
在未来面前,每个人都是学生
江海升月明,天涯共此时,关注江时!

引
子
篇为AI未来系列第三篇,中阶部分开始。pandas的数据分析功能比excel强太多,基本上学会pandas,走遍天下都不怕。这是我的备查字典, 是比较实用的一章。大概再介绍几个库就开始全面的实战案例系列,且行且珍惜。
小学生级,阿姨也会,pandas入门到精通备查表。
正
文
Pandas是基于NumPy 的一种工具,其出现是为了解决数据分析任务。
Pandas吸纳了大量库和一些标准的数据模型,提供了高效操作大型数据集所需的工具。
Pandas中的函数和方法能够使我们快速便捷地处理数据。
它是使Python成为强大而高效的数据分析环境的重要因素之一。http://pandas.pydata.org/pandas-docs/stable/api.html
http://pandas.pydata.org/
import numpy as np
import pandas as pd
# 首先导入pandas库
一、序列Series
序列Series是一个一维数组结构,可以存入任一种Python数据类型(integers, strings, floating point numbers, Python objects, 等等)
序列Series由两部分构成,一个是index,另一个是对应的值,注意两者的长度必须一样。序列Series和数组array很类似,大多数numpy的函数都可以直接应用与序列Series
序列Series也像一个固定大小的字典dict,可以通过index来赋值或者取值
1.1 序列Series生成
print('通过数组来生成序列Series')
s_array = np.random.randn(5)
s = pd.Series(s_array, index = ['a','b','c','d','e'])
sprint('通过字典来生成序列Series')
s_dict= {'a':11,'b':1000,'c':123213,'d':-1000}
s = pd.Series(s_dict)
s
1.2 序列Series性质和计算
s = pd.Series(np.random.randn(5), index = ['a','b','c','d','e'])
s# 可以通过index来查看序列Series中的元素
print('查看序列中index为a的元素:',s['a'])
print('查看序列中index为a,c,e的元素:n',s[['a','c','e']])# 基于index 可以修改序列s中的元素
print('原序列:n',s)
s['a'] = 1000000000
print('修改后的序列:n',s)s = pd.Series(np.random.randn(5), index = ['a','b','c','d','e'])
print('原序列:n',s)
# 大多数numpy的函数可以直接应用于 序列 Series
print('序列相加:n',s+s)
print('序列每个元素求指数:n',np.exp(s))s = pd.Series(np.random.randint(1,5,5), index = ['a','b','c','d','e'])
print('查看序列s的index:',s.index)
print('查看序列的值:',s.values)
print('序列s的一阶差分:n',s.diff())ss = pd.Series(np.random.randint(1,3,100))
print(ss[:10])
print('查看序列的唯一取值:',ss.unique())
二、数据框DataFrame
数据框DataFrame是一个二维数组结构,可以存入任一种Python数据类型(integers, strings, floating point numbers, Python objects, 等等)
数据框DataFrame由三部分构成,一个是行索引index,一个是列名,另一个则是取值。
2.1 数据框生成
print('由字典来产生数据框')
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],'year': [2000, 2001, 2002, 2001, 2002],'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = pd.DataFrame(data)
frameprint('由列表来产生数据框')
data = [['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],[2000, 2001, 2002, 2001, 2002],[1.5, 1.7, 3.6, 2.4, 2.9]]
frame = pd.DataFrame(data,index=['state','year','pop']).T
frame
2.2 数据框基本性质
data = pd.DataFrame(np.random.randint(1,100,(10,4)),columns=['x1','x2','x3','x4'])
print('首先查看数据框的形状',data.shape)
print('查看数据框的头部:')
print(data.head())
print('---------------------')
print('查看数据框的尾部:')
print(data.tail())
print('---------------------')
print('查看数据框的索引index')
print(data.index)print('查看数据框的列名')
print(data.columns)
print('---------------------')
print('查看数据框的值,其格式为数组array')
print(data.values)
print('---------------------')
print('查看数据框的基础描述性统计')
print(data.describe())# 在原有的数据框中新加入一列
