文章目录
- 1 前言
- 2 经验误差与过拟合
- 3 训练集与测试集的划分方法
- 3.1 留出法(Hold-out)
- 3.2 交叉验证法(Cross Validation)
- 3.3 自助法(Bootstrap)
- 4 调参与最终模型
- 5 结语

1 前言
欢迎来到蓝色是天的机器学习笔记专栏!在上一篇文章《机器学习理论笔记(一):初识机器学习》中,我们初步了解了机器学习,并探讨了其定义、分类以及基本术语。作为继续学习机器学习的进一步之旅,今天我们将进一步讨论机器学习中的一些重要概念和技巧。
在本文中,我们将重点关注以下几个方面:经验误差与过拟合、数据集划分、调参以及最终模型的选择。这些主题对于解决实际问题中的机器学习挑战至关重要。通过深入了解这些概念和方法,我们可以更好地理解机器学习模型的训练过程,提高模型的预测准确性,从而使我们能够做出更好的决策和预测。
无论你是新手还是有经验的机器学习从业者,本文都将为你提供有价值的知识和实用的技巧。让我们一起探索机器学习中这些关键领域,并加深对机器学习的理解。让我们开始吧!
2 经验误差与过拟合
在机器学习中,我们通常希望通过训练学习器来对新样本进行泛化,即在未见过的数据上具有良好的预测准确性。为了衡量学习器的性能,我们引入了错误率、精度、误差等概念。
- 错误率表示分类错误的样本数占样本总数的比例,而精度则是错误率的补数,即1减去错误率。误差是指学习器的实际预测输出样本与样本真实输出之间的差异。
- 训练误差,也称为经验误差,表示学习器在训练集上的误差。训练误差是通过与已知标签进行比较来评估学习器的预测准确性。然而,我们希望学习器在新样本上也能表现出良好的预测能力,即具有较低的泛化误差。
- 泛化误差是指学习器在新样本上的误差,它度量了学习器在未见过的数据上的表现能力。我们希望泛化误差尽可能小,但是我们只能通过训练集的经验误差作为指标进行衡量。
然而,经验误差往往无法完全反映学习器的泛化能力。当学习器过度追求在训练集上的准确性时,很可能会过于贴合训练数据的细节特征,而忽视了样本的一般性质,从而导致泛化性能下降。这种现象被称为过拟合。
过拟合是机器学习中一个常见的问题,即学习器在训练集上表现出较好的性能,但在新样本上的表现却差。它表明学习器过于复杂,将训练样本自身的特点当作了所有潜在样本都会具有的一般性质,从而导致了泛化性能的降低。
相对应的,欠拟合是指学习器对训练样本的一般性质学习得不够好,导致无法很好地进行预测和泛化。

