MVC OR DDD
说明:这篇是标题党,不包含相关概念说明
前段时间跟随师兄学习了解了DDD领域驱动模型,觉得这个思想更好,进行下面解析和学习方面的思考和实践,觉得很好,耐心读下去。希望对您有所帮助。
首先,面向对象出来已久,但是大多情况下,我的思考分析方式停留在了MVC面条层面,比如学生管理系统,直接思考的是应该有哪几个表【学生,班级,成绩。。。】,然后基于这个表应该有哪些字段,进行数据库设计,生成dao,service层进行简单逻辑CRUD,Mangager和Controller,包个VO,暴露给前端,自己手动调用一下,好,没啥大问题,提交,部属个机器丢给前端,联调完事。
但是后面开发的时候前端对照PRD进行开发的时候经常发现,这个字段咋没有,这个PRD的交互不太合理,需要增加字段,更为复杂的时候,是你有一对N的表映射的时候,你发现你的状态字段,不是来源一个表,要主表,审批表,从表,聚合之后而来,好不容易写完了,然后测试,发现某个操作之后,展示的不对,产品看了看法完成之后的,这个咋不符合他原先的设计。我们不得不接受的现实是一千个人眼中就有一千个哈姆雷特以及你的需求不可能不变化。
那么我们怎么解决这类现象。其实我们上面开发代码的时候思考的方式用形象的比喻的话就是面条代码,基于底层数据库表,一层添加点东西一层一个entry,现在想想很形象。
后来接触DDD【领域驱动模型】,我们先要对领域边界划分,领域内进行高内聚,对于边界外的,让对应的领域提供必要的接口,我们核心设计的内容,不再是数据库中存储的表,把设计的中心,上移到领域层,我们应该划分那些领域,这个领域有那些model,这个model的主键(值对象)是什么,别的model都依赖这个值对象,另外我这个领域的对象,应该有那些能力(比如,鸭子这个领域对象,应该可以飞,吃)这些核心能力就是这个领域应该拥有的方法,另外这个对象应该是充血还是贫血(MVC那块只有getset方法的是贫血模型)把属于这个对象的方法放到这个领域对象中,就是这个对象拥有飞的能力。这样才更符合我们OOP的现实。
上面主要有两个问题,1。哈姆雷特,这个就需要一个开发团队中,大家【产品,系统owner,开发,测试】有统一的认知,统一的语言,向同一个方向搞项目,这个东西,客观其实比较难实现,多数情况下,面向领导编程模型中,我们是要向上级展现结果的,而不是我们的代码有多规范,并且这个东西,需要大家有统一的时间,有一定的学习成本,以及人员流动情况。但是我们需要有一定的项目结构,这就要求我们要有一定的文档记录我们的项目是干什么的,发展方向,未来愿景,不知道多少项目做到后面还能保持原来设计的方向,如果你的方向已经做的很大的改变,对于不重构的系统来说是灾难性的,并且你会发现,偏航不是一天跑远的,是潜移默化的。对于一个持久发展的项目,这个是一个严重影响的方向。所以哈姆雷特问题对于权限不高的小开发是一个黑洞。但是我们可以根据目前产品界面上的重点,用户高频使用的,重点关注的点,进行汇总,总结,这个项目前面的航向。2.变化的需求,项目要发展就要改变创新,跟你申请专利差不多,最难的就是创新型,最简单的就是改变外观,优化下界面,改变下交互,这可能就是某些人,向上交的作业,不过我要说明的是,改变用户习惯的习惯很可怕,对于一个用户习惯的改变会应该一段时间内用户的体感,不知道多少产品会考虑这方面的影响,OOP中一条重要的规则,对于修改关闭,对于扩展开放,对于之前的用户已经习惯的东西,如果你的新设计没有明显的好处就不要重新设计了,不如多思考下用户痛点,项目的核心是什么,多push下开发,共同解决优化下。DDD中很重要的思想是依赖倒置,领域层依赖存储层。这样你变更的核心的领域中那个对象应该拥有什么属性,能力,而不是这个应该存储到哪个表里面。另外一个就是加防腐层,外部第三方和前端页面中间加防腐,防腐,而不是前端有一个小的变化直接击穿到领域里面了,当然你原来领域中没有的肯定是要击穿到领域层的。
鬼扯半天毛用没有,举个例子,最近面试,八股文很多,在看和学习的过程中思考应该吧这个思想运用到生活中,我命名为糖葫芦模型。
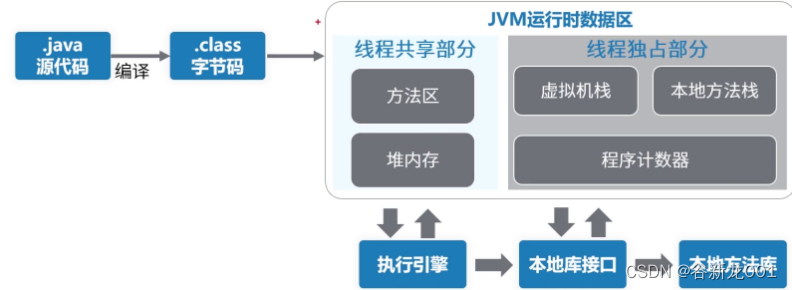
我们从一个java文件为开头,沿数据流向分析过程
java文件通过javac编译成class文件,然后通过ClassLoad加载进行内存,ClassLoad是双亲委派,最上面的是BootstrapClassLoad,加载rt.jar内容 【进入ClassLoad域】…
加载进内存后,JMM模型包含下面几个区域【JMM域、堆栈方法区pc本地方法区】【垃圾回收】
执行引擎+本地接口
这样从数据流向看过去,经过一段是一个领域,这样坐地铁什么的时候直接看我们串了几个糖葫芦就行。
mysql糖葫芦
sql -> conn -> server端 链接 解析 优化 + 缓存 -》 执行引擎
这样就又是一个糖葫芦,这种方法其实就是我们常见的图书目录【一般来说图书的目录是渐进式的,并不一定有数据流向有关系】,但是一个别致的名字总是会引起新的兴趣。水文一篇,欢迎吐槽



)
模型服务)