data['新列'] = ['HAHA'] * len(data)
data# 数据框的转置
data.T
2.3 数据框截取
2.3.1 行截取
print('查看数据框data索引为1的行——方法一')
print(data.ix[1])
print('---------------------')
print('查看数据框data索引为1的行——方法二')
print(data.loc[1,:])
print('---------------------')
print('查看数据框data前3行')
print(data[:3])
2.3.2 列截取
print('数据框data的x3列选取')
print(data['x3'])
print('---------------------')
print('数据框data的x3,x4两列同时选取')
print(data[['x3','x4']])
2.3.3 数据框行列同时截取
print('截取数据框data的前4行的x3和x4列')
data.loc[:3,['x3','x4']]
2.3.4 数据框条件截取
print('截取数据框x3大于等于50的记录')
print(data[data['x3']>=50])
print('---------------------')
print('截取数据框x3大于20且x4小于50的记录')
print(data[(data['x3']>20)&(data['x4']<50)])
print('---------------------')
print('截取数据框x3大于20的x1列')
print(data[data['x3']>50]['x1'])
2.4 数据框缺失值处理
例如下面这个数据框data,其中就存在缺失值
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],'year': [2000, 2001, 2002, 2001, 2002],'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
data = pd.DataFrame(data)
data.loc[1,'pop'] = np.NaN
data.loc[3,'state'] = None
datadata.dropna()
#删除含有缺失的行data.dropna(how="all")
#表示该行都为缺失的行才删除 注意是这一行中的每一个元素都为缺失才删除这一行data.dropna(how="all", axis=1)
#表示该列若都为缺失的列则删除,注意是这一列的每个元素都为缺失才会删除这一列data.dropna(thresh=3, axis=0)
#表示保留至少存在3个非NaN的行,即如果某一行的非缺失值个数小于3个,则会被删除data.dropna(thresh=3, axis=1)
#表示保留至少存在3个非NaN的列,即如果某一列的非缺失值个数小于3个,则会被删除
上面对缺失值的处理都是将缺失值剔除,下面介绍了填充缺失值的方法
dataprint('用0填充数据框中的缺失值,0是可选参数之一')
data.fillna(value=0)data.fillna(method='ffill')
#填充缺失值 用缺失值所在列的前一个非NaN值来进行填充 data.fillna(method="bfill")
#用缺失值所在列的后一个非NaN来填充
2.5 数据框排序
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],'year': [2000, 2001, 2002, 2001, 2002],'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
data = pd.DataFrame(data)
dataprint('数据框data按列pop降序排序')
data.sort(columns='pop',ascending=False)print('数据框data按列pop升序排序')
data.sort(columns='pop',ascending=True)print('数据框data按行索引index降序排序')
data.sort_index()
2.6 数据框的基本函数
print('按列求均值')
data.mean() print('按行求均值')
data.mean(axis=1)
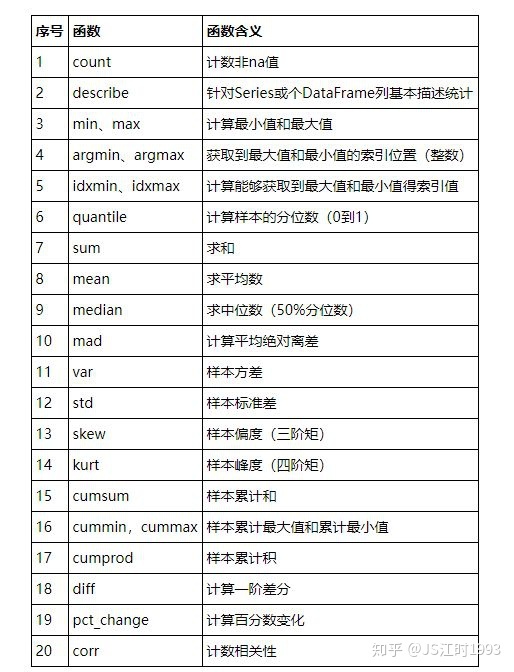
函数汇总
下面的函数都是通过数据框.函数名(参数设置)来进行调用,一般的参数是axis=0/1,选择为0则是按行来实现函数,1则是按列来实现函数。
2.7 数据框拼接
下面介绍了三个函数来实现数据框的拼接功能——concat函数,merge函数和join函数
2.7.1 数据框拼接—pd.concat
data1 = pd.DataFrame(np.random.randn(4,3),index=['a','b','c','d'],columns=['x1','x2','x3'])
data1data2 = pd.DataFrame(np.random.randn(4,3),index=['e','f','g','h'],columns=['x1','x2','x3'])
data2print('按行拼接')
pd.concat([data1,data2],axis=0)
data1 = pd.DataFrame(np.random.randn(4,3),index=['a','b','c','d'],columns=['x1','x2','x3'])
data1data2 = pd.DataFrame(np.random.randn(4,3),index=['a','b','c','e'],columns=['x1','x3','x4'])
data2print('按列拼接')
pd.concat([data1,data2],axis=1)
2.7.2 数据框拼接—pd.merge
pd.merge一般针对的是按列合并。
pd.merge(