虽然完全避免过拟合是不可能的,但我们可以采取一些措施来“缓解”过拟合并减小其风险。例如,我们可以增加更多的训练数据,以减少对特定样本的过度依赖。另外,我们还可以采用正则化方法来约束学习器的复杂度,以防止其过度拟合训练数据。
同时,对于欠拟合问题,我们可以尝试增加模型的复杂度或采用更复杂的算法来提高学习器的性能。此外,合理选择特征、调整模型参数以及使用集成学习等方法也可以帮助克服欠拟合问题。
在实际应用中,我们需要根据问题的特点和数据的情况来选择合适的机器学习算法,并采取恰当的方法来克服过拟合或欠拟合的问题,以达到更好的泛化性能。
3 训练集与测试集的划分方法
在机器学习中,训练集和测试集的划分是评估模型性能的重要步骤。合理划分训练集和测试集能够准确评估模型的泛化能力和性能。本文将介绍三种常用的训练集与测试集划分方法:留出法、交叉验证法和自助法,并讨论它们的优缺点和适用场景。
3.1 留出法(Hold-out)
留出法是最简单直接的划分方法之一。它将原始数据集划分为两个互斥的集合:一个用作训练集,另一个用作测试集。训练集用于训练模型的参数和规则,而测试集则用于评估模型的性能。划分时应保持训练集和测试集的数据分布相同,并确保测试集与训练集互斥,即测试样本不在训练集中出现。为了减小随机划分的影响,通常建议进行多次随机划分,并取平均值作为留出法的评估结果。
直接将数据集刀划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T,即D = S∪T, S∩T = ∅。 上训练出模型后,用T来评估其测试误差,作为对泛化误差的估计
优点:
简单易行,实现方便。
计算效率高,适用于大数据集。
缺点:
可能由于随机划分的不一致导致评估结果偏差较大。
对于小规模数据集,划分比例的选择有一定的挑战。
适用场景:
数据集规模较大。
对划分效果要求不苛刻的场景。
3.2 交叉验证法(Cross Validation)
交叉验证法是一种更稳健的划分方法,它将原始数据集划分为k个大小相似的互斥子集。然后,使用k-1个子集作为训练集,剩下的一个子集作为测试集,进行模型的训练和测试。重复这个过程k次,每次选择不同的测试集,最终将k次测试结果的均值作为最终评估结果。交叉验证法能够更充分地利用数据集的信息,减小因单次划分导致的偏差。常见的k值有10、5、20等,其中10折交叉验证是最常用的。
D=D1∪D2∪……Dk,Di∩Dj=∅(i≠j)
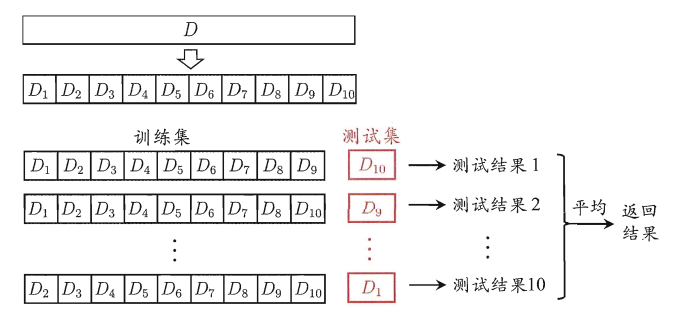
优点:
可以更准确地评估模型的性能,有效利用数据集。
具有较低的评估结果方差。
对于数据集较小且难以进行有效划分的情况下特别有用。
缺点:
计算复杂度高,需要进行多次模型训练和测试。
对于大规模数据集,计算资源消耗较大。
适用场景:
数据集规模较小。
对模型性能评估要求较高的场景。
3.3 自助法(Bootstrap)
自助法是一种特殊的划分方法,适用于数据集较小或难以有效划分训练集和测试集的情况。自助法通过自助采样的方式,从原始数据集中进行有放回地采样,生成一个与原始数据集大小相同的自助样本集。由于自助样本集的生成过程中部分样本可能多次出现,而另一部分样本可能未出现,因此可以使用自助样本集作为训练集,剩余未出现的样本作为测试集,得到一个称为包外估计(out-of-bag estimate)的评估结果。自助法能够更充分地利用数据集的信息,减小因划分导致的偏差,并且适用于数据集较小或难以有效划分的情况。
给定包含m个样本的数据集Q ,我们对它进行釆样产生数据集每次随机从Q中挑选一个样本,将其拷贝放入Df,然后再将该样本放回初始数据集D中,使得该样本在下次釆样时仍有可能被釆到;这个过程重复执行m次后,我们就得到了包含m个样本的数据集Df,这就是自助釆样的结果。显然,D中有一部分样本会在Df中多次出现,而另一部分样本不出现。可以做一个简单的估计,样本在m次釆样中始终不被釆到的概率是:
