器之前,我们先来总结下前面经常用到的内容,方法链:在scikit-learn中所有模型的fit方法返回的都是self。我们用一行代码初始化模型并拟合,对应代码如下:logreg = LogisticRegression().fit(x_train, y_train).
这里我们利用fit的返回值(即self)将训练后的模型复制给变量logreg。这种方法钓友的拼接(先调用_init_.然后调用fit)被称为方法链,在scikit-learn中方法链的另一种常用的方法是在一行代码中同时fit和predict,如下:
logreg = LogisticRegression()
y_pred = logreg.fit(x_train, y_train).predict(x_test)
甚至可以在一行代码中同时完成模拟初始化、拟合和预测,如下:
y_pred = LogisticRegression().fit(x_train, y_train).predict(x_test)
不过这种非常简短的写法并不完美,一行代码中如果同时发生了很多事情,可能会使得代码难以阅读。此外,拟合后的回归模型也没有保存在任何变量中,所以我们既不能查看他也不能用他来预测其他数据。
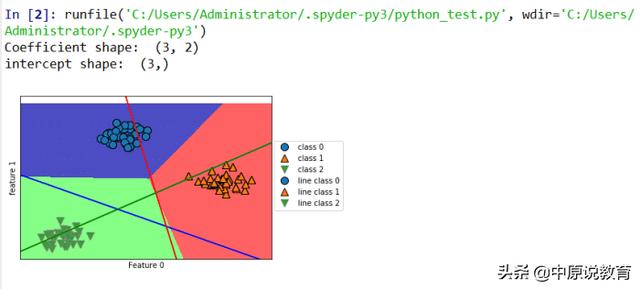
线性模型的多分类决策边界
朴素贝叶斯分类器:朴素贝叶斯分类器是和前面面我们说的线性模型非常相似的一种分类器,但他的训练速度往往会更快。这种高效率所付出的代价是,朴素贝叶斯模型的泛化能力要比线性分类器稍差。
朴素贝叶斯分类器如此高效的原因在于他通过单独查看每个特征来学习参数,并从每个特征中收集到简单类别的统计数据。scikit-learn中实现了三种朴素贝叶斯分类器,分别为:应用于任意连续数据的GaussianNB,用于假定输入数据为二分类的BernoulliNB和假定输入计数数据(即每个特征代表某个对象的整数计数,比如一个单词在句子里面出现的次数)。后两种主要用于文本分类。
朴素贝叶斯分类器 很多优点和缺点与线性模型相同。它们的训练和预测速度都很快,其训练过程也容易理解,对应模型对高危稀疏数据的效果很好,对参数的鲁棒性也不错。对于非常大的数据集来说具有良好的效果。而其缺点就是这些数据集上即使使用 线性模型也会耗费大量的时间。






...)




...)
)



?...)