left,
right,
how='inner',
on=None,
left_on=None,
right_on=None,
left_index=False, right_index=False,
sort=True,
suffixes=('_x', '_y'),
copy=True,
indicator=False)
left: 一个dataframe对象
right: 另一个dataframe对象
how: 可以是'left', 'right', 'outer', 'inner'. 默认为inner。
on: 列名,两个dataframe都有的列。如果不传参数,而且left_index和right_index也等于False,则默认把两者交叉/共有的列作为链接键(join keys)。可以是一个列名,也可以是包含多个列名的list。
left_on: 左边dataframe的列会用做keys。可以是列名,或者与dataframe长度相同的矩阵array。
right_on: 右边同上。
left_index: 如果为Ture,用左侧dataframe的index作为连接键。如果是多维索引,level数要跟右边相同才行。
right_index: 右边同上。
sort: 对合并后的数据框排序,以连接键。
suffixes: 一个tuple,包字符串后缀,用来加在重叠的列名后面。默认是('_x','_y')。
copy: 默认Ture,复制数据。
indicator: 布尔型(True/FALSE),或是字符串。如果为True,合并之后会增加一列叫做'_merge'。是分类数据,用left_only, right_only, both来标记来自左边,右边和两边的数据。
left_data = pd.DataFrame({'time':['2017-09-11','2017-09-12','2017-09-13'],'x1':[1,2,3],'x2':[2,2,1]})
left_dataright_data = pd.DataFrame({'time':['2017-09-10','2017-09-11','2017-09-12'],'x3':[-1,-1,10],'x4':[2,-100,0]})
right_dataprint('按time拼接,只保留共同的部分')
pd.merge(left_data,right_data,on='time')print('按time拼接,但所有的数据都保留下来')
pd.merge(left_data,right_data,on='time',how='outer')print('按time拼接,但所有的数据都保留下来,且生成一列来表示数据的来源')
pd.merge(left_data,right_data,on='time',how='outer',indicator='数据来源')
2.7.3 数据框拼接—.join
DataFrame.join(other,
on=None,
how='left',
lsuffix='',
rsuffix='',
sort=False)
other:一个DataFrame、Series(要有命名),或者DataFrame组成的list。
on:列名,包含列名的list或tuple,或矩阵样子的列 (如果是多列,必须有MultiIndex)。 跟上面的几种方法一样,用来指明依据哪一列进行合并。 如果没有赋值,则依据两个数据框的index合并。
how:合并方式, {‘left’, ‘right’, ‘outer’, ‘inner’}, 默认‘left‘。
lsuffix:字符串。用于左侧数据框的重复列。 把重复列重新命名,原来的列名+字符串。 【如果有重复列,必须添加这个参数。】
rsuffix:同上。右侧。
sort:布尔型,默认False。如果为True,将链接键(on的那列)按字母排序。
left_data = pd.DataFrame({'time':['2017-09-11','2017-09-12','2017-09-13'],'x1':[1,2,3],'x2':[2,2,1]})
left_dataright_data = pd.DataFrame({'time':['2017-09-10','2017-09-11','2017-09-12'],'x2':[-1,-1,10],'x4':[2,-100,0]})
right_dataprint('注意到两个拼接的数据框,含有相同的列x2和time,故重新命名了这两个列')
left_data.join(right_data,lsuffix='_left',rsuffix='_right')
2.8 数据框重复值剔除
有时候,希望能够剔除掉数据框中的重复记录
data = pd.concat([left_data,left_data],axis=0)
dataprint('查看数据框中是否存在重复记录,标记为True的为重复记录')
data.duplicated()print('剔除数据框中的重复记录')
data.drop_duplicates()
2.9 基于pandas的文件操作
在进行数据分析之前,可能需要读写自己的数据文件。或者在完成数据分析之后,想把结果输出到外部的文件
在Python中,利用pandas模块中的几个函数,可以轻松实现这些功能,利用pandas读取文件之后数据的格式为数据框,且如果想用pandas将数据输出为外部文件,也要先确保要输出的文件的格式为数据框
注意在运行下面的程序之前,需要确保文件已经在目录下
2.9.1 读取txt文件
text = pd.read_table('data/training/test2.txt',index_col=0,delimiter=' ')
# 文件所在的路径是必须输入的
# index_col=0指定第一列为index
# delimiter指定了数据间的分隔符,分隔符可以使空格,制表符,;等等
# 这个函数中还有很多参数可以定义
text
2.9.2 读取excel/csv文件
import pandas as pd
data_excel = pd.read_excel('data/training/test3.xlsx')