( 1 − 1 m ) m \left(1-{\frac{1}{m}}\right)^{m} (1−m1)m
取极限得到
* l i m m → ∞ ( 1 − 1 m ) m ↦ 1 e ≈ 0.368 \operatorname*{lim}_{m\rightarrow\infty}\left(1-\frac{1}{m}\right)^{m}\mapsto\frac{1}{e}\approx0.368 *limm→∞(1−m1)m↦e1≈0.368
优点:
可以有效利用小规模数据集,减小由于数据量不足导致的问题。
无需对数据集进行显式的划分,简化了训练集和测试集的划分过程。
缺点:
自助样本集中约有37%的样本未被采样到,可能导致评估结果偏乐观。
对于大规模数据集,自助法可能会导致计算资源浪费。
适用场景:
数据集规模较小或难以有效划分训练集和测试集的情况。
对数据集的利用率要求较高的场景。
4 调参与最终模型
在机器学习中,调参和算法选择是非常重要的步骤,它们直接影响到最终模型的性能和泛化能力。本章将介绍调参的概念以及一些常见的调参方法,同时还会涉及到最终模型的训练和评估。
调参的过程实际上和算法选择并没有本质的区别。对于许多学习算法来说,有很多参数需要设置,而这些参数的不同取值通常会导致学得模型的性能有显著差异。因此,我们需要对参数进行调节以找到最优的参数配置。然而,由于学习算法的参数通常是连续的实数值,无法对每种参数取值都进行模型训练。为了解决这个问题,我们常常会选择一个参数的范围和变化步长,然后在这个范围内进行参数的取值评估。例如,在范围 [0, 0.2] 内以 0.05 为步长进行取值评估,这样就得到了5个候选参数值。尽管这种方法不能保证找到最佳的参数值,但是通过权衡计算开销和性能估计,它仍然是一个可行的解决方案。
我们通常会将学得模型在实际使用中遇到的数据称为测试数据,为了区分,模型评估和选择中用于评估测试的数据集被称为验证集(validation set)。在调参过程中,我们会使用验证集来评估不同参数配置下模型的性能,并选择表现最好的参数配置作为最终模型的参数。
需要注意的是,在模型训练和调参完成后,我们还需要使用初始的数据集重新训练模型。这样做的目的是让初始的测试集也被模型学习,从而进一步提升模型的学习效果。类比于考试的情形,就像我们每次考试完后,需要复习和消化考试题目的内容,从而能够更好地应对下一次考试。因此,重新训练模型可以增强模型的泛化能力和性能。
综上所述,调参和最终模型的训练是实现好的机器学习模型的重要步骤。通过选择合适的参数值以及重新训练模型,我们可以进一步提升模型的性能和泛化能力,从而更好地适应实际应用场景。调参需要耐心和实践经验,同时也需要通过验证集的评估来指导参数选择的过程。最终,我们希望通过调参和最终模型的训练得到一个具有良好性能的模型,以解决实际问题并取得好的效果。
5 结语
在本篇文章中,我们介绍了机器学习中的调参与最终模型的相关内容。调参是为了找到最优的参数配置,能够提高模型的性能和泛化能力。同时,为了评估模型的性能,在训练和调参过程中,我们将数据集划分为训练集和测试集。
对于数据集的划分,我们介绍了三种常用的方法:留出法、交叉验证法和自助法。每种方法都有各自的使用场景和特点,可以根据实际情况选择合适的方法。
调参过程需要一定的经验和技巧,在限定的参数范围内尝试不同的取值,并通过验证集来评估模型的性能。通过不断地调节参数,我们可以找到最佳的参数配置,以获得最佳的模型性能。
最终模型的训练也是十分重要的,通过重新使用全部的数据集来训练模型,可以进一步提高模型的泛化能力和性能。
调参与最终模型的训练是机器学习中不可忽视的环节,需要经过实践与验证逐步优化模型。通过本文的内容,我们希望读者能够理解调参的重要性,并掌握划分数据集和调参的基本方法。只有通过合理的调参和最终模型的训练,我们才能得到好的结果,并应用机器学习技术来解决现实问题。






)










)


创建流程,以及pom详解)