# 文件所在的路径是必须输入的
data_excel.head()data_csv = pd.read_csv('data/training/test3_csv.csv',encoding='GBK')
# 文件所在的路径是必须输入的
#这里要注意,encoding='GBK'一般是要加上,涉及到编译解码的问题
data_csv.head()
2.9.3 输出为excel/csv文件
由于使用了pandas库,我们在将想要的数据集输出为外部的excel/csv文件时,首先要确保文件的格式为数据框
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],'year': [2000, 2001, 2002, 2001, 2002],'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}
frame = pd.DataFrame(data)
frame# 将数据集frame输出为外部文件
frame.to_excel('data/training/写出为excel.xlsx')
frame.to_csv('data/training/写出为csv.csv')
2.10 数据框分组及透视表
2.10.1 分组——groupby函数
例如下面这个数据框data,希望根据地域或者性别来分组再进行数据分析
data = {'地域': ['上海', '上海', '非上海', '非上海', '上海','非上海','上海','上海','上海'],'性别': ['男', '女', '男', '女', '男','女','女','男','男'],'x1': [1.5, 1.7, 3.6, 2.4, 2.9,2.2,100,2.0,0],'x2': np.random.randn(9)}
data = pd.DataFrame(data)
dataprint('按地域求x1和x2的均值')
data.groupby('地域').mean()grouped = data.groupby('地域')
#形成按地域分组后的数据集 grouped
grouped.describe()
print('按地域和性别求x1,x2的均值')
data.groupby(['地域','性别']).mean()grouped = data.groupby(['地域','性别'])
functions = ['count','mean','max','min']
print('对按地域和性别分组后的数据框,可以进行多个函数的同时操作')
res = grouped['x1','x2'].agg(functions)
resres.to_excel('data/training/agg.xlsx')print('对不同的列可以进行不同的操作,例如对x2求均值,而对x1求和,最大值和最小值')
grouped = data.groupby(['地域','性别'])
grouped.agg({'x1': ['sum','max','min'], 'x2': 'mean'})
2.10.2 apply函数,可以对分组后的数据框进行自定义的函数操作
def top(data_in, n=5, column='x2'):return data_in.sort(column)[-n:]print('对数据框data按地域进行分组之后,且对于每一组,按x2排序,且输出x2最小的二条记录')
data.groupby('地域').apply(top, n=2)
print('对数据框data按地域进行分组之后,且对于每一组,按x2排序,且输出x2最小的二条记录')
data.groupby('地域').apply(top, n=2)
小例子——分组的线性回归
import pandas as pd
例如我们有如下数据集,希望按年分组,利用每一年的y对x进行回归
data = pd.DataFrame([])
x = np.random.randn(2192)
data['x'] = x
data['y'] = 2 * x + 1 + np.random.randn(2192)*0.2
data.index = list(pd.date_range('2011-01-01','2016-12-31'))
data['年份'] = data.index.year
data.head()
先对数据框by_year按年份进行分组
by_year = data.groupby('年份') #按年份分组
按年份分组后,求y和x之间的相关系数
by_year.apply(lambda g:g['y'].corr(g['x'])) #按年分组 求y和x求相关系数 注意这里使用了lambda函数
按年份分组后,y对x进行回归
import statsmodels.api as smdef regression(data, y_name, x_name): #定义一个回归的函数Y = data[y_name]X = data[x_name]X['intercept'] = 1.0result = sm.OLS(Y,X).fit()return result.paramsby_year.apply(regression,'y',['x']) #按年分组进行回归
2.10.3 数据透视表——pivot
data = {'地域': ['上海', '上海', '非上海', '非上海', '上海','非上海','上海','上海','上海'],'性别': ['男', '女', '男', '女', '男','女','女','男','男'],'x1': [1.5, 1.7, 3.6, 2.4, 2.9,2.2,100,2.0,0],'x2': np.random.randn(9)}
data = pd.DataFrame(data)
datadata.pivot_table(index='地域', columns='性别', values='x1',aggfunc='sum')来源:我的印象笔记整理














 —— 几个简单函数掌握!)
 方法的使用及注意事项)

、Collection.toArray()...)
)